 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CAIR: Fast and Lightweight Multi-Scale Color Attention Network for Instagram Filter Removal
Aug 30, 2022

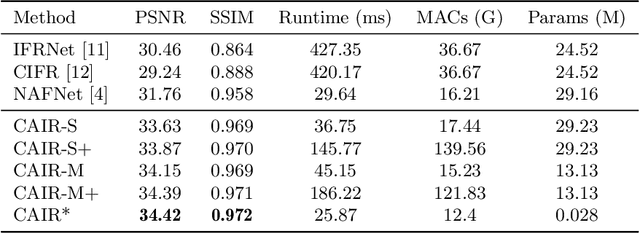
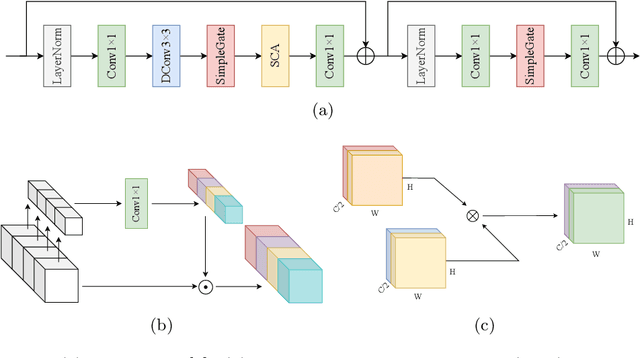
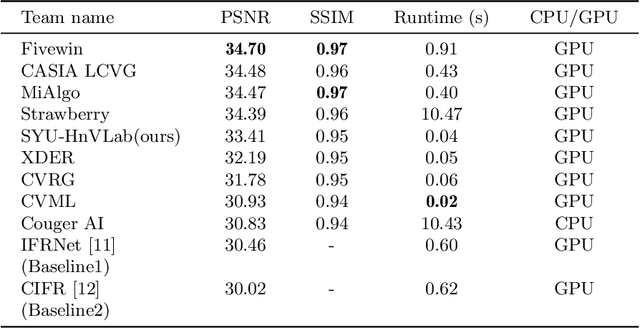
Image restoration is an important and challenging task in computer vision. Reverting a filtered image to its original image is helpful in various computer vision tasks. We employ a nonlinear activation function free network (NAFNet) for a fast and lightweight model and add a color attention module that extracts useful color information for better accuracy. We propose an accurate, fast, lightweight network with multi-scale and color attention for Instagram filter removal (CAIR). Experiment results show that the proposed CAIR outperforms existing Instagram filter removal networks in fast and lightweight ways, about 11$\times$ faster and 2.4$\times$ lighter while exceeding 3.69 dB PSNR on IFFI dataset. CAIR can successfully remove the Instagram filter with high quality and restore color information in qualitative results. The source code and pretrained weights are available at \url{https://github.com/HnV-Lab/CAIR}.
HiMFR: A Hybrid Masked Face Recognition Through Face Inpainting
Sep 19, 2022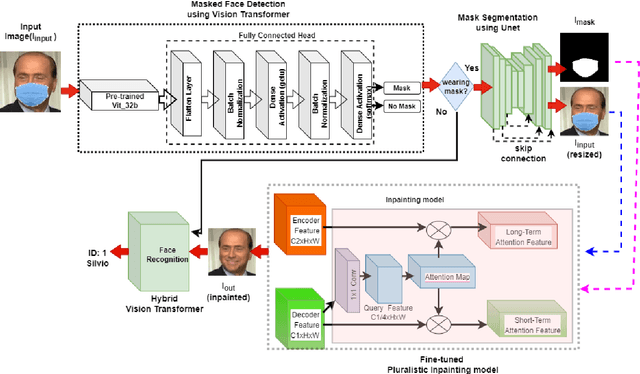
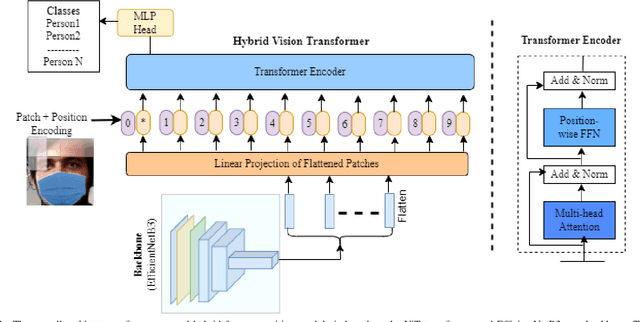


To recognize the masked face, one of the possible solutions could be to restore the occluded part of the face first and then apply the face recognition method. Inspired by the recent image inpainting methods, we propose an end-to-end hybrid masked face recognition system, namely HiMFR, consisting of three significant parts: masked face detector, face inpainting, and face recognition. The masked face detector module applies a pretrained Vision Transformer (ViT\_b32) to detect whether faces are covered with masked or not. The inpainting module uses a fine-tune image inpainting model based on a Generative Adversarial Network (GAN) to restore faces. Finally, the hybrid face recognition module based on ViT with an EfficientNetB3 backbone recognizes the faces. We have implemented and evaluated our proposed method on four different publicly available datasets: CelebA, SSDMNV2, MAFA, {Pubfig83} with our locally collected small dataset, namely Face5. Comprehensive experimental results show the efficacy of the proposed HiMFR method with competitive performance. Code is available at https://github.com/mdhosen/HiMFR
Interactive Machine Learning for Image Captioning
Feb 28, 2022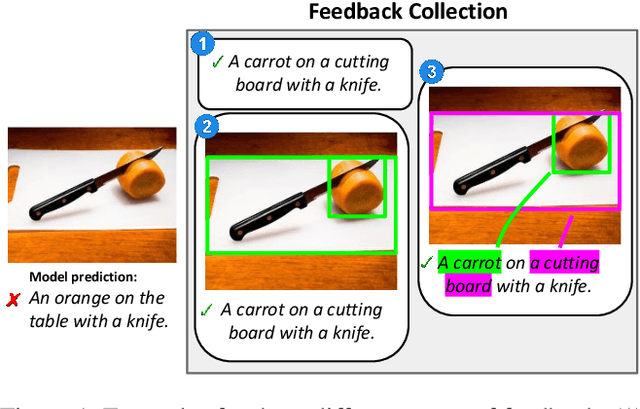
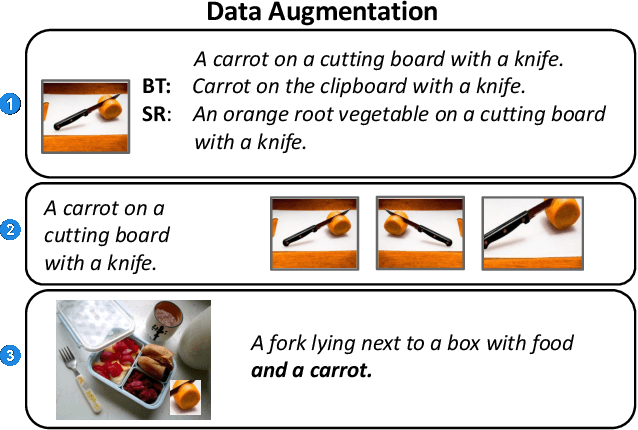
We propose an approach for interactive learning for an image captioning model. As human feedback is expensive and modern neural network based approaches often require large amounts of supervised data to be trained, we envision a system that exploits human feedback as good as possible by multiplying the feedback using data augmentation methods, and integrating the resulting training examples into the model in a smart way. This approach has three key components, for which we need to find suitable practical implementations: feedback collection, data augmentation, and model update. We outline our idea and review different possibilities to address these tasks.
The Concurrent Use of Medical Imaging Modalities and Innovative Treatments to Combat Retinitis Pigmentosa
Nov 08, 2022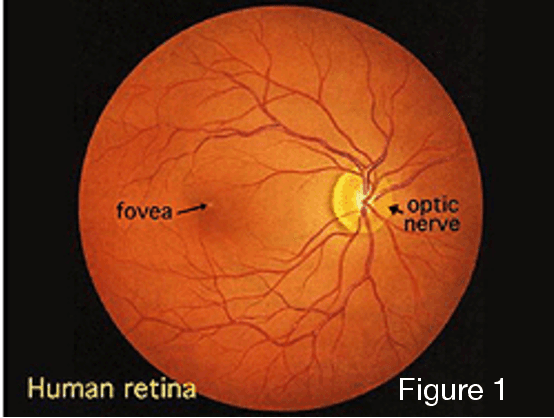
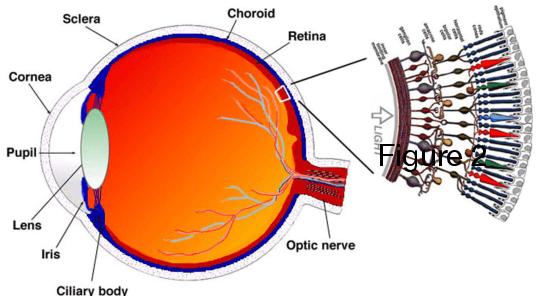
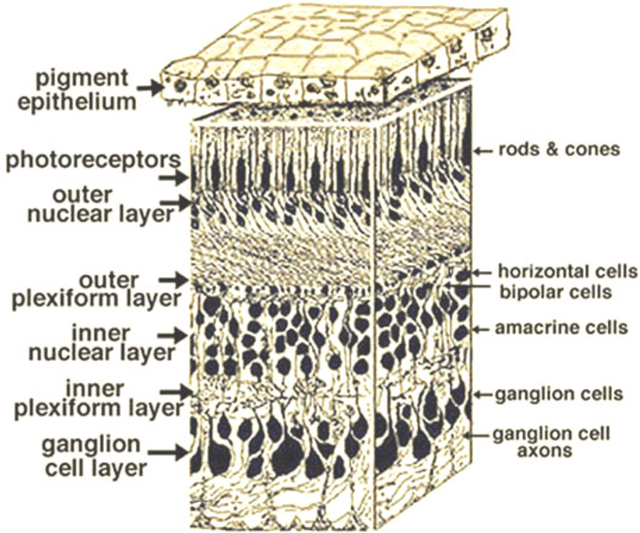
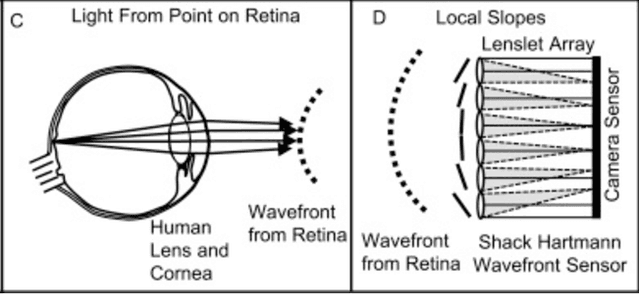
Retinitis pigmentosa (RP), one of the leading causes of vision loss and blindness globally, is a progressive retinal disease involving the degradation of photoreceptors (7) and/or retinal pigment epithelial cells (14). Affecting approximately 1 in 4000 people, RP is caused by a series of genetic mutations; each specific mutation presents a specific pathological pattern in the patient, with the same mutation even presenting in different phenotypes in different patients (14). RP generally starts with peripheral vision loss, attacking the rods first, causing nyctalopia or night blindness (22). In later stages of the disease, the cones start to atrophy, further narrowing the field of vision and obscuring central vision (22). Luckily, with recent advances in medical imaging techniques and novel therapeutic treatments, both early detection and the overall prognosis of RP in patients have improved dramatically in the past few decades. This review will trace RP's physiological causes, how it affects retinal and ocular physiology, the techniques through which we can diagnose and image it, and the various treatments developed to try to combat it. The medical imaging techniques to be discussed include but are not limited to adaptive optics (AO), OCT including SD-OCT and OCTA, fundus autofluorescence (FAF) and its associated fluorescence lifetime imaging ophthalmoscopy (FLIO), colour Doppler flow imaging (CDFI), microperimetry, and MRI. The treatments to be discussed include stem cell therapy, gene therapy, cell transplantation, pharmacological therapy, and artificial retinal implants. Throughout this review, it will be made evident of not just the severity and diversity through which RP can present, but also the advanced made in medical imaging and innovative treatments designed to combat this pathology.
Non-learning Stereo-aided Depth Completion under Mis-projection via Selective Stereo Matching
Oct 04, 2022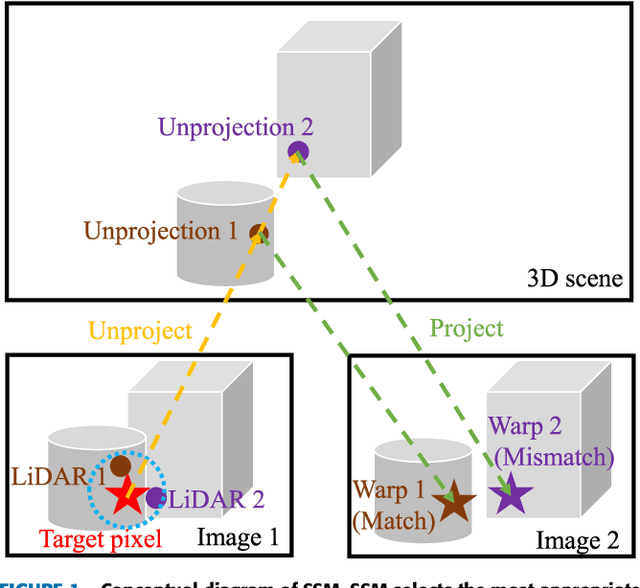
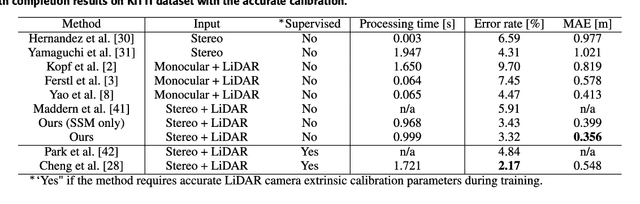
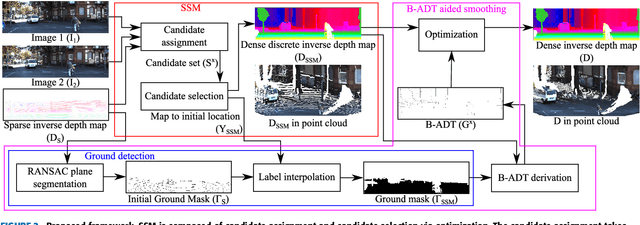

We propose a non-learning depth completion method for a sparse depth map captured using a light detection and ranging (LiDAR) sensor guided by a pair of stereo images. Generally, conventional stereo-aided depth completion methods have two limiations. (i) They assume the given sparse depth map is accurately aligned to the input image, whereas the alignment is difficult to achieve in practice. (ii) They have limited accuracy in the long range because the depth is estimated by pixel disparity. To solve the abovementioned limitations, we propose selective stereo matching (SSM) that searches the most appropriate depth value for each image pixel from its neighborly projected LiDAR points based on an energy minimization framework. This depth selection approach can handle any type of mis-projection. Moreover, SSM has an advantage in terms of long-range depth accuracy because it directly uses the LiDAR measurement rather than the depth acquired from the stereo. SSM is a discrete process; thus, we apply variational smoothing with binary anisotropic diffusion tensor (B-ADT) to generate a continuous depth map while preserving depth discontinuity across object boundaries. Experimentally, compared with the previous state-of-the-art stereo-aided depth completion, the proposed method reduced the mean absolute error (MAE) of the depth estimation to 0.65 times and demonstrated approximately twice more accurate estimation in the long range. Moreover, under various LiDAR-camera calibration errors, the proposed method reduced the depth estimation MAE to 0.34-0.93 times from previous depth completion methods.
* 15 pages, 13 figures
Self-Score: Self-Supervised Learning on Score-Based Models for MRI Reconstruction
Sep 02, 2022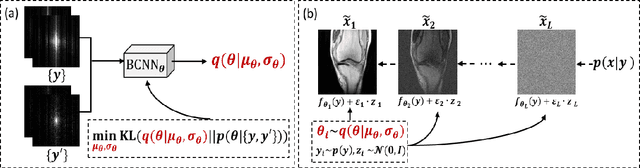
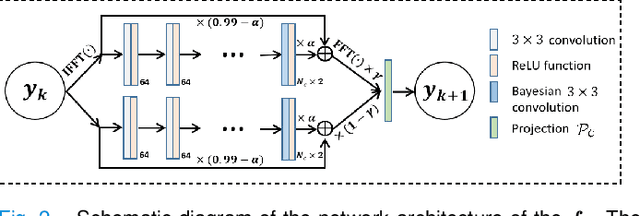

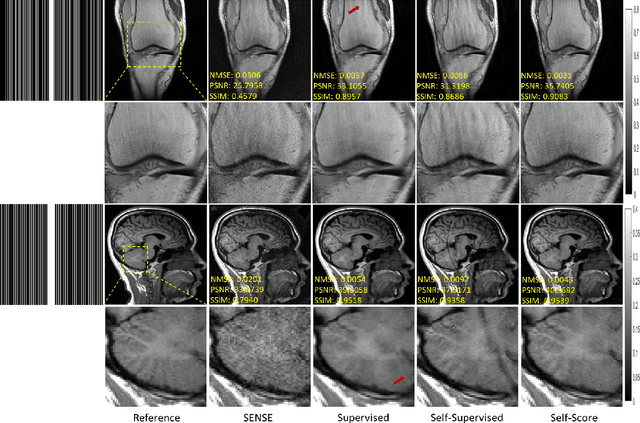
Recently, score-based diffusion models have shown satisfactory performance in MRI reconstruction. Most of these methods require a large amount of fully sampled MRI data as a training set, which, sometimes, is difficult to acquire in practice. This paper proposes a fully-sampled-data-free score-based diffusion model for MRI reconstruction, which learns the fully sampled MR image prior in a self-supervised manner on undersampled data. Specifically, we first infer the fully sampled MR image distribution from the undersampled data by Bayesian deep learning, then perturb the data distribution and approximate their probability density gradient by training a score function. Leveraging the learned score function as a prior, we can reconstruct the MR image by performing conditioned Langevin Markov chain Monte Carlo (MCMC) sampling. Experiments on the public dataset show that the proposed method outperforms existing self-supervised MRI reconstruction methods and achieves comparable performances with the conventional (fully sampled data trained) score-based diffusion methods.
Image-to-image Translation as a Unique Source of Knowledge
Dec 03, 2021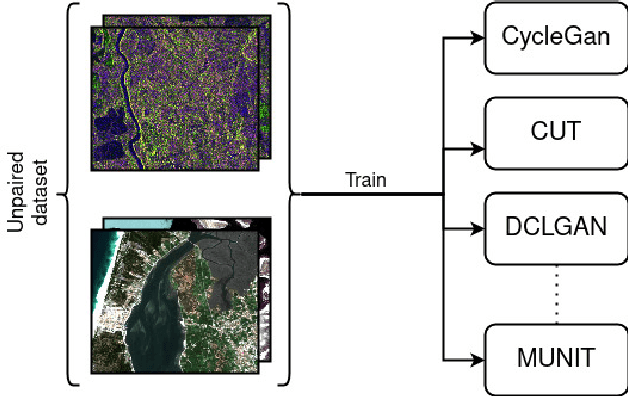
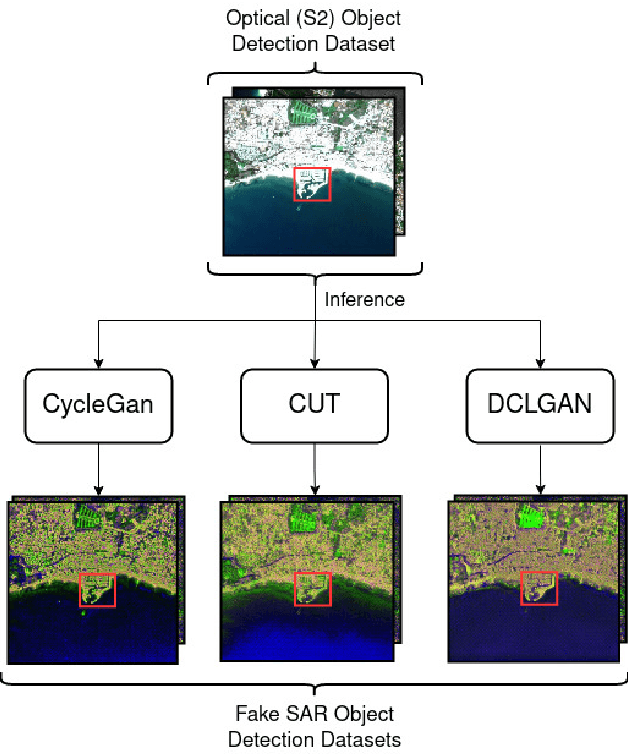
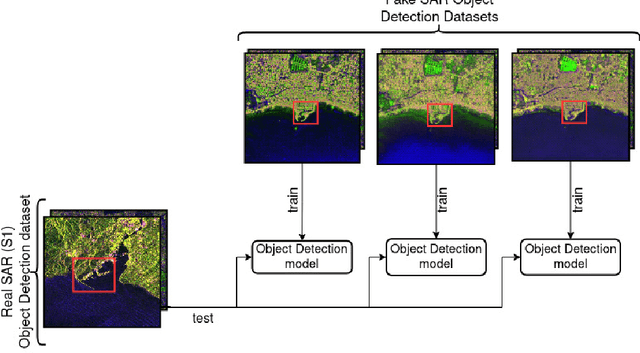
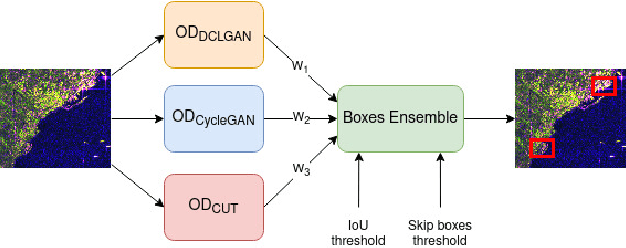
Image-to-image (I2I) translation is an established way of translating data from one domain to another but the usability of the translated images in the target domain when working with such dissimilar domains as the SAR/optical satellite imagery ones and how much of the origin domain is translated to the target domain is still not clear enough. This article address this by performing translations of labelled datasets from the optical domain to the SAR domain with different I2I algorithms from the state-of-the-art, learning from transferred features in the destination domain and evaluating later how much from the original dataset was transferred. Added to this, stacking is proposed as a way of combining the knowledge learned from the different I2I translations and evaluated against single models.
Multi-view Contrastive Learning with Additive Margin for Adaptive Nasopharyngeal Carcinoma Radiotherapy Prediction
Oct 27, 2022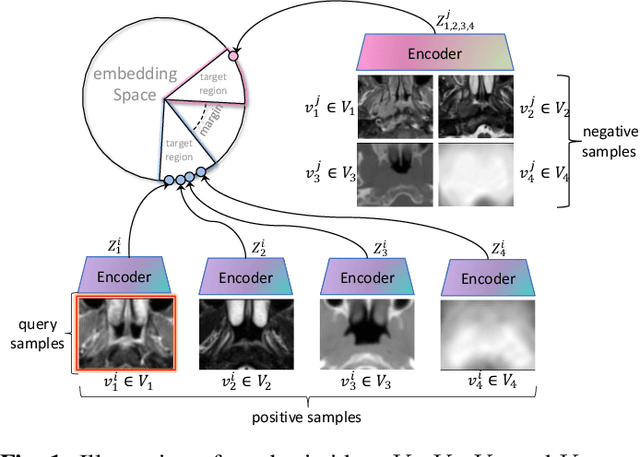

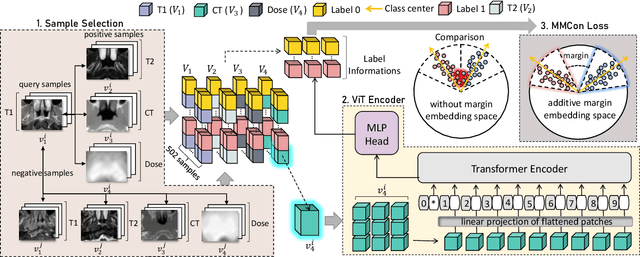
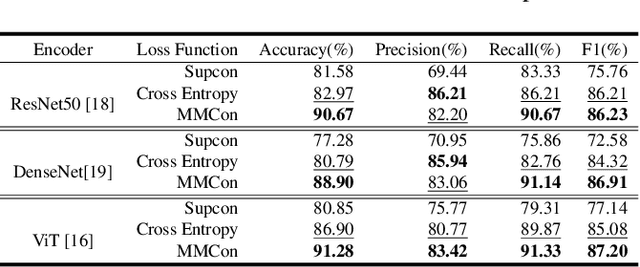
The prediction of adaptive radiation therapy (ART) prior to radiation therapy (RT) for nasopharyngeal carcinoma (NPC) patients is important to reduce toxicity and prolong the survival of patients. Currently, due to the complex tumor micro-environment, a single type of high-resolution image can provide only limited information. Meanwhile, the traditional softmax-based loss is insufficient for quantifying the discriminative power of a model. To overcome these challenges, we propose a supervised multi-view contrastive learning method with an additive margin (MMCon). For each patient, four medical images are considered to form multi-view positive pairs, which can provide additional information and enhance the representation of medical images. In addition, the embedding space is learned by means of contrastive learning. NPC samples from the same patient or with similar labels will remain close in the embedding space, while NPC samples with different labels will be far apart. To improve the discriminative ability of the loss function, we incorporate a margin into the contrastive learning. Experimental result show this new learning objective can be used to find an embedding space that exhibits superior discrimination ability for NPC images.
Rethinking the Reverse-engineering of Trojan Triggers
Oct 27, 2022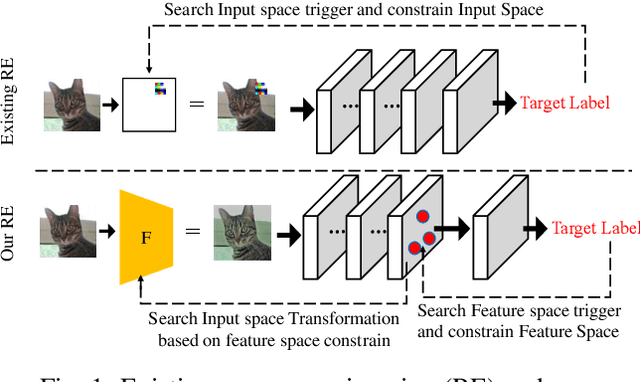
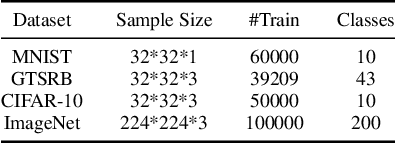
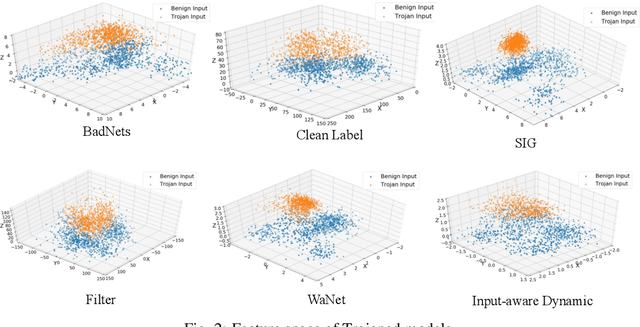
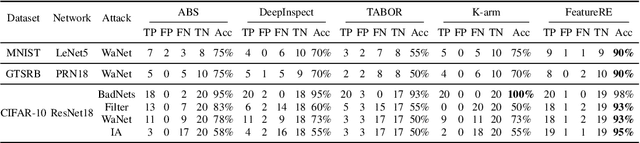
Deep Neural Networks are vulnerable to Trojan (or backdoor) attacks. Reverse-engineering methods can reconstruct the trigger and thus identify affected models. Existing reverse-engineering methods only consider input space constraints, e.g., trigger size in the input space. Expressly, they assume the triggers are static patterns in the input space and fail to detect models with feature space triggers such as image style transformations. We observe that both input-space and feature-space Trojans are associated with feature space hyperplanes. Based on this observation, we design a novel reverse-engineering method that exploits the feature space constraint to reverse-engineer Trojan triggers. Results on four datasets and seven different attacks demonstrate that our solution effectively defends both input-space and feature-space Trojans. It outperforms state-of-the-art reverse-engineering methods and other types of defenses in both Trojaned model detection and mitigation tasks. On average, the detection accuracy of our method is 93\%. For Trojan mitigation, our method can reduce the ASR (attack success rate) to only 0.26\% with the BA (benign accuracy) remaining nearly unchanged. Our code can be found at https://github.com/RU-System-Software-and-Security/FeatureRE.
Learning Neural Radiance Fields from Multi-View Geometry
Oct 24, 2022
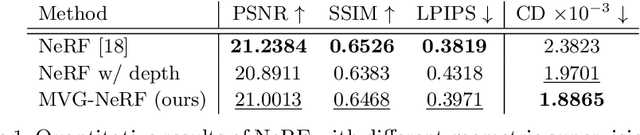
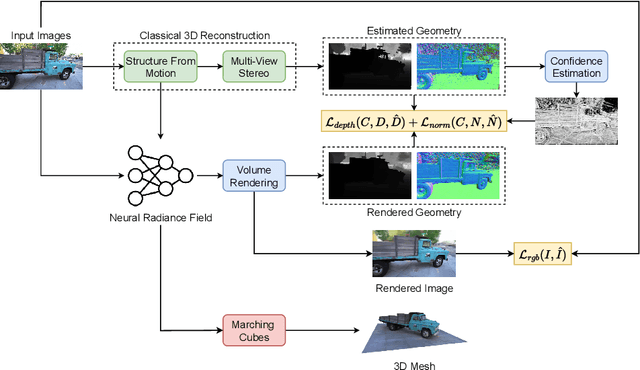
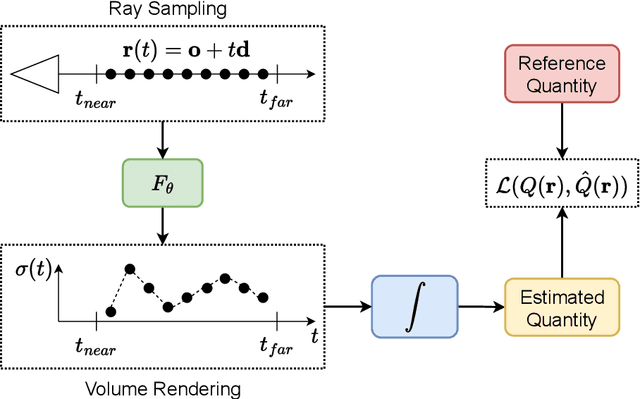
We present a framework, called MVG-NeRF, that combines classical Multi-View Geometry algorithms and Neural Radiance Fields (NeRF) for image-based 3D reconstruction. NeRF has revolutionized the field of implicit 3D representations, mainly due to a differentiable volumetric rendering formulation that enables high-quality and geometry-aware novel view synthesis. However, the underlying geometry of the scene is not explicitly constrained during training, thus leading to noisy and incorrect results when extracting a mesh with marching cubes. To this end, we propose to leverage pixelwise depths and normals from a classical 3D reconstruction pipeline as geometric priors to guide NeRF optimization. Such priors are used as pseudo-ground truth during training in order to improve the quality of the estimated underlying surface. Moreover, each pixel is weighted by a confidence value based on the forward-backward reprojection error for additional robustness. Experimental results on real-world data demonstrate the effectiveness of this approach in obtaining clean 3D meshes from images, while maintaining competitive performances in novel view synthesis.