 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VTruST: Controllable value function based subset selection for Data-Centric Trustworthy AI
Mar 08, 2024
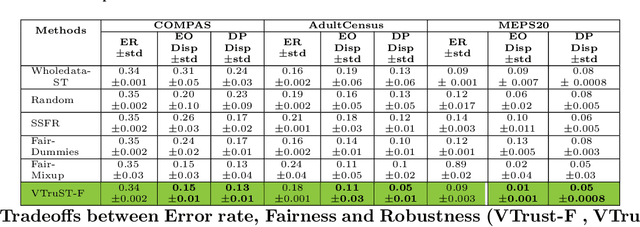
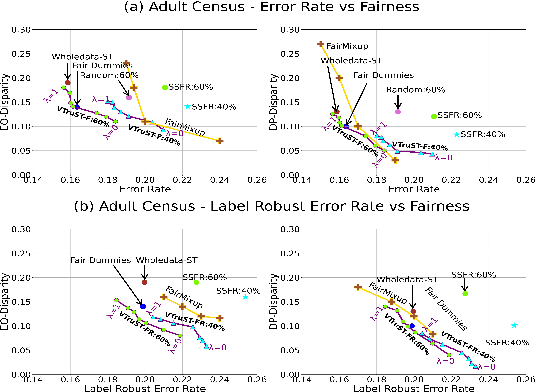
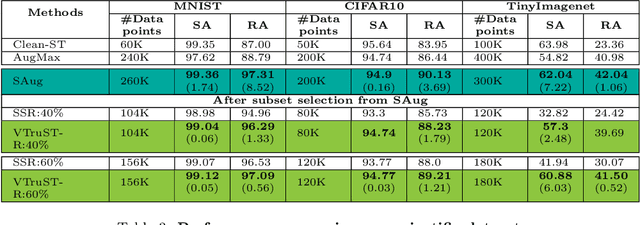
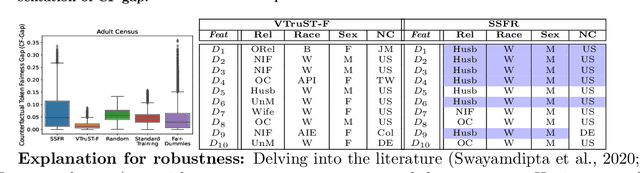
Trustworthy AI is crucial to the widespread adoption of AI in high-stakes applications with fairness, robustness, and accuracy being some of the key trustworthiness metrics. In this work, we propose a controllable framework for data-centric trustworthy AI (DCTAI)- VTruST, that allows users to control the trade-offs between the different trustworthiness metrics of the constructed training datasets. A key challenge in implementing an efficient DCTAI framework is to design an online value-function-based training data subset selection algorithm. We pose the training data valuation and subset selection problem as an online sparse approximation formulation. We propose a novel online version of the Orthogonal Matching Pursuit (OMP) algorithm for solving this problem. Experimental results show that VTruST outperforms the state-of-the-art baselines on social, image, and scientific datasets. We also show that the data values generated by VTruST can provide effective data-centric explanations for different trustworthiness metrics.
Scene Graph Aided Radiology Report Generation
Mar 08, 2024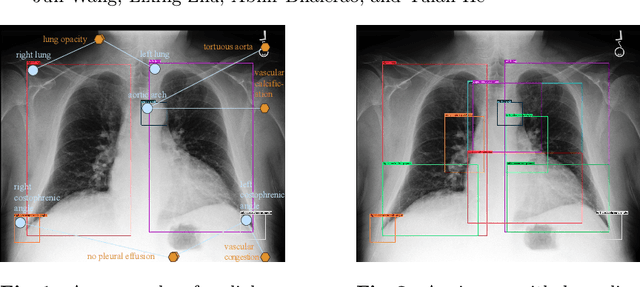
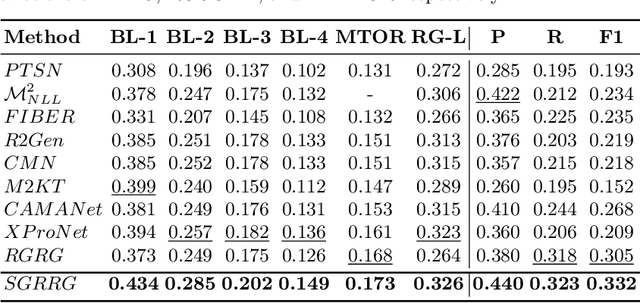
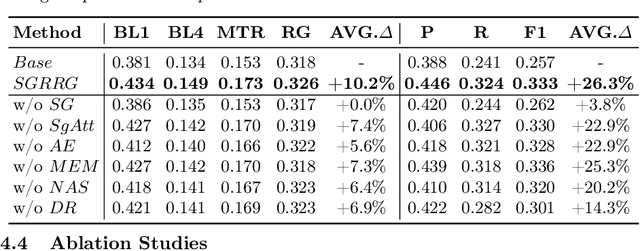
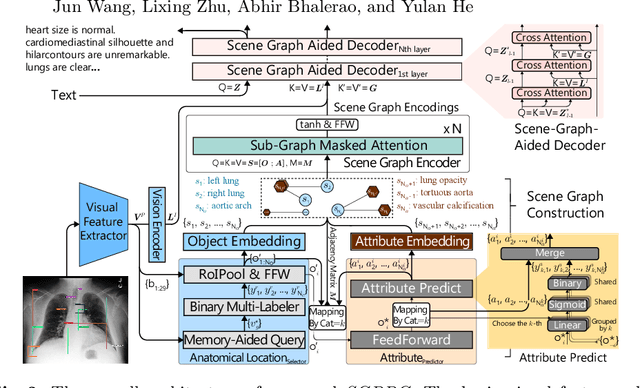
Radiology report generation (RRG) methods often lack sufficient medical knowledge to produce clinically accurate reports. The scene graph contains rich information to describe the objects in an image. We explore enriching the medical knowledge for RRG via a scene graph, which has not been done in the current RRG literature. To this end, we propose the Scene Graph aided RRG (SGRRG) network, a framework that generates region-level visual features, predicts anatomical attributes, and leverages an automatically generated scene graph, thus achieving medical knowledge distillation in an end-to-end manner. SGRRG is composed of a dedicated scene graph encoder responsible for translating the scene graph, and a scene graph-aided decoder that takes advantage of both patch-level and region-level visual information. A fine-grained, sentence-level attention method is designed to better dis-till the scene graph information. Extensive experiments demonstrate that SGRRG outperforms previous state-of-the-art methods in report generation and can better capture abnormal findings.
APPLE: Adversarial Privacy-aware Perturbations on Latent Embedding for Unfairness Mitigation
Mar 08, 2024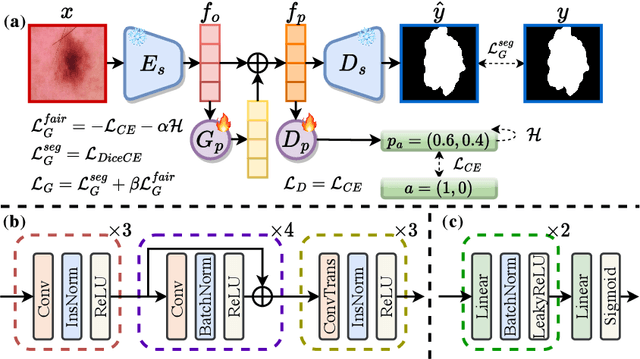
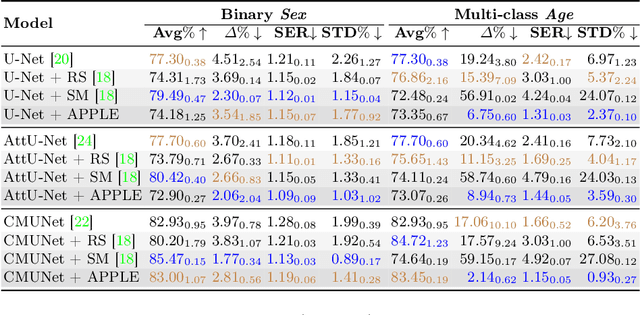


Ensuring fairness in deep-learning-based segmentors is crucial for health equity. Much effort has been dedicated to mitigating unfairness in the training datasets or procedures. However, with the increasing prevalence of foundation models in medical image analysis, it is hard to train fair models from scratch while preserving utility. In this paper, we propose a novel method, Adversarial Privacy-aware Perturbations on Latent Embedding (APPLE), that can improve the fairness of deployed segmentors by introducing a small latent feature perturber without updating the weights of the original model. By adding perturbation to the latent vector, APPLE decorates the latent vector of segmentors such that no fairness-related features can be passed to the decoder of the segmentors while preserving the architecture and parameters of the segmentor. Experiments on two segmentation datasets and five segmentors (three U-Net-like and two SAM-like) illustrate the effectiveness of our proposed method compared to several unfairness mitigation methods.
When do Convolutional Neural Networks Stop Learning?
Mar 04, 2024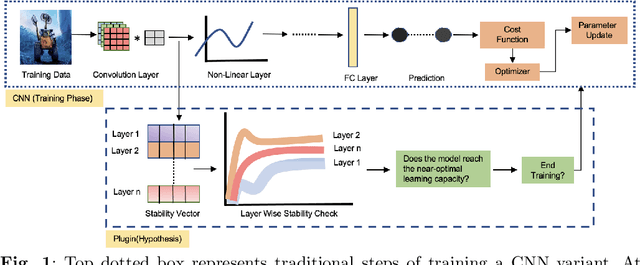
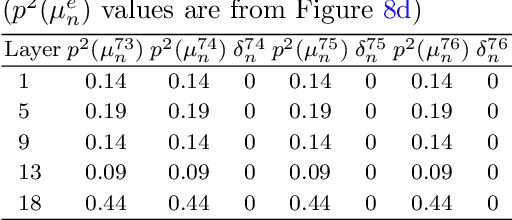
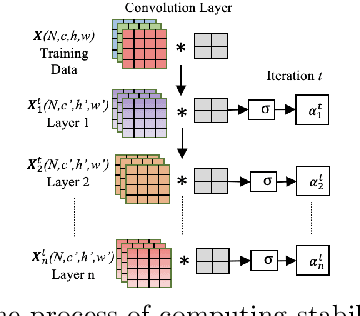
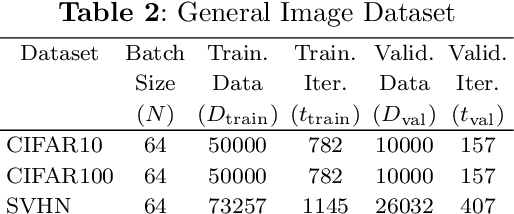
Convolutional Neural Networks (CNNs) have demonstrated outstanding performance in computer vision tasks such as image classification, detection, segmentation, and medical image analysis. In general, an arbitrary number of epochs is used to train such neural networks. In a single epoch, the entire training data -- divided by batch size -- are fed to the network. In practice, validation error with training loss is used to estimate the neural network's generalization, which indicates the optimal learning capacity of the network. Current practice is to stop training when the training loss decreases and the gap between training and validation error increases (i.e., the generalization gap) to avoid overfitting. However, this is a trial-and-error-based approach which raises a critical question: Is it possible to estimate when neural networks stop learning based on training data? This research work introduces a hypothesis that analyzes the data variation across all the layers of a CNN variant to anticipate its near-optimal learning capacity. In the training phase, we use our hypothesis to anticipate the near-optimal learning capacity of a CNN variant without using any validation data. Our hypothesis can be deployed as a plug-and-play to any existing CNN variant without introducing additional trainable parameters to the network. We test our hypothesis on six different CNN variants and three different general image datasets (CIFAR10, CIFAR100, and SVHN). The result based on these CNN variants and datasets shows that our hypothesis saves 58.49\% of computational time (on average) in training. We further conduct our hypothesis on ten medical image datasets and compared with the MedMNIST-V2 benchmark. Based on our experimental result, we save $\approx$ 44.1\% of computational time without losing accuracy against the MedMNIST-V2 benchmark.
Radio-astronomical Image Reconstruction with Conditional Denoising Diffusion Model
Feb 20, 2024Reconstructing sky models from dirty radio images for accurate source localization and flux estimation is crucial for studying galaxy evolution at high redshift, especially in deep fields using instruments like the Atacama Large Millimetre Array (ALMA). With new projects like the Square Kilometre Array (SKA), there's a growing need for better source extraction methods. Current techniques, such as CLEAN and PyBDSF, often fail to detect faint sources, highlighting the need for more accurate methods. This study proposes using stochastic neural networks to rebuild sky models directly from dirty images. This method can pinpoint radio sources and measure their fluxes with related uncertainties, marking a potential improvement in radio source characterization. We tested this approach on 10164 images simulated with the CASA tool simalma, based on ALMA's Cycle 5.3 antenna setup. We applied conditional Denoising Diffusion Probabilistic Models (DDPMs) for sky models reconstruction, then used Photutils to determine source coordinates and fluxes, assessing the model's performance across different water vapor levels. Our method showed excellence in source localization, achieving more than 90% completeness at a signal-to-noise ratio (SNR) as low as 2. It also surpassed PyBDSF in flux estimation, accurately identifying fluxes for 96% of sources in the test set, a significant improvement over CLEAN+ PyBDSF's 57%. Conditional DDPMs is a powerful tool for image-to-image translation, yielding accurate and robust characterisation of radio sources, and outperforming existing methodologies. While this study underscores its significant potential for applications in radio astronomy, we also acknowledge certain limitations that accompany its usage, suggesting directions for further refinement and research.
Deep Learning based acoustic measurement approach for robotic applications on orthopedics
Mar 09, 2024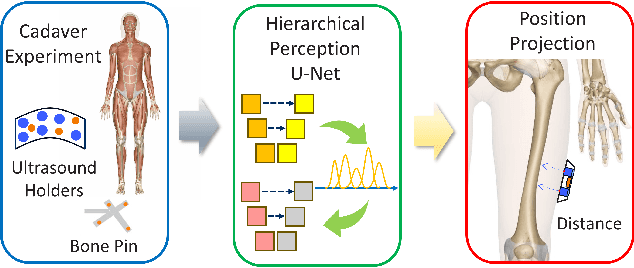
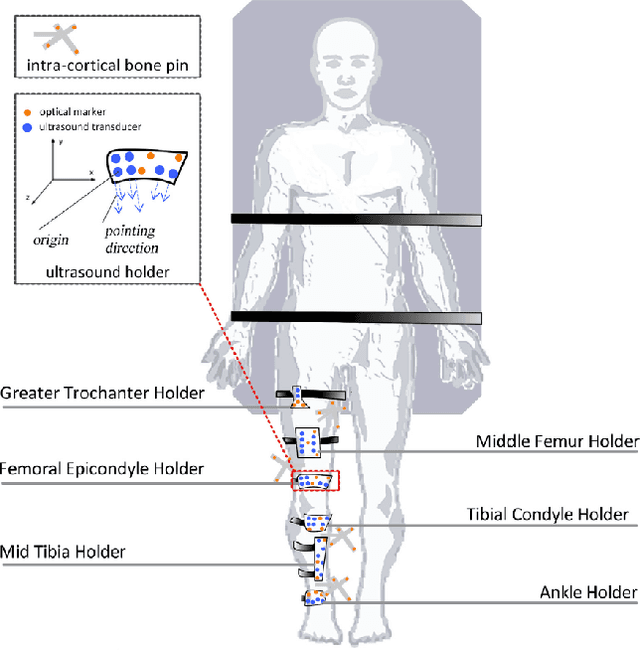
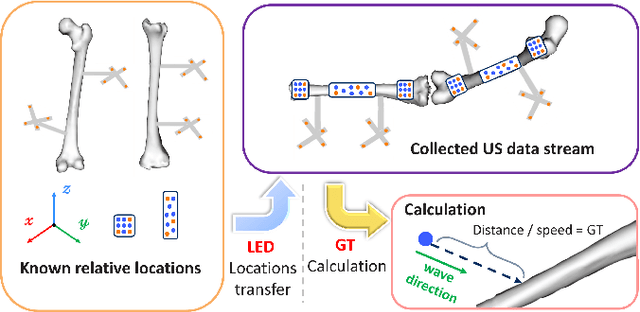
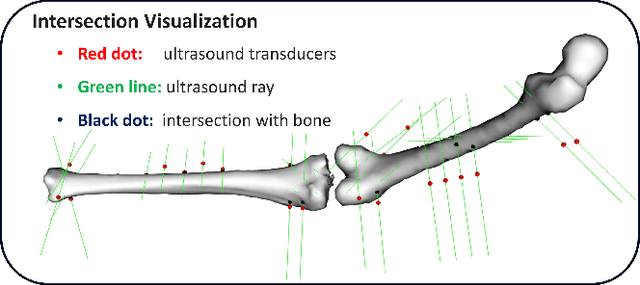
In Total Knee Replacement Arthroplasty (TKA), surgical robotics can provide image-guided navigation to fit implants with high precision. Its tracking approach highly relies on inserting bone pins into the bones tracked by the optical tracking system. This is normally done by invasive, radiative manners (implantable markers and CT scans), which introduce unnecessary trauma and prolong the preparation time for patients. To tackle this issue, ultrasound-based bone tracking could offer an alternative. In this study, we proposed a novel deep learning structure to improve the accuracy of bone tracking by an A-mode ultrasound (US). We first obtained a set of ultrasound dataset from the cadaver experiment, where the ground truth locations of bones were calculated using bone pins. These data were used to train the proposed CasAtt-UNet to predict bone location automatically and robustly. The ground truth bone locations and those locations of US were recorded simultaneously. Therefore, we could label bone peaks in the raw US signals. As a result, our method achieved sub millimeter precision across all eight bone areas with the only exception of one channel in the ankle. This method enables the robust measurement of lower extremity bone positions from 1D raw ultrasound signals. It shows great potential to apply A-mode ultrasound in orthopedic surgery from safe, convenient, and efficient perspectives.
UDCR: Unsupervised Aortic DSA/CTA Rigid Registration Using Deep Reinforcement Learning and Overlap Degree Calculation
Mar 09, 2024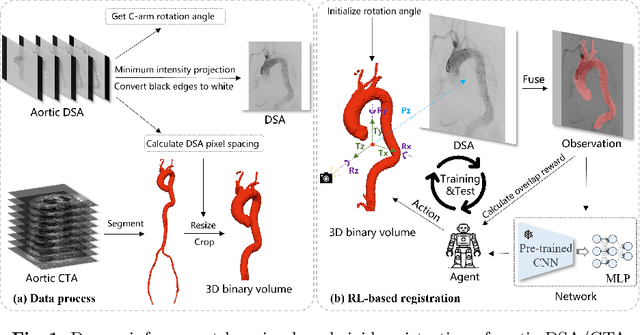
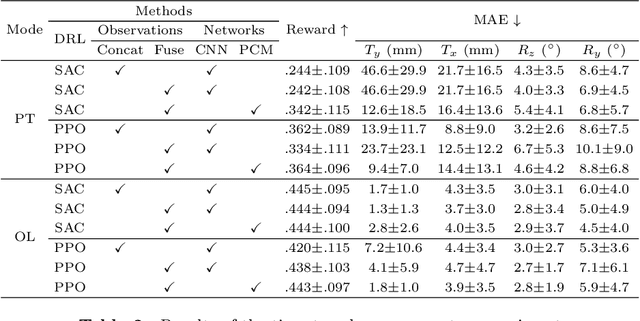
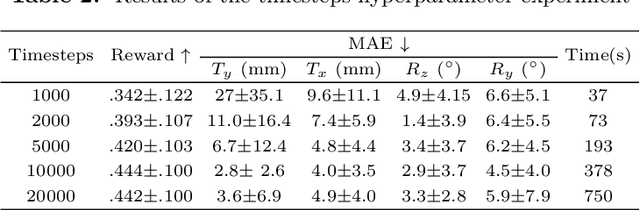
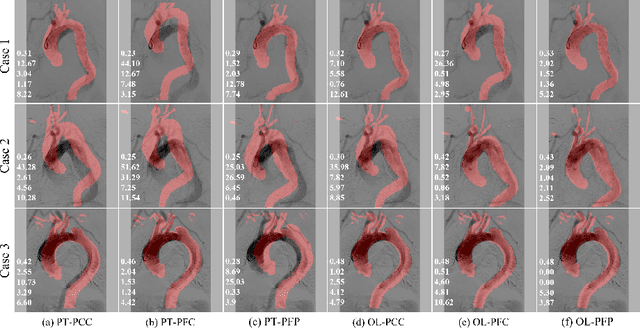
The rigid registration of aortic Digital Subtraction Angiography (DSA) and Computed Tomography Angiography (CTA) can provide 3D anatomical details of the vasculature for the interventional surgical treatment of conditions such as aortic dissection and aortic aneurysms, holding significant value for clinical research. However, the current methods for 2D/3D image registration are dependent on manual annotations or synthetic data, as well as the extraction of landmarks, which is not suitable for cross-modal registration of aortic DSA/CTA. In this paper, we propose an unsupervised method, UDCR, for aortic DSA/CTA rigid registration based on deep reinforcement learning. Leveraging the imaging principles and characteristics of DSA and CTA, we have constructed a cross-dimensional registration environment based on spatial transformations. Specifically, we propose an overlap degree calculation reward function that measures the intensity difference between the foreground and background, aimed at assessing the accuracy of registration between segmentation maps and DSA images. This method is highly flexible, allowing for the loading of pre-trained models to perform registration directly or to seek the optimal spatial transformation parameters through online learning. We manually annotated 61 pairs of aortic DSA/CTA for algorithm evaluation. The results indicate that the proposed UDCR achieved a Mean Absolute Error (MAE) of 2.85 mm in translation and 4.35{\deg} in rotation, showing significant potential for clinical applications.
Asphalt Concrete Characterization Using Digital Image Correlation: A Systematic Review of Best Practices, Applications, and Future Vision
Feb 26, 2024Digital Image Correlation (DIC) is an optical technique that measures displacement and strain by tracking pattern movement in a sequence of captured images during testing. DIC has gained recognition in asphalt pavement engineering since the early 2000s. However, users often perceive the DIC technique as an out-of-box tool and lack a thorough understanding of its operational and measurement principles. This article presents a state-of-art review of DIC as a crucial tool for laboratory testing of asphalt concrete (AC), primarily focusing on the widely utilized 2D-DIC and 3D-DIC techniques. To address frequently asked questions from users, the review thoroughly examines the optimal methods for preparing speckle patterns, configuring single-camera or dual-camera imaging systems, conducting DIC analyses, and exploring various applications. Furthermore, emerging DIC methodologies such as Digital Volume Correlation and deep-learning-based DIC are introduced, highlighting their potential for future applications in pavement engineering. The article also provides a comprehensive and reliable flowchart for implementing DIC in AC characterization. Finally, critical directions for future research are presented.
Improved Focus on Hard Samples for Lung Nodule Detection
Mar 07, 2024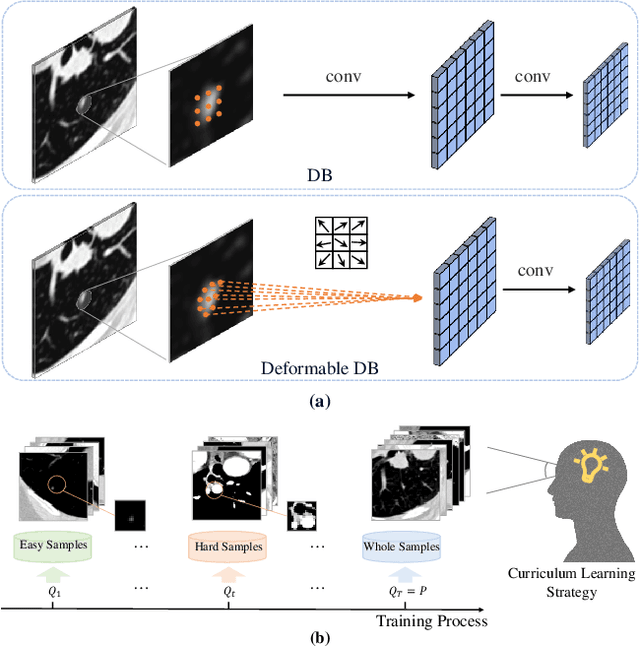
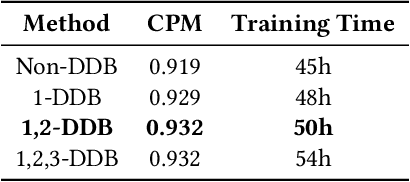
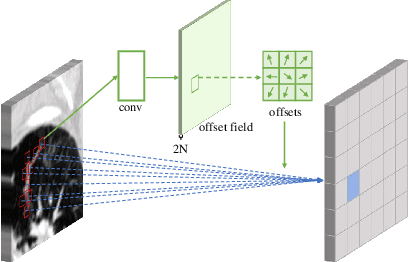

Recently, lung nodule detection methods based on deep learning have shown excellent performance in the medical image processing field. Considering that only a few public lung datasets are available and lung nodules are more difficult to detect in CT images than in natural images, the existing methods face many bottlenecks when detecting lung nodules, especially hard ones in CT images. In order to solve these problems, we plan to enhance the focus of our network. In this work, we present an improved detection network that pays more attention to hard samples and datasets to deal with lung nodules by introducing deformable convolution and self-paced learning. Experiments on the LUNA16 dataset demonstrate the effectiveness of our proposed components and show that our method has reached competitive performance.
Semi-Supervised Semantic Segmentation Based on Pseudo-Labels: A Survey
Mar 04, 2024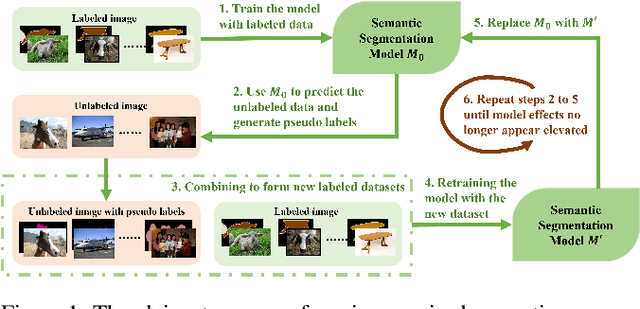
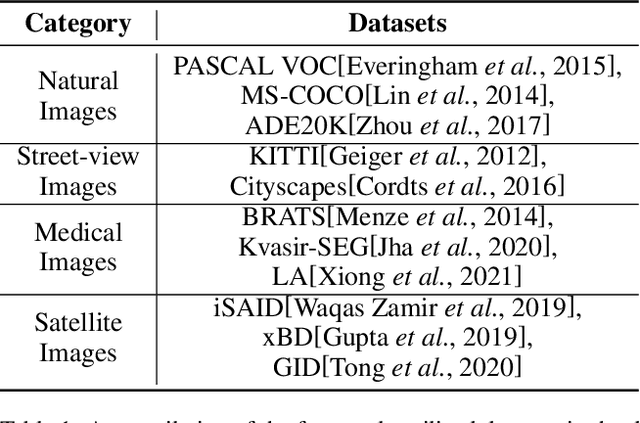
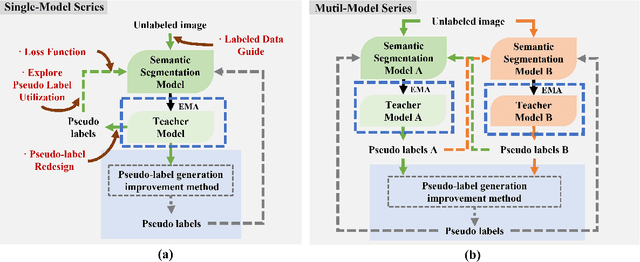
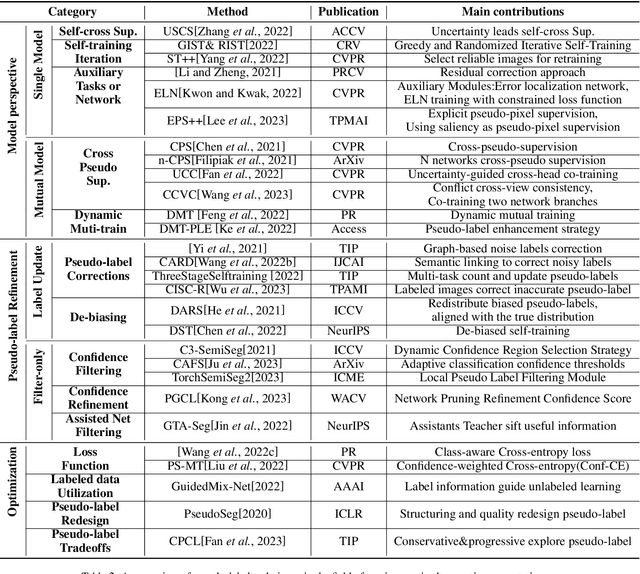
Semantic segmentation is an important and popular research area in computer vision that focuses on classifying pixels in an image based on their semantics. However, supervised deep learning requires large amounts of data to train models and the process of labeling images pixel by pixel is time-consuming and laborious. This review aims to provide a first comprehensive and organized overview of the state-of-the-art research results on pseudo-label methods in the field of semi-supervised semantic segmentation, which we categorize from different perspectives and present specific methods for specific application areas. In addition, we explore the application of pseudo-label technology in medical and remote-sensing image segmentation. Finally, we also propose some feasible future research directions to address the existing challenges.