 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
REGAS: REspiratory-GAted Synthesis of Views for Multi-Phase CBCT Reconstruction from a single 3D CBCT Acquisition
Aug 17, 2022
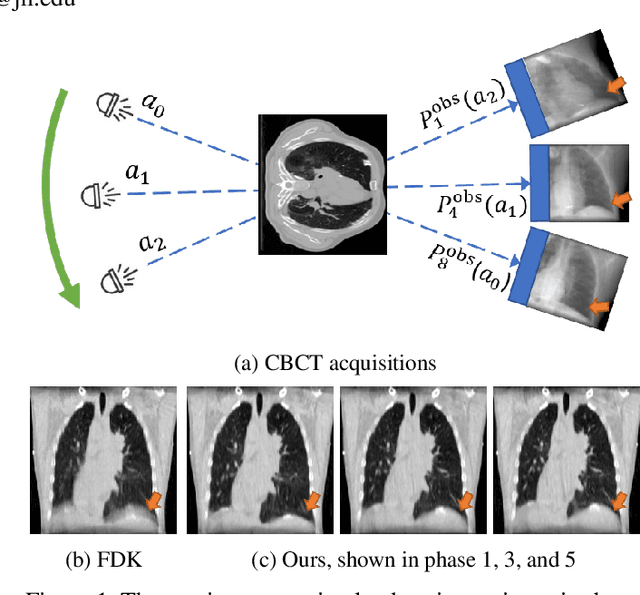
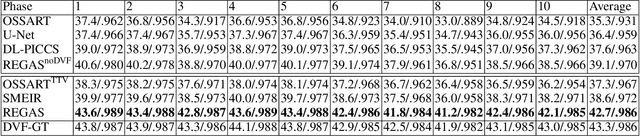
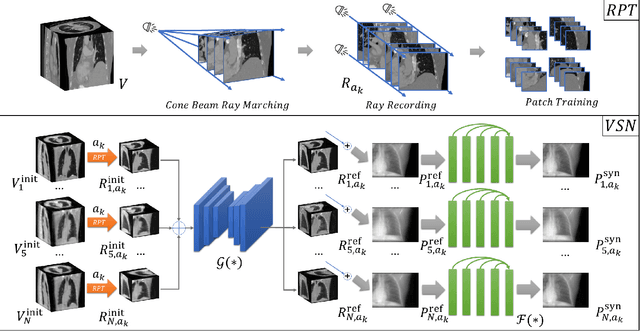
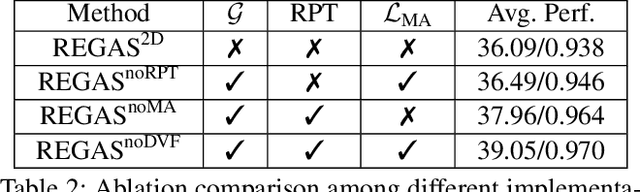
It is a long-standing challenge to reconstruct Cone Beam Computed Tomography (CBCT) of the lung under respiratory motion. This work takes a step further to address a challenging setting in reconstructing a multi-phase}4D lung image from just a single}3D CBCT acquisition. To this end, we introduce REpiratory-GAted Synthesis of views, or REGAS. REGAS proposes a self-supervised method to synthesize the undersampled tomographic views and mitigate aliasing artifacts in reconstructed images. This method allows a much better estimation of between-phase Deformation Vector Fields (DVFs), which are used to enhance reconstruction quality from direct observations without synthesis. To address the large memory cost of deep neural networks on high resolution 4D data, REGAS introduces a novel Ray Path Transformation (RPT) that allows for distributed, differentiable forward projections. REGAS require no additional measurements like prior scans, air-flow volume, or breathing velocity. Our extensive experiments show that REGAS significantly outperforms comparable methods in quantitative metrics and visual quality.
Self-Supervised Face Presentation Attack Detection with Dynamic Grayscale Snippets
Aug 27, 2022
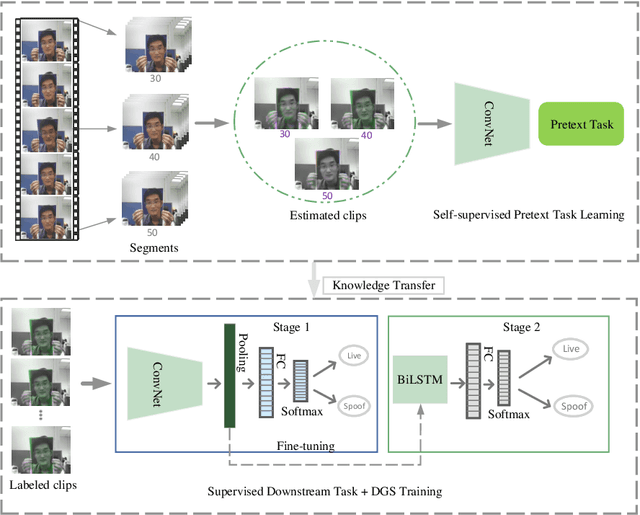
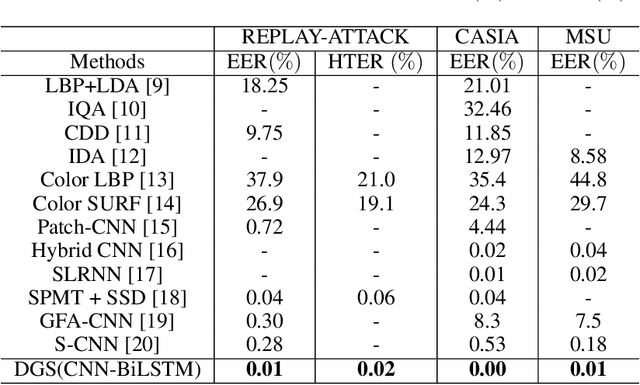
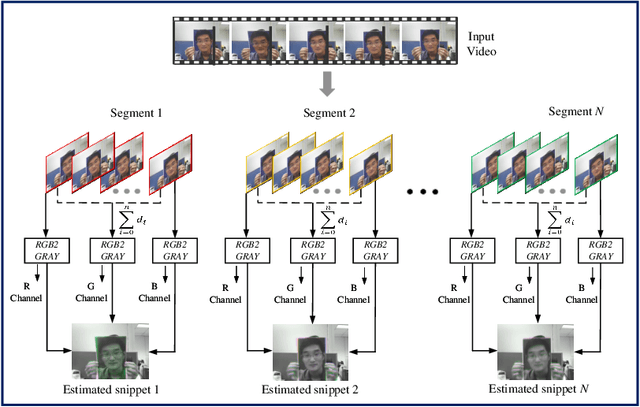
Face presentation attack detection (PAD) plays an important role in defending face recognition systems against presentation attacks. The success of PAD largely relies on supervised learning that requires a huge number of labeled data, which is especially challenging for videos and often requires expert knowledge. To avoid the costly collection of labeled data, this paper presents a novel method for self-supervised video representation learning via motion prediction. To achieve this, we exploit the temporal consistency based on three RGB frames which are acquired at three different times in the video sequence. The obtained frames are then transformed into grayscale images where each image is specified to three different channels such as R(red), G(green), and B(blue) to form a dynamic grayscale snippet (DGS). Motivated by this, the labels are automatically generated to increase the temporal diversity based on DGS by using the different temporal lengths of the videos, which prove to be very helpful for the downstream task. Benefiting from the self-supervised nature of our method, we report the results that outperform existing methods on four public benchmark datasets, namely Replay-Attack, MSU-MFSD, CASIA-FASD, and OULU-NPU. Explainability analysis has been carried out through LIME and Grad-CAM techniques to visualize the most important features used in the DGS.
STrajNet: Occupancy Flow Prediction via Multi-modal Swin Transformer
Jul 31, 2022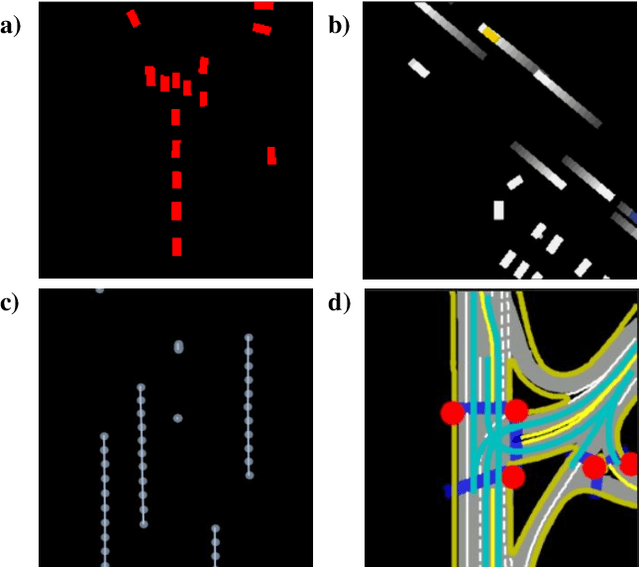

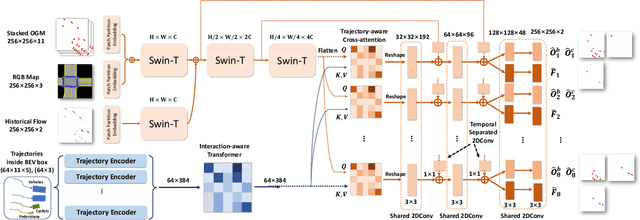
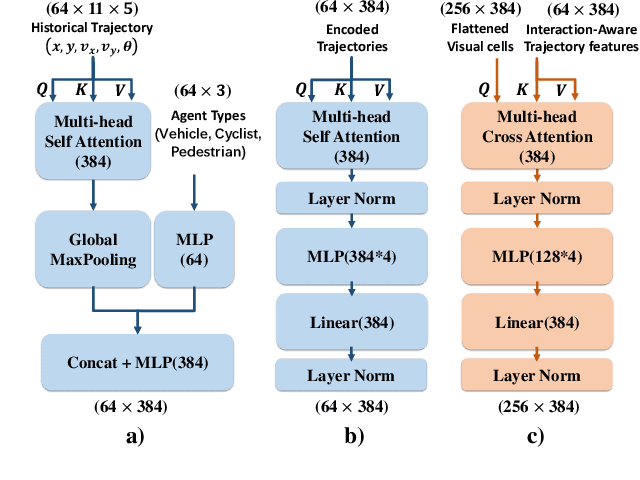
Making an accurate prediction of occupancy and flow is essential to enable better safety and interaction for autonomous vehicles under complex traffic scenarios. This work proposes STrajNet: a multi-modal Swin Transformerbased framework for effective scene occupancy and flow predictions. We employ Swin Transformer to encode the image and interaction-aware motion representations and propose a cross-attention module to inject motion awareness into grid cells across different time steps. Flow and occupancy predictions are then decoded through temporalsharing Pyramid decoders. The proposed method shows competitive prediction accuracy and other evaluation metrics in the Waymo Open Dataset benchmark.
Deep Learning Enabled Time-Lapse 3D Cell Analysis
Aug 17, 2022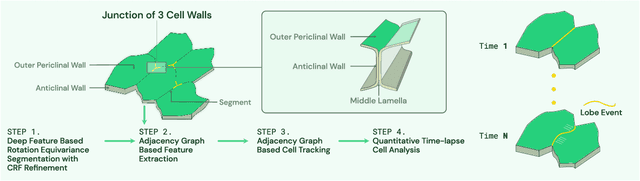
This paper presents a method for time-lapse 3D cell analysis. Specifically, we consider the problem of accurately localizing and quantitatively analyzing sub-cellular features, and for tracking individual cells from time-lapse 3D confocal cell image stacks. The heterogeneity of cells and the volume of multi-dimensional images presents a major challenge for fully automated analysis of morphogenesis and development of cells. This paper is motivated by the pavement cell growth process, and building a quantitative morphogenesis model. We propose a deep feature based segmentation method to accurately detect and label each cell region. An adjacency graph based method is used to extract sub-cellular features of the segmented cells. Finally, the robust graph based tracking algorithm using multiple cell features is proposed for associating cells at different time instances. Extensive experiment results are provided and demonstrate the robustness of the proposed method. The code is available on Github and the method is available as a service through the BisQue portal.
Optimized Views Photogrammetry: Precision Analysis and A Large-scale Case Study in Qingdao
Jun 24, 2022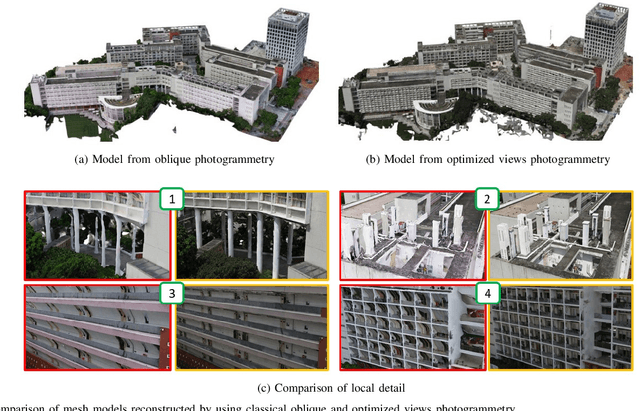


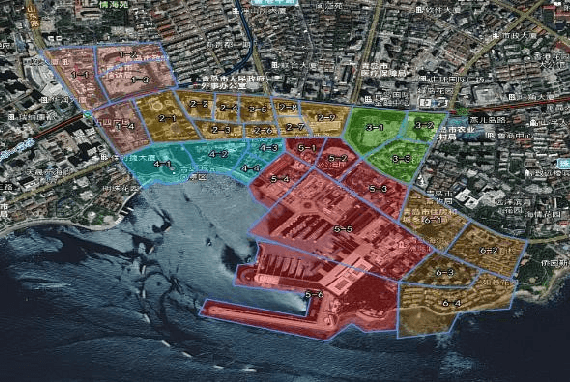
UAVs have become one of the widely used remote sensing platforms and played a critical role in the construction of smart cities. However, due to the complex environment in urban scenes, secure and accurate data acquisition brings great challenges to 3D modeling and scene updating. Optimal trajectory planning of UAVs and accurate data collection of onboard cameras are non-trivial issues in urban modeling. This study presents the principle of optimized views photogrammetry and verifies its precision and potential in large-scale 3D modeling. Different from oblique photogrammetry, optimized views photogrammetry uses rough models to generate and optimize UAV trajectories, which is achieved through the consideration of model point reconstructability and view point redundancy. Based on the principle of optimized views photogrammetry, this study first conducts a precision analysis of 3D models by using UAV images of optimized views photogrammetry and then executes a large-scale case study in the urban region of Qingdao city, China, to verify its engineering potential. By using GCPs for image orientation precision analysis and TLS (terrestrial laser scanning) point clouds for model quality analysis, experimental results show that optimized views photogrammetry could construct stable image connection networks and could achieve comparable image orientation accuracy. Benefiting from the accurate image acquisition strategy, the quality of mesh models significantly improves, especially for urban areas with serious occlusions, in which 3 to 5 times of higher accuracy has been achieved. Besides, the case study in Qingdao city verifies that optimized views photogrammetry can be a reliable and powerful solution for the large-scale 3D modeling in complex urban scenes.
Sparse Subspace Clustering Friendly Deep Dictionary Learning for Hyperspectral Image Classification
Nov 27, 2021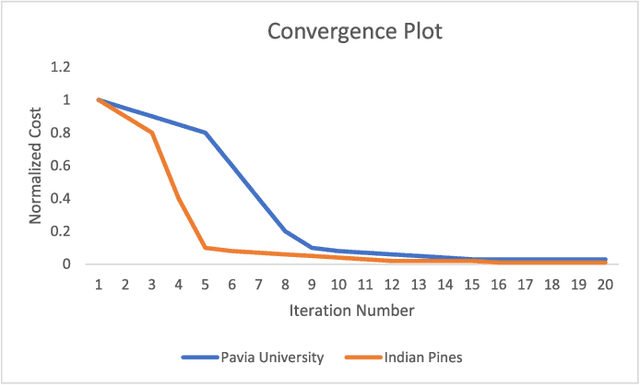
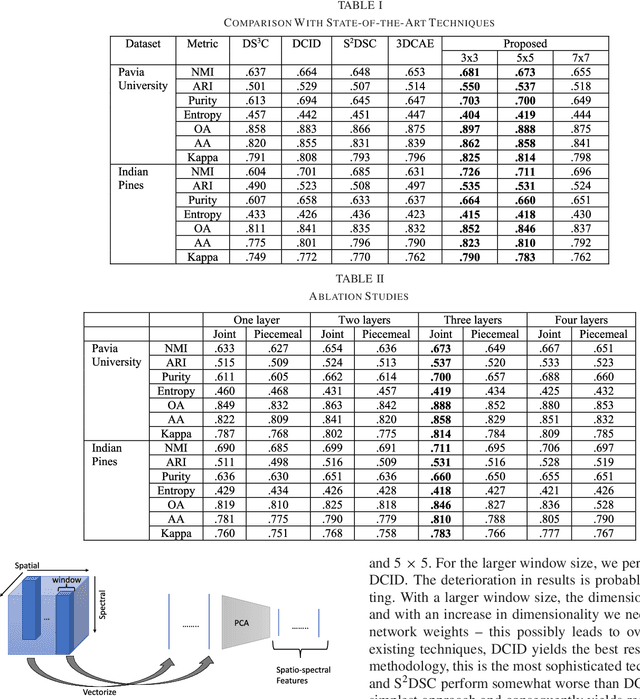
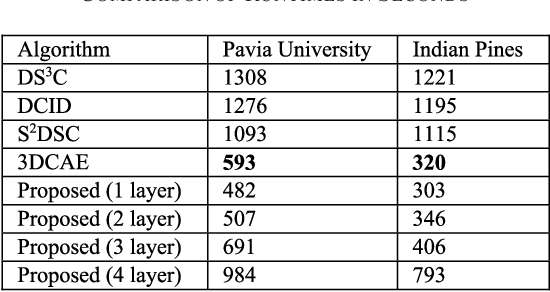
Subspace clustering techniques have shown promise in hyperspectral image segmentation. The fundamental assumption in subspace clustering is that the samples belonging to different clusters/segments lie in separable subspaces. What if this condition does not hold? We surmise that even if the condition does not hold in the original space, the data may be nonlinearly transformed to a space where it will be separable into subspaces. In this work, we propose a transformation based on the tenets of deep dictionary learning (DDL). In particular, we incorporate the sparse subspace clustering (SSC) loss in the DDL formulation. Here DDL nonlinearly transforms the data such that the transformed representation (of the data) is separable into subspaces. We show that the proposed formulation improves over the state-of-the-art deep learning techniques in hyperspectral image clustering.
Calibrate the inter-observer segmentation uncertainty via diagnosis-first principle
Aug 05, 2022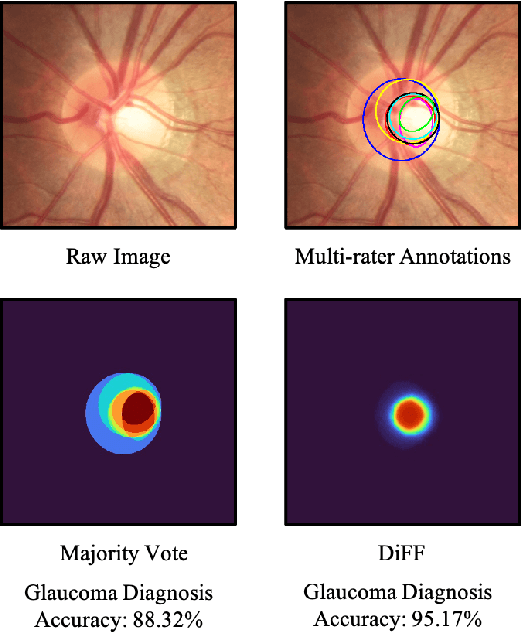
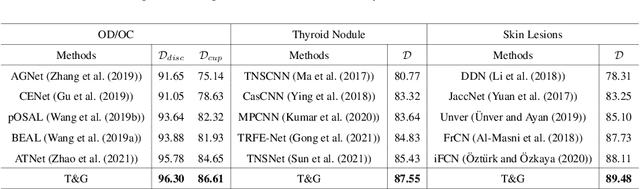
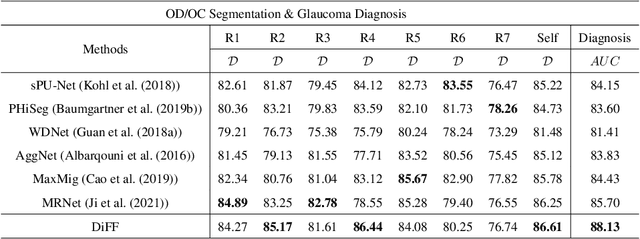
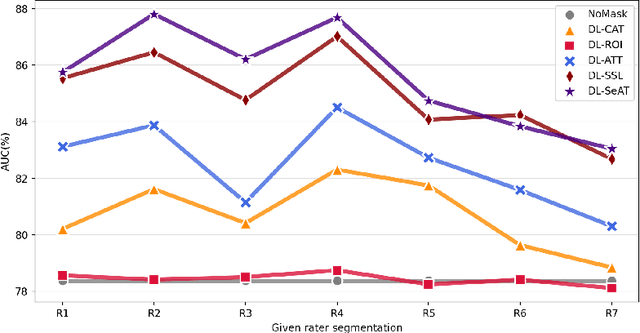
On the medical images, many of the tissues/lesions may be ambiguous. That is why the medical segmentation is typically annotated by a group of clinical experts to mitigate the personal bias. However, this clinical routine also brings new challenges to the application of machine learning algorithms. Without a definite ground-truth, it will be difficult to train and evaluate the deep learning models. When the annotations are collected from different graders, a common choice is majority vote. However such a strategy ignores the difference between the grader expertness. In this paper, we consider the task of predicting the segmentation with the calibrated inter-observer uncertainty. We note that in clinical practice, the medical image segmentation is usually used to assist the disease diagnosis. Inspired by this observation, we propose diagnosis-first principle, which is to take disease diagnosis as the criterion to calibrate the inter-observer segmentation uncertainty. Following this idea, a framework named Diagnosis First segmentation Framework (DiFF) is proposed to estimate diagnosis-first segmentation from the raw images.Specifically, DiFF will first learn to fuse the multi-rater segmentation labels to a single ground-truth which could maximize the disease diagnosis performance. We dubbed the fused ground-truth as Diagnosis First Ground-truth (DF-GT).Then, we further propose Take and Give Modelto segment DF-GT from the raw image. We verify the effectiveness of DiFF on three different medical segmentation tasks: OD/OC segmentation on fundus images, thyroid nodule segmentation on ultrasound images, and skin lesion segmentation on dermoscopic images. Experimental results show that the proposed DiFF is able to significantly facilitate the corresponding disease diagnosis, which outperforms previous state-of-the-art multi-rater learning methods.
A Literature Review of 3D Face Reconstruction From a Single Image
Oct 13, 2021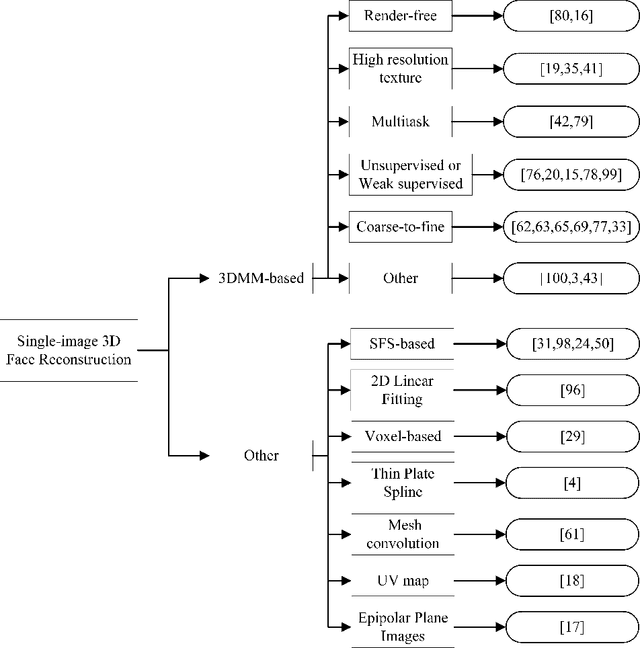
This paper is a brief survey of the recent literature on 3D face reconstruction from a single image. Most articles have been choosen among 2016 and 2020, in order to provide the most up-to-date view of the single image 3D face reconstruction.
Cut Inner Layers: A Structured Pruning Strategy for Efficient U-Net GANs
Jun 29, 2022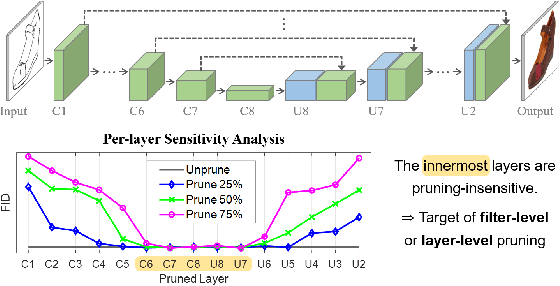
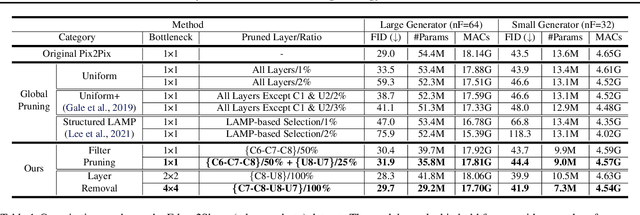
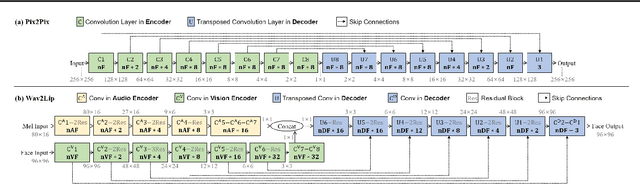
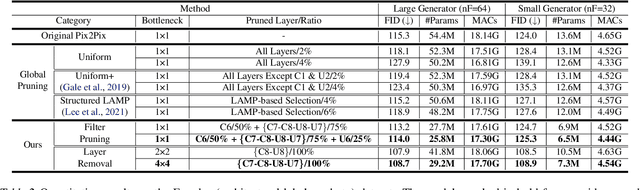
Pruning effectively compresses overparameterized models. Despite the success of pruning methods for discriminative models, applying them for generative models has been relatively rarely approached. This study conducts structured pruning on U-Net generators of conditional GANs. A per-layer sensitivity analysis confirms that many unnecessary filters exist in the innermost layers near the bottleneck and can be substantially pruned. Based on this observation, we prune these filters from multiple inner layers or suggest alternative architectures by completely eliminating the layers. We evaluate our approach with Pix2Pix for image-to-image translation and Wav2Lip for speech-driven talking face generation. Our method outperforms global pruning baselines, demonstrating the importance of properly considering where to prune for U-Net generators.
Eformer: Edge Enhancement based Transformer for Medical Image Denoising
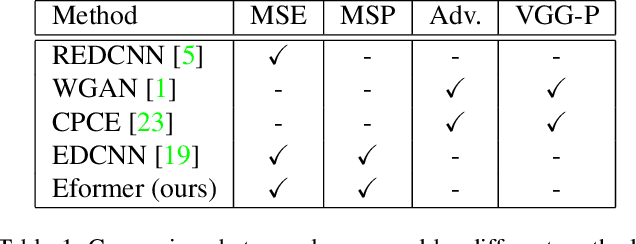
Sep 16, 2021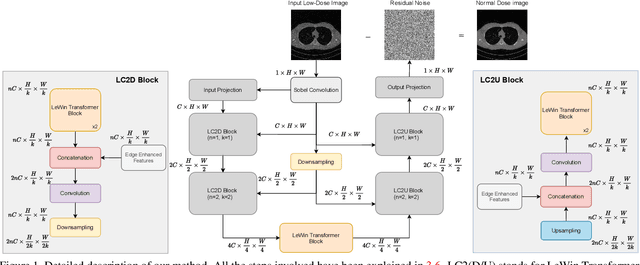
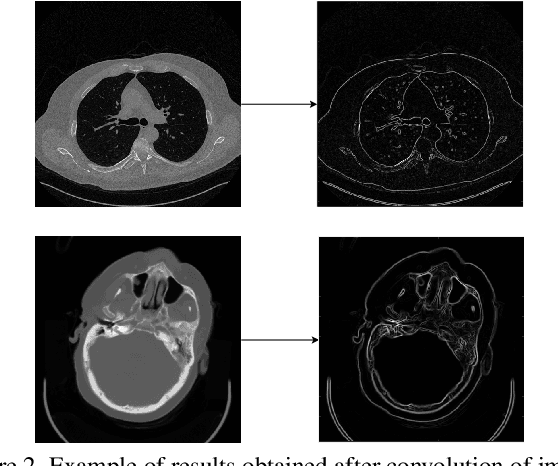
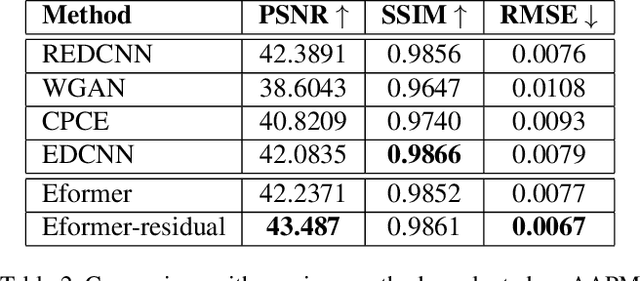
In this work, we present Eformer - Edge enhancement based transformer, a novel architecture that builds an encoder-decoder network using transformer blocks for medical image denoising. Non-overlapping window-based self-attention is used in the transformer block that reduces computational requirements. This work further incorporates learnable Sobel-Feldman operators to enhance edges in the image and propose an effective way to concatenate them in the intermediate layers of our architecture. The experimental analysis is conducted by comparing deterministic learning and residual learning for the task of medical image denoising. To defend the effectiveness of our approach, our model is evaluated on the AAPM-Mayo Clinic Low-Dose CT Grand Challenge Dataset and achieves state-of-the-art performance, $i.e.$, 43.487 PSNR, 0.0067 RMSE, and 0.9861 SSIM. We believe that our work will encourage more research in transformer-based architectures for medical image denoising using residual learning.