 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Deep Neural Framework for Image Caption Generation Using GRU-Based Attention Mechanism
Mar 03, 2022
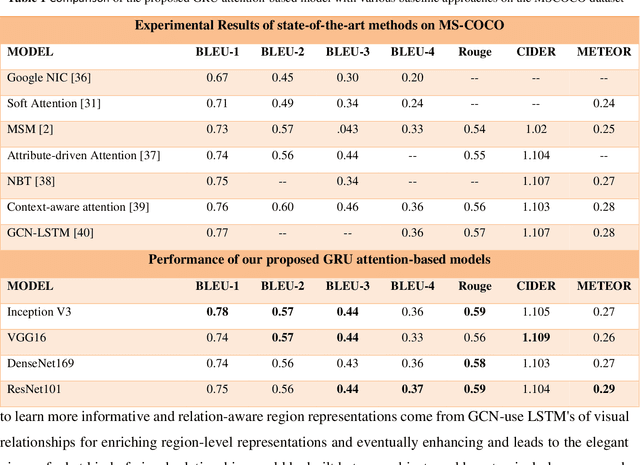
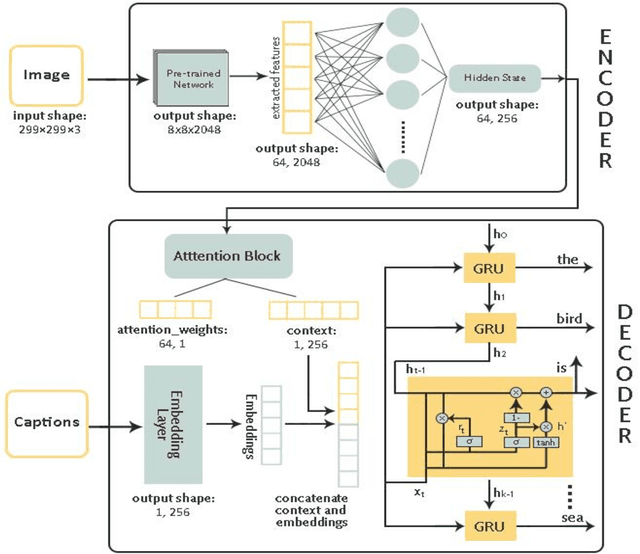
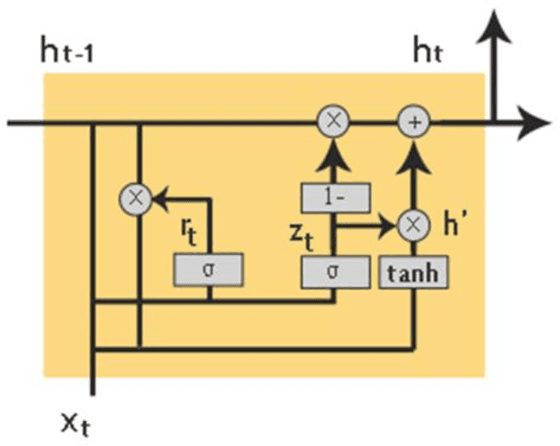
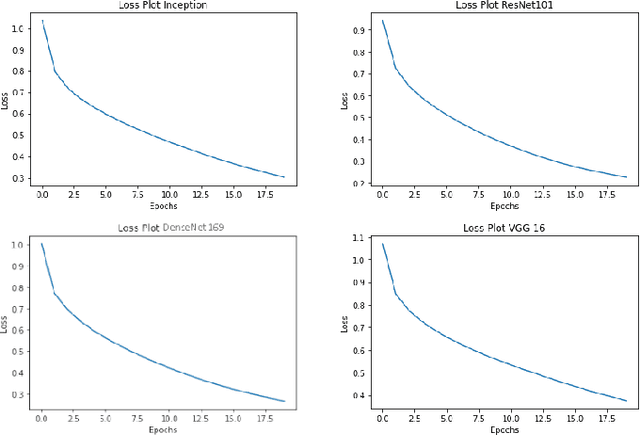
Image captioning is a fast-growing research field of computer vision and natural language processing that involves creating text explanations for images. This study aims to develop a system that uses a pre-trained convolutional neural network (CNN) to extract features from an image, integrates the features with an attention mechanism, and creates captions using a recurrent neural network (RNN). To encode an image into a feature vector as graphical attributes, we employed multiple pre-trained convolutional neural networks. Following that, a language model known as GRU is chosen as the decoder to construct the descriptive sentence. In order to increase performance, we merge the Bahdanau attention model with GRU to allow learning to be focused on a specific portion of the image. On the MSCOCO dataset, the experimental results achieve competitive performance against state-of-the-art approaches.
* 16 PAGES, 8 figures, 1 TABLE
One Model, Multiple Modalities: A Sparsely Activated Approach for Text, Sound, Image, Video and Code
May 12, 2022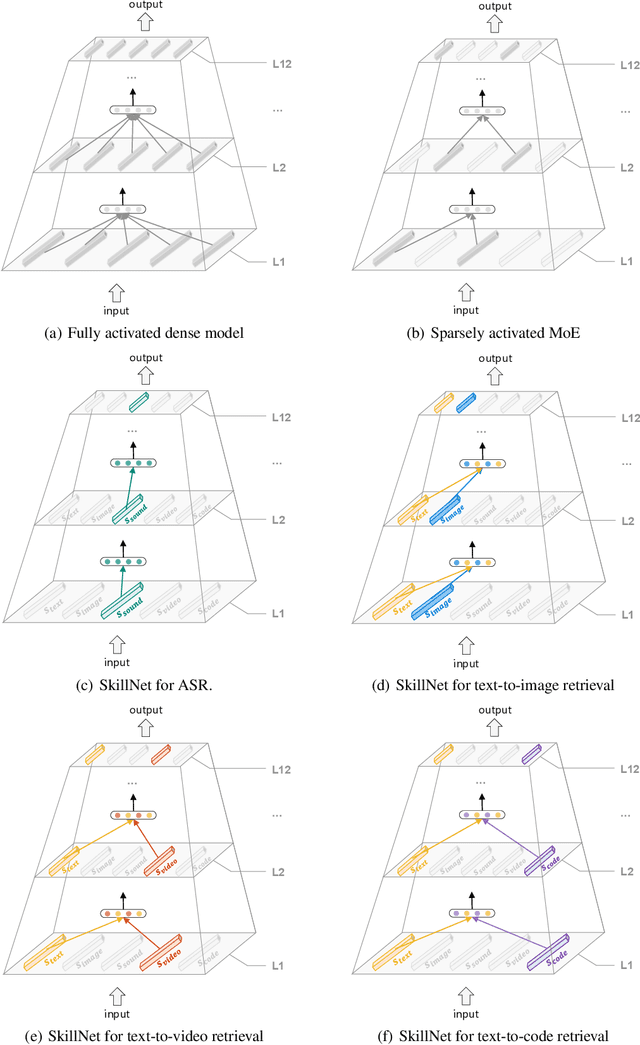

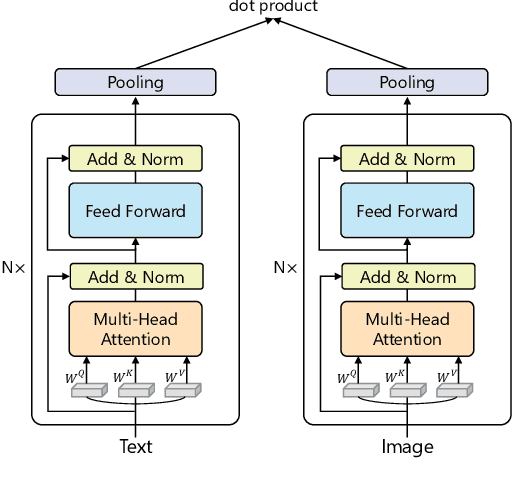
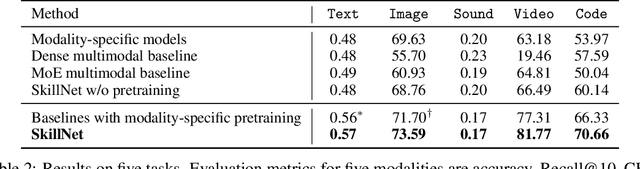
People perceive the world with multiple senses (e.g., through hearing sounds, reading words and seeing objects). However, most existing AI systems only process an individual modality. This paper presents an approach that excels at handling multiple modalities of information with a single model. In our "{SkillNet}" model, different parts of the parameters are specialized for processing different modalities. Unlike traditional dense models that always activate all the model parameters, our model sparsely activates parts of the parameters whose skills are relevant to the task. Such model design enables SkillNet to learn skills in a more interpretable way. We develop our model for five modalities including text, image, sound, video and code. Results show that, SkillNet performs comparably to five modality-specific fine-tuned models. Moreover, our model supports self-supervised pretraining with the same sparsely activated way, resulting in better initialized parameters for different modalities. We find that pretraining significantly improves the performance of SkillNet on five modalities, on par with or even better than baselines with modality-specific pretraining. On the task of Chinese text-to-image retrieval, our final system achieves higher accuracy than existing leading systems including Wukong{ViT-B} and Wenlan 2.0 while using less number of activated parameters.
Space-time design for deep joint source channel coding of images Over MIMO channels
Oct 30, 2022
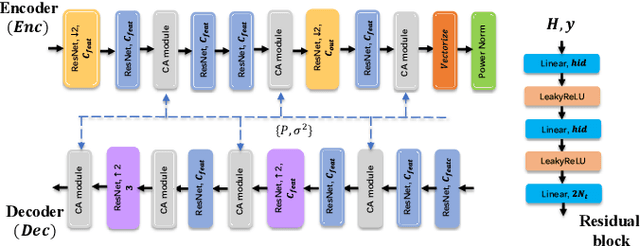
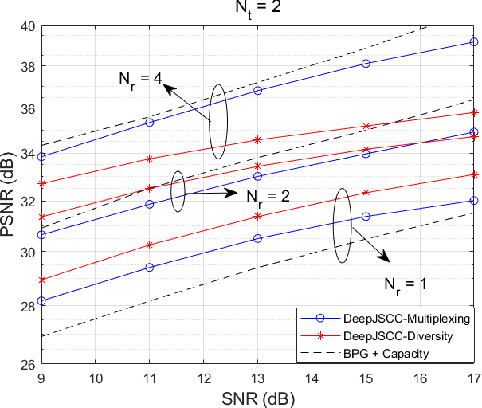
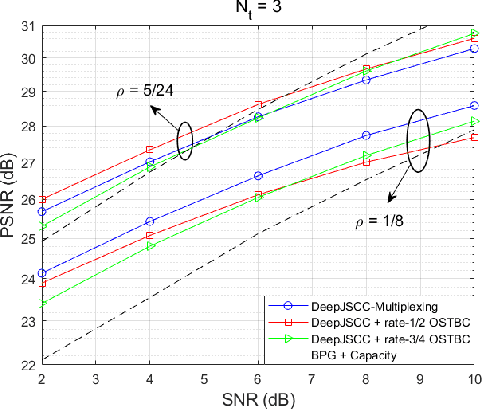
We propose novel deep joint source-channel coding (DeepJSCC) algorithms for wireless image transmission over multi-input multi-output (MIMO) Rayleigh fading channels, when channel state information (CSI) is available only at the receiver. We consider two different transmission schemes; one exploiting spatial diversity and the other one exploiting spatial multiplexing of the MIMO channel. In the diversity scheme, we utilize an orthogonal space-time block code (OSTBC) to achieve full diversity which increases the robustness of transmission against channel variations. The multiplexing scheme, on the other hand, allows the user to directly map the codeword to the antennas, where the additional degree-of-freedom is used to send more information about the source signal. Simulation results show that the diversity scheme outperforms the multiplexing scheme at lower signal-to-noise ratio (SNR) values and smaller number of receive antennas at the AP. When the number of transmit antennas is greater than two, however, the full-diversity scheme becomes less beneficial. We also show that both the diversity and multiplexing scheme can achieve comparable performance with the state-of-the-art BPG algorithm delivered at the MIMO capacity in the considered scenarios.
A Novel Approach for Neuromorphic Vision Data Compression based on Deep Belief Network
Oct 27, 2022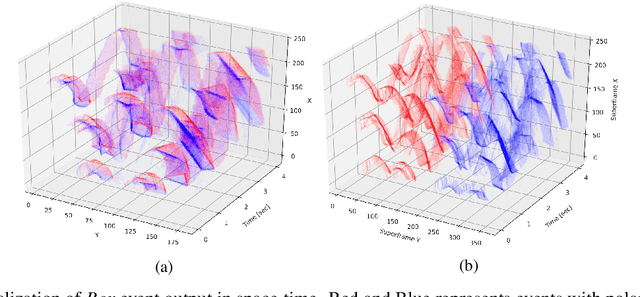
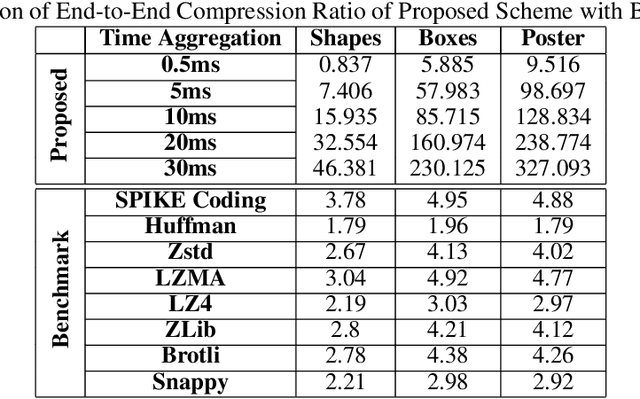
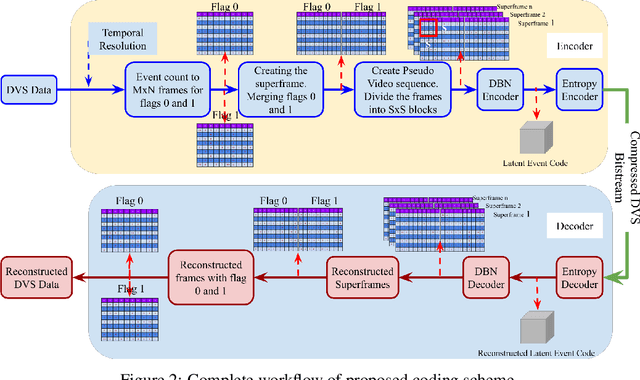
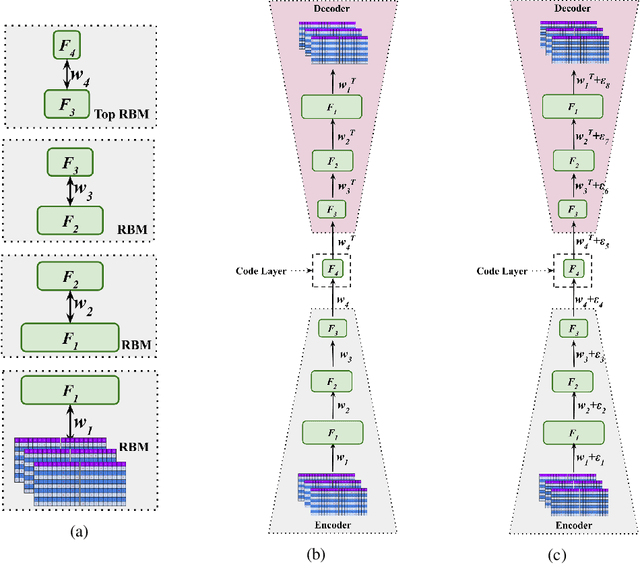
A neuromorphic camera is an image sensor that emulates the human eyes capturing only changes in local brightness levels. They are widely known as event cameras, silicon retinas or dynamic vision sensors (DVS). DVS records asynchronous per-pixel brightness changes, resulting in a stream of events that encode the brightness change's time, location, and polarity. DVS consumes little power and can capture a wider dynamic range with no motion blur and higher temporal resolution than conventional frame-based cameras. Although this method of event capture results in a lower bit rate than traditional video capture, it is further compressible. This paper proposes a novel deep learning-based compression scheme for event data. Using a deep belief network (DBN), the high dimensional event data is reduced into a latent representation and later encoded using an entropy-based coding technique. The proposed scheme is among the first to incorporate deep learning for event compression. It achieves a high compression ratio while maintaining good reconstruction quality outperforming state-of-the-art event data coders and other lossless benchmark techniques.
MSSNet: Multi-Scale-Stage Network for Single Image Deblurring
Feb 19, 2022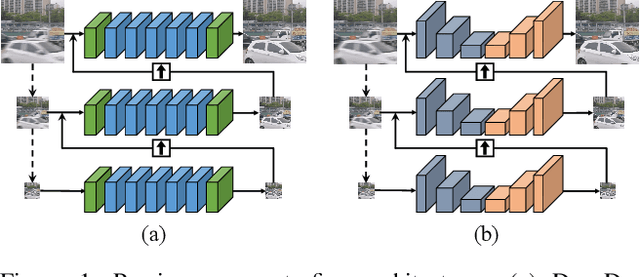
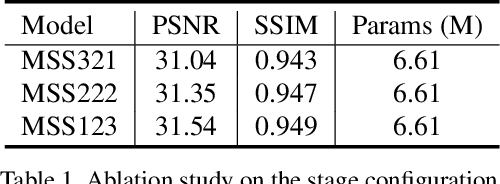
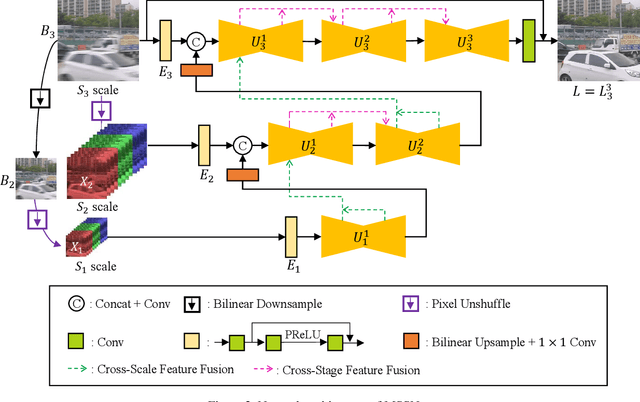
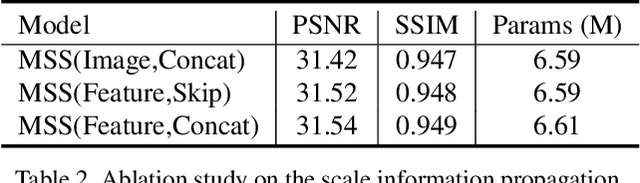
Most of traditional single image deblurring methods before deep learning adopt a coarse-to-fine scheme that estimates a sharp image at a coarse scale and progressively refines it at finer scales. While this scheme has also been adopted to several deep learning-based approaches, recently a number of single-scale approaches have been introduced showing superior performance to previous coarse-to-fine approaches both in quality and computation time, making the traditional coarse-to-fine scheme seemingly obsolete. In this paper, we revisit the coarse-to-fine scheme, and analyze defects of previous coarse-to-fine approaches that degrade their performance. Based on the analysis, we propose Multi-Scale-Stage Network (MSSNet), a novel deep learning-based approach to single image deblurring that adopts our remedies to the defects. Specifically, MSSNet adopts three novel technical components: stage configuration reflecting blur scales, an inter-scale information propagation scheme, and a pixel-shuffle-based multi-scale scheme. Our experiments show that MSSNet achieves the state-of-the-art performance in terms of quality, network size, and computation time.
MICDIR: Multi-scale Inverse-consistent Deformable Image Registration using UNetMSS with Self-Constructing Graph Latent
Mar 08, 2022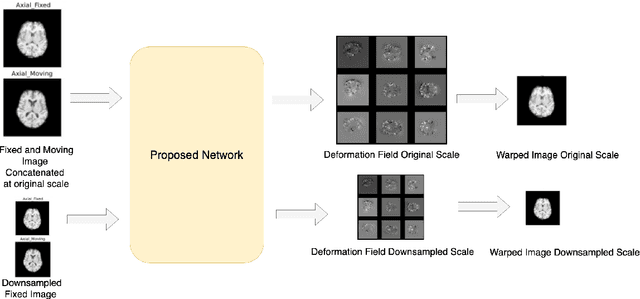
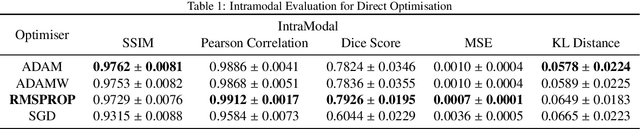
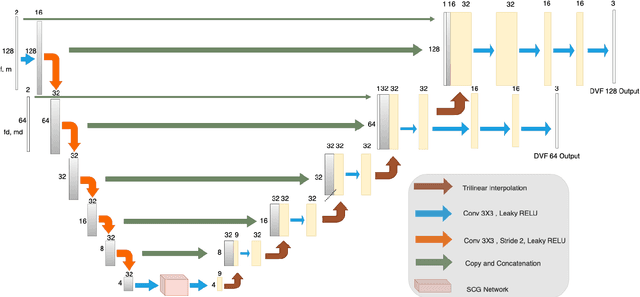
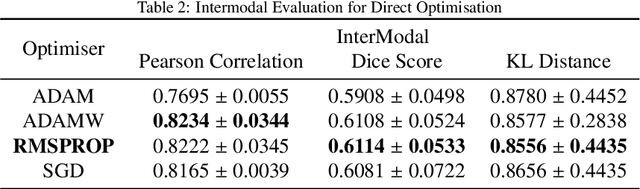
Image registration is the process of bringing different images into a common coordinate system - a technique widely used in various applications of computer vision, such as remote sensing, image retrieval, and most commonly in medical imaging. Deep Learning based techniques have been applied successfully to tackle various complex medical image processing problems, including medical image registration. Over the years, several image registration techniques have been proposed using deep learning. Deformable image registration techniques such as Voxelmorph have been successful in capturing finer changes and providing smoother deformations. However, Voxelmorph, as well as ICNet and FIRE, do not explicitly encode global dependencies (i.e. the overall anatomical view of the supplied image) and therefore can not track large deformations. In order to tackle the aforementioned problems, this paper extends the Voxelmorph approach in three different ways. To improve the performance in case of small as well as large deformations, supervision of the model at different resolutions have been integrated using a multi-scale UNet. To support the network to learn and encode the minute structural co-relations of the given image-pairs, a self-constructing graph network (SCGNet) has been used as the latent of the multi-scale UNet - which can improve the learning process of the model and help the model to generalise better. And finally, to make the deformations inverse-consistent, cycle consistency loss has been employed. On the task of registration of brain MRIs, the proposed method achieved significant improvements over ANTs and VoxelMorph, obtaining a Dice score of 0.8013$\pm$0.0243 for intramodal and 0.6211$\pm$0.0309 for intermodal, while VoxelMorph achieved 0.7747$\pm$0.0260 and 0.6071$\pm$0.0510, respectively.
This is what a pandemic looks like: Visual framing of COVID-19 on search engines
Sep 22, 2022
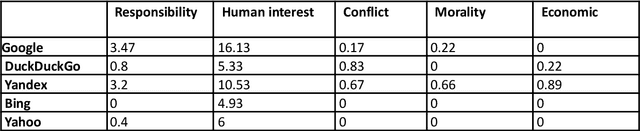
In today's high-choice media environment, search engines play an integral role in informing individuals and societies about the latest events. The importance of search algorithms is even higher at the time of crisis, when users search for information to understand the causes and the consequences of the current situation and decide on their course of action. In our paper, we conduct a comparative audit of how different search engines prioritize visual information related to COVID-19 and what consequences it has for the representation of the pandemic. Using a virtual agent-based audit approach, we examine image search results for the term "coronavirus" in English, Russian and Chinese on five major search engines: Google, Yandex, Bing, Yahoo, and DuckDuckGo. Specifically, we focus on how image search results relate to generic news frames (e.g., the attribution of responsibility, human interest, and economics) used in relation to COVID-19 and how their visual composition varies between the search engines.
CurveFormer: 3D Lane Detection by Curve Propagation with Curve Queries and Attention
Sep 16, 2022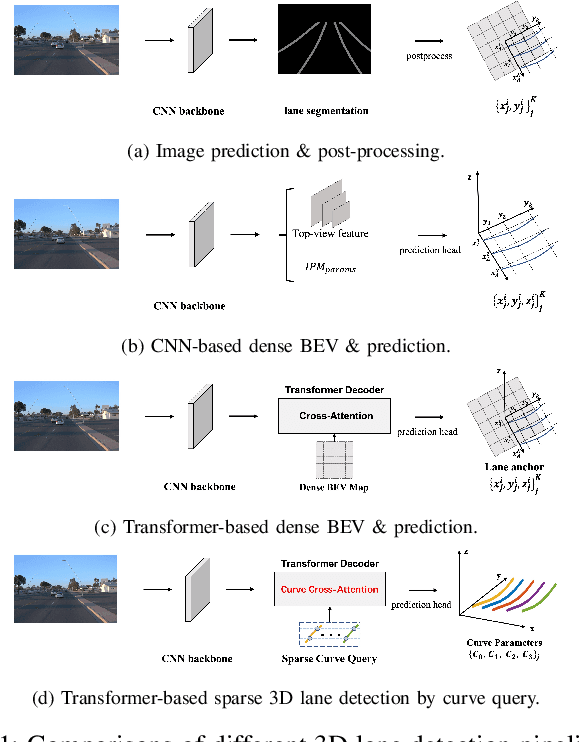
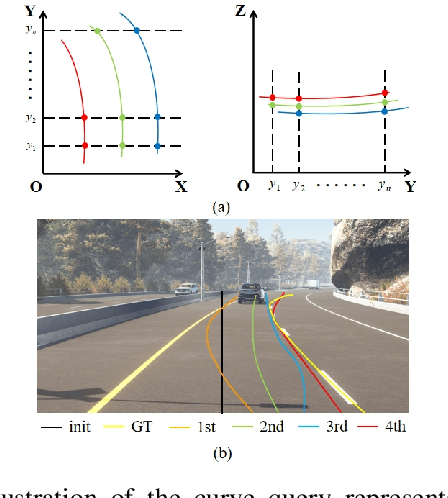
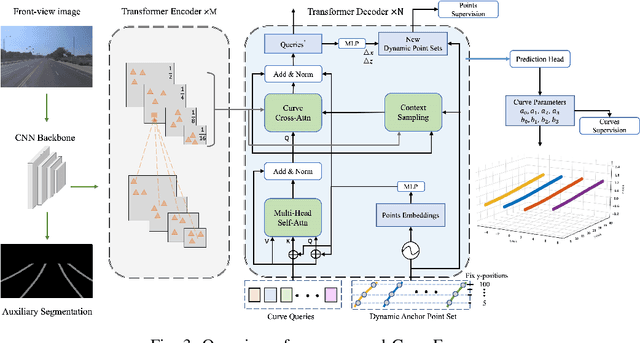
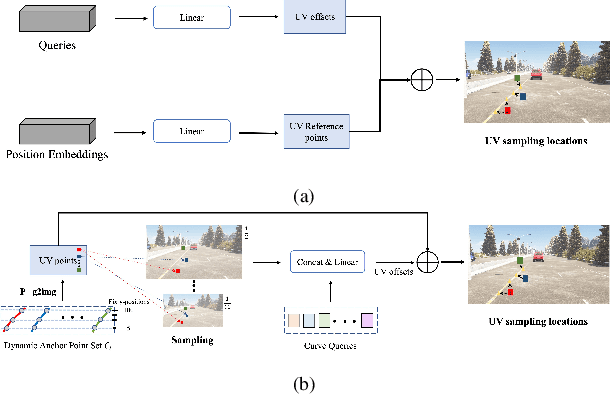
3D lane detection is an integral part of autonomous driving systems. Previous CNN and Transformer-based methods usually first generate a bird's-eye-view (BEV) feature map from the front view image, and then use a sub-network with BEV feature map as input to predict 3D lanes. Such approaches require an explicit view transformation between BEV and front view, which itself is still a challenging problem. In this paper, we propose CurveFormer, a single-stage Transformer-based method that directly calculates 3D lane parameters and can circumvent the difficult view transformation step. Specifically, we formulate 3D lane detection as a curve propagation problem by using curve queries. A 3D lane query is represented by a dynamic and ordered anchor point set. In this way, queries with curve representation in Transformer decoder iteratively refine the 3D lane detection results. Moreover, a curve cross-attention module is introduced to compute the similarities between curve queries and image features. Additionally, a context sampling module that can capture more relative image features of a curve query is provided to further boost the 3D lane detection performance. We evaluate our method for 3D lane detection on both synthetic and real-world datasets, and the experimental results show that our method achieves promising performance compared with the state-of-the-art approaches. The effectiveness of each component is validated via ablation studies as well.
3DConvCaps: 3DUnet with Convolutional Capsule Encoder for Medical Image Segmentation
May 19, 2022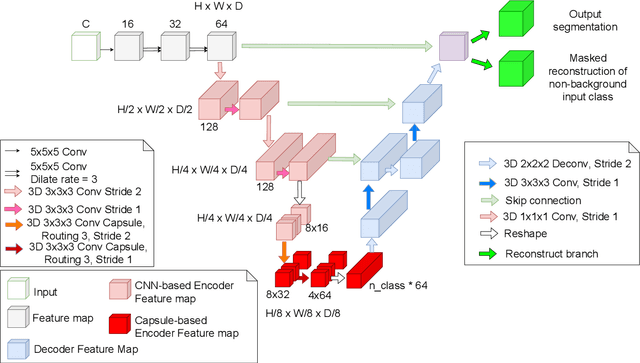
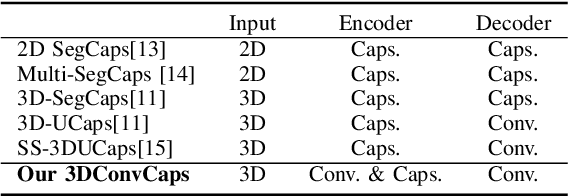
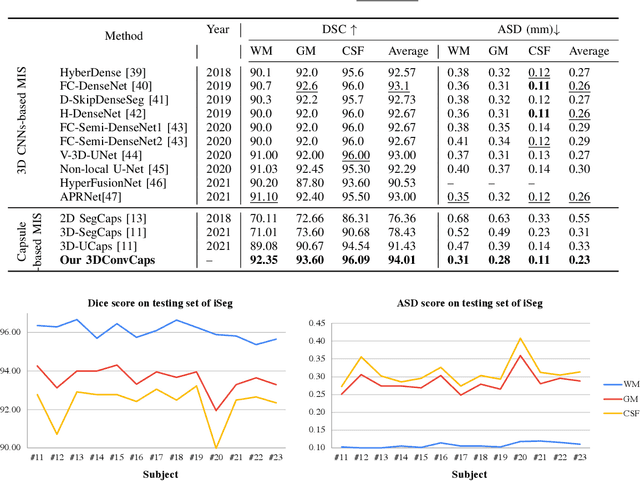
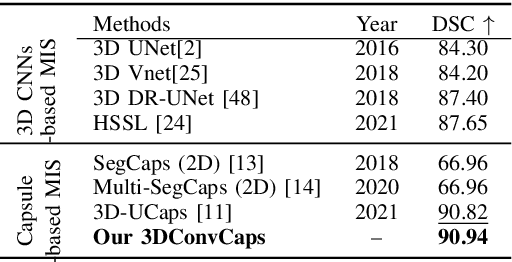
Convolutional Neural Networks (CNNs) have achieved promising results in medical image segmentation. However, CNNs require lots of training data and are incapable of handling pose and deformation of objects. Furthermore, their pooling layers tend to discard important information such as positions as well as CNNs are sensitive to rotation and affine transformation. Capsule network is a recent new architecture that has achieved better robustness in part-whole representation learning by replacing pooling layers with dynamic routing and convolutional strides, which has shown potential results on popular tasks such as digit classification and object segmentation. In this paper, we propose a 3D encoder-decoder network with Convolutional Capsule Encoder (called 3DConvCaps) to learn lower-level features (short-range attention) with convolutional layers while modeling the higher-level features (long-range dependence) with capsule layers. Our experiments on multiple datasets including iSeg-2017, Hippocampus, and Cardiac demonstrate that our 3D 3DConvCaps network considerably outperforms previous capsule networks and 3D-UNets. We further conduct ablation studies of network efficiency and segmentation performance under various configurations of convolution layers and capsule layers at both contracting and expanding paths.
A Visual Tour Of Current Challenges In Multimodal Language Models
Oct 22, 2022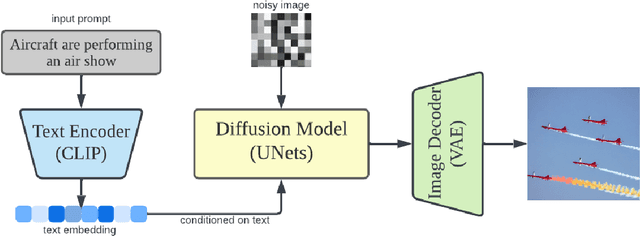



Transformer models trained on massive text corpora have become the de facto models for a wide range of natural language processing tasks. However, learning effective word representations for function words remains challenging. Multimodal learning, which visually grounds transformer models in imagery, can overcome the challenges to some extent; however, there is still much work to be done. In this study, we explore the extent to which visual grounding facilitates the acquisition of function words using stable diffusion models that employ multimodal models for text-to-image generation. Out of seven categories of function words, along with numerous subcategories, we find that stable diffusion models effectively model only a small fraction of function words -- a few pronoun subcategories and relatives. We hope that our findings will stimulate the development of new datasets and approaches that enable multimodal models to learn better representations of function words.