 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Initiative Context: Structuring and Managing Context for Human-AI Collaboration
Apr 08, 2026In the human-AI collaboration area, the context formed naturally through multi-turn interactions is typically flattened into a chronological sequence and treated as a fixed whole in subsequent reasoning, with no mechanism for dynamic organization and management along the collaboration workflow. Yet these contexts differ substantially in lifecycle, structural hierarchy, and relevance. For instance, temporary or abandoned exchanges and parallel topic threads persist in the limited context window, causing interference and even conflict. Meanwhile, users are largely limited to influencing context indirectly through input modifications (e.g., corrections, references, or ignoring), leaving their control neither explicit nor verifiable. To address this, we propose Mixed-Initiative Context, which reconceptualizes the context formed across multi-turn interactions as an explicit, structured, and manipulable interactive object. Under this concept, the structure, scope, and content of context can be dynamically organized and adjusted according to task needs, enabling both humans and AI to actively participate in context construction and regulation. To explore this concept, we implement Contextify as a probe system and conduct a user study examining users' context management behaviors, attitudes toward AI initiative, and overall collaboration experience. We conclude by discussing the implications of this concept for the HCI community.
Alignment-Process-Outcome: Rethinking How AIs and Humans Collaborate
Mar 10, 2026In real-world collaboration, alignment, process structure, and outcome quality do not exhibit a simple linear or one-to-one correspondence: similar alignment may accompany either rapid convergence or extensive multi-branch exploration, and lead to different results. Existing accounts often isolate these dimensions or focus on specific participant types, limiting structural accounts of collaboration. We reconceptualize collaboration through two complementary lenses. The task lens models collaboration as trajectory evolution in a structured task space, revealing patterns such as advancement, branching, and backtracking. The intent lens examines how individual intents are expressed within shared contexts and enter situated decisions. Together, these lenses clarify the structural relationships among alignment, decision-making, and trajectory structure. Rather than reducing collaboration to outcome quality or treating alignment as the sole objective, we propose a unified dynamic view of the relationships among alignment, process, and outcome, and use it to re-examine collaboration structure across Human-Human, AI-AI, and Human-AI settings.
Multiple Fusion Adaptation: A Strong Framework for Unsupervised Semantic Segmentation Adaptation
Dec 01, 2021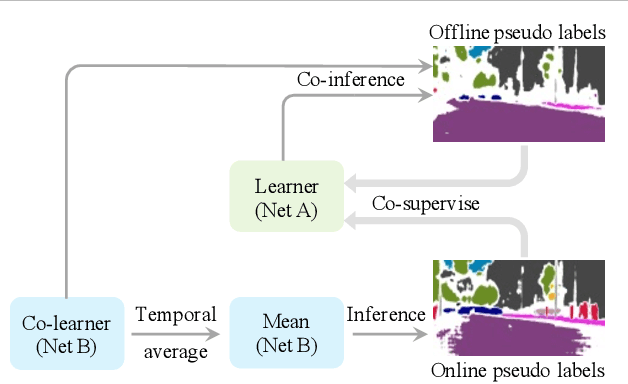
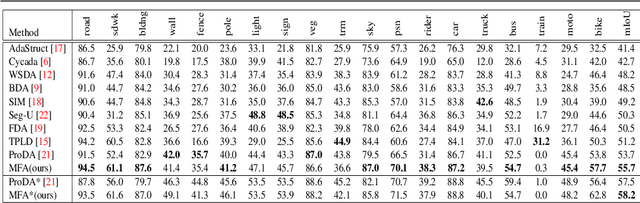
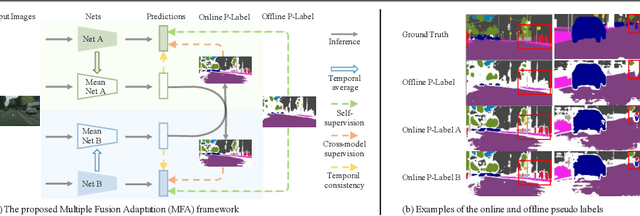
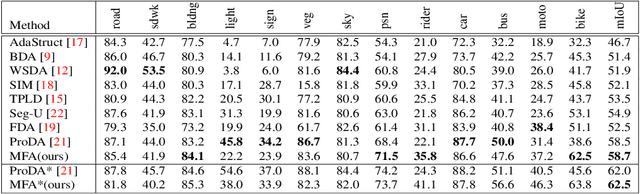
This paper challenges the cross-domain semantic segmentation task, aiming to improve the segmentation accuracy on the unlabeled target domain without incurring additional annotation. Using the pseudo-label-based unsupervised domain adaptation (UDA) pipeline, we propose a novel and effective Multiple Fusion Adaptation (MFA) method. MFA basically considers three parallel information fusion strategies, i.e., the cross-model fusion, temporal fusion and a novel online-offline pseudo label fusion. Specifically, the online-offline pseudo label fusion encourages the adaptive training to pay additional attention to difficult regions that are easily ignored by offline pseudo labels, therefore retaining more informative details. While the other two fusion strategies may look standard, MFA pays significant efforts to raise the efficiency and effectiveness for integration, and succeeds in injecting all the three strategies into a unified framework. Experiments on two widely used benchmarks, i.e., GTA5-to-Cityscapes and SYNTHIA-to-Cityscapes, show that our method significantly improves the semantic segmentation adaptation, and sets up new state of the art (58.2% and 62.5% mIoU, respectively). The code will be available at https://github.com/KaiiZhang/MFA.
Cross Modification Attention Based Deliberation Model for Image Captioning
Sep 17, 2021
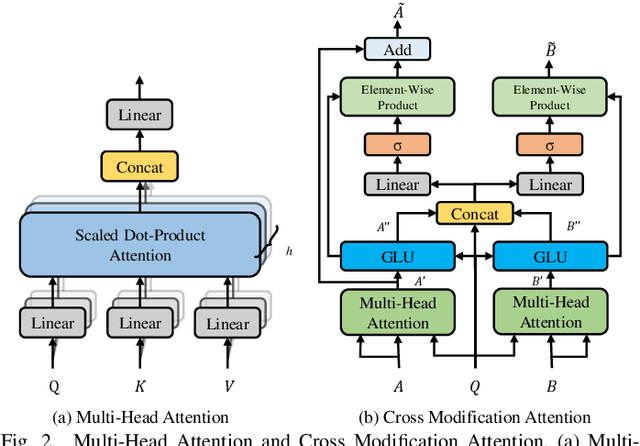
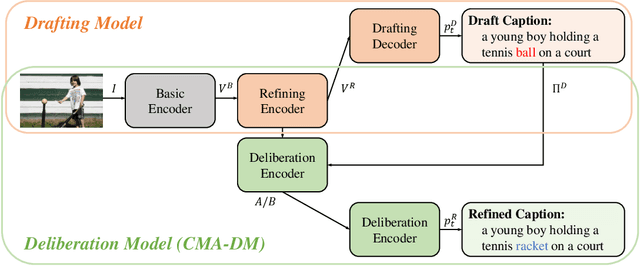
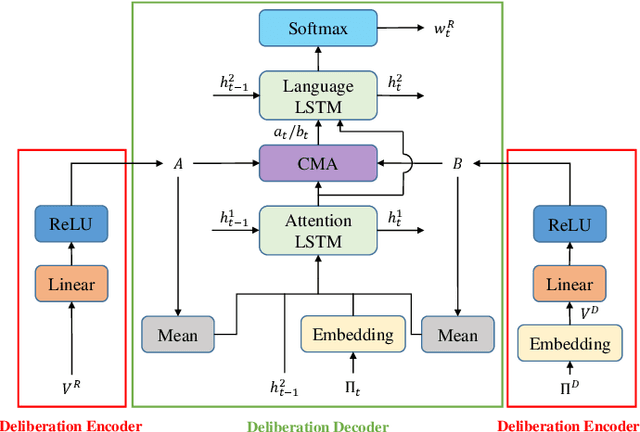
The conventional encoder-decoder framework for image captioning generally adopts a single-pass decoding process, which predicts the target descriptive sentence word by word in temporal order. Despite the great success of this framework, it still suffers from two serious disadvantages. Firstly, it is unable to correct the mistakes in the predicted words, which may mislead the subsequent prediction and result in error accumulation problem. Secondly, such a framework can only leverage the already generated words but not the possible future words, and thus lacks the ability of global planning on linguistic information. To overcome these limitations, we explore a universal two-pass decoding framework, where a single-pass decoding based model serving as the Drafting Model first generates a draft caption according to an input image, and a Deliberation Model then performs the polishing process to refine the draft caption to a better image description. Furthermore, inspired from the complementarity between different modalities, we propose a novel Cross Modification Attention (CMA) module to enhance the semantic expression of the image features and filter out error information from the draft captions. We integrate CMA with the decoder of our Deliberation Model and name it as Cross Modification Attention based Deliberation Model (CMA-DM). We train our proposed framework by jointly optimizing all trainable components from scratch with a trade-off coefficient. Experiments on MS COCO dataset demonstrate that our approach obtains significant improvements over single-pass decoding baselines and achieves competitive performances compared with other state-of-the-art two-pass decoding based methods.