 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Quantum-Classical Hybrid Machine Learning for Image Classification (ICCAD Special Session Paper)
Sep 17, 2021
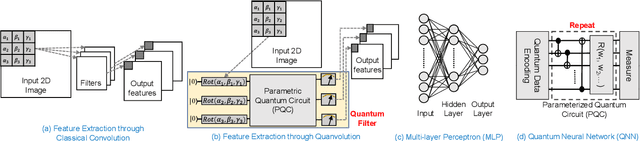
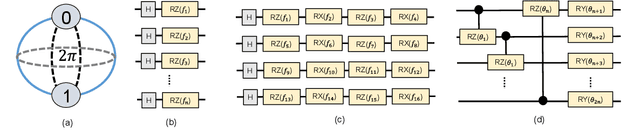
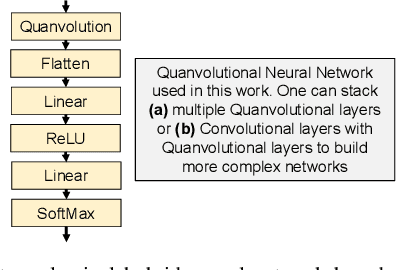
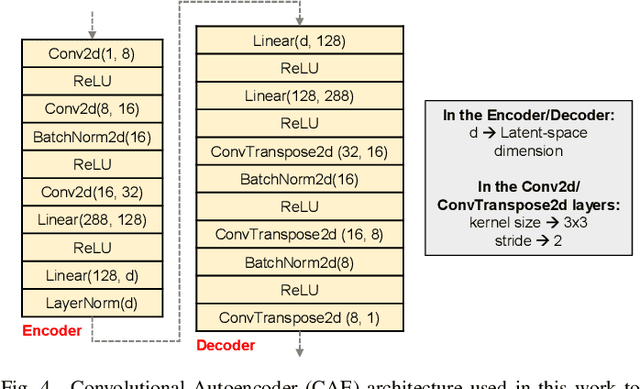
Image classification is a major application domain for conventional deep learning (DL). Quantum machine learning (QML) has the potential to revolutionize image classification. In any typical DL-based image classification, we use convolutional neural network (CNN) to extract features from the image and multi-layer perceptron network (MLP) to create the actual decision boundaries. On one hand, QML models can be useful in both of these tasks. Convolution with parameterized quantum circuits (Quanvolution) can extract rich features from the images. On the other hand, quantum neural network (QNN) models can create complex decision boundaries. Therefore, Quanvolution and QNN can be used to create an end-to-end QML model for image classification. Alternatively, we can extract image features separately using classical dimension reduction techniques such as, Principal Components Analysis (PCA) or Convolutional Autoencoder (CAE) and use the extracted features to train a QNN. We review two proposals on quantum-classical hybrid ML models for image classification namely, Quanvolutional Neural Network and dimension reduction using a classical algorithm followed by QNN. Particularly, we make a case for trainable filters in Quanvolution and CAE-based feature extraction for image datasets (instead of dimension reduction using linear transformations such as, PCA). We discuss various design choices, potential opportunities, and drawbacks of these models. We also release a Python-based framework to create and explore these hybrid models with a variety of design choices.
Threat Model-Agnostic Adversarial Defense using Diffusion Models
Jul 17, 2022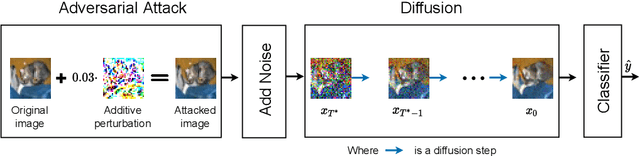
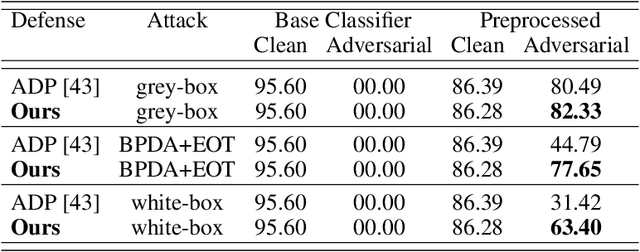
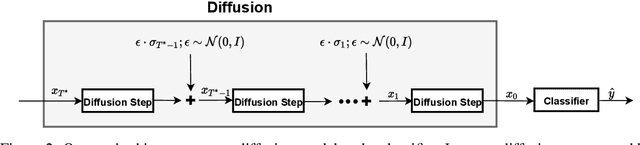
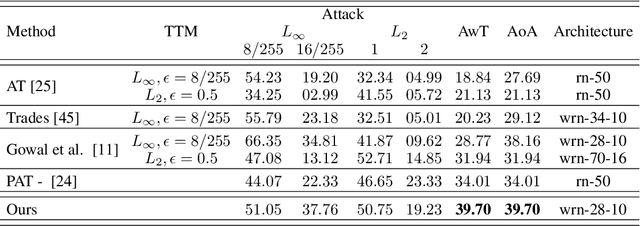
Deep Neural Networks (DNNs) are highly sensitive to imperceptible malicious perturbations, known as adversarial attacks. Following the discovery of this vulnerability in real-world imaging and vision applications, the associated safety concerns have attracted vast research attention, and many defense techniques have been developed. Most of these defense methods rely on adversarial training (AT) -- training the classification network on images perturbed according to a specific threat model, which defines the magnitude of the allowed modification. Although AT leads to promising results, training on a specific threat model fails to generalize to other types of perturbations. A different approach utilizes a preprocessing step to remove the adversarial perturbation from the attacked image. In this work, we follow the latter path and aim to develop a technique that leads to robust classifiers across various realizations of threat models. To this end, we harness the recent advances in stochastic generative modeling, and means to leverage these for sampling from conditional distributions. Our defense relies on an addition of Gaussian i.i.d noise to the attacked image, followed by a pretrained diffusion process -- an architecture that performs a stochastic iterative process over a denoising network, yielding a high perceptual quality denoised outcome. The obtained robustness with this stochastic preprocessing step is validated through extensive experiments on the CIFAR-10 dataset, showing that our method outperforms the leading defense methods under various threat models.
LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action
Jul 10, 2022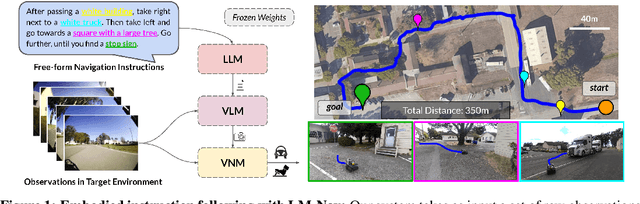

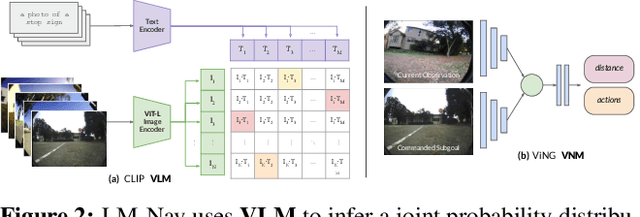
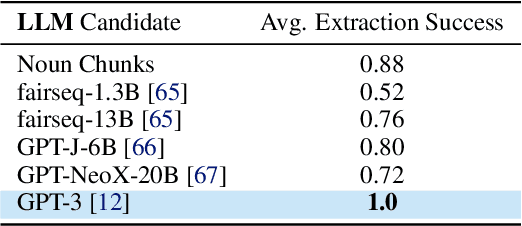
Goal-conditioned policies for robotic navigation can be trained on large, unannotated datasets, providing for good generalization to real-world settings. However, particularly in vision-based settings where specifying goals requires an image, this makes for an unnatural interface. Language provides a more convenient modality for communication with robots, but contemporary methods typically require expensive supervision, in the form of trajectories annotated with language descriptions. We present a system, LM-Nav, for robotic navigation that enjoys the benefits of training on unannotated large datasets of trajectories, while still providing a high-level interface to the user. Instead of utilizing a labeled instruction following dataset, we show that such a system can be constructed entirely out of pre-trained models for navigation (ViNG), image-language association (CLIP), and language modeling (GPT-3), without requiring any fine-tuning or language-annotated robot data. We instantiate LM-Nav on a real-world mobile robot and demonstrate long-horizon navigation through complex, outdoor environments from natural language instructions. For videos of our experiments, code release, and an interactive Colab notebook that runs in your browser, please check out our project page https://sites.google.com/view/lmnav
EGFR Mutation Prediction of Lung Biopsy Images using Deep Learning
Aug 26, 2022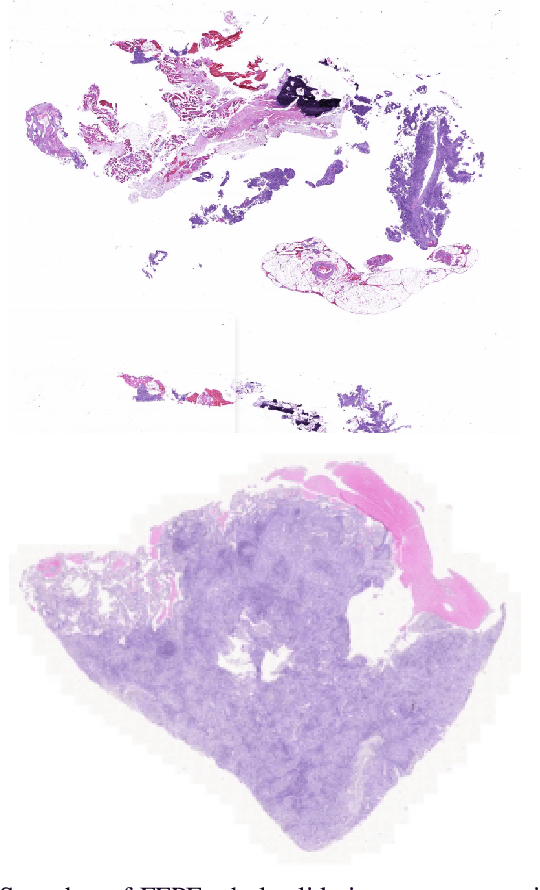
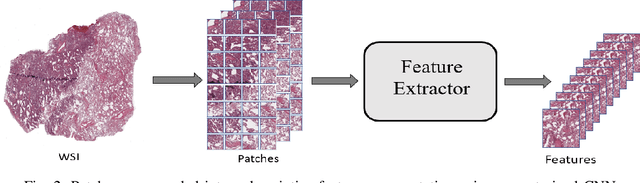
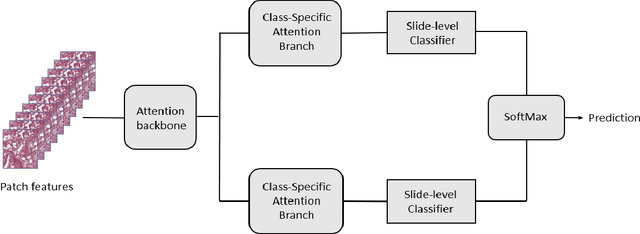

The standard diagnostic procedures for targeted therapies in lung cancer treatment involve histological subtyping and subsequent detection of key driver mutations, such as EGFR. Even though molecular profiling can uncover the driver mutation, the process is often expensive and time-consuming. Deep learning-oriented image analysis offers a more economical alternative for discovering driver mutations directly from whole slide images (WSIs). In this work, we used customized deep learning pipelines with weak supervision to identify the morphological correlates of EGFR mutation from hematoxylin and eosin-stained WSIs, in addition to detecting tumor and histologically subtyping it. We demonstrate the effectiveness of our pipeline by conducting rigorous experiments and ablation studies on two lung cancer datasets - TCGA and a private dataset from India. With our pipeline, we achieved an average area under the curve (AUC) of 0.964 for tumor detection, and 0.942 for histological subtyping between adenocarcinoma and squamous cell carcinoma on the TCGA dataset. For EGFR detection, we achieved an average AUC of 0.864 on the TCGA dataset and 0.783 on the dataset from India. Our key learning points include the following. Firstly, there is no particular advantage of using a feature extractor layers trained on histology, if one is going to fine-tune the feature extractor on the target dataset. Secondly, selecting patches with high cellularity, presumably capturing tumor regions, is not always helpful, as the sign of a disease class may be present in the tumor-adjacent stroma.
A Visual Analytics Framework for Composing a Hierarchical Classification for Medieval Illuminations
Aug 20, 2022
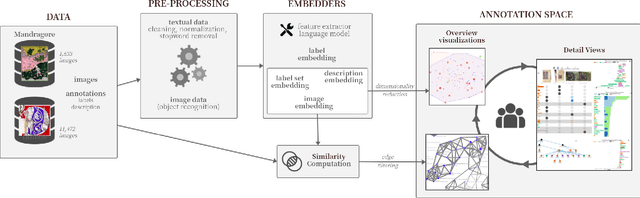
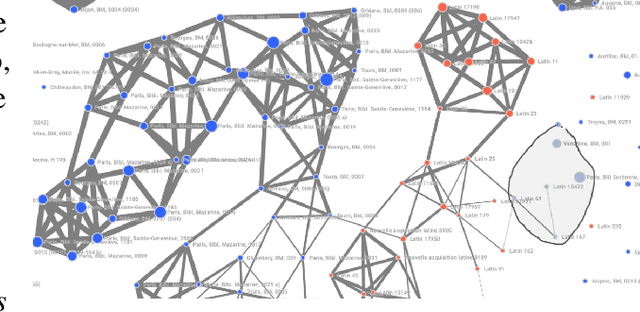
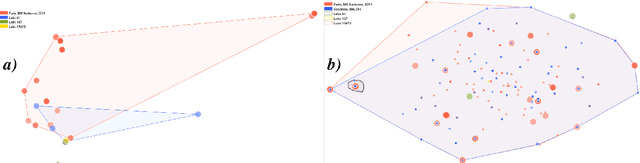
Annotated data is a requirement for applying supervised machine learning methods, and the quality of annotations is crucial for the result. Especially when working with cultural heritage collections that inhere a manifold of uncertainties, annotating data remains a manual, arduous task to be carried out by domain experts. Our project started with two already annotated sets of medieval manuscript images which however were incomplete and comprised conflicting metadata based on scholarly and linguistic differences. Our aims were to create (1) a uniform set of descriptive labels for the combined data set, and (2) a hierarchical classification of a high quality that can be used as a valuable input for supervised machine learning. To reach these goals, we developed a visual analytics system to enable medievalists to combine, regularize and extend the vocabulary used to describe these data sets. Visual interfaces for word and image embeddings as well as co-occurrences of the annotations across the data sets enable annotating multiple images at the same time, recommend annotation label candidates and support composing a hierarchical classification of labels. Our system itself implements a semi-supervised method as it updates visual representations based on the medievalists' feedback, and a series of usage scenarios document its value for the target community.
Learning Eye-in-Hand Camera Calibration from a Single Image
Nov 03, 2021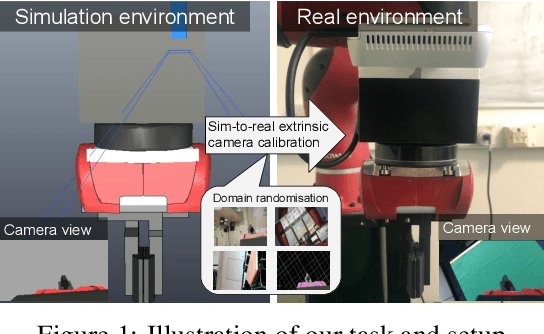
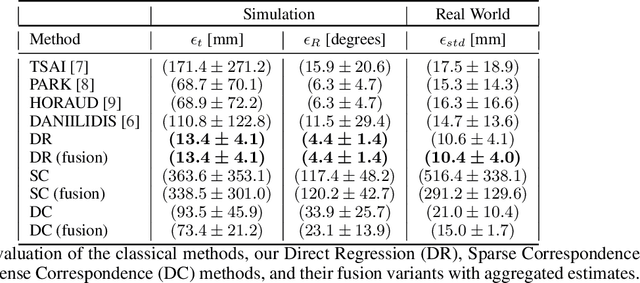
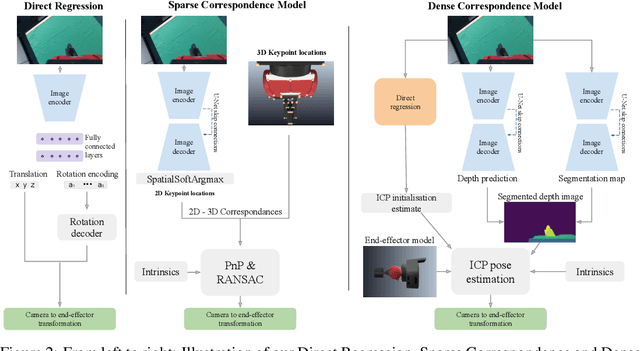

Eye-in-hand camera calibration is a fundamental and long-studied problem in robotics. We present a study on using learning-based methods for solving this problem online from a single RGB image, whilst training our models with entirely synthetic data. We study three main approaches: one direct regression model that directly predicts the extrinsic matrix from an image, one sparse correspondence model that regresses 2D keypoints and then uses PnP, and one dense correspondence model that uses regressed depth and segmentation maps to enable ICP pose estimation. In our experiments, we benchmark these methods against each other and against well-established classical methods, to find the surprising result that direct regression outperforms other approaches, and we perform noise-sensitivity analysis to gain further insights into these results.
Learning From Positive and Unlabeled Data Using Observer-GAN
Aug 26, 2022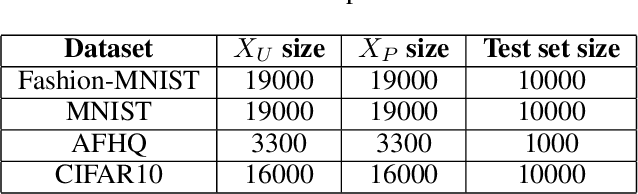
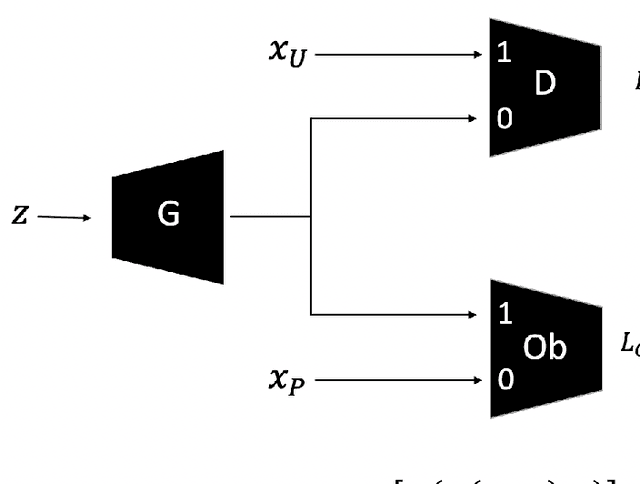


The problem of learning from positive and unlabeled data (A.K.A. PU learning) has been studied in a binary (i.e., positive versus negative) classification setting, where the input data consist of (1) observations from the positive class and their corresponding labels, (2) unlabeled observations from both positive and negative classes. Generative Adversarial Networks (GANs) have been used to reduce the problem to the supervised setting with the advantage that supervised learning has state-of-the-art accuracy in classification tasks. In order to generate \textit{pseudo}-negative observations, GANs are trained on positive and unlabeled observations with a modified loss. Using both positive and \textit{pseudo}-negative observations leads to a supervised learning setting. The generation of pseudo-negative observations that are realistic enough to replace missing negative class samples is a bottleneck for current GAN-based algorithms. By including an additional classifier into the GAN architecture, we provide a novel GAN-based approach. In our suggested method, the GAN discriminator instructs the generator only to produce samples that fall into the unlabeled data distribution, while a second classifier (observer) network monitors the GAN training to: (i) prevent the generated samples from falling into the positive distribution; and (ii) learn the features that are the key distinction between the positive and negative observations. Experiments on four image datasets demonstrate that our trained observer network performs better than existing techniques in discriminating between real unseen positive and negative samples.
Color Image Segmentation Using Multi-Objective Swarm Optimizer and Multi-level Histogram Thresholding
Oct 18, 2021
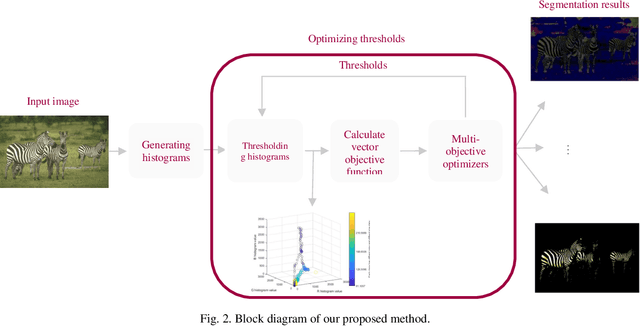
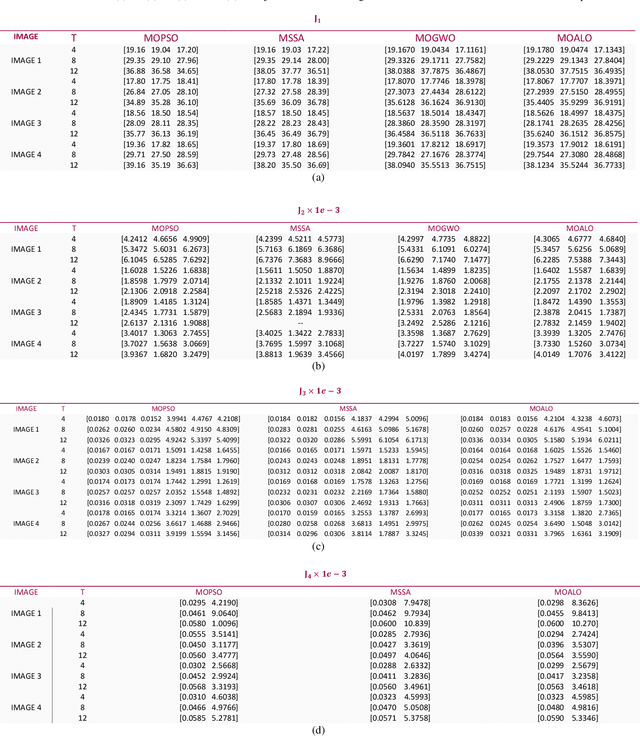
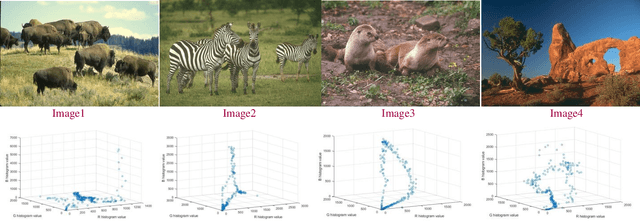
Rapid developments in swarm intelligence optimizers and computer processing abilities make opportunities to design more accurate, stable, and comprehensive methods for color image segmentation. This paper presents a new way for unsupervised image segmentation by combining histogram thresholding methods (Kapur's entropy and Otsu's method) and different multi-objective swarm intelligence algorithms (MOPSO, MOGWO, MSSA, and MOALO) to thresholding 3D histogram of a color image. More precisely, this method first combines the objective function of traditional thresholding algorithms to design comprehensive objective functions then uses multi-objective optimizers to find the best thresholds during the optimization of designed objective functions. Also, our method uses a vector objective function in 3D space that could simultaneously handle the segmentation of entire image color channels with the same thresholds. To optimize this vector objective function, we employ multiobjective swarm optimizers that can optimize multiple objective functions at the same time. Therefore, our method considers dependencies between channels to find the thresholds that satisfy objective functions of color channels (which we name as vector objective function) simultaneously. Segmenting entire color channels with the same thresholds also benefits from the fact that our proposed method needs fewer thresholds to segment the image than other thresholding algorithms; thus, it requires less memory space to save thresholds. It helps a lot when we want to segment many images to many regions. The subjective and objective results show the superiority of this method to traditional thresholding methods that separately threshold histograms of a color image.
Annular Computational Imaging: Capture Clear Panoramic Images through Simple Lens
Jun 13, 2022

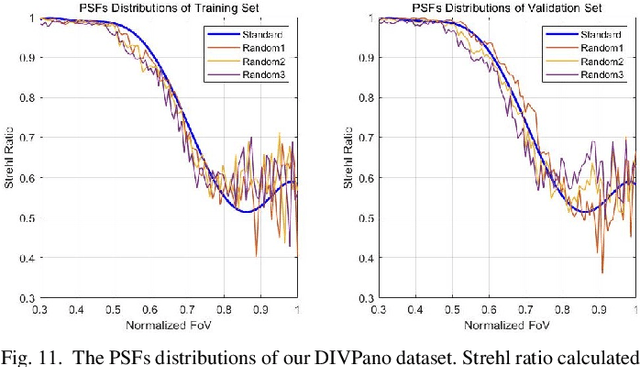
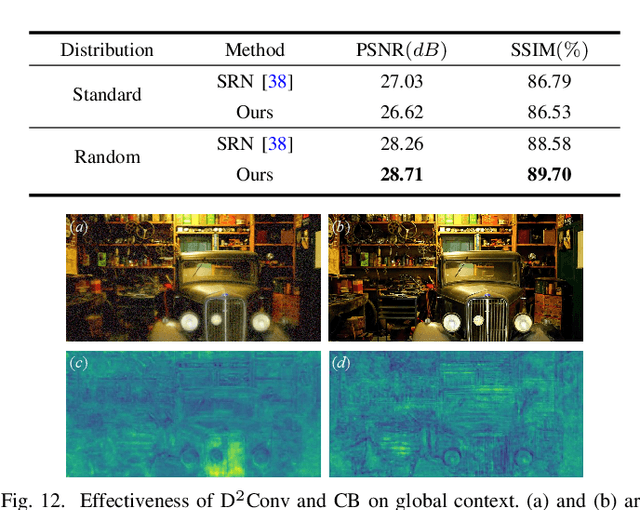
Panoramic Annular Lens (PAL), composed of few lenses, has great potential in panoramic surrounding sensing tasks for mobile and wearable devices because of its tiny size and large Field of View (FoV). However, the image quality of tiny-volume PAL confines to optical limit due to the lack of lenses for aberration correction. In this paper, we propose an Annular Computational Imaging (ACI) framework to break the optical limit of light-weight PAL design. To facilitate learning-based image restoration, we introduce a wave-based simulation pipeline for panoramic imaging and tackle the synthetic-to-real gap through multiple data distributions. The proposed pipeline can be easily adapted to any PAL with design parameters and is suitable for loose-tolerance designs. Furthermore, we design the Physics Informed Image Restoration Network (PI2RNet), considering the physical priors of panoramic imaging and physics-informed learning. At the dataset level, we create the DIVPano dataset and the extensive experiments on it illustrate that our proposed network sets the new state of the art in the panoramic image restoration under spatially-variant degradation. In addition, the evaluation of the proposed ACI on a simple PAL with only 3 spherical lenses reveals the delicate balance between high-quality panoramic imaging and compact design. To the best of our knowledge, we are the first to explore Computational Imaging (CI) in PAL. Code and datasets will be made publicly available at https://github.com/zju-jiangqi/ACI-PI2RNet.
Imaging through the Atmosphere using Turbulence Mitigation Transformer
Jul 13, 2022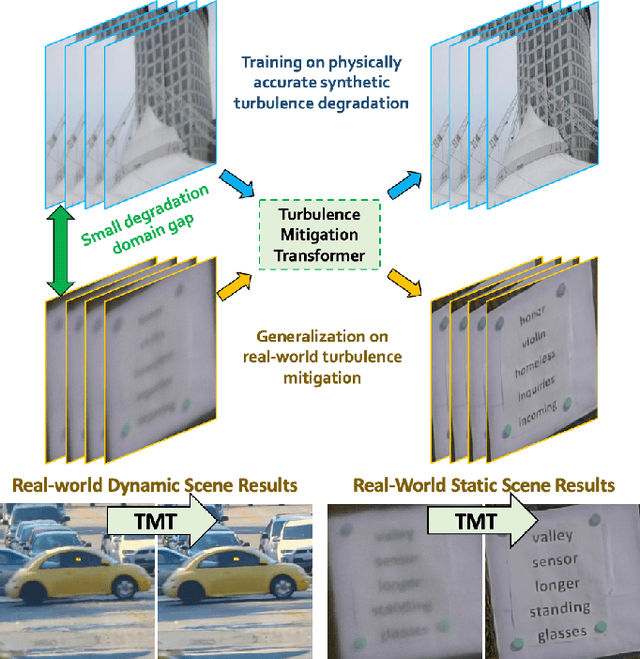



Restoring images distorted by atmospheric turbulence is a long-standing problem due to the spatially varying nature of the distortion, nonlinearity of the image formation process, and scarcity of training and testing data. Existing methods often have strong statistical assumptions on the distortion model which in many cases will lead to a limited performance in real-world scenarios as they do not generalize. To overcome the challenge, this paper presents an end-to-end physics-driven approach that is efficient and can generalize to real-world turbulence. On the data synthesis front, we significantly increase the image resolution that can be handled by the SOTA turbulence simulator by approximating the random field via wide-sense stationarity. The new data synthesis process enables the generation of large-scale multi-level turbulence and ground truth pairs for training. On the network design front, we propose the turbulence mitigation transformer (TMT), a two stage U-Net shaped multi-frame restoration network which has a noval efficient self-attention mechanism named temporal channel joint attention (TCJA). We also introduce a new training scheme that is enabled by the new simulator, and we design new transformer units to reduce the memory consumption. Experimental results on both static and dynamic scenes are promising, including various real turbulence scenarios.