 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Adaptive Non-linear Filtering Technique for Image Restoration
Apr 20, 2022
Removing noise from the any processed images is very important. Noise should be removed in such a way that important information of image should be preserved. A decisionbased nonlinear algorithm for elimination of band lines, drop lines, mark, band lost and impulses in images is presented in this paper. The algorithm performs two simultaneous operations, namely, detection of corrupted pixels and evaluation of new pixels for replacing the corrupted pixels. Removal of these artifacts is achieved without damaging edges and details. However, the restricted window size renders median operation less effective whenever noise is excessive in that case the proposed algorithm automatically switches to mean filtering. The performance of the algorithm is analyzed in terms of Mean Square Error [MSE], Peak-Signal-to-Noise Ratio [PSNR], Signal-to-Noise Ratio Improved [SNRI], Percentage Of Noise Attenuated [PONA], and Percentage Of Spoiled Pixels [POSP]. This is compared with standard algorithms already in use and improved performance of the proposed algorithm is presented. The advantage of the proposed algorithm is that a single algorithm can replace several independent algorithms which are required for removal of different artifacts.
* Accepted. arXiv admin note: text overlap with arXiv:1003.1827 by other authors
Image quality measurements and denoising using Fourier Ring Correlations
Jan 11, 2022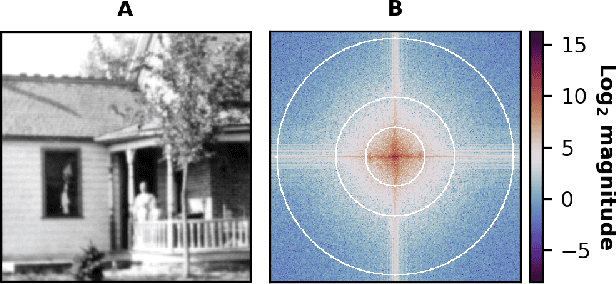
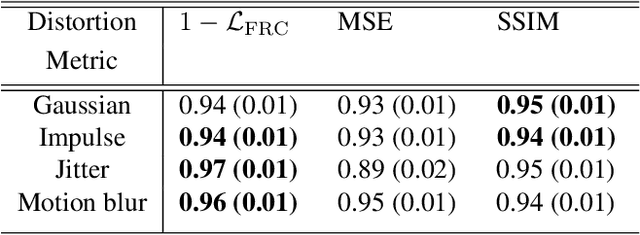
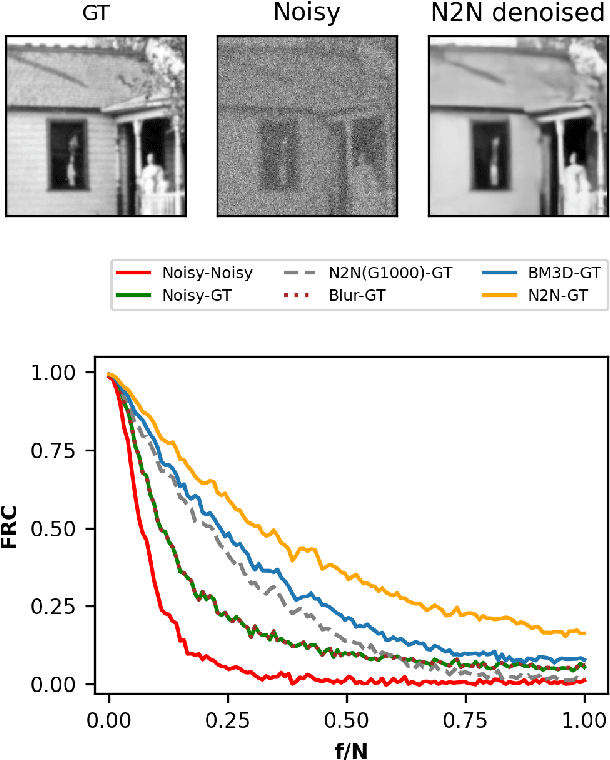
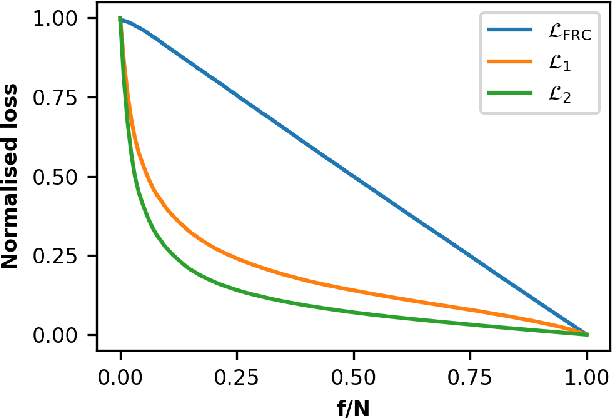
Image quality is a nebulous concept with different meanings to different people. To quantify image quality a relative difference is typically calculated between a corrupted image and a ground truth image. But what metric should we use for measuring this difference? Ideally, the metric should perform well for both natural and scientific images. The structural similarity index (SSIM) is a good measure for how humans perceive image similarities, but is not sensitive to differences that are scientifically meaningful in microscopy. In electron and super-resolution microscopy, the Fourier Ring Correlation (FRC) is often used, but is little known outside of these fields. Here we show that the FRC can equally well be applied to natural images, e.g. the Google Open Images dataset. We then define a loss function based on the FRC, show that it is analytically differentiable, and use it to train a U-net for denoising of images. This FRC-based loss function allows the network to train faster and achieve similar or better results than when using L1- or L2- based losses. We also investigate the properties and limitations of neural network denoising with the FRC analysis.
S2MS: Self-Supervised Learning Driven Multi-Spectral CT Image Enhancement
Jan 26, 2022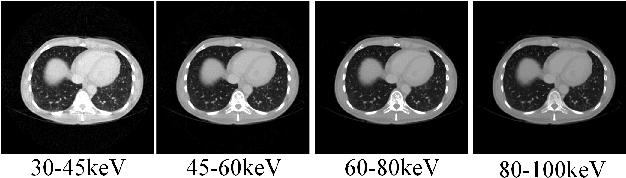
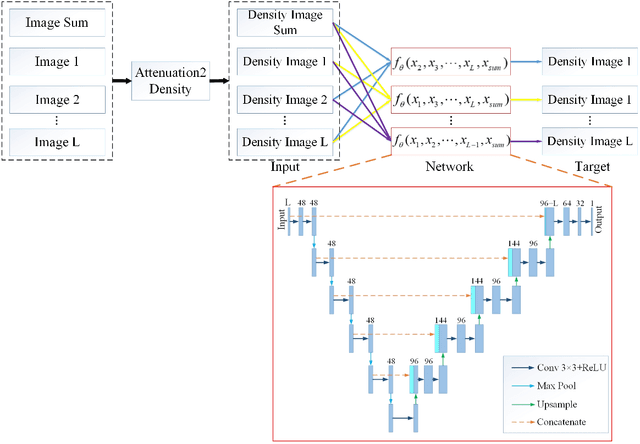
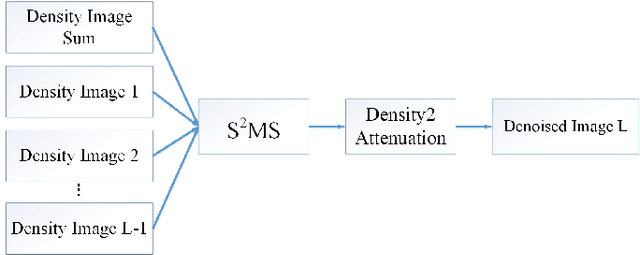
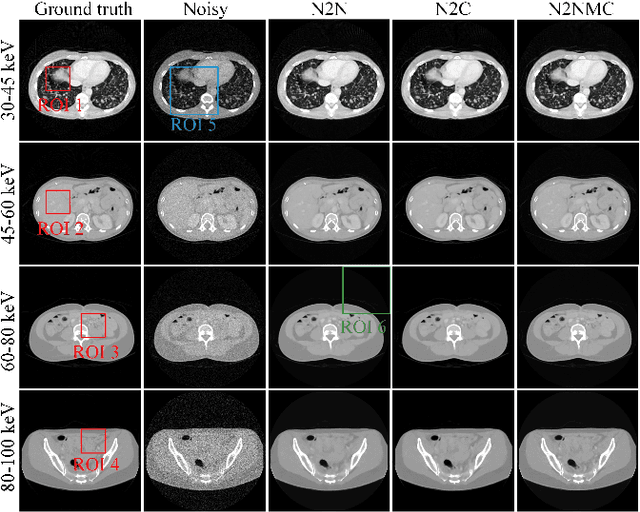
Photon counting spectral CT (PCCT) can produce reconstructed attenuation maps in different energy channels, reflecting energy properties of the scanned object. Due to the limited photon numbers and the non-ideal detector response of each energy channel, the reconstructed images usually contain much noise. With the development of Deep Learning (DL) technique, different kinds of DL-based models have been proposed for noise reduction. However, most of the models require clean data set as the training labels, which are not always available in medical imaging field. Inspiring by the similarities of each channel's reconstructed image, we proposed a self-supervised learning based PCCT image enhancement framework via multi-spectral channels (S2MS). In S2MS framework, both the input and output labels are noisy images. Specifically, one single channel image was used as output while images of other single channels and channel-sum image were used as input to train the network, which can fully use the spectral data information without extra cost. The simulation results based on the AAPM Low-dose CT Challenge database showed that the proposed S2MS model can suppress the noise and preserve details more effectively in comparison with the traditional DL models, which has potential to improve the image quality of PCCT in clinical applications.
Multiple Instance Learning via Iterative Self-Paced Supervised Contrastive Learning
Oct 17, 2022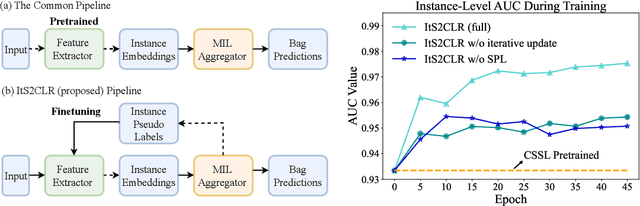
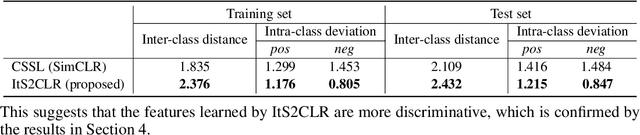
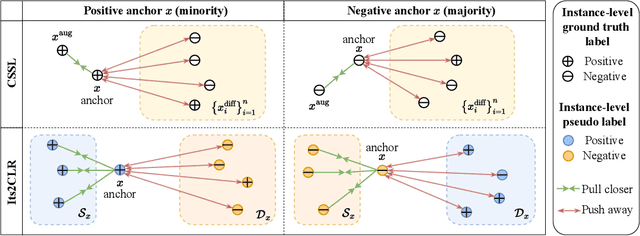

Learning representations for individual instances when only bag-level labels are available is a fundamental challenge in multiple instance learning (MIL). Recent works have shown promising results using contrastive self-supervised learning (CSSL), which learns to push apart representations corresponding to two different randomly-selected instances. Unfortunately, in real-world applications such as medical image classification, there is often class imbalance, so randomly-selected instances mostly belong to the same majority class, which precludes CSSL from learning inter-class differences. To address this issue, we propose a novel framework, Iterative Self-paced Supervised Contrastive Learning for MIL Representations (ItS2CLR), which improves the learned representation by exploiting instance-level pseudo labels derived from the bag-level labels. The framework employs a novel self-paced sampling strategy to ensure the accuracy of pseudo labels. We evaluate ItS2CLR on three medical datasets, showing that it improves the quality of instance-level pseudo labels and representations, and outperforms existing MIL methods in terms of both bag and instance level accuracy.
A Novel Membership Inference Attack against Dynamic Neural Networks by Utilizing Policy Networks Information
Oct 17, 2022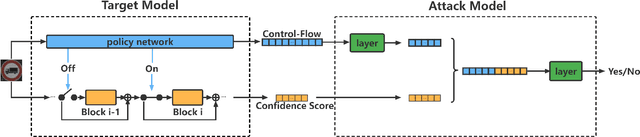
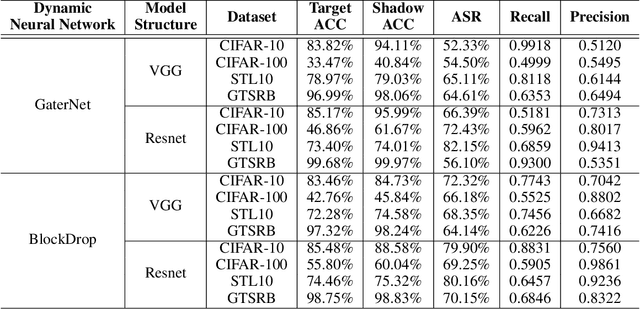
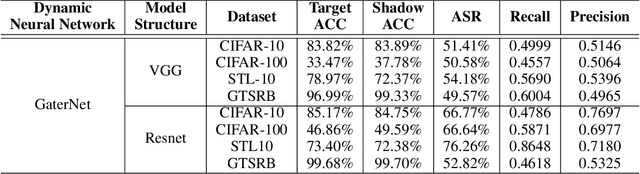

Unlike traditional static deep neural networks (DNNs), dynamic neural networks (NNs) adjust their structures or parameters to different inputs to guarantee accuracy and computational efficiency. Meanwhile, it has been an emerging research area in deep learning recently. Although traditional static DNNs are vulnerable to the membership inference attack (MIA) , which aims to infer whether a particular point was used to train the model, little is known about how such an attack performs on the dynamic NNs. In this paper, we propose a novel MI attack against dynamic NNs, leveraging the unique policy networks mechanism of dynamic NNs to increase the effectiveness of membership inference. We conducted extensive experiments using two dynamic NNs, i.e., GaterNet, BlockDrop, on four mainstream image classification tasks, i.e., CIFAR-10, CIFAR-100, STL-10, and GTSRB. The evaluation results demonstrate that the control-flow information can significantly promote the MIA. Based on backbone-finetuning and information-fusion, our method achieves better results than baseline attack and traditional attack using intermediate information.
ArtFacePoints: High-resolution Facial Landmark Detection in Paintings and Prints
Oct 17, 2022
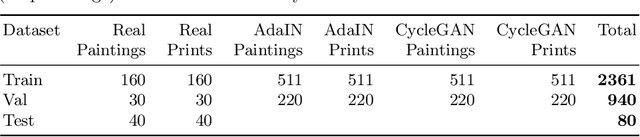

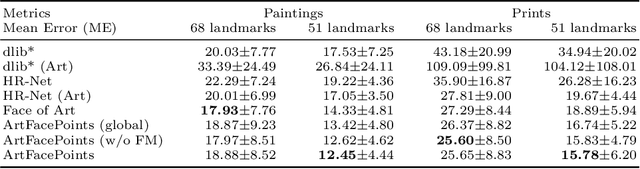
Facial landmark detection plays an important role for the similarity analysis in artworks to compare portraits of the same or similar artists. With facial landmarks, portraits of different genres, such as paintings and prints, can be automatically aligned using control-point-based image registration. We propose a deep-learning-based method for facial landmark detection in high-resolution images of paintings and prints. It divides the task into a global network for coarse landmark prediction and multiple region networks for precise landmark refinement in regions of the eyes, nose, and mouth that are automatically determined based on the predicted global landmark coordinates. We created a synthetically augmented facial landmark art dataset including artistic style transfer and geometric landmark shifts. Our method demonstrates an accurate detection of the inner facial landmarks for our high-resolution dataset of artworks while being comparable for a public low-resolution artwork dataset in comparison to competing methods.
Massive MIMO Channel Prediction Via Meta-Learning and Deep Denoising: Is a Small Dataset Enough?
Oct 17, 2022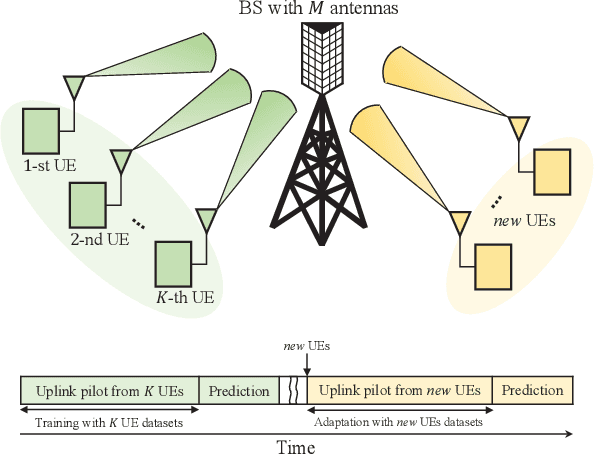
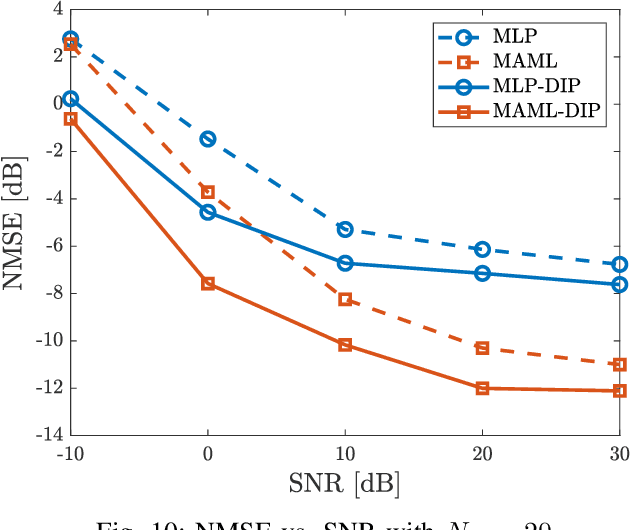
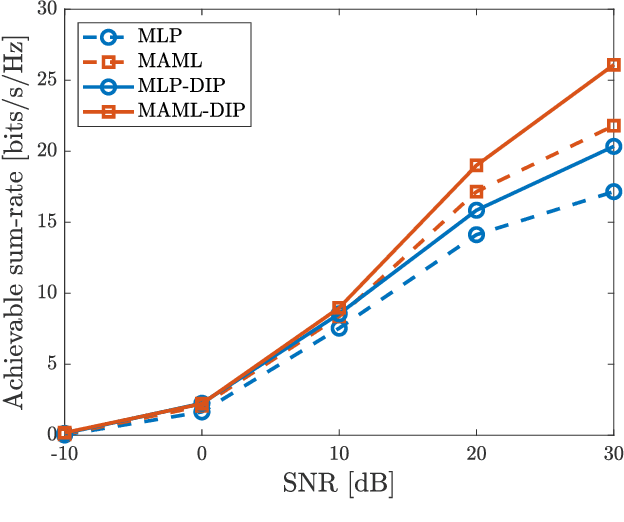
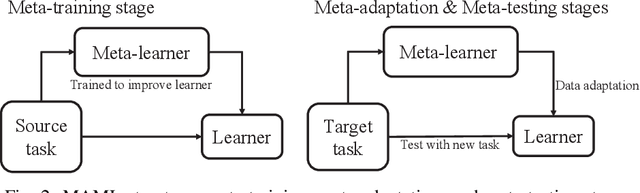
Accurate channel knowledge is critical in massive multiple-input multiple-output (MIMO), which motivates the use of channel prediction. Machine learning techniques for channel prediction hold much promise, but current schemes are limited in their ability to adapt to changes in the environment because they require large training overheads. To accurately predict wireless channels for new environments with reduced training overhead, we propose a fast adaptive channel prediction technique based on a meta-learning algorithm for massive MIMO communications. We exploit the model-agnostic meta-learning (MAML) algorithm to achieve quick adaptation with a small amount of labeled data. Also, to improve the prediction accuracy, we adopt the denoising process for the training data by using deep image prior (DIP). Numerical results show that the proposed MAML-based channel predictor can improve the prediction accuracy with only a few fine-tuning samples. The DIP-based denoising process gives an additional gain in channel prediction, especially in low signal-to-noise ratio regimes.
Comparison of semi-supervised learning methods for High Content Screening quality control
Aug 09, 2022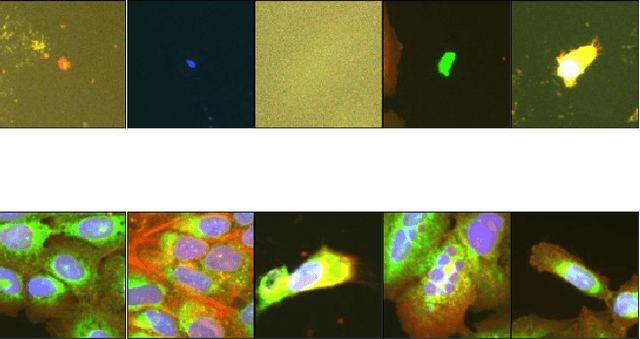
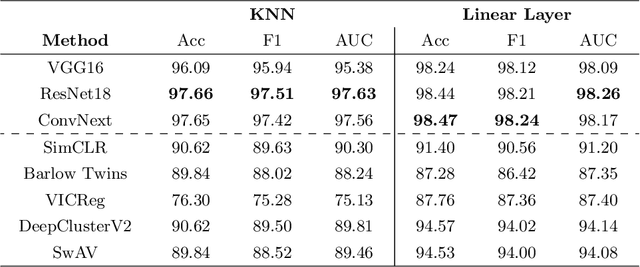
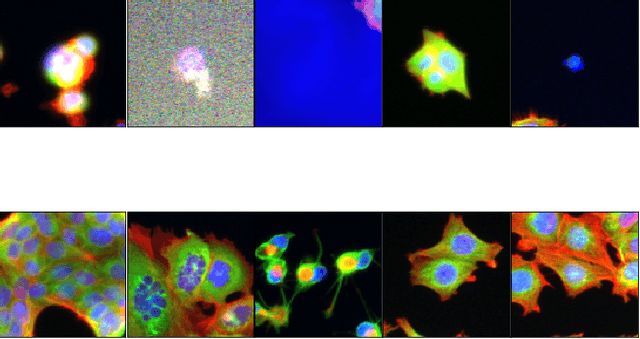
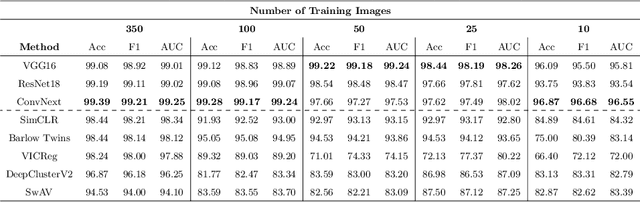
Progress in automated microscopy and quantitative image analysis has promoted high-content screening (HCS) as an efficient drug discovery and research tool. While HCS offers to quantify complex cellular phenotypes from images at high throughput, this process can be obstructed by image aberrations such as out-of-focus image blur, fluorophore saturation, debris, a high level of noise, unexpected auto-fluorescence or empty images. While this issue has received moderate attention in the literature, overlooking these artefacts can seriously hamper downstream image processing tasks and hinder detection of subtle phenotypes. It is therefore of primary concern, and a prerequisite, to use quality control in HCS. In this work, we evaluate deep learning options that do not require extensive image annotations to provide a straightforward and easy to use semi-supervised learning solution to this issue. Concretely, we compared the efficacy of recent self-supervised and transfer learning approaches to provide a base encoder to a high throughput artefact image detector. The results of this study suggest that transfer learning methods should be preferred for this task as they not only performed best here but present the advantage of not requiring sensitive hyperparameter settings nor extensive additional training.
PatchDropout: Economizing Vision Transformers Using Patch Dropout
Aug 10, 2022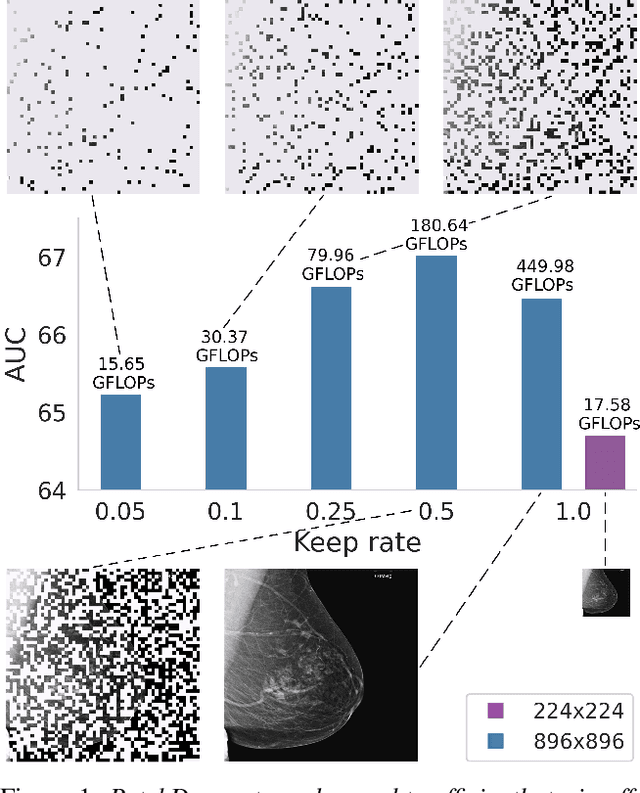
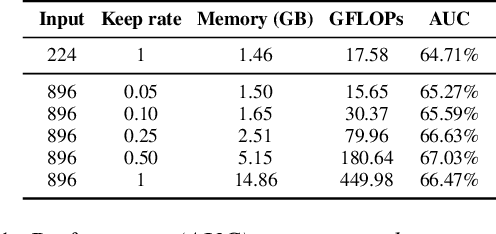
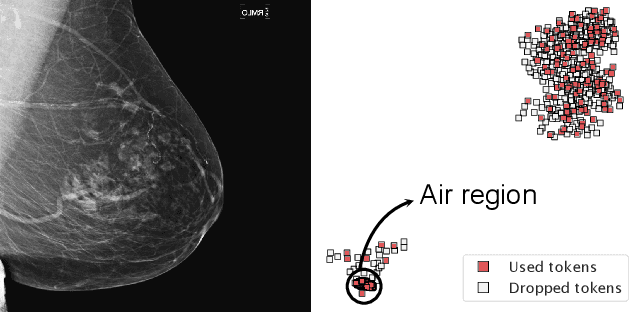
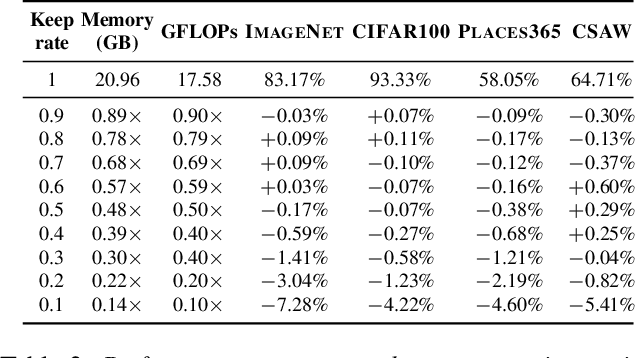
Vision transformers have demonstrated the potential to outperform CNNs in a variety of vision tasks. But the computational and memory requirements of these models prohibit their use in many applications, especially those that depend on high-resolution images, such as medical image classification. Efforts to train ViTs more efficiently are overly complicated, necessitating architectural changes or intricate training schemes. In this work, we show that standard ViT models can be efficiently trained at high resolution by randomly dropping input image patches. This simple approach, PatchDropout, reduces FLOPs and memory by at least 50% in standard natural image datasets such as ImageNet, and those savings only increase with image size. On CSAW, a high-resolution medical dataset, we observe a 5 times savings in computation and memory using PatchDropout, along with a boost in performance. For practitioners with a fixed computational or memory budget, PatchDropout makes it possible to choose image resolution, hyperparameters, or model size to get the most performance out of their model.
Automatic Diagnosis of Myocarditis Disease in Cardiac MRI Modality using Deep Transformers and Explainable Artificial Intelligence
Oct 26, 2022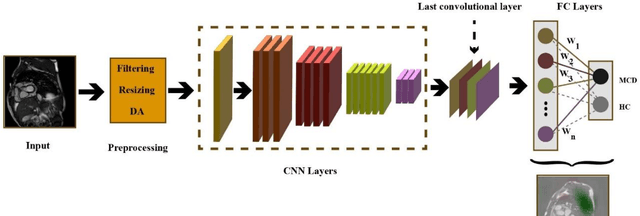
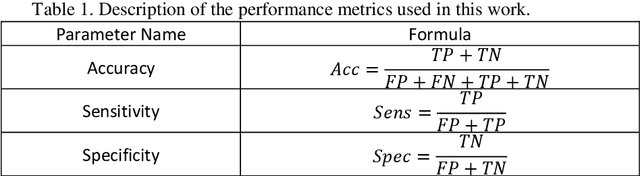
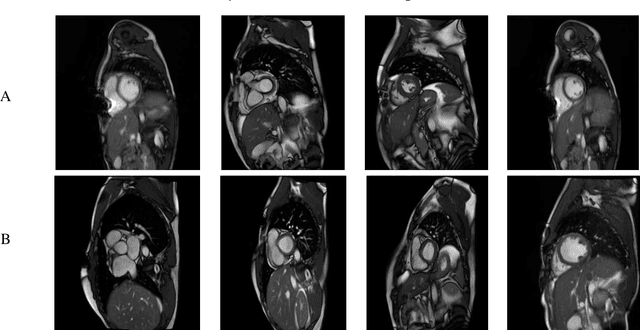
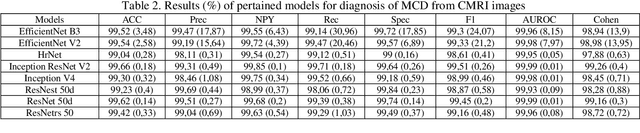
Myocarditis is among the most important cardiovascular diseases (CVDs), endangering the health of many individuals by damaging the myocardium. Microbes and viruses, such as HIV, play a vital role in myocarditis disease (MCD) incidence. Lack of MCD diagnosis in the early stages is associated with irreversible complications. Cardiac magnetic resonance imaging (CMRI) is highly popular among cardiologists to diagnose CVDs. In this paper, a deep learning (DL) based computer-aided diagnosis system (CADS) is presented for the diagnosis of MCD using CMRI images. The proposed CADS includes dataset, preprocessing, feature extraction, classification, and post-processing steps. First, the Z-Alizadeh dataset was selected for the experiments. The preprocessing step included noise removal, image resizing, and data augmentation (DA). In this step, CutMix, and MixUp techniques were used for the DA. Then, the most recent pre-trained and transformers models were used for feature extraction and classification using CMRI images. Our results show high performance for the detection of MCD using transformer models compared with the pre-trained architectures. Among the DL architectures, Turbulence Neural Transformer (TNT) architecture achieved an accuracy of 99.73% with 10-fold cross-validation strategy. Explainable-based Grad Cam method is used to visualize the MCD suspected areas in CMRI images.