 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Representation Learning for 3D MRI Super Resolution with Degradation Adaptation
May 13, 2022
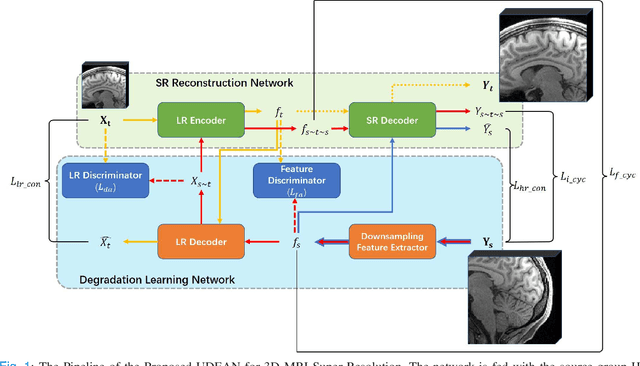
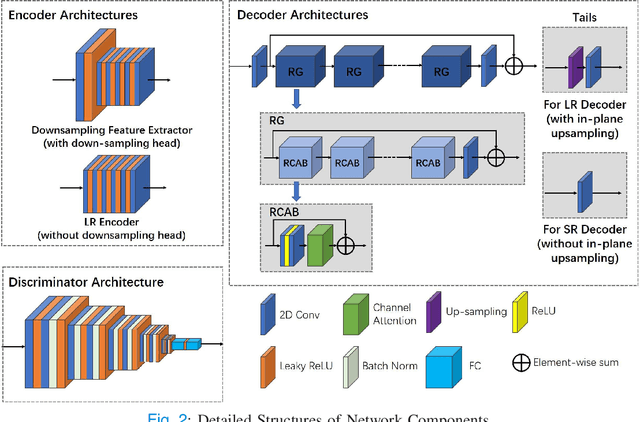
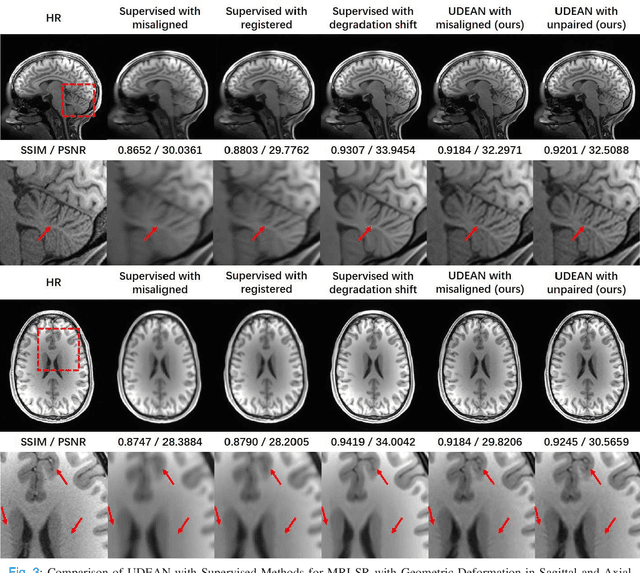
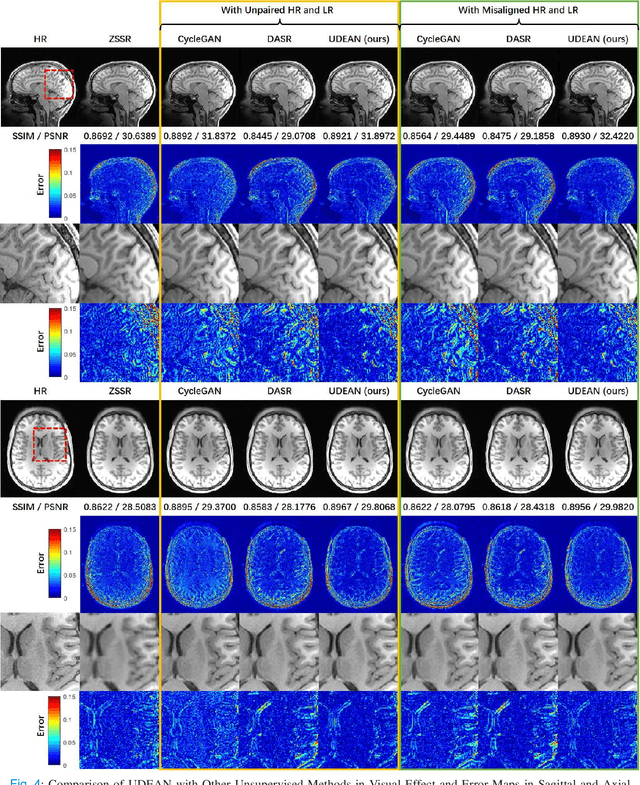
High-resolution (HR) MRI is critical in assisting the doctor's diagnosis and image-guided treatment, but is hard to obtain in a clinical setting due to long acquisition time. Therefore, the research community investigated deep learning-based super-resolution (SR) technology to reconstruct HR MRI images with shortened acquisition time. However, training such neural networks usually requires paired HR and low-resolution (LR) in-vivo images, which are difficult to acquire due to patient movement during and between the image acquisition. Rigid movements of hard tissues can be corrected with image-registration, whereas the alignment of deformed soft tissues is challenging, making it impractical to train the neural network with such authentic HR and LR image pairs. Therefore, most of the previous studies proposed SR reconstruction by employing authentic HR images and synthetic LR images downsampled from the HR images, yet the difference in degradation representations between synthetic and authentic LR images suppresses the performance of SR reconstruction from authentic LR images. To mitigate the aforementioned problems, we propose a novel Unsupervised DEgradation Adaptation Network (UDEAN). Our model consists of two components: the degradation learning network and the SR reconstruction network. The degradation learning network downsamples the HR images by addressing the degradation representation of the misaligned or unpaired LR images, and the SR reconstruction network learns the mapping from the downsampled HR images to their original HR images. As a result, the SR reconstruction network can generate SR images from the LR images and achieve comparable quality to the HR images. Experimental results show that our method outperforms the state-of-the-art models and can potentially be applied in real-world clinical settings.
Fourier Transform Approximation as an Auxiliary Task for Image Classification
Jul 01, 2021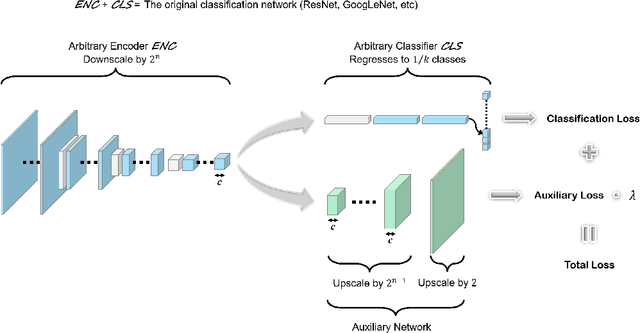
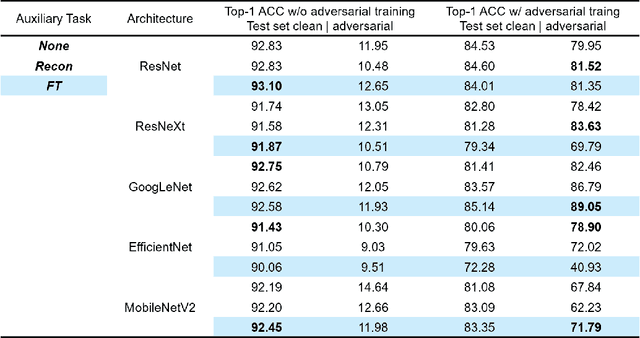
Image reconstruction is likely the most predominant auxiliary task for image classification, but we would like to think twice about this convention. In this paper, we investigated "approximating the Fourier Transform of the input image" as a potential alternative, in the hope that it may further boost the performances on the primary task or introduce novel constraints not well covered by image reconstruction. We experimented with five popular classification architectures on the CIFAR-10 dataset, and the empirical results indicated that our proposed auxiliary task generally improves the classification accuracy. More notably, the results showed that in certain cases our proposed auxiliary task may enhance the classifiers' resistance to adversarial attacks generated using the fast gradient sign method.
The Importance of the Instantaneous Phase for classification using Convolutional Neural Networks
Jul 01, 2022



Large-scale training of Convolutional Neural Networks (CNN) is extremely demanding in terms of computational resources. Also, for specific applications, the standard use of transfer learning also tends to require far more resources than what may be needed. This work examines the impact of using AM-FM representations as input images for CNN classification applications. A comparison was made between AM-FM components combinations and grayscale images as inputs for reduced and complete networks. The results showed that only the phase component produced significant predictions within a simple network. Neither IA or gray scale image were able to induce any learning in the system. Furthermore, the FM results were 7x faster during training and used 123x less parameters compared to state-of-the-art MobileNetV2 architecture, while maintaining comparable performance (AUC of 0.78 vs 0.79).
3D Clothed Human Reconstruction in the Wild
Jul 20, 2022
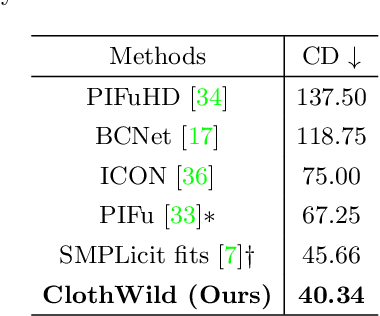
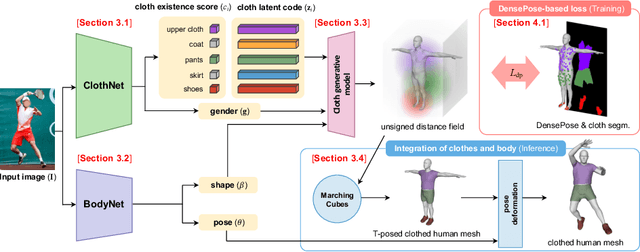
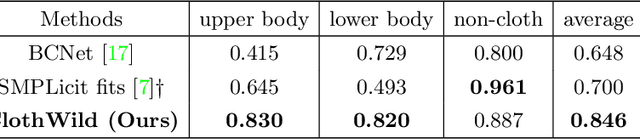
Although much progress has been made in 3D clothed human reconstruction, most of the existing methods fail to produce robust results from in-the-wild images, which contain diverse human poses and appearances. This is mainly due to the large domain gap between training datasets and in-the-wild datasets. The training datasets are usually synthetic ones, which contain rendered images from GT 3D scans. However, such datasets contain simple human poses and less natural image appearances compared to those of real in-the-wild datasets, which makes generalization of it to in-the-wild images extremely challenging. To resolve this issue, in this work, we propose ClothWild, a 3D clothed human reconstruction framework that firstly addresses the robustness on in-thewild images. First, for the robustness to the domain gap, we propose a weakly supervised pipeline that is trainable with 2D supervision targets of in-the-wild datasets. Second, we design a DensePose-based loss function to reduce ambiguities of the weak supervision. Extensive empirical tests on several public in-the-wild datasets demonstrate that our proposed ClothWild produces much more accurate and robust results than the state-of-the-art methods. The codes are available in here: https://github.com/hygenie1228/ClothWild_RELEASE.
Parallel Structure from Motion for UAV Images via Weighted Connected Dominating Set
Jun 23, 2022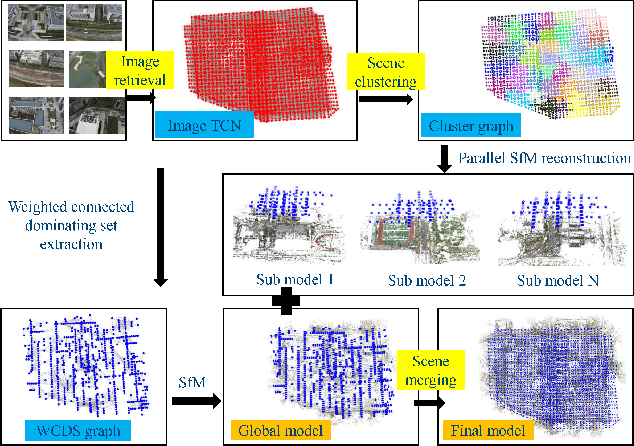

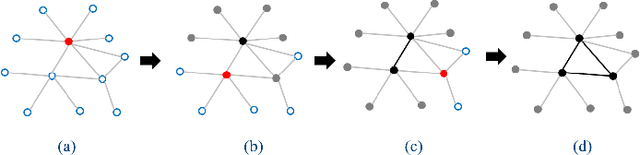
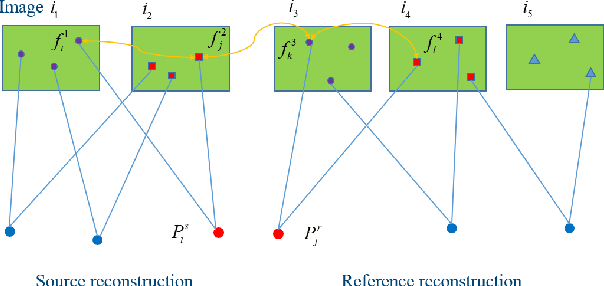
Incremental Structure from Motion (ISfM) has been widely used for UAV image orientation. Its efficiency, however, decreases dramatically due to the sequential constraint. Although the divide-and-conquer strategy has been utilized for efficiency improvement, cluster merging becomes difficult or depends on seriously designed overlap structures. This paper proposes an algorithm to extract the global model for cluster merging and designs a parallel SfM solution to achieve efficient and accurate UAV image orientation. First, based on vocabulary tree retrieval, match pairs are selected to construct an undirected weighted match graph, whose edge weights are calculated by considering both the number and distribution of feature matches. Second, an algorithm, termed weighted connected dominating set (WCDS), is designed to achieve the simplification of the match graph and build the global model, which incorporates the edge weight in the graph node selection and enables the successful reconstruction of the global model. Third, the match graph is simultaneously divided into compact and non-overlapped clusters. After the parallel reconstruction, cluster merging is conducted with the aid of common 3D points between the global and cluster models. Finally, by using three UAV datasets that are captured by classical oblique and recent optimized views photogrammetry, the validation of the proposed solution is verified through comprehensive analysis and comparison. The experimental results demonstrate that the proposed parallel SfM can achieve 17.4 times efficiency improvement and comparative orientation accuracy. In absolute BA, the geo-referencing accuracy is approximately 2.0 and 3.0 times the GSD (Ground Sampling Distance) value in the horizontal and vertical directions, respectively. For parallel SfM, the proposed solution is a more reliable alternative.
Text-Aware Single Image Specular Highlight Removal
Aug 16, 2021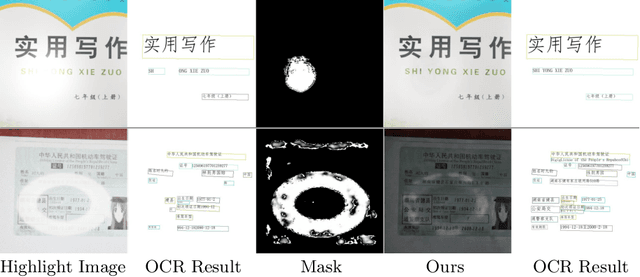
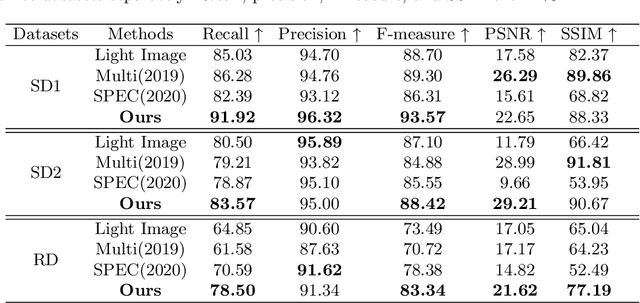

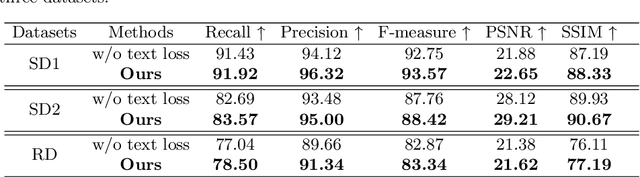
Removing undesirable specular highlight from a single input image is of crucial importance to many computer vision and graphics tasks. Existing methods typically remove specular highlight for medical images and specific-object images, however, they cannot handle the images with text. In addition, the impact of specular highlight on text recognition is rarely studied by text detection and recognition community. Therefore, in this paper, we first raise and study the text-aware single image specular highlight removal problem. The core goal is to improve the accuracy of text detection and recognition by removing the highlight from text images. To tackle this challenging problem, we first collect three high-quality datasets with fine-grained annotations, which will be appropriately released to facilitate the relevant research. Then, we design a novel two-stage network, which contains a highlight detection network and a highlight removal network. The output of highlight detection network provides additional information about highlight regions to guide the subsequent highlight removal network. Moreover, we suggest a measurement set including the end-to-end text detection and recognition evaluation and auxiliary visual quality evaluation. Extensive experiments on our collected datasets demonstrate the superior performance of the proposed method.
Virus-MNIST: Machine Learning Baseline Calculations for Image Classification
Nov 03, 2021
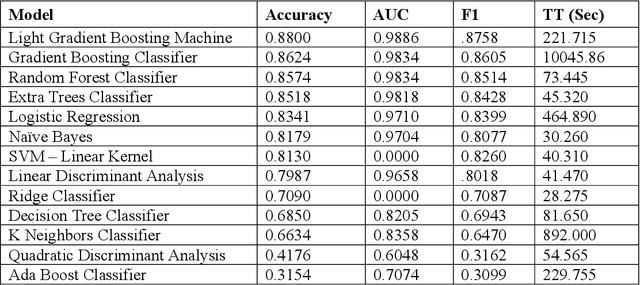
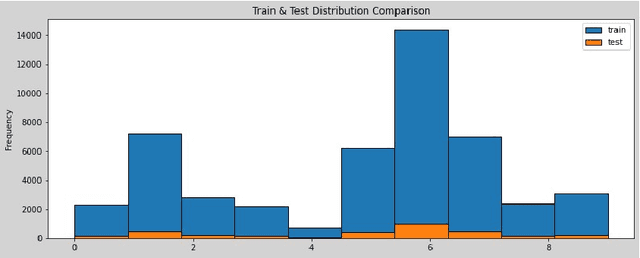

The Virus-MNIST data set is a collection of thumbnail images that is similar in style to the ubiquitous MNIST hand-written digits. These, however, are cast by reshaping possible malware code into an image array. Naturally, it is poised to take on a role in benchmarking progress of virus classifier model training. Ten types are present: nine classified as malware and one benign. Cursory examination reveals unequal class populations and other key aspects that must be considered when selecting classification and pre-processing methods. Exploratory analyses show possible identifiable characteristics from aggregate metrics (e.g., the pixel median values), and ways to reduce the number of features by identifying strong correlations. A model comparison shows that Light Gradient Boosting Machine, Gradient Boosting Classifier, and Random Forest algorithms produced the highest accuracy scores, thus showing promise for deeper scrutiny.
A Deep Variational Bayesian Framework for Blind Image Deblurring
Jun 05, 2021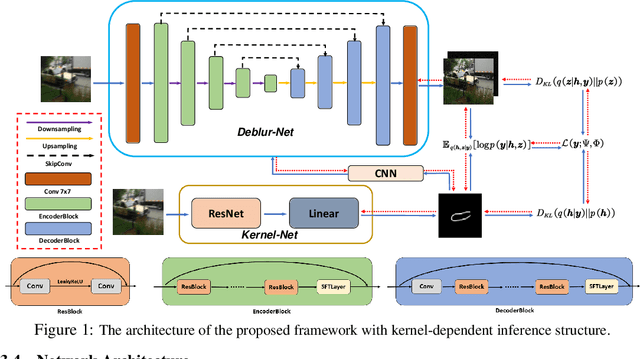



Blind image deblurring is an important yet very challenging problem in low-level vision. Traditional optimization based methods generally formulate this task as a maximum-a-posteriori estimation or variational inference problem, whose performance highly relies on the handcraft priors for both the latent image and the blur kernel. In contrast, recent deep learning methods generally learn, from a large collection of training images, deep neural networks (DNNs) directly mapping the blurry image to the clean one or to the blur kernel, paying less attention to the physical degradation process of the blurry image. In this paper, we present a deep variational Bayesian framework for blind image deblurring. Under this framework, the posterior of the latent clean image and blur kernel can be jointly estimated in an amortized inference fashion with DNNs, and the involved inference DNNs can be trained by fully considering the physical blur model, together with the supervision of data driven priors for the clean image and blur kernel, which is naturally led to by the evidence lower bound objective. Comprehensive experiments are conducted to substantiate the effectiveness of the proposed framework. The results show that it can not only achieve a promising performance with relatively simple networks, but also enhance the performance of existing DNNs for deblurring.
Objects Matter: Learning Object Relation Graph for Robust Camera Relocalization
May 26, 2022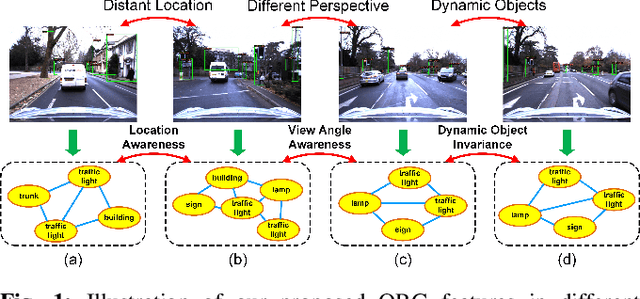
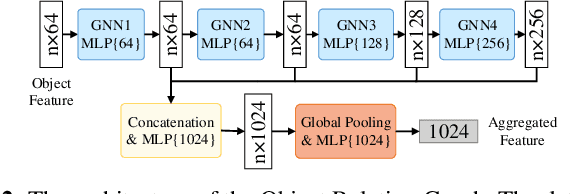
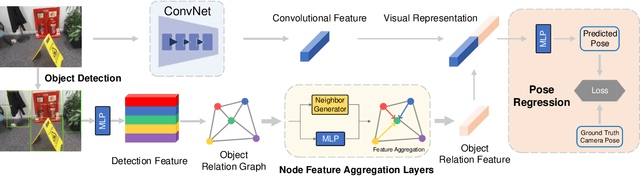
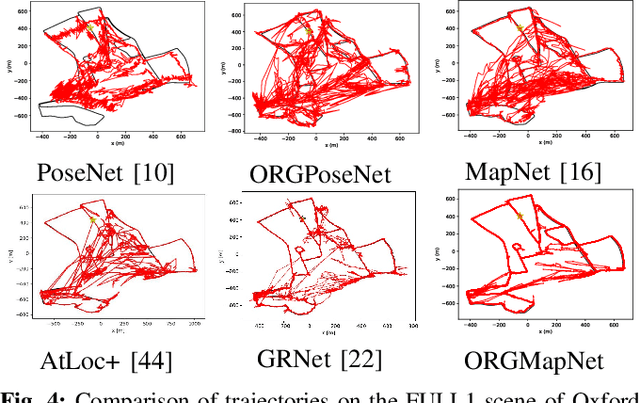
Visual relocalization aims to estimate the pose of a camera from one or more images. In recent years deep learning based pose regression methods have attracted many attentions. They feature predicting the absolute poses without relying on any prior built maps or stored images, making the relocalization very efficient. However, robust relocalization under environments with complex appearance changes and real dynamics remains very challenging. In this paper, we propose to enhance the distinctiveness of the image features by extracting the deep relationship among objects. In particular, we extract objects in the image and construct a deep object relation graph (ORG) to incorporate the semantic connections and relative spatial clues of the objects. We integrate our ORG module into several popular pose regression models. Extensive experiments on various public indoor and outdoor datasets demonstrate that our method improves the performance significantly and outperforms the previous approaches.
AR-NeRF: Unsupervised Learning of Depth and Defocus Effects from Natural Images with Aperture Rendering Neural Radiance Fields
Jun 13, 2022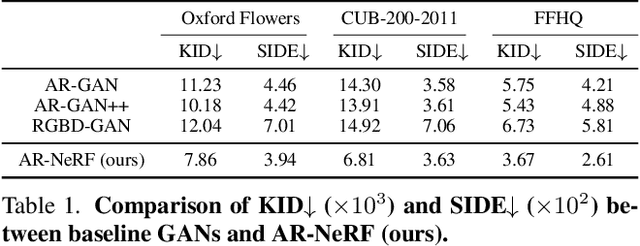
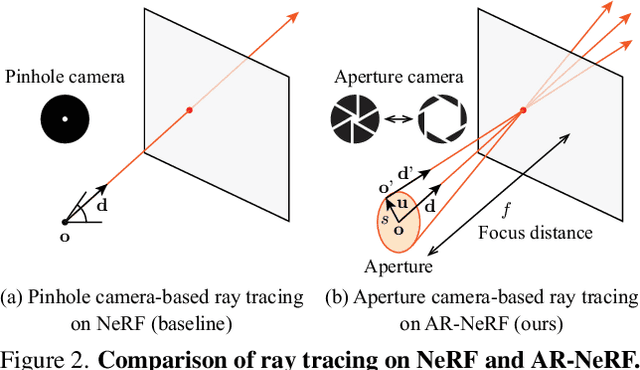
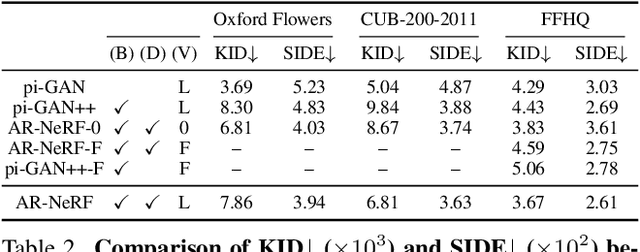
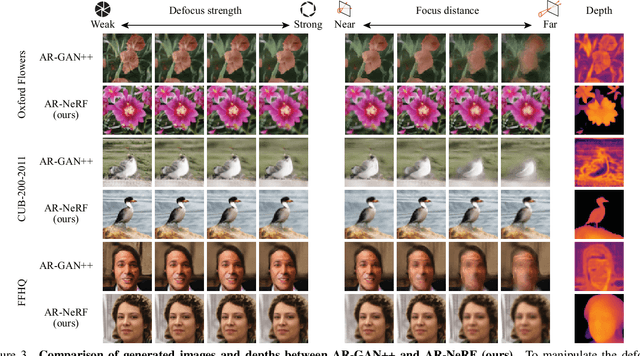
Fully unsupervised 3D representation learning has gained attention owing to its advantages in data collection. A successful approach involves a viewpoint-aware approach that learns an image distribution based on generative models (e.g., generative adversarial networks (GANs)) while generating various view images based on 3D-aware models (e.g., neural radiance fields (NeRFs)). However, they require images with various views for training, and consequently, their application to datasets with few or limited viewpoints remains a challenge. As a complementary approach, an aperture rendering GAN (AR-GAN) that employs a defocus cue was proposed. However, an AR-GAN is a CNN-based model and represents a defocus independently from a viewpoint change despite its high correlation, which is one of the reasons for its performance. As an alternative to an AR-GAN, we propose an aperture rendering NeRF (AR-NeRF), which can utilize viewpoint and defocus cues in a unified manner by representing both factors in a common ray-tracing framework. Moreover, to learn defocus-aware and defocus-independent representations in a disentangled manner, we propose aperture randomized training, for which we learn to generate images while randomizing the aperture size and latent codes independently. During our experiments, we applied AR-NeRF to various natural image datasets, including flower, bird, and face images, the results of which demonstrate the utility of AR-NeRF for unsupervised learning of the depth and defocus effects.