 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Directional Lifting Wavelet Transform for Image Edge Analysis
Dec 02, 2021



In this paper, we propose a new two-dimensional directional discrete wavelet transform that can decompose an image into 12 multiscale directional edge components. The proposed transform is designed in a fully discrete setting and thus is easy to implement in actual computations. The proposed transform is viewed as a category of redundant discrete wavelet transforms implemented by fast in-place computational algorithms by a lifting scheme that has been modified to incorporate redundancy. The redundancy is limited to $(N \times J+1)/4$, where $N=12$ is the directional selectivity and $J$ is a decomposition level of the multiscale transform. Numerical experiments in edge detection using various images demonstrate the advantages of the proposed method over some conventional standard methods. The proposed method outperforms several conventional edge detection methods in identifying both the location and orientation of edges, and well captures the directional and geometrical features of images.
Virtual stain transfer in histology via cascaded deep neural networks
Jul 14, 2022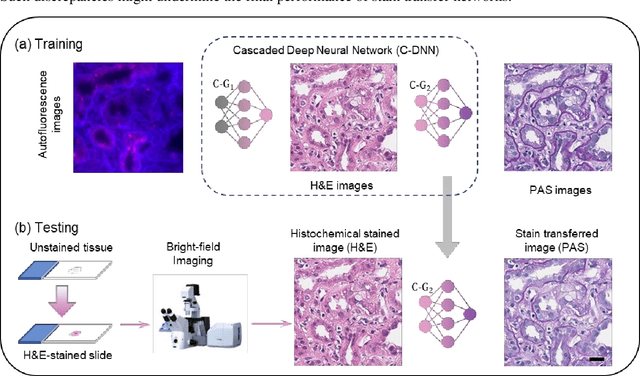

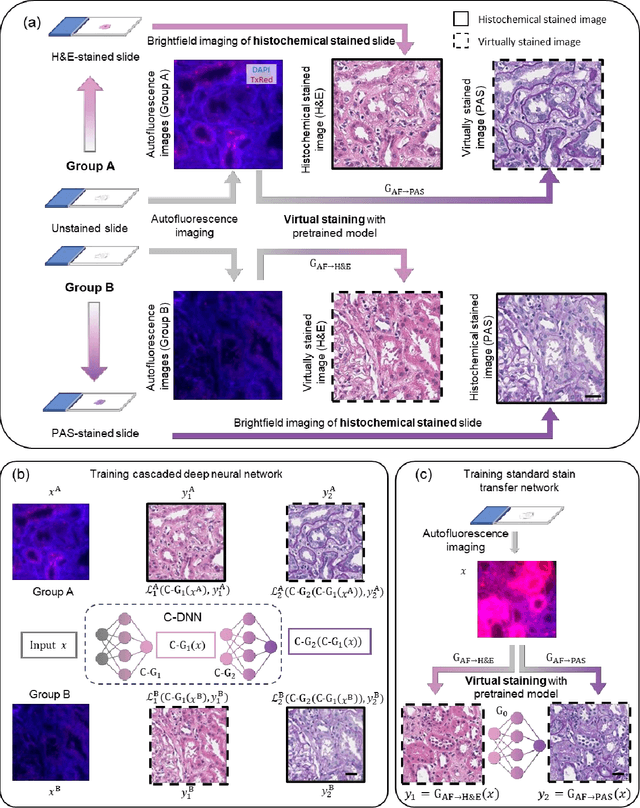
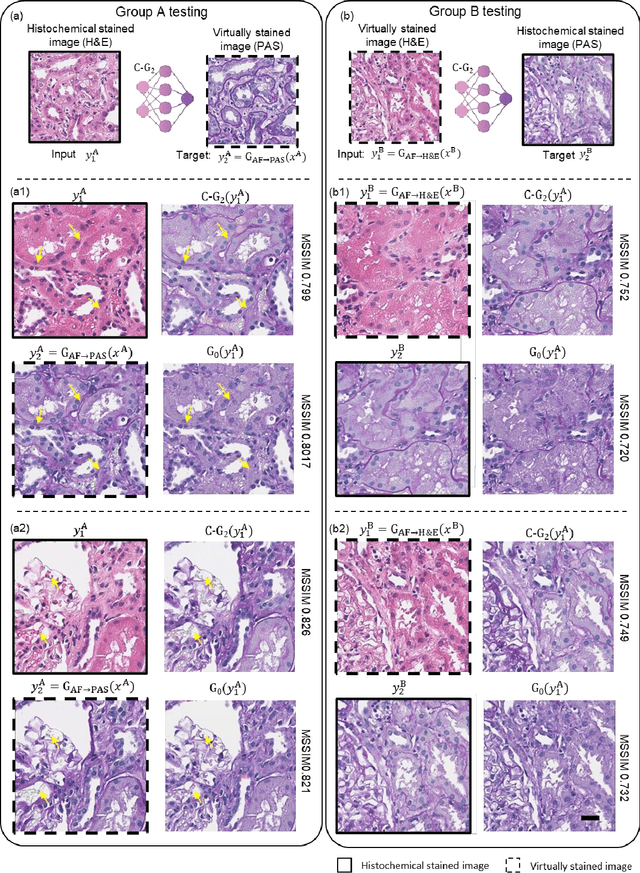
Pathological diagnosis relies on the visual inspection of histologically stained thin tissue specimens, where different types of stains are applied to bring contrast to and highlight various desired histological features. However, the destructive histochemical staining procedures are usually irreversible, making it very difficult to obtain multiple stains on the same tissue section. Here, we demonstrate a virtual stain transfer framework via a cascaded deep neural network (C-DNN) to digitally transform hematoxylin and eosin (H&E) stained tissue images into other types of histological stains. Unlike a single neural network structure which only takes one stain type as input to digitally output images of another stain type, C-DNN first uses virtual staining to transform autofluorescence microscopy images into H&E and then performs stain transfer from H&E to the domain of the other stain in a cascaded manner. This cascaded structure in the training phase allows the model to directly exploit histochemically stained image data on both H&E and the target special stain of interest. This advantage alleviates the challenge of paired data acquisition and improves the image quality and color accuracy of the virtual stain transfer from H&E to another stain. We validated the superior performance of this C-DNN approach using kidney needle core biopsy tissue sections and successfully transferred the H&E-stained tissue images into virtual PAS (periodic acid-Schiff) stain. This method provides high-quality virtual images of special stains using existing, histochemically stained slides and creates new opportunities in digital pathology by performing highly accurate stain-to-stain transformations.
DeepDefacer: Automatic Removal of Facial Features via U-Net Image Segmentation
May 31, 2022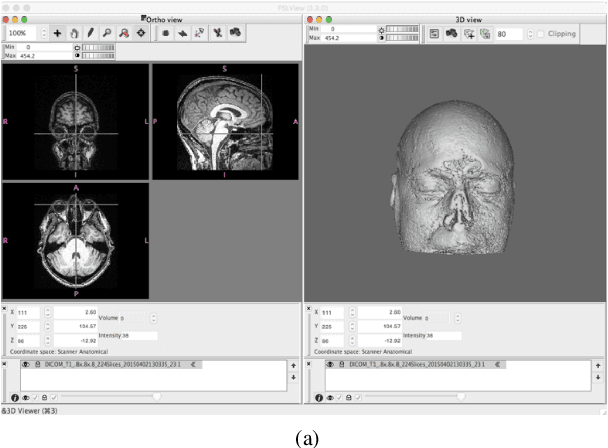
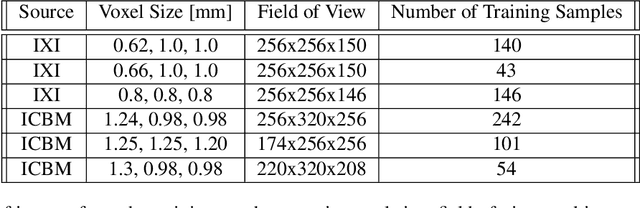
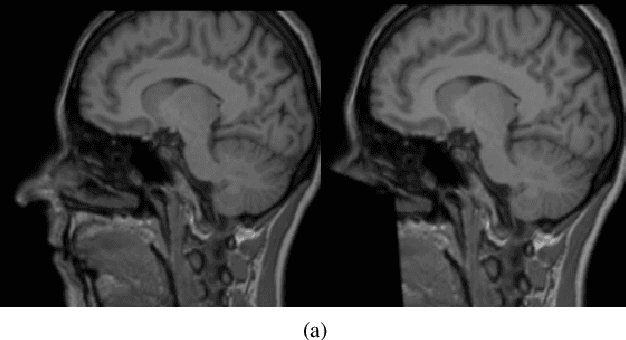

Recent advancements in the field of magnetic resonance imaging (MRI) have enabled large-scale collaboration among clinicians and researchers for neuroimaging tasks. However, researchers are often forced to use outdated and slow software to anonymize MRI images for publication. These programs specifically perform expensive mathematical operations over 3D images that rapidly slow down anonymization speed as an image's volume increases in size. In this paper, we introduce DeepDefacer, an application of deep learning to MRI anonymization that uses a streamlined 3D U-Net network to mask facial regions in MRI images with a significant increase in speed over traditional de-identification software. We train DeepDefacer on MRI images from the Brain Development Organization (IXI) and International Consortium for Brain Mapping (ICBM) and quantitatively evaluate our model against a baseline 3D U-Net model with regards to Dice, recall, and precision scores. We also evaluate DeepDefacer against Pydeface, a traditional defacing application, with regards to speed on a range of CPU and GPU devices and qualitatively evaluate our model's defaced output versus the ground truth images produced by Pydeface. We provide a link to a PyPi program at the end of this manuscript to encourage further research into the application of deep learning to MRI anonymization.
Exploring Semantic Relationships for Unpaired Image Captioning
Jun 20, 2021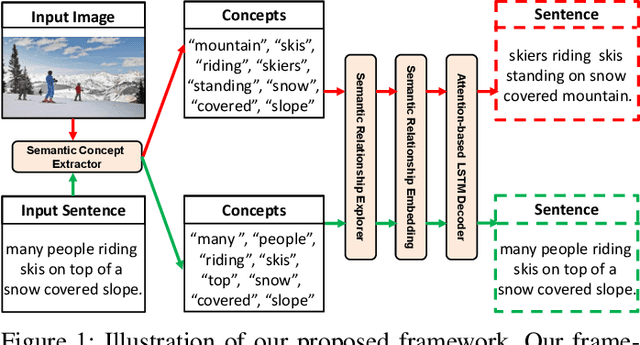
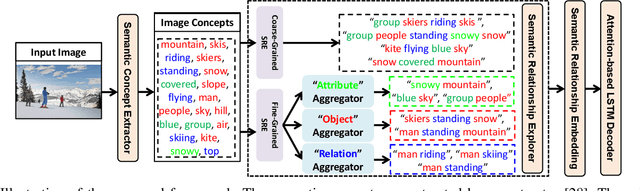
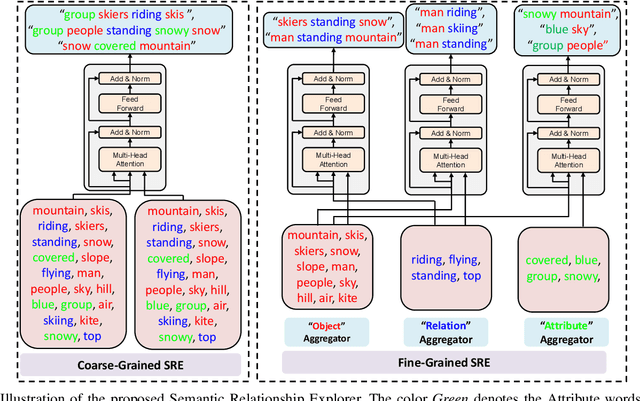

Recently, image captioning has aroused great interest in both academic and industrial worlds. Most existing systems are built upon large-scale datasets consisting of image-sentence pairs, which, however, are time-consuming to construct. In addition, even for the most advanced image captioning systems, it is still difficult to realize deep image understanding. In this work, we achieve unpaired image captioning by bridging the vision and the language domains with high-level semantic information. The motivation stems from the fact that the semantic concepts with the same modality can be extracted from both images and descriptions. To further improve the quality of captions generated by the model, we propose the Semantic Relationship Explorer, which explores the relationships between semantic concepts for better understanding of the image. Extensive experiments on MSCOCO dataset show that we can generate desirable captions without paired datasets. Furthermore, the proposed approach boosts five strong baselines under the paired setting, where the most significant improvement in CIDEr score reaches 8%, demonstrating that it is effective and generalizes well to a wide range of models.
INSightR-Net: Interpretable Neural Network for Regression using Similarity-based Comparisons to Prototypical Examples
Jul 31, 2022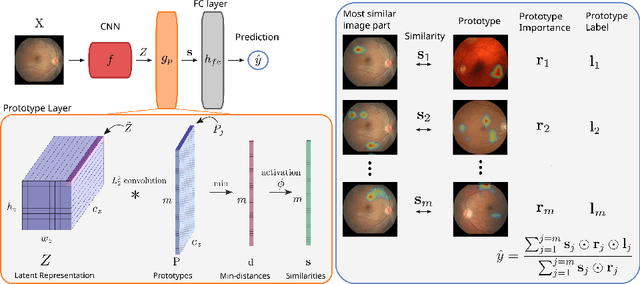
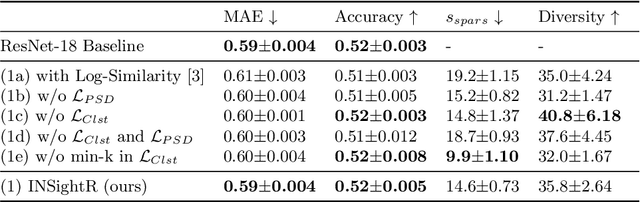
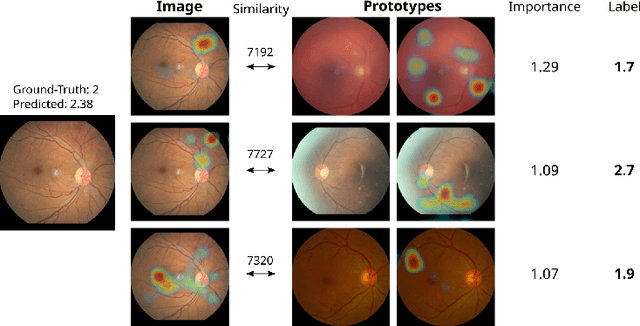
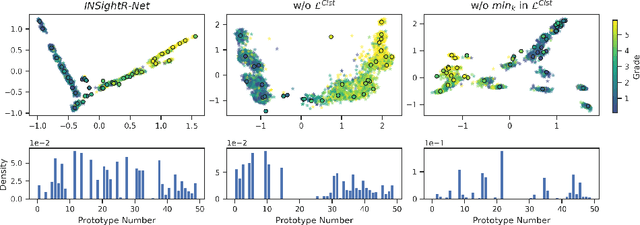
Convolutional neural networks (CNNs) have shown exceptional performance for a range of medical imaging tasks. However, conventional CNNs are not able to explain their reasoning process, therefore limiting their adoption in clinical practice. In this work, we propose an inherently interpretable CNN for regression using similarity-based comparisons (INSightR-Net) and demonstrate our methods on the task of diabetic retinopathy grading. A prototype layer incorporated into the architecture enables visualization of the areas in the image that are most similar to learned prototypes. The final prediction is then intuitively modeled as a mean of prototype labels, weighted by the similarities. We achieved competitive prediction performance with our INSightR-Net compared to a ResNet baseline, showing that it is not necessary to compromise performance for interpretability. Furthermore, we quantified the quality of our explanations using sparsity and diversity, two concepts considered important for a good explanation, and demonstrated the effect of several parameters on the latent space embeddings.
Visualizing the Passage of Time with Video Temporal Pyramids
Aug 25, 2022
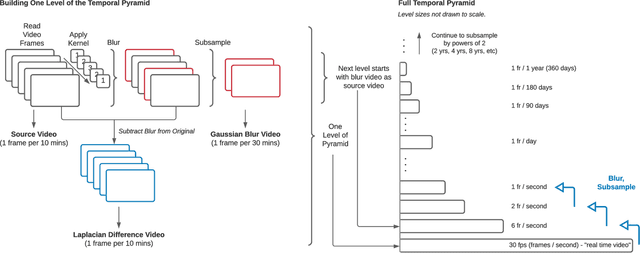


What can we learn about a scene by watching it for months or years? A video recorded over a long timespan will depict interesting phenomena at multiple timescales, but identifying and viewing them presents a challenge. The video is too long to watch in full, and some occurrences are too slow to experience in real-time, such as glacial retreat. Timelapse videography is a common approach to summarizing long videos and visualizing slow timescales. However, a timelapse is limited to a single chosen temporal frequency, and often appears flickery due to aliasing and temporal discontinuities between frames. In this paper, we propose Video Temporal Pyramids, a technique that addresses these limitations and expands the possibilities for visualizing the passage of time. Inspired by spatial image pyramids from computer vision, we developed an algorithm that builds video pyramids in the temporal domain. Each level of a Video Temporal Pyramid visualizes a different timescale; for instance, videos from the monthly timescale are usually good for visualizing seasonal changes, while videos from the one-minute timescale are best for visualizing sunrise or the movement of clouds across the sky. To help explore the different pyramid levels, we also propose a Video Spectrogram to visualize the amount of activity across the entire pyramid, providing a holistic overview of the scene dynamics and the ability to explore and discover phenomena across time and timescales. To demonstrate our approach, we have built Video Temporal Pyramids from ten outdoor scenes, each containing months or years of data. We compare Video Temporal Pyramid layers to naive timelapse and find that our pyramids enable alias-free viewing of longer-term changes. We also demonstrate that the Video Spectrogram facilitates exploration and discovery of phenomena across pyramid levels, by enabling both overview and detail-focused perspectives.
Design What You Desire: Icon Generation from Orthogonal Application and Theme Labels
Jul 31, 2022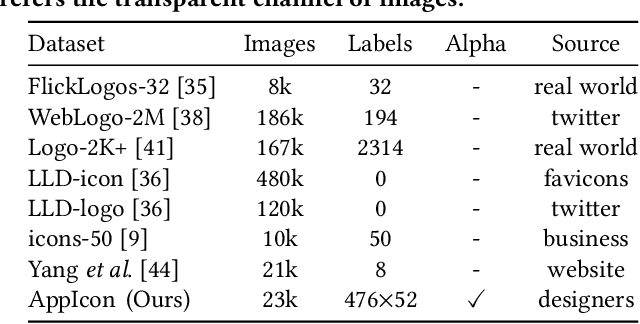
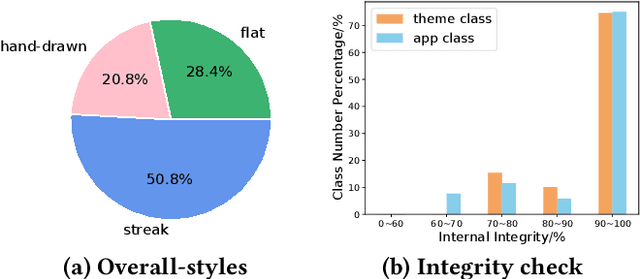
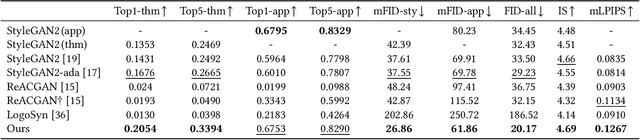
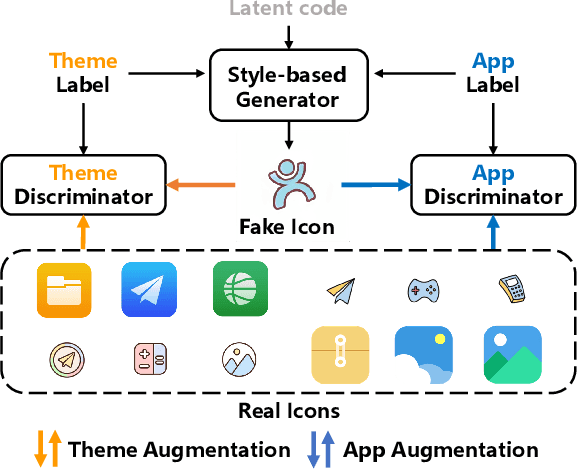
Generative adversarial networks (GANs) have been trained to be professional artists able to create stunning artworks such as face generation and image style transfer. In this paper, we focus on a realistic business scenario: automated generation of customizable icons given desired mobile applications and theme styles. We first introduce a theme-application icon dataset, termed AppIcon, where each icon has two orthogonal theme and app labels. By investigating a strong baseline StyleGAN2, we observe mode collapse caused by the entanglement of the orthogonal labels. To solve this challenge, we propose IconGAN composed of a conditional generator and dual discriminators with orthogonal augmentations, and a contrastive feature disentanglement strategy is further designed to regularize the feature space of the two discriminators. Compared with other approaches, IconGAN indicates a superior advantage on the AppIcon benchmark. Further analysis also justifies the effectiveness of disentangling app and theme representations. Our project will be released at: https://github.com/architect-road/IconGAN.
Practical Insights of Repairing Model Problems on Image Classification
May 14, 2022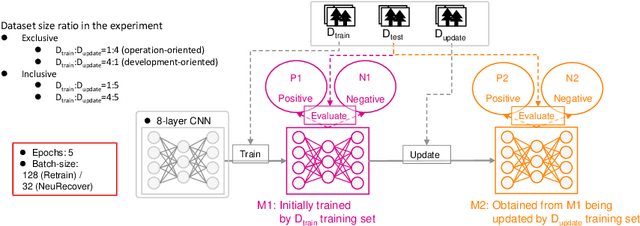
Additional training of a deep learning model can cause negative effects on the results, turning an initially positive sample into a negative one (degradation). Such degradation is possible in real-world use cases due to the diversity of sample characteristics. That is, a set of samples is a mixture of critical ones which should not be missed and less important ones. Therefore, we cannot understand the performance by accuracy alone. While existing research aims to prevent a model degradation, insights into the related methods are needed to grasp their benefits and limitations. In this talk, we will present implications derived from a comparison of methods for reducing degradation. Especially, we formulated use cases for industrial settings in terms of arrangements of a data set. The results imply that a practitioner should care about better method continuously considering dataset availability and life cycle of an AI system because of a trade-off between accuracy and preventing degradation.
Cross Modification Attention Based Deliberation Model for Image Captioning
Sep 17, 2021
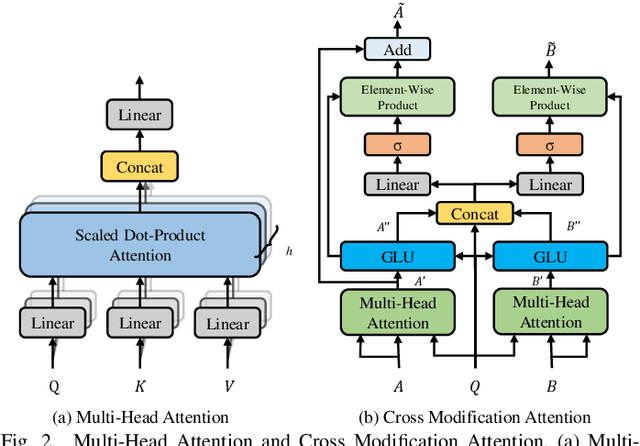
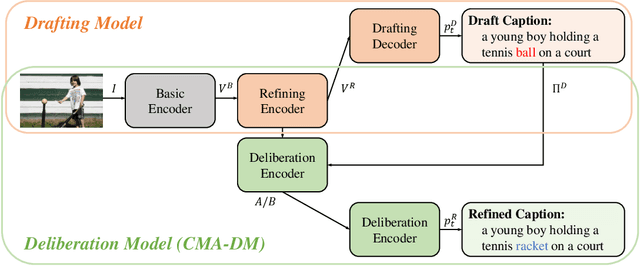
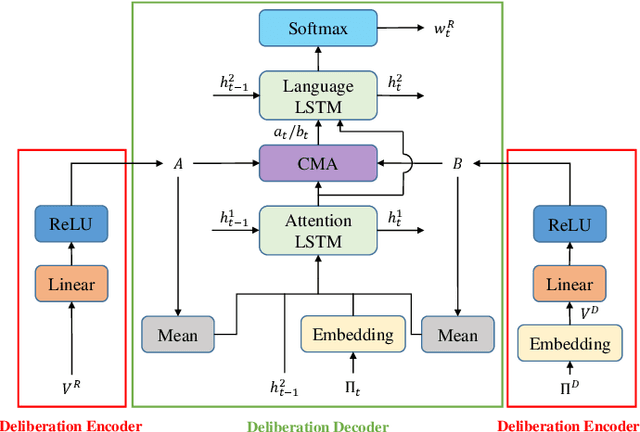
The conventional encoder-decoder framework for image captioning generally adopts a single-pass decoding process, which predicts the target descriptive sentence word by word in temporal order. Despite the great success of this framework, it still suffers from two serious disadvantages. Firstly, it is unable to correct the mistakes in the predicted words, which may mislead the subsequent prediction and result in error accumulation problem. Secondly, such a framework can only leverage the already generated words but not the possible future words, and thus lacks the ability of global planning on linguistic information. To overcome these limitations, we explore a universal two-pass decoding framework, where a single-pass decoding based model serving as the Drafting Model first generates a draft caption according to an input image, and a Deliberation Model then performs the polishing process to refine the draft caption to a better image description. Furthermore, inspired from the complementarity between different modalities, we propose a novel Cross Modification Attention (CMA) module to enhance the semantic expression of the image features and filter out error information from the draft captions. We integrate CMA with the decoder of our Deliberation Model and name it as Cross Modification Attention based Deliberation Model (CMA-DM). We train our proposed framework by jointly optimizing all trainable components from scratch with a trade-off coefficient. Experiments on MS COCO dataset demonstrate that our approach obtains significant improvements over single-pass decoding baselines and achieves competitive performances compared with other state-of-the-art two-pass decoding based methods.
Variable-Rate Deep Image Compression through Spatially-Adaptive Feature Transform
Aug 21, 2021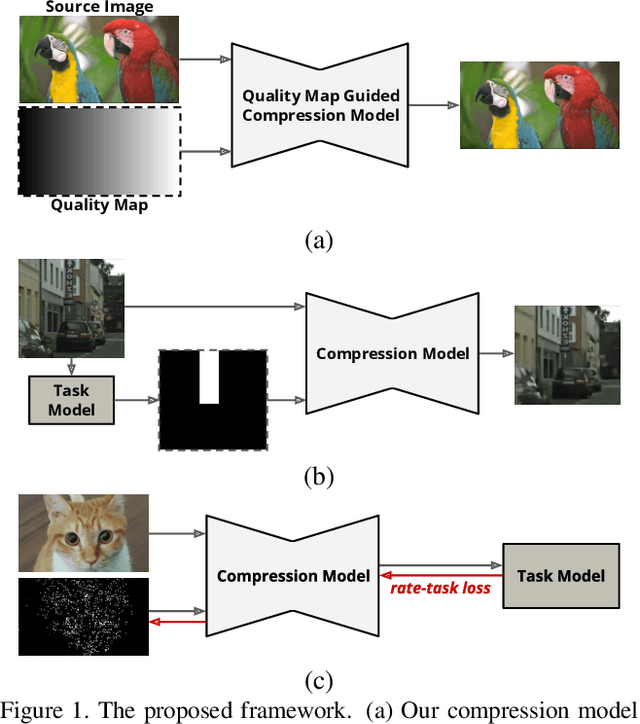


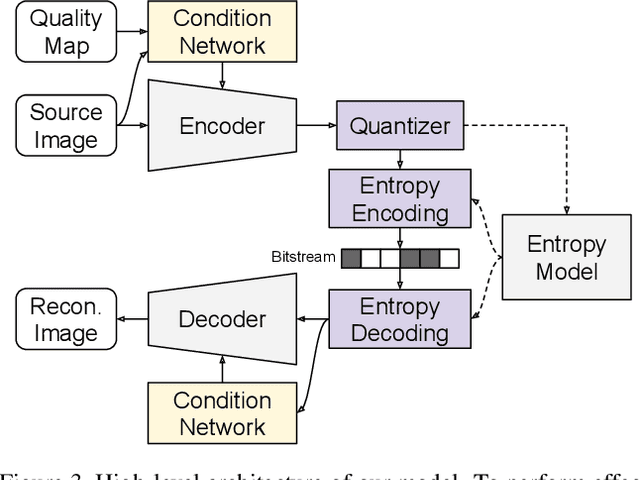
We propose a versatile deep image compression network based on Spatial Feature Transform (SFT arXiv:1804.02815), which takes a source image and a corresponding quality map as inputs and produce a compressed image with variable rates. Our model covers a wide range of compression rates using a single model, which is controlled by arbitrary pixel-wise quality maps. In addition, the proposed framework allows us to perform task-aware image compressions for various tasks, e.g., classification, by efficiently estimating optimized quality maps specific to target tasks for our encoding network. This is even possible with a pretrained network without learning separate models for individual tasks. Our algorithm achieves outstanding rate-distortion trade-off compared to the approaches based on multiple models that are optimized separately for several different target rates. At the same level of compression, the proposed approach successfully improves performance on image classification and text region quality preservation via task-aware quality map estimation without additional model training. The code is available at the project website: https://github.com/micmic123/QmapCompression