 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PETS-SWINF: A regression method that considers images with metadata based Neural Network for pawpularity prediction on 2021 Kaggle Competition "PetFinder.my"
Jan 16, 2022


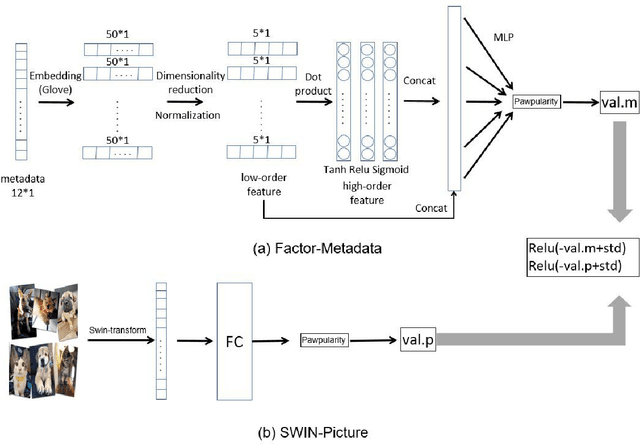

Millions of stray animals suffer on the streets or are euthanized in shelters every day around the world. In order to better adopt stray animals, scoring the pawpularity (cuteness) of stray animals is very important, but evaluating the pawpularity of animals is a very labor-intensive thing. Consequently, there has been an urgent surge of interest to develop an algorithm that scores pawpularity of animals. However, the dataset in Kaggle not only has images, but also metadata describing images. Most methods basically focus on the most advanced image regression methods in recent years, but there is no good method to deal with the metadata of images. To address the above challenges, the paper proposes an image regression model called PETS-SWINF that considers metadata of the images. Our results based on a dataset of Kaggle competition, "PetFinder.my", show that PETS-SWINF has an advantage over only based images models. Our results shows that the RMSE loss of the proposed model on the test dataset is 17.71876 but 17.76449 without metadata. The advantage of the proposed method is that PETS-SWINF can consider both low-order and high-order features of metadata, and adaptively adjust the weights of the image model and the metadata model. The performance is promising as our leadboard score is ranked 15 out of 3545 teams (Gold medal) currently for 2021 Kaggle competition on the challenge "PetFinder.my".
De-Noising of Photoacoustic Microscopy Images by Deep Learning
Jan 12, 2022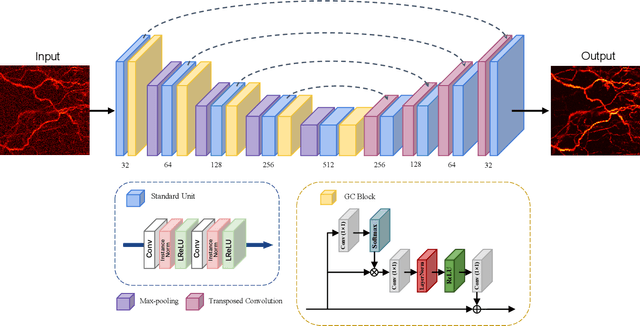
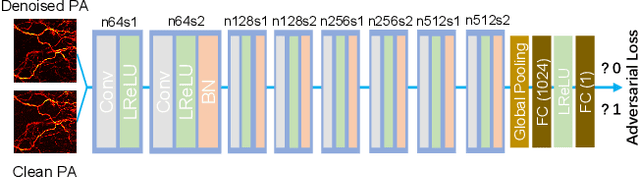
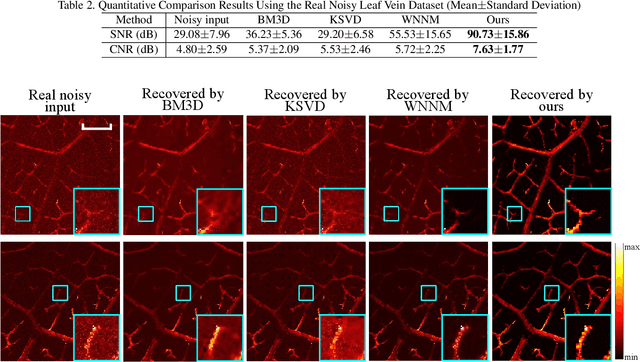
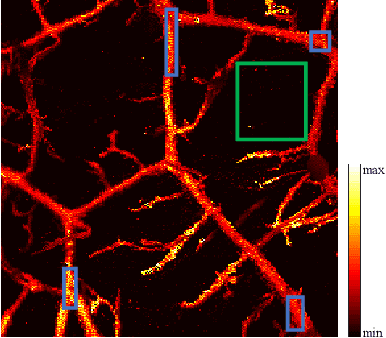
As a hybrid imaging technology, photoacoustic microscopy (PAM) imaging suffers from noise due to the maximum permissible exposure of laser intensity, attenuation of ultrasound in the tissue, and the inherent noise of the transducer. De-noising is a post-processing method to reduce noise, and PAM image quality can be recovered. However, previous de-noising techniques usually heavily rely on mathematical priors as well as manually selected parameters, resulting in unsatisfactory and slow de-noising performance for different noisy images, which greatly hinders practical and clinical applications. In this work, we propose a deep learning-based method to remove complex noise from PAM images without mathematical priors and manual selection of settings for different input images. An attention enhanced generative adversarial network is used to extract image features and remove various noises. The proposed method is demonstrated on both synthetic and real datasets, including phantom (leaf veins) and in vivo (mouse ear blood vessels and zebrafish pigment) experiments. The results show that compared with previous PAM de-noising methods, our method exhibits good performance in recovering images qualitatively and quantitatively. In addition, the de-noising speed of 0.016 s is achieved for an image with $256\times256$ pixels. Our approach is effective and practical for the de-noising of PAM images.
FlexHDR: Modelling Alignment and Exposure Uncertainties for Flexible HDR Imaging
Jan 07, 2022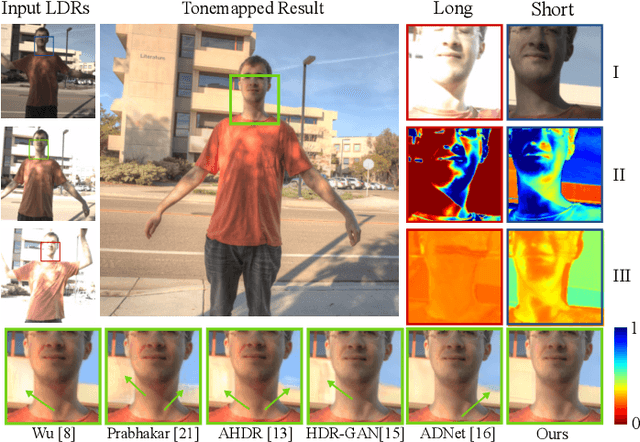


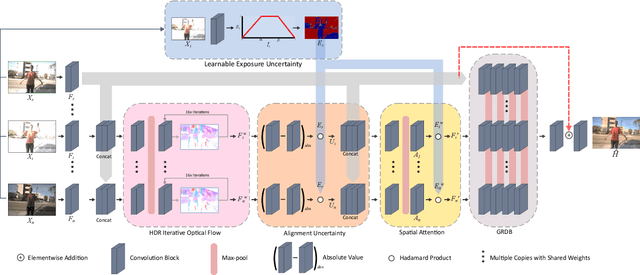
High dynamic range (HDR) imaging is of fundamental importance in modern digital photography pipelines and used to produce a high-quality photograph with well exposed regions despite varying illumination across the image. This is typically achieved by merging multiple low dynamic range (LDR) images taken at different exposures. However, over-exposed regions and misalignment errors due to poorly compensated motion result in artefacts such as ghosting. In this paper, we present a new HDR imaging technique that specifically models alignment and exposure uncertainties to produce high quality HDR results. We introduce a strategy that learns to jointly align and assess the alignment and exposure reliability using an HDR-aware, uncertainty-driven attention map that robustly merges the frames into a single high quality HDR image. Further, we introduce a progressive, multi-stage image fusion approach that can flexibly merge any number of LDR images in a permutation-invariant manner. Experimental results show our method can produce better quality HDR images with up to 0.8dB PSNR improvement to the state-of-the-art, and subjective improvements in terms of better detail, colours, and fewer artefacts.
Contrastive Learning with Large Memory Bank and Negative Embedding Subtraction for Accurate Copy Detection
Dec 08, 2021


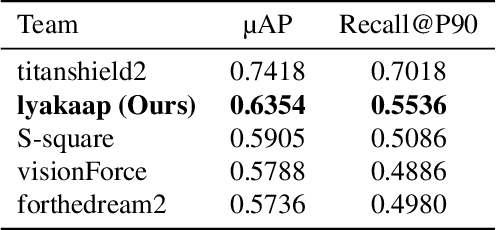
Copy detection, which is a task to determine whether an image is a modified copy of any image in a database, is an unsolved problem. Thus, we addressed copy detection by training convolutional neural networks (CNNs) with contrastive learning. Training with a large memory-bank and hard data augmentation enables the CNNs to obtain more discriminative representation. Our proposed negative embedding subtraction further boosts the copy detection accuracy. Using our methods, we achieved 1st place in the Facebook AI Image Similarity Challenge: Descriptor Track. Our code is publicly available here: \url{https://github.com/lyakaap/ISC21-Descriptor-Track-1st}
A Method of Generating Measurable Panoramic Image for Indoor Mobile Measurement System
Oct 27, 2020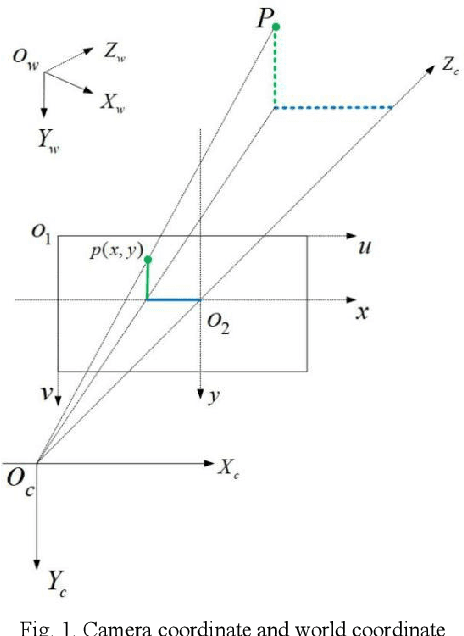
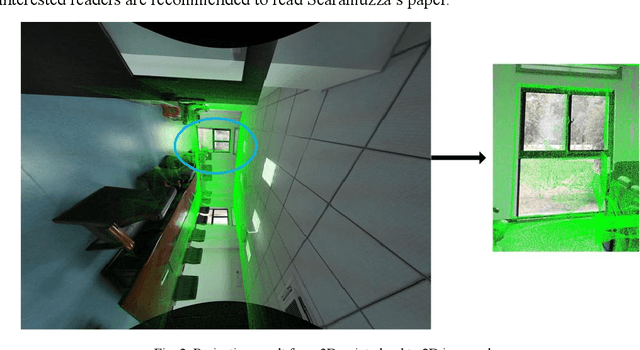

This paper designs a technique route to generate high-quality panoramic image with depth information, which involves two critical research hotspots: fusion of LiDAR and image data and image stitching. For the fusion of 3D points and image data, since a sparse depth map can be firstly generated by projecting LiDAR point onto the RGB image plane based on our reliable calibrated and synchronized sensors, we adopt a parameter self-adaptive framework to produce 2D dense depth map. For image stitching, optimal seamline for the overlapping area is searched using a graph-cuts-based method to alleviate the geometric influence and image blending based on the pyramid multi-band is utilized to eliminate the photometric effects near the stitching line. Since each pixel is associated with a depth value, we design this depth value as a radius in the spherical projection which can further project the panoramic image to the world coordinate and consequently produces a high-quality measurable panoramic image. The purposed method is tested on the data from our data collection platform and presents a satisfactory application prospects.
GPU-Net: Lightweight U-Net with more diverse features
Jan 07, 2022
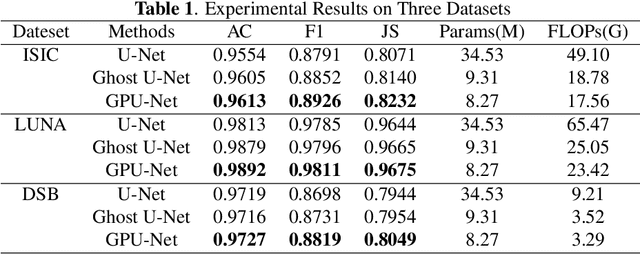
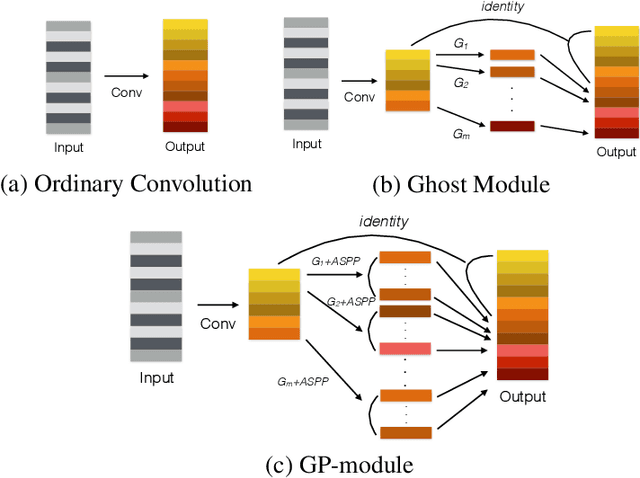
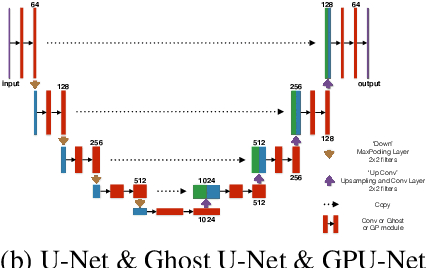
Image segmentation is an important task in the medical image field and many convolutional neural networks (CNNs) based methods have been proposed, among which U-Net and its variants show promising performance. In this paper, we propose GP-module and GPU-Net based on U-Net, which can learn more diverse features by introducing Ghost module and atrous spatial pyramid pooling (ASPP). Our method achieves better performance with more than 4 times fewer parameters and 2 times fewer FLOPs, which provides a new potential direction for future research. Our plug-and-play module can also be applied to existing segmentation methods to further improve their performance.
A Pixel-based Encryption Method for Privacy-Preserving Deep Learning Models
Mar 31, 2022
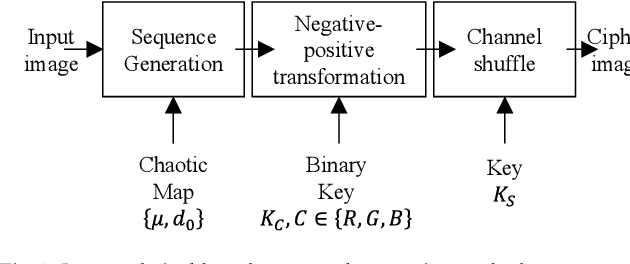
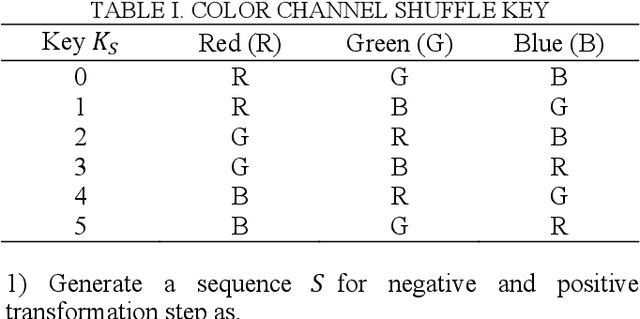

In the recent years, pixel-based perceptual algorithms have been successfully applied for privacy-preserving deep learning (DL) based applications. However, their security has been broken in subsequent works by demonstrating a chosen-plaintext attack. In this paper, we propose an efficient pixel-based perceptual encryption method. The method provides a necessary level of security while preserving the intrinsic properties of the original image. Thereby, can enable deep learning (DL) applications in the encryption domain. The method is substitution based where pixel values are XORed with a sequence (as opposed to a single value used in the existing methods) generated by a chaotic map. We have used logistic maps for their low computational requirements. In addition, to compensate for any inefficiency because of the logistic maps, we use a second key to shuffle the sequence. We have compared the proposed method in terms of encryption efficiency and classification accuracy of the DL models on them. We have validated the proposed method with CIFAR datasets. The analysis shows that when classification is performed on the cipher images, the model preserves accuracy of the existing methods while provides better security.
Analyzing Human Observer Ability in Morphing Attack Detection -- Where Do We Stand?
Mar 04, 2022
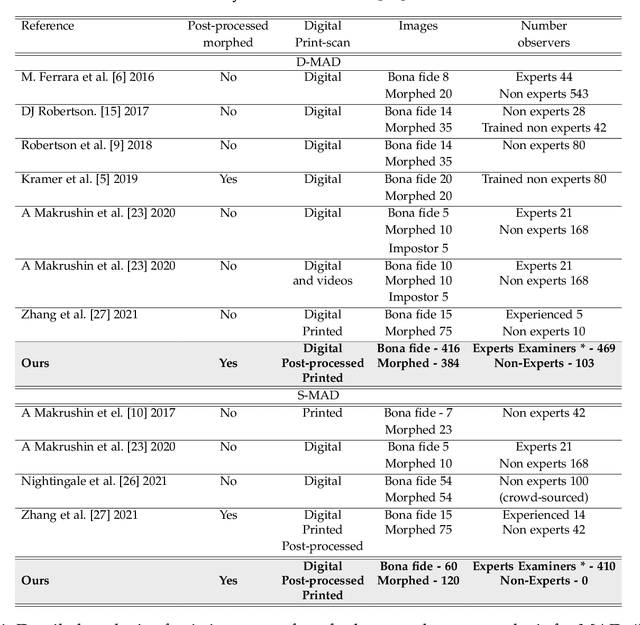
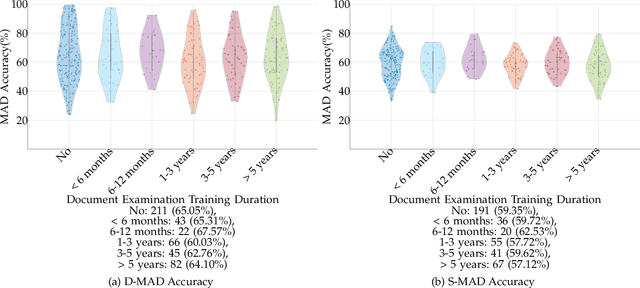
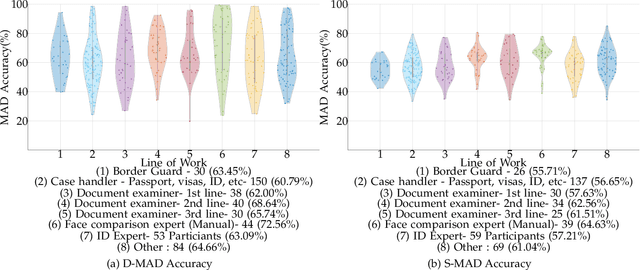
While several works have studied the vulnerability of automated FRS and have proposed morphing attack detection (MAD) methods, very few have focused on studying the human ability to detect morphing attacks. The examiner/observer's face morph detection ability is based on their observation, domain knowledge, experience, and familiarity with the problem, and no works report the detailed findings from observers who check identity documents as a part of their everyday professional life. This work creates a new benchmark database of realistic morphing attacks from 48 unique subjects leading to 400 morphed images presented to the observers in a Differential-MAD (D-MAD) setting. Unlike the existing databases, the newly created morphed image database has been created with careful considerations to age, gender and ethnicity to create realistic morph attacks. Further, unlike the previous works, we also capture ten images from Automated Border Control (ABC) gates to mimic the realistic D-MAD setting leading to 400 probe images in border crossing scenarios. The newly created dataset is further used to study the ability of human observers' ability to detect morphed images. In addition, a new dataset of 180 morphed images is also created using the FRGCv2 dataset under the Single Image-MAD (S-MAD) setting. Further, to benchmark the human ability in detecting morphs, a new evaluation platform is created to conduct S-MAD and D-MAD analysis. The benchmark study employs 469 observers for D-MAD and 410 observers for S-MAD who are primarily governmental employees from more than 40 countries. The analysis provides interesting insights and points to expert observers' missing competence and failure to detect a considerable amount of morphing attacks. Human observers tend to detect morphed images to a lower accuracy as compared to the automated MAD algorithms evaluated in this work.
Channel Estimation for Underwater Acoustic OFDM Communications: An Image Super-Resolution Approach
Mar 07, 2021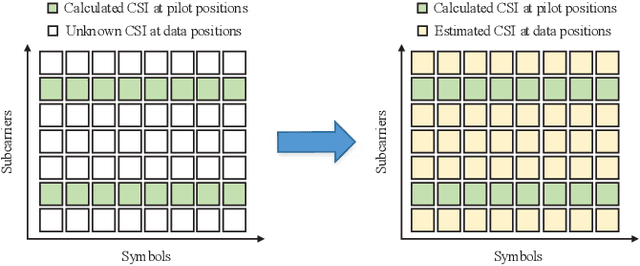
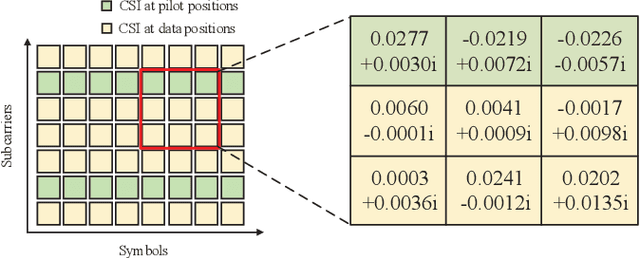
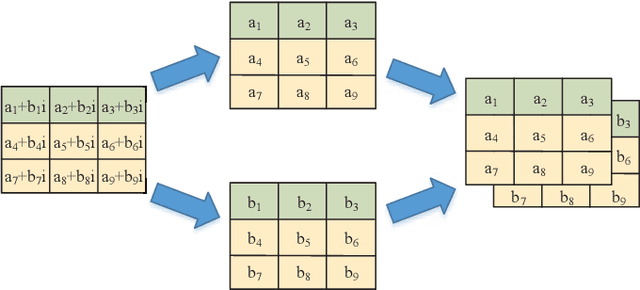
In this paper, by exploiting the powerful ability of deep learning, we devote to designing a well-performing and pilot-saving neural network for the channel estimation in underwater acoustic (UWA) orthogonal frequency division multiplexing (OFDM) communications. By considering the channel estimation problem as a matrix completion problem, we interestingly find it mathematically equivalent to the image super-resolution problem arising in the field of image processing. Hence, we attempt to make use of the very deep super-resolution neural network (VDSR), one of the most typical neural networks to solve the image super-resolution problem, to handle our problem. However, there still exist significant differences between these two problems, we thus elegantly modify the basic framework of the VDSR to design our channel estimation neural network, referred to as the channel super-resolution neural network (CSRNet). Moreover, instead of training an individual network for each considered signal-to-noise ratio (SNR), we obtain an unified network that works well for all SNRs with the help of transfer learning, thus substantially increasing the practicality of the CSRNet. Simulation results validate the superiority of the CSRNet against the existing least square (LS) and deep neural network (DNN) based algorithms in terms of the mean square error (MSE) and the bit error rate (BER). Specifically, compared with the LS algorithm, the CSRNet can reduce the BER by 44.74% even using 50% fewer pilots.
Meta-optic Accelerators for Object Classifiers
Jan 26, 2022Rapid advances in deep learning have led to paradigm shifts in a number of fields, from medical image analysis to autonomous systems. These advances, however, have resulted in digital neural networks with large computational requirements, resulting in high energy consumption and limitations in real-time decision making when computation resources are limited. Here, we demonstrate a meta-optic based neural network accelerator that can off-load computationally expensive convolution operations into high-speed and low-power optics. In this architecture, metasurfaces enable both spatial multiplexing and additional information channels, such as polarization, in object classification. End-to-end design is used to co-optimize the optical and digital systems resulting in a robust classifier that achieves 95% accurate classification of handwriting digits and 94% accuracy in classifying both the digit and its polarization state. This approach could enable compact, high-speed, and low-power image and information processing systems for a wide range of applications in machine-vision and artificial intelligence.