 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
What's in your hands? 3D Reconstruction of Generic Objects in Hands
Apr 14, 2022

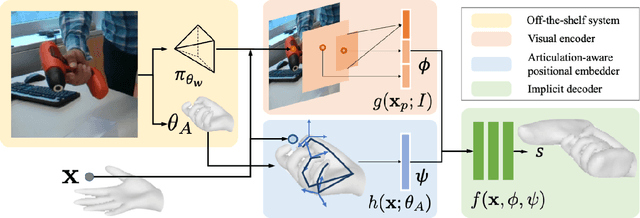

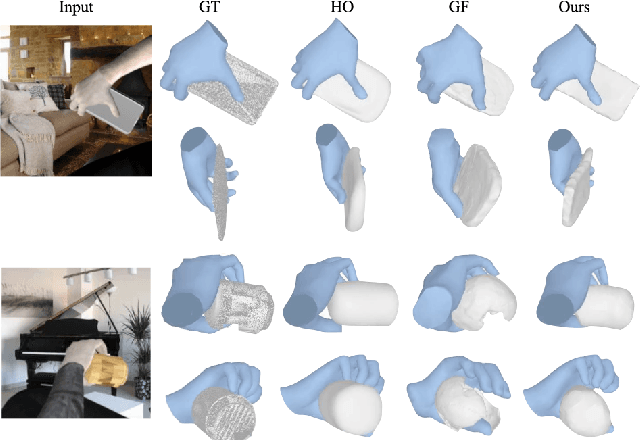
Our work aims to reconstruct hand-held objects given a single RGB image. In contrast to prior works that typically assume known 3D templates and reduce the problem to 3D pose estimation, our work reconstructs generic hand-held object without knowing their 3D templates. Our key insight is that hand articulation is highly predictive of the object shape, and we propose an approach that conditionally reconstructs the object based on the articulation and the visual input. Given an image depicting a hand-held object, we first use off-the-shelf systems to estimate the underlying hand pose and then infer the object shape in a normalized hand-centric coordinate frame. We parameterized the object by signed distance which are inferred by an implicit network which leverages the information from both visual feature and articulation-aware coordinates to process a query point. We perform experiments across three datasets and show that our method consistently outperforms baselines and is able to reconstruct a diverse set of objects. We analyze the benefits and robustness of explicit articulation conditioning and also show that this allows the hand pose estimation to further improve in test-time optimization.
Light Field Raindrop Removal via 4D Re-sampling
May 26, 2022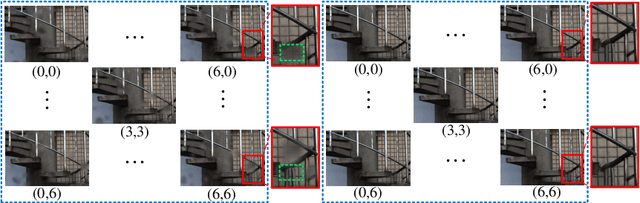


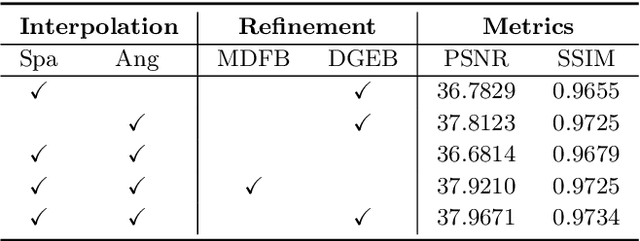
The Light Field Raindrop Removal (LFRR) aims to restore the background areas obscured by raindrops in the Light Field (LF). Compared with single image, the LF provides more abundant information by regularly and densely sampling the scene. Since raindrops have larger disparities than the background in the LF, the majority of texture details occluded by raindrops are visible in other views. In this paper, we propose a novel LFRR network by directly utilizing the complementary pixel information of raindrop-free areas in the input raindrop LF, which consists of the re-sampling module and the refinement module. Specifically, the re-sampling module generates a new LF which is less polluted by raindrops through re-sampling position predictions and the proposed 4D interpolation. The refinement module improves the restoration of the completely occluded background areas and corrects the pixel error caused by 4D interpolation. Furthermore, we carefully build the first real scene LFRR dataset for model training and validation. Experiments demonstrate that the proposed method can effectively remove raindrops and achieves state-of-the-art performance in both background restoration and view consistency maintenance.
Median Pixel Difference Convolutional Network for Robust Face Recognition
May 30, 2022
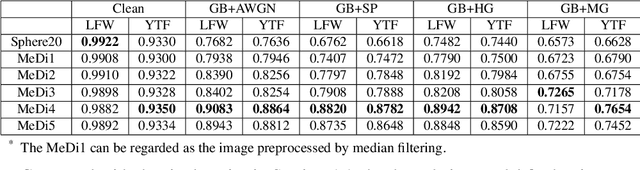
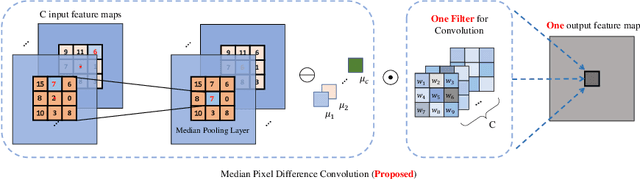
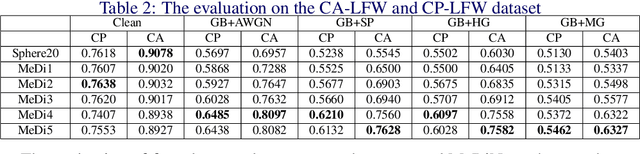
Face recognition is one of the most active tasks in computer vision and has been widely used in the real world. With great advances made in convolutional neural networks (CNN), lots of face recognition algorithms have achieved high accuracy on various face datasets. However, existing face recognition algorithms based on CNNs are vulnerable to noise. Noise corrupted image patterns could lead to false activations, significantly decreasing face recognition accuracy in noisy situations. To equip CNNs with built-in robustness to noise of different levels, we proposed a Median Pixel Difference Convolutional Network (MeDiNet) by replacing some traditional convolutional layers with the proposed novel Median Pixel Difference Convolutional Layer (MeDiConv) layer. The proposed MeDiNet integrates the idea of traditional multiscale median filtering with deep CNNs. The MeDiNet is tested on the four face datasets (LFW, CA-LFW, CP-LFW, and YTF) with versatile settings on blur kernels, noise intensities, scales, and JPEG quality factors. Extensive experiments show that our MeDiNet can effectively remove noisy pixels in the feature map and suppress the negative impact of noise, leading to achieving limited accuracy loss under these practical noises compared with the standard CNN under clean conditions.
Improving the Thermal Infrared Monitoring of Volcanoes: A Deep Learning Approach for Intermittent Image Series
Sep 27, 2021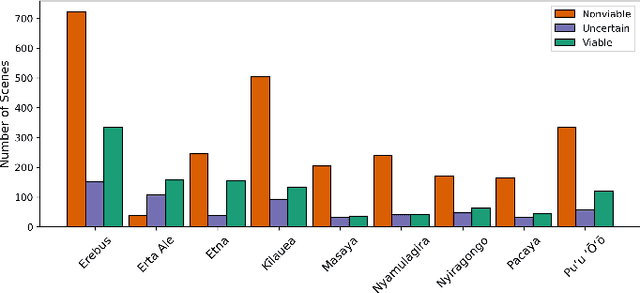
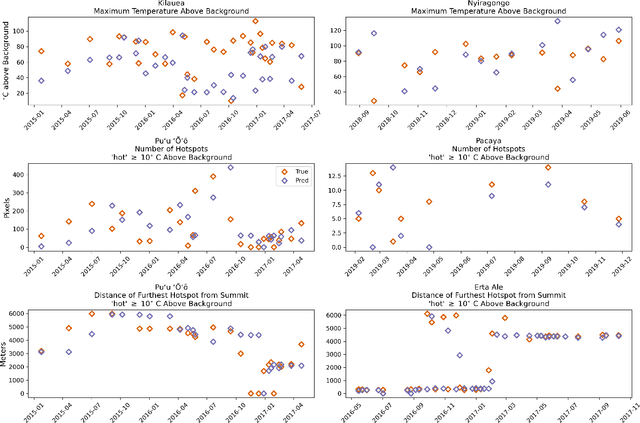
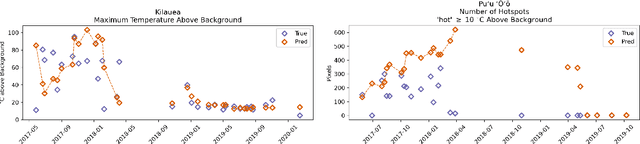

Active volcanoes are globally distributed and pose societal risks at multiple geographic scales, ranging from local hazards to regional/international disruptions. Many volcanoes do not have continuous ground monitoring networks; meaning that satellite observations provide the only record of volcanic behavior and unrest. Among these remote sensing observations, thermal imagery is inspected daily by volcanic observatories for examining the early signs, onset, and evolution of eruptive activity. However, thermal scenes are often obstructed by clouds, meaning that forecasts must be made off image sequences whose scenes are only usable intermittently through time. Here, we explore forecasting this thermal data stream from a deep learning perspective using existing architectures that model sequences with varying spatiotemporal considerations. Additionally, we propose and evaluate new architectures that explicitly model intermittent image sequences. Using ASTER Kinetic Surface Temperature data for $9$ volcanoes between $1999$ and $2020$, we found that a proposed architecture (ConvLSTM + Time-LSTM + U-Net) forecasts volcanic temperature imagery with the lowest RMSE ($4.164^{\circ}$C, other methods: $4.217-5.291^{\circ}$C). Additionally, we examined performance on multiple time series derived from the thermal imagery and the effect of training with data from singular volcanoes. Ultimately, we found that models with the lowest RMSE on forecasting imagery did not possess the lowest RMSE on recreating time series derived from that imagery and that training with individual volcanoes generally worsened performance relative to a multi-volcano data set. This work highlights the potential of data-driven deep learning models for volcanic unrest forecasting while revealing the need for carefully constructed optimization targets.
Effects of Image Size on Deep Learning
Jan 27, 2021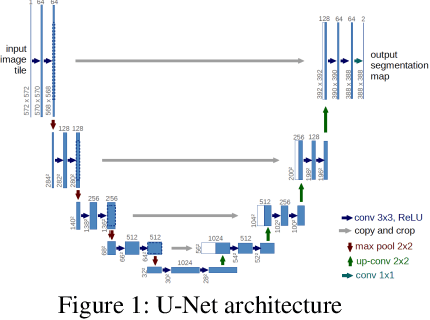

The question is: what size of the region of interest is likely to lead to better training outcomes? To answer this: The U-net is used for semantic segmentation. Image interpolation algorithms are used to double the cropped image size and create new datasets. Depending on the selected image interpolation algorithm category, non-original classes are created in the ground truth images thus a filtering strategy is introduced to remove such spurious classes. Evaluation results of effects on the myocardium segmentation and quantification of the myocardial infarction are provided and discussed.
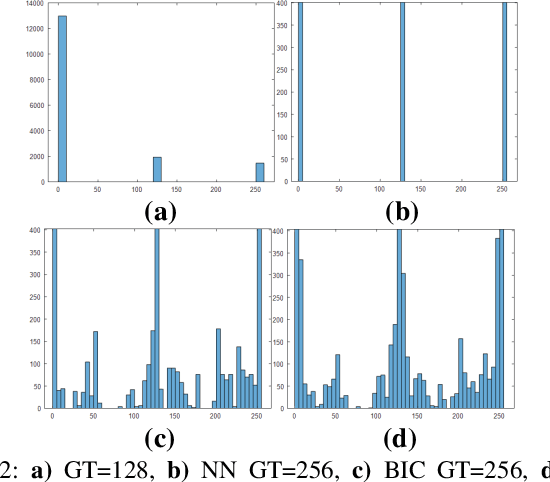
RPLHR-CT Dataset and Transformer Baseline for Volumetric Super-Resolution from CT Scans
Jun 13, 2022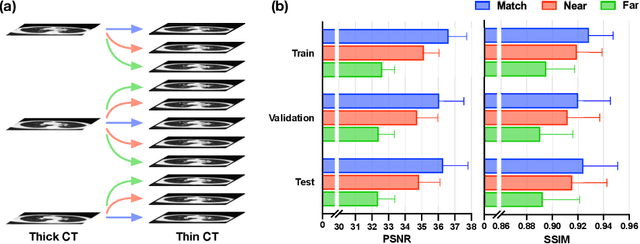
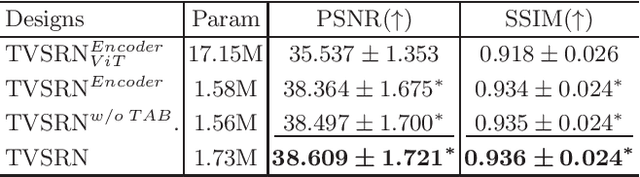
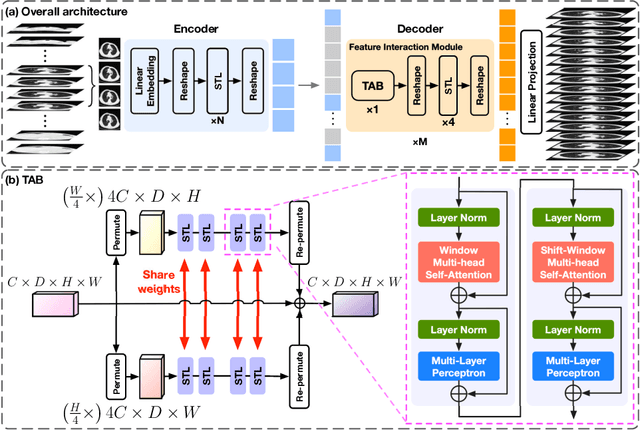
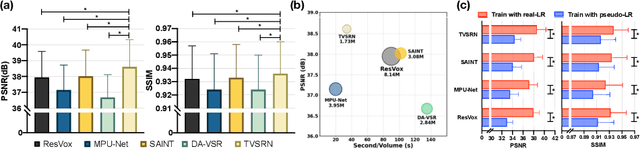
In clinical practice, anisotropic volumetric medical images with low through-plane resolution are commonly used due to short acquisition time and lower storage cost. Nevertheless, the coarse resolution may lead to difficulties in medical diagnosis by either physicians or computer-aided diagnosis algorithms. Deep learning-based volumetric super-resolution (SR) methods are feasible ways to improve resolution, with convolutional neural networks (CNN) at their core. Despite recent progress, these methods are limited by inherent properties of convolution operators, which ignore content relevance and cannot effectively model long-range dependencies. In addition, most of the existing methods use pseudo-paired volumes for training and evaluation, where pseudo low-resolution (LR) volumes are generated by a simple degradation of their high-resolution (HR) counterparts. However, the domain gap between pseudo- and real-LR volumes leads to the poor performance of these methods in practice. In this paper, we build the first public real-paired dataset RPLHR-CT as a benchmark for volumetric SR, and provide baseline results by re-implementing four state-of-the-art CNN-based methods. Considering the inherent shortcoming of CNN, we also propose a transformer volumetric super-resolution network (TVSRN) based on attention mechanisms, dispensing with convolutions entirely. This is the first research to use a pure transformer for CT volumetric SR. The experimental results show that TVSRN significantly outperforms all baselines on both PSNR and SSIM. Moreover, the TVSRN method achieves a better trade-off between the image quality, the number of parameters, and the running time. Data and code are available at https://github.com/smilenaxx/RPLHR-CT.
VizInspect Pro -- Automated Optical Inspection (AOI) solution
May 26, 2022Traditional vision based Automated Optical Inspection (referred to as AOI in paper) systems present multiple challenges in factory settings including inability to scale across multiple product lines, requirement of vendor programming expertise, little tolerance to variations and lack of cloud connectivity for aggregated insights. The lack of flexibility in these systems presents a unique opportunity for a deep learning based AOI system specifically for factory automation. The proposed solution, VizInspect pro is a generic computer vision based AOI solution built on top of Leo - An edge AI platform. Innovative features that overcome challenges of traditional vision systems include deep learning based image analysis which combines the power of self-learning with high speed and accuracy, an intuitive user interface to configure inspection profiles in minutes without ML or vision expertise and the ability to solve complex inspection challenges while being tolerant to deviations and unpredictable defects. This solution has been validated by multiple external enterprise customers with confirmed value propositions. In this paper we show you how this solution and platform solved problems around model development, deployment, scaling multiple inferences and visualizations.
A New Backbone for Hyperspectral Image Reconstruction
Aug 17, 2021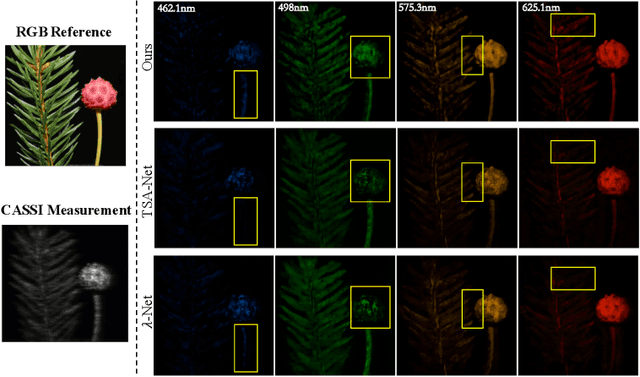



The study of 3D hyperspectral image (HSI) reconstruction refers to the inverse process of snapshot compressive imaging, during which the optical system, e.g., the coded aperture snapshot spectral imaging (CASSI) system, captures the 3D spatial-spectral signal and encodes it to a 2D measurement. While numerous sophisticated neural networks have been elaborated for end-to-end reconstruction, trade-offs still need to be made among performance, efficiency (training and inference time), and feasibility (the ability of restoring high resolution HSI on limited GPU memory). This raises a challenge to design a new baseline to conjointly meet the above requirements. In this paper, we fill in this blank by proposing a Spatial/Spectral Invariant Residual U-Net, namely SSI-ResU-Net. It differentiates with U-Net in three folds--1) scale/spectral-invariant learning, 2) nested residual learning, and 3) computational efficiency. Benefiting from these three modules, the proposed SSI-ResU-Net outperforms the current state-of-the-art method TSA-Net by over 3 dB in PSNR and 0.036 in SSIM while only using 2.82% trainable parameters. To the greatest extent, SSI-ResU-Net achieves competing performance with over 77.3% reduction in terms of floating-point operations (FLOPs), which for the first time, makes high-resolution HSI reconstruction feasible under practical application scenarios. Code and pre-trained models are made available at https://github.com/Jiamian-Wang/HSI_baseline.
New Image Captioning Encoder via Semantic Visual Feature Matching for Heavy Rain Images
May 31, 2021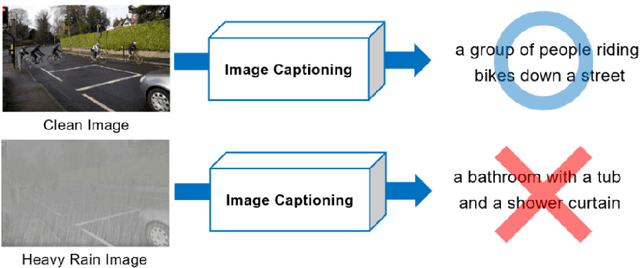
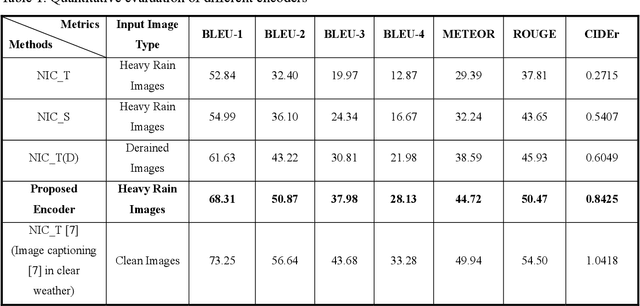

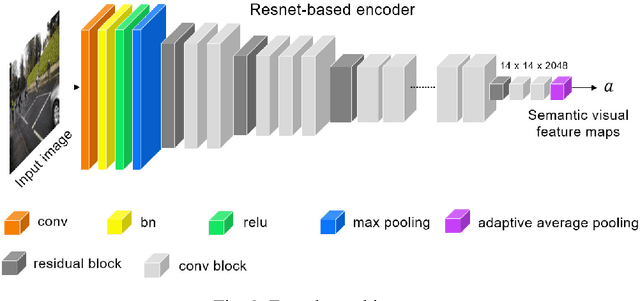
Image captioning generates text that describes scenes from input images. It has been developed for high quality images taken in clear weather. However, in bad weather conditions, such as heavy rain, snow, and dense fog, the poor visibility owing to rain streaks, rain accumulation, and snowflakes causes a serious degradation of image quality. This hinders the extraction of useful visual features and results in deteriorated image captioning performance. To address practical issues, this study introduces a new encoder for captioning heavy rain images. The central idea is to transform output features extracted from heavy rain input images into semantic visual features associated with words and sentence context. To achieve this, a target encoder is initially trained in an encoder-decoder framework to associate visual features with semantic words. Subsequently, the objects in a heavy rain image are rendered visible by using an initial reconstruction subnetwork (IRS) based on a heavy rain model. The IRS is then combined with another semantic visual feature matching subnetwork (SVFMS) to match the output features of the IRS with the semantic visual features of the pretrained target encoder. The proposed encoder is based on the joint learning of the IRS and SVFMS. It is is trained in an end-to-end manner, and then connected to the pretrained decoder for image captioning. It is experimentally demonstrated that the proposed encoder can generate semantic visual features associated with words even from heavy rain images, thereby increasing the accuracy of the generated captions.
Restricted Black-box Adversarial Attack Against DeepFake Face Swapping
Apr 26, 2022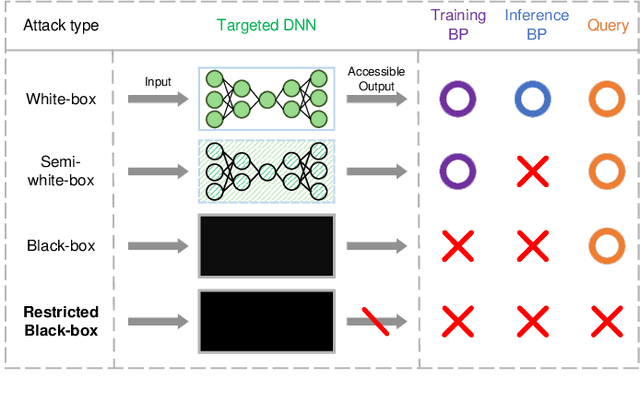
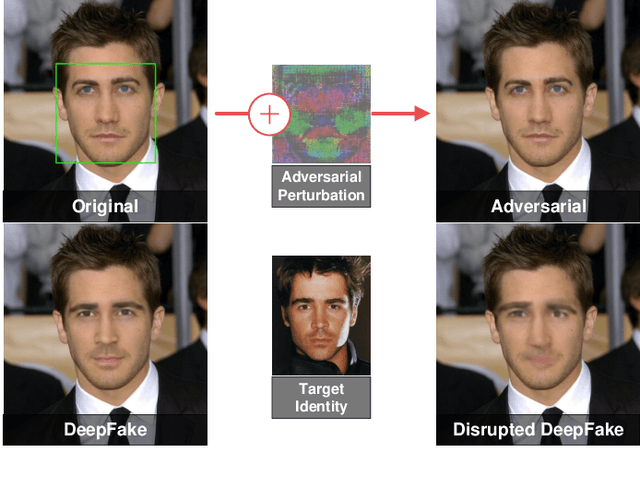
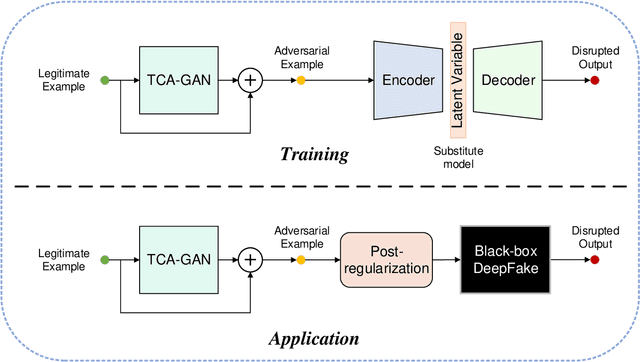
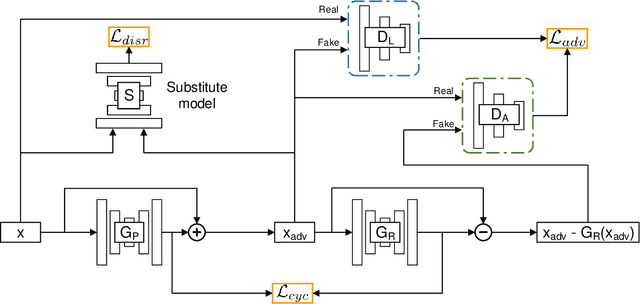
DeepFake face swapping presents a significant threat to online security and social media, which can replace the source face in an arbitrary photo/video with the target face of an entirely different person. In order to prevent this fraud, some researchers have begun to study the adversarial methods against DeepFake or face manipulation. However, existing works focus on the white-box setting or the black-box setting driven by abundant queries, which severely limits the practical application of these methods. To tackle this problem, we introduce a practical adversarial attack that does not require any queries to the facial image forgery model. Our method is built on a substitute model persuing for face reconstruction and then transfers adversarial examples from the substitute model directly to inaccessible black-box DeepFake models. Specially, we propose the Transferable Cycle Adversary Generative Adversarial Network (TCA-GAN) to construct the adversarial perturbation for disrupting unknown DeepFake systems. We also present a novel post-regularization module for enhancing the transferability of generated adversarial examples. To comprehensively measure the effectiveness of our approaches, we construct a challenging benchmark of DeepFake adversarial attacks for future development. Extensive experiments impressively show that the proposed adversarial attack method makes the visual quality of DeepFake face images plummet so that they are easier to be detected by humans and algorithms. Moreover, we demonstrate that the proposed algorithm can be generalized to offer face image protection against various face translation methods.