 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On the Equity of Nuclear Norm Maximization in Unsupervised Domain Adaptation
Apr 12, 2022
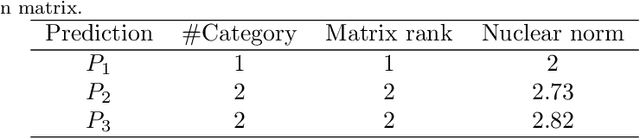


Nuclear norm maximization has shown the power to enhance the transferability of unsupervised domain adaptation model (UDA) in an empirical scheme. In this paper, we identify a new property termed equity, which indicates the balance degree of predicted classes, to demystify the efficacy of nuclear norm maximization for UDA theoretically. With this in mind, we offer a new discriminability-and-equity maximization paradigm built on squares loss, such that predictions are equalized explicitly. To verify its feasibility and flexibility, two new losses termed Class Weighted Squares Maximization (CWSM) and Normalized Squares Maximization (NSM), are proposed to maximize both predictive discriminability and equity, from the class level and the sample level, respectively. Importantly, we theoretically relate these two novel losses (i.e., CWSM and NSM) to the equity maximization under mild conditions, and empirically suggest the importance of the predictive equity in UDA. Moreover, it is very efficient to realize the equity constraints in both losses. Experiments of cross-domain image classification on three popular benchmark datasets show that both CWSM and NSM contribute to outperforming the corresponding counterparts.
A New Dataset and Transformer for Stereoscopic Video Super-Resolution
Apr 21, 2022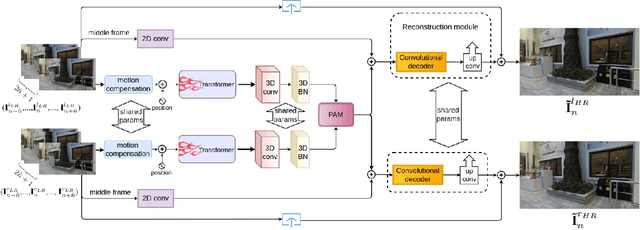

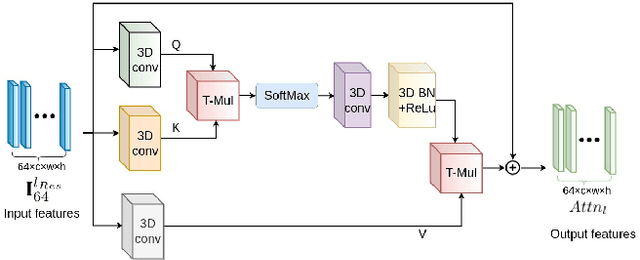
Stereo video super-resolution (SVSR) aims to enhance the spatial resolution of the low-resolution video by reconstructing the high-resolution video. The key challenges in SVSR are preserving the stereo-consistency and temporal-consistency, without which viewers may experience 3D fatigue. There are several notable works on stereoscopic image super-resolution, but there is little research on stereo video super-resolution. In this paper, we propose a novel Transformer-based model for SVSR, namely Trans-SVSR. Trans-SVSR comprises two key novel components: a spatio-temporal convolutional self-attention layer and an optical flow-based feed-forward layer that discovers the correlation across different video frames and aligns the features. The parallax attention mechanism (PAM) that uses the cross-view information to consider the significant disparities is used to fuse the stereo views. Due to the lack of a benchmark dataset suitable for the SVSR task, we collected a new stereoscopic video dataset, SVSR-Set, containing 71 full high-definition (HD) stereo videos captured using a professional stereo camera. Extensive experiments on the collected dataset, along with two other datasets, demonstrate that the Trans-SVSR can achieve competitive performance compared to the state-of-the-art methods. Project code and additional results are available at https://github.com/H-deep/Trans-SVSR/
SeeingGAN: Galactic image deblurring with deep learning for better morphological classification of galaxies
Mar 28, 2021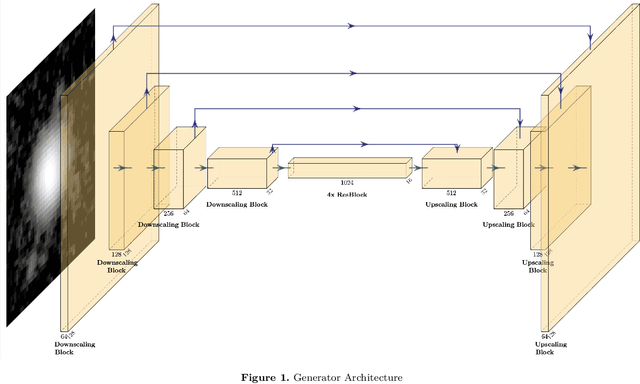


Classification of galactic morphologies is a crucial task in galactic astronomy, and identifying fine structures of galaxies (e.g., spiral arms, bars, and clumps) is an essential ingredient in such a classification task. However, seeing effects can cause images we obtain to appear blurry, making it difficult for astronomers to derive galaxies' physical properties and, in particular, distant galaxies. Here, we present a method that converts blurred images obtained by the ground-based Subaru Telescope into quasi Hubble Space Telescope (HST) images via machine learning. Using an existing deep learning method called generative adversarial networks (GANs), we can eliminate seeing effects, effectively resulting in an image similar to an image taken by the HST. Using multiple Subaru telescope image and HST telescope image pairs, we demonstrate that our model can augment fine structures present in the blurred images in aid for better and more precise galactic classification. Using our first of its kind machine learning-based deblurring technique on space images, we can obtain up to 18% improvement in terms of CW-SSIM (Complex Wavelet Structural Similarity Index) score when comparing the Subaru-HST pair versus SeeingGAN-HST pair. With this model, we can generate HST-like images from relatively less capable telescopes, making space exploration more accessible to the broader astronomy community. Furthermore, this model can be used not only in professional morphological classification studies of galaxies but in all citizen science for galaxy classifications.
Reference-based Texture transfer for Single Image Super-resolution of Magnetic Resonance images
Feb 10, 2021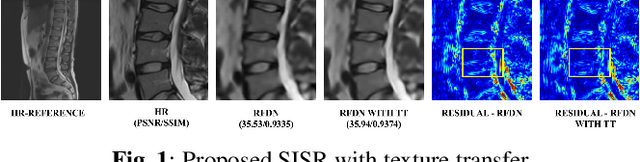
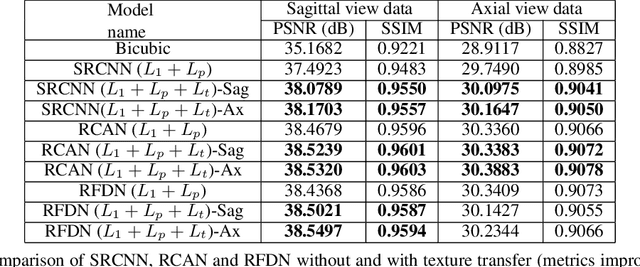
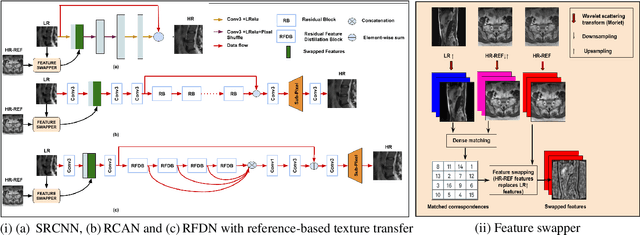
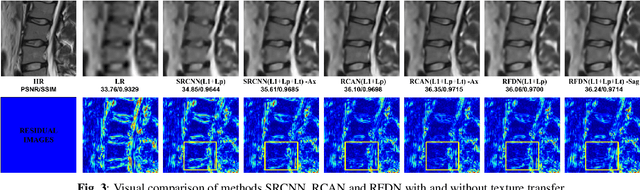
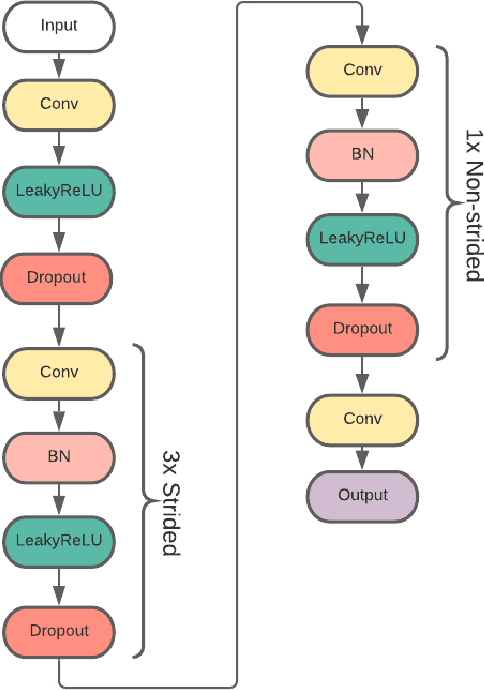
Magnetic Resonance Imaging (MRI) is a valuable clinical diagnostic modality for spine pathologies with excellent characterization for infection, tumor, degenerations, fractures and herniations. However in surgery, image-guided spinal procedures continue to rely on CT and fluoroscopy, as MRI slice resolutions are typically insufficient. Building upon state-of-the-art single image super-resolution, we propose a reference-based, unpaired multi-contrast texture-transfer strategy for deep learning based in-plane and across-plane MRI super-resolution. We use the scattering transform to relate the texture features of image patches to unpaired reference image patches, and additionally a loss term for multi-contrast texture. We apply our scheme in different super-resolution architectures, observing improvement in PSNR and SSIM for 4x super-resolution in most of the cases.
A survey in Adversarial Defences and Robustness in NLP
Apr 12, 2022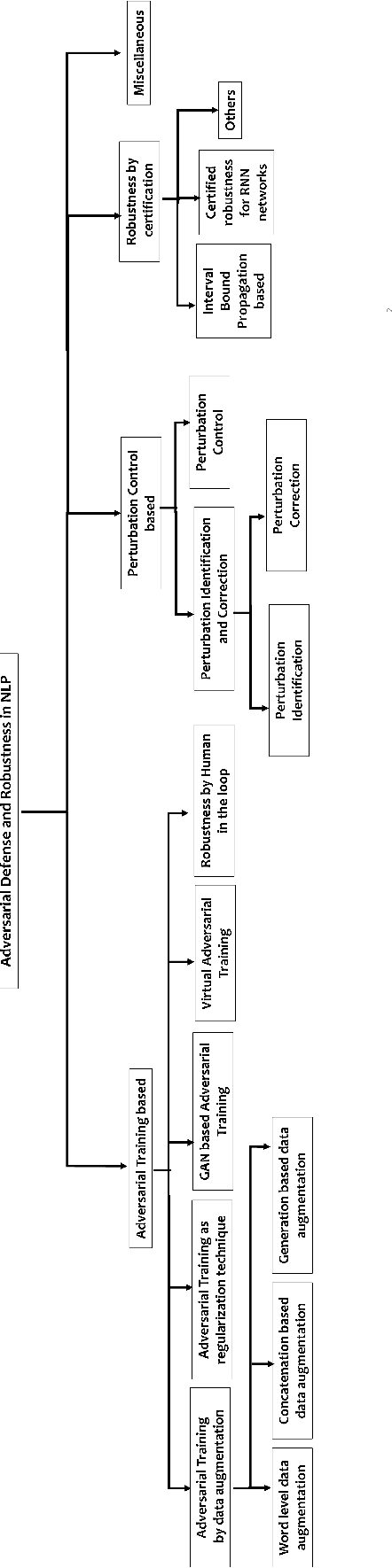
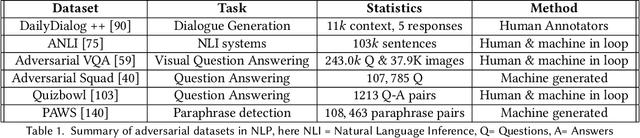
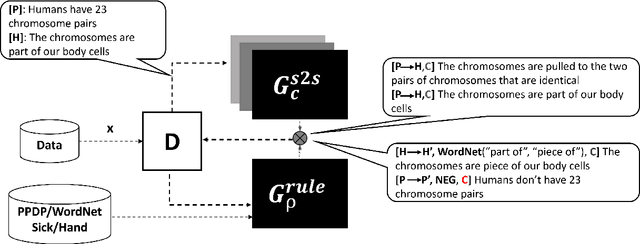

In recent years, it has been seen that deep neural networks are lacking robustness and are likely to break in case of adversarial perturbations in input data. Strong adversarial attacks are proposed by various authors for computer vision and Natural Language Processing (NLP). As a counter-effort, several defense mechanisms are also proposed to save these networks from failing. In contrast with image data, generating adversarial attacks and defending these models is not easy in NLP because of the discrete nature of the text data. However, numerous methods for adversarial defense are proposed of late, for different NLP tasks such as text classification, named entity recognition, natural language inferencing, etc. These methods are not just used for defending neural networks from adversarial attacks, but also used as a regularization mechanism during training, saving the model from overfitting. The proposed survey is an attempt to review different methods proposed for adversarial defenses in NLP in the recent past by proposing a novel taxonomy. This survey also highlights the fragility of the advanced deep neural networks in NLP and the challenges in defending them.
Contrastive Visual Semantic Pretraining Magnifies the Semantics of Natural Language Representations
Mar 14, 2022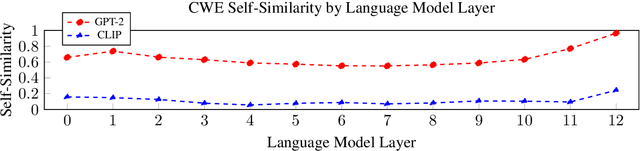
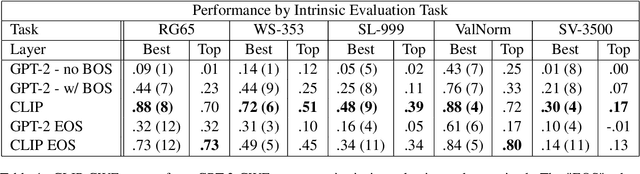
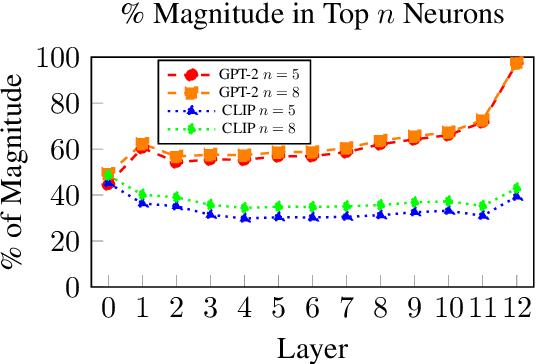
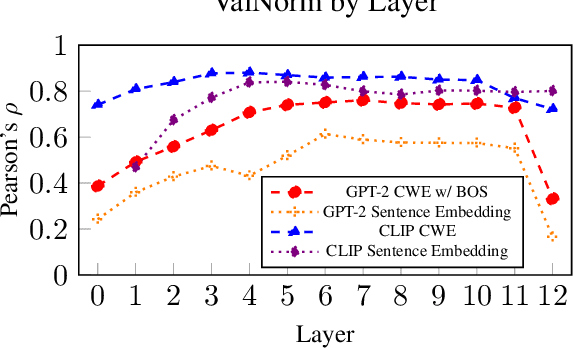
We examine the effects of contrastive visual semantic pretraining by comparing the geometry and semantic properties of contextualized English language representations formed by GPT-2 and CLIP, a zero-shot multimodal image classifier which adapts the GPT-2 architecture to encode image captions. We find that contrastive visual semantic pretraining significantly mitigates the anisotropy found in contextualized word embeddings from GPT-2, such that the intra-layer self-similarity (mean pairwise cosine similarity) of CLIP word embeddings is under .25 in all layers, compared to greater than .95 in the top layer of GPT-2. CLIP word embeddings outperform GPT-2 on word-level semantic intrinsic evaluation tasks, and achieve a new corpus-based state of the art for the RG65 evaluation, at .88. CLIP also forms fine-grained semantic representations of sentences, and obtains Spearman's rho = .73 on the SemEval-2017 Semantic Textual Similarity Benchmark with no fine-tuning, compared to no greater than rho = .45 in any layer of GPT-2. Finally, intra-layer self-similarity of CLIP sentence embeddings decreases as the layer index increases, finishing at .25 in the top layer, while the self-similarity of GPT-2 sentence embeddings formed using the EOS token increases layer-over-layer and never falls below .97. Our results indicate that high anisotropy is not an inevitable consequence of contextualization, and that visual semantic pretraining is beneficial not only for ordering visual representations, but also for encoding useful semantic representations of language, both on the word level and the sentence level.
Domain-Smoothing Network for Zero-Shot Sketch-Based Image Retrieval
Jun 22, 2021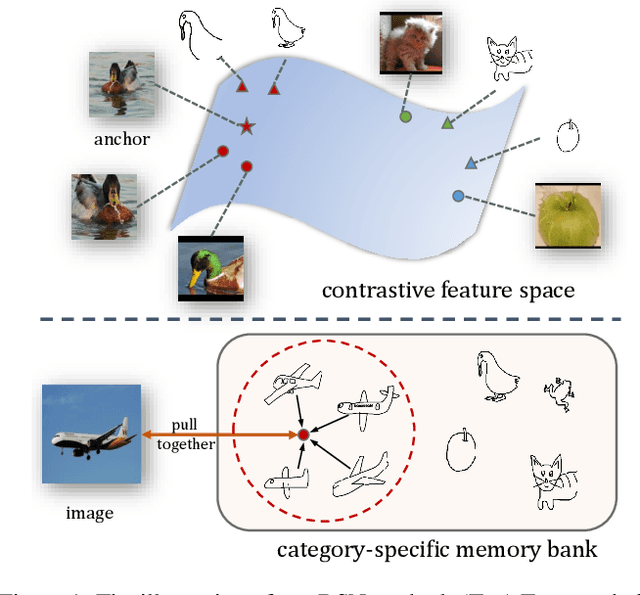
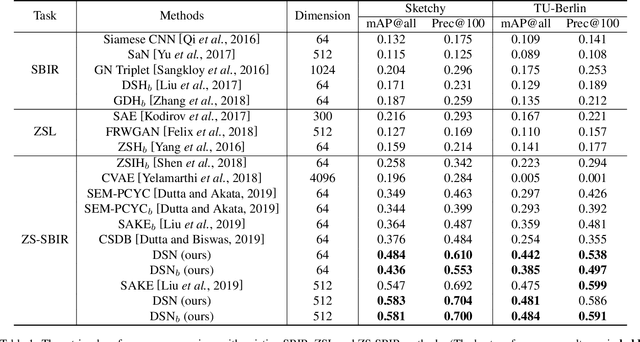
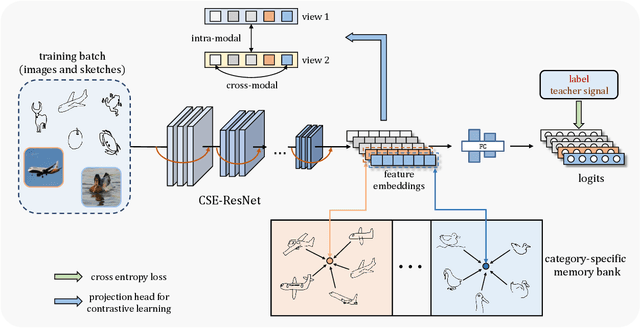
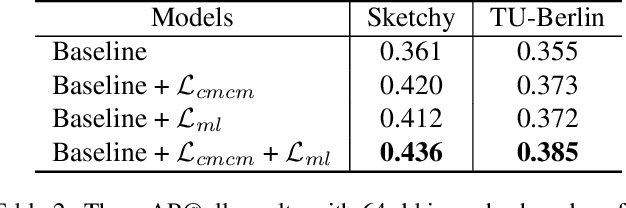
Zero-Shot Sketch-Based Image Retrieval (ZS-SBIR) is a novel cross-modal retrieval task, where abstract sketches are used as queries to retrieve natural images under zero-shot scenario. Most existing methods regard ZS-SBIR as a traditional classification problem and employ a cross-entropy or triplet-based loss to achieve retrieval, which neglect the problems of the domain gap between sketches and natural images and the large intra-class diversity in sketches. Toward this end, we propose a novel Domain-Smoothing Network (DSN) for ZS-SBIR. Specifically, a cross-modal contrastive method is proposed to learn generalized representations to smooth the domain gap by mining relations with additional augmented samples. Furthermore, a category-specific memory bank with sketch features is explored to reduce intra-class diversity in the sketch domain. Extensive experiments demonstrate that our approach notably outperforms the state-of-the-art methods in both Sketchy and TU-Berlin datasets. Our source code is publicly available at https://github.com/haowang1992/DSN.
Neural network processing of holographic images
Mar 18, 2022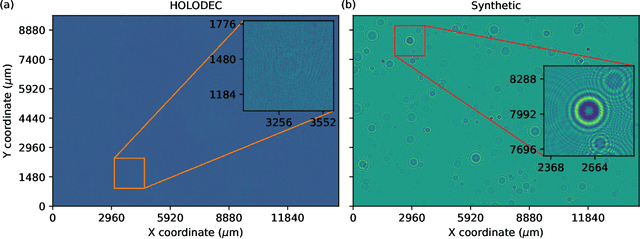
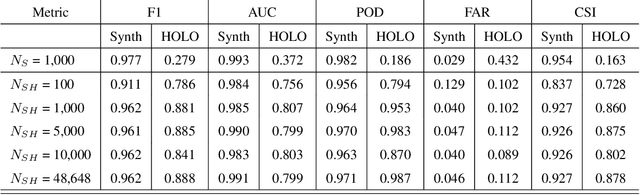
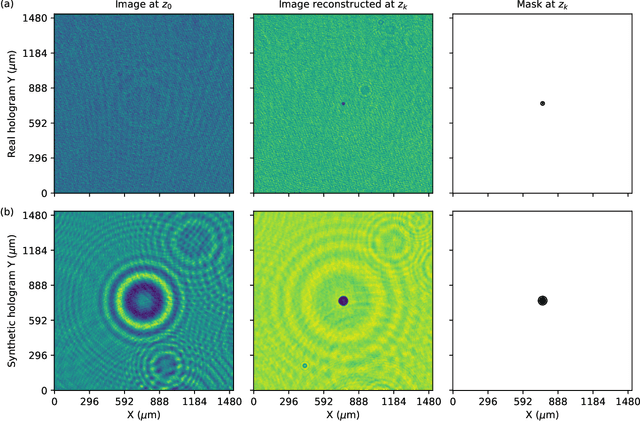
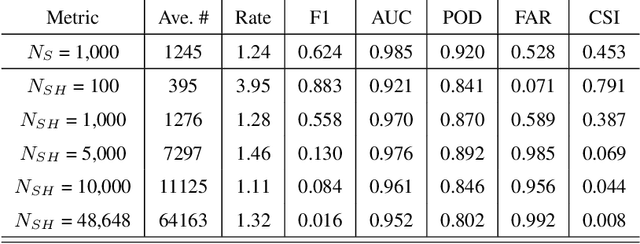
HOLODEC, an airborne cloud particle imager, captures holographic images of a fixed volume of cloud to characterize the types and sizes of cloud particles, such as water droplets and ice crystals. Cloud particle properties include position, diameter, and shape. We present a hologram processing algorithm, HolodecML, that utilizes a neural segmentation model, GPUs, and computational parallelization. HolodecML is trained using synthetically generated holograms based on a model of the instrument, and predicts masks around particles found within reconstructed images. From these masks, the position and size of the detected particles can be characterized in three dimensions. In order to successfully process real holograms, we find we must apply a series of image corrupting transformations and noise to the synthetic images used in training. In this evaluation, HolodecML had comparable position and size estimation performance to the standard processing method, but improved particle detection by nearly 20\% on several thousand manually labeled HOLODEC images. However, the improvement only occurred when image corruption was performed on the simulated images during training, thereby mimicking non-ideal conditions in the actual probe. The trained model also learned to differentiate artifacts and other impurities in the HOLODEC images from the particles, even though no such objects were present in the training data set, while the standard processing method struggled to separate particles from artifacts. The novelty of the training approach, which leveraged noise as a means for parameterizing non-ideal aspects of the HOLODEC detector, could be applied in other domains where the theoretical model is incapable of fully describing the real-world operation of the instrument and accurate truth data required for supervised learning cannot be obtained from real-world observations.
Pho(SC)Net: An Approach Towards Zero-shot Word Image Recognition in Historical Documents
May 31, 2021
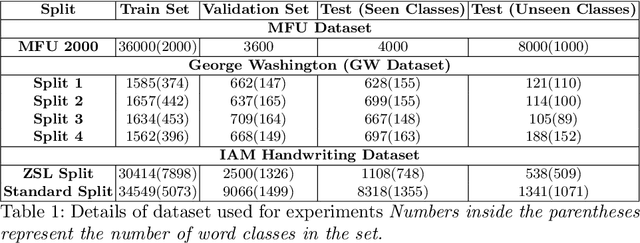

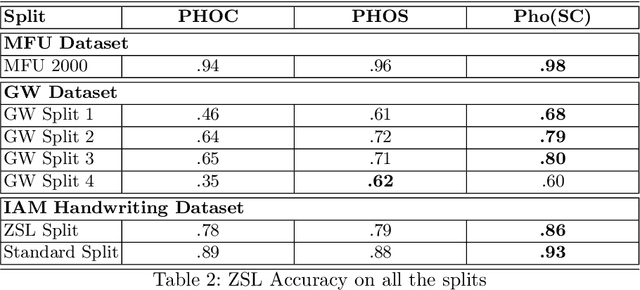
Annotating words in a historical document image archive for word image recognition purpose demands time and skilled human resource (like historians, paleographers). In a real-life scenario, obtaining sample images for all possible words is also not feasible. However, Zero-shot learning methods could aptly be used to recognize unseen/out-of-lexicon words in such historical document images. Based on previous state-of-the-art methods for word spotting and recognition, we propose a hybrid representation that considers the character's shape appearance to differentiate between two different words and has shown to be more effective in recognizing unseen words. This representation has been termed as Pyramidal Histogram of Shapes (PHOS), derived from PHOC, which embeds information about the occurrence and position of characters in the word. Later, the two representations are combined and experiments were conducted to examine the effectiveness of an embedding that has properties of both PHOS and PHOC. Encouraging results were obtained on two publicly available historical document datasets and one synthetic handwritten dataset, which justifies the efficacy of "Phos" and the combined "Pho(SC)" representation.
Perception Visualization: Seeing Through the Eyes of a DNN
Apr 21, 2022
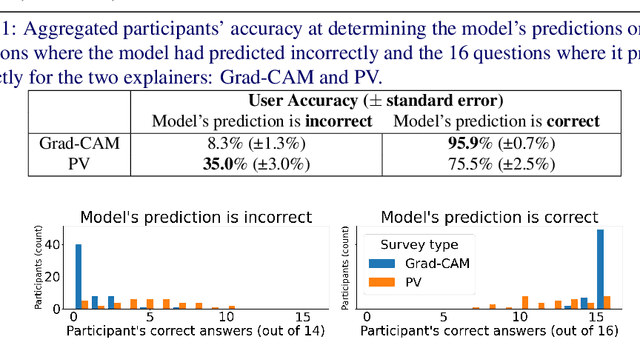

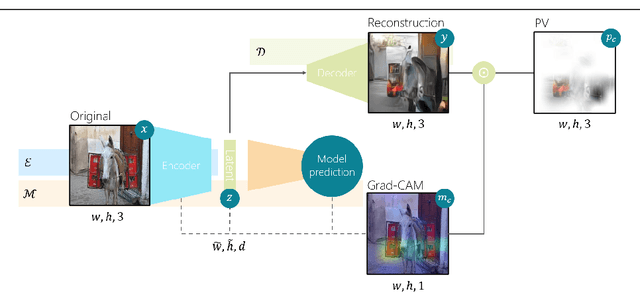
Artificial intelligence (AI) systems power the world we live in. Deep neural networks (DNNs) are able to solve tasks in an ever-expanding landscape of scenarios, but our eagerness to apply these powerful models leads us to focus on their performance and deprioritises our ability to understand them. Current research in the field of explainable AI tries to bridge this gap by developing various perturbation or gradient-based explanation techniques. For images, these techniques fail to fully capture and convey the semantic information needed to elucidate why the model makes the predictions it does. In this work, we develop a new form of explanation that is radically different in nature from current explanation methods, such as Grad-CAM. Perception visualization provides a visual representation of what the DNN perceives in the input image by depicting what visual patterns the latent representation corresponds to. Visualizations are obtained through a reconstruction model that inverts the encoded features, such that the parameters and predictions of the original models are not modified. Results of our user study demonstrate that humans can better understand and predict the system's decisions when perception visualizations are available, thus easing the debugging and deployment of deep models as trusted systems.