 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning-based Inverse Rendering of Complex Indoor Scenes with Differentiable Monte Carlo Raytracing
Nov 06, 2022
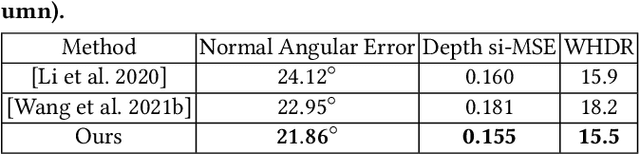

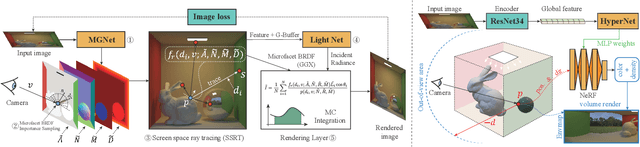

Indoor scenes typically exhibit complex, spatially-varying appearance from global illumination, making inverse rendering a challenging ill-posed problem. This work presents an end-to-end, learning-based inverse rendering framework incorporating differentiable Monte Carlo raytracing with importance sampling. The framework takes a single image as input to jointly recover the underlying geometry, spatially-varying lighting, and photorealistic materials. Specifically, we introduce a physically-based differentiable rendering layer with screen-space ray tracing, resulting in more realistic specular reflections that match the input photo. In addition, we create a large-scale, photorealistic indoor scene dataset with significantly richer details like complex furniture and dedicated decorations. Further, we design a novel out-of-view lighting network with uncertainty-aware refinement leveraging hypernetwork-based neural radiance fields to predict lighting outside the view of the input photo. Through extensive evaluations on common benchmark datasets, we demonstrate superior inverse rendering quality of our method compared to state-of-the-art baselines, enabling various applications such as complex object insertion and material editing with high fidelity. Code and data will be made available at \url{https://jingsenzhu.github.io/invrend}.
Semi-supervised domain adaptation with CycleGAN guided by a downstream task loss
Aug 18, 2022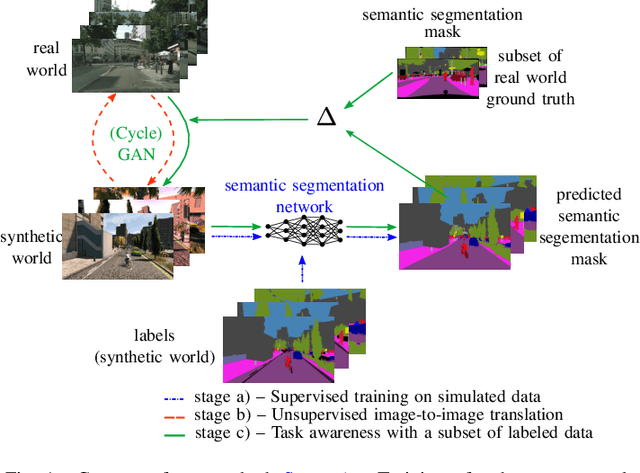
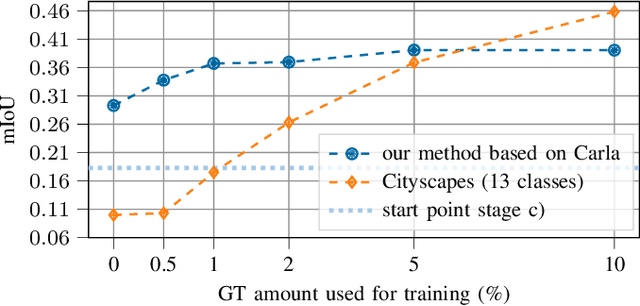


Domain adaptation is of huge interest as labeling is an expensive and error-prone task, especially when labels are needed on pixel-level like in semantic segmentation. Therefore, one would like to be able to train neural networks on synthetic domains, where data is abundant and labels are precise. However, these models often perform poorly on out-of-domain images. To mitigate the shift in the input, image-to-image approaches can be used. Nevertheless, standard image-to-image approaches that bridge the domain of deployment with the synthetic training domain do not focus on the downstream task but only on the visual inspection level. We therefore propose a "task aware" version of a GAN in an image-to-image domain adaptation approach. With the help of a small amount of labeled ground truth data, we guide the image-to-image translation to a more suitable input image for a semantic segmentation network trained on synthetic data (synthetic-domain expert). The main contributions of this work are 1) a modular semi-supervised domain adaptation method for semantic segmentation by training a downstream task aware CycleGAN while refraining from adapting the synthetic semantic segmentation expert 2) the demonstration that the method is applicable to complex domain adaptation tasks and 3) a less biased domain gap analysis by using from scratch networks. We evaluate our method on a classification task as well as on semantic segmentation. Our experiments demonstrate that our method outperforms CycleGAN - a standard image-to-image approach - by 7 percent points in accuracy in a classification task using only 70 (10%) ground truth images. For semantic segmentation we can show an improvement of about 4 to 7 percent points in mean Intersection over union on the Cityscapes evaluation dataset with only 14 ground truth images during training.
Clustering Without Knowing How To: Application and Evaluation
Sep 21, 2022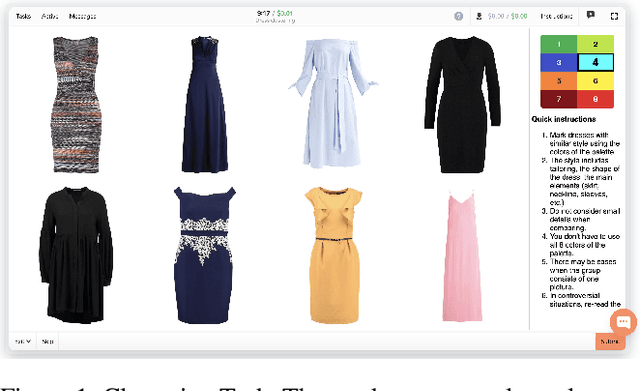
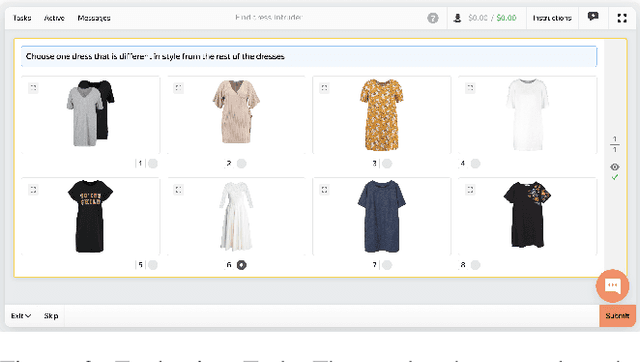
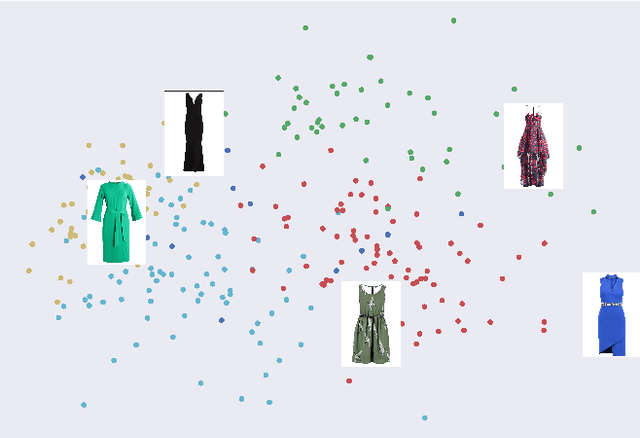
Crowdsourcing allows running simple human intelligence tasks on a large crowd of workers, enabling solving problems for which it is difficult to formulate an algorithm or train a machine learning model in reasonable time. One of such problems is data clustering by an under-specified criterion that is simple for humans, but difficult for machines. In this demonstration paper, we build a crowdsourced system for image clustering and release its code under a free license at https://github.com/Toloka/crowdclustering. Our experiments on two different image datasets, dresses from Zalando's FEIDEGGER and shoes from the Toloka Shoes Dataset, confirm that one can yield meaningful clusters with no machine learning algorithms purely with crowdsourcing.
Glo-In-One: Holistic Glomerular Detection, Segmentation, and Lesion Characterization with Large-scale Web Image Mining
May 31, 2022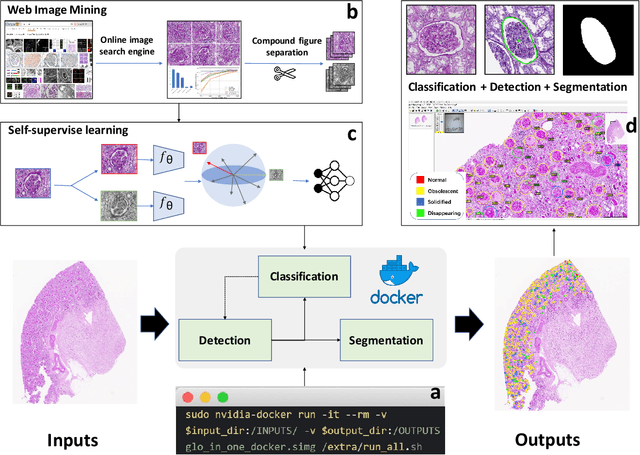
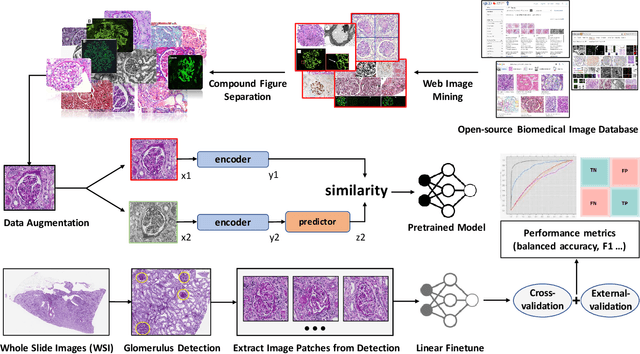
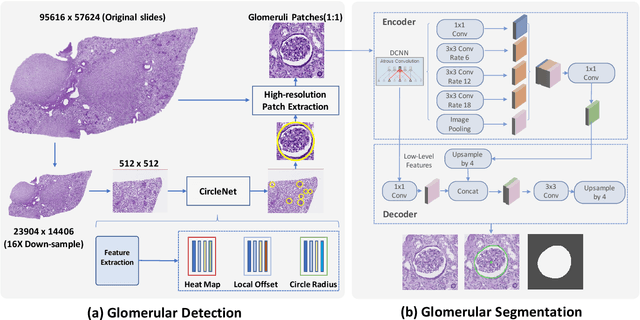
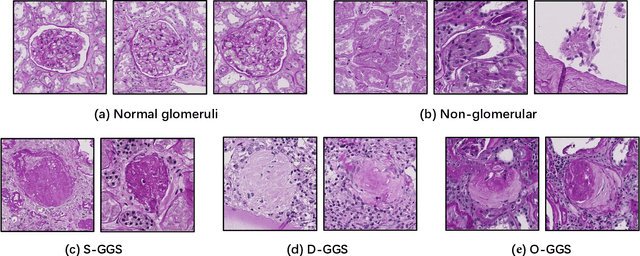
The quantitative detection, segmentation, and characterization of glomeruli from high-resolution whole slide imaging (WSI) play essential roles in the computer-assisted diagnosis and scientific research in digital renal pathology. Historically, such comprehensive quantification requires extensive programming skills in order to be able to handle heterogeneous and customized computational tools. To bridge the gap of performing glomerular quantification for non-technical users, we develop the Glo-In-One toolkit to achieve holistic glomerular detection, segmentation, and characterization via a single line of command. Additionally, we release a large-scale collection of 30,000 unlabeled glomerular images to further facilitate the algorithmic development of self-supervised deep learning. The inputs of the Glo-In-One toolkit are WSIs, while the outputs are (1) WSI-level multi-class circle glomerular detection results (which can be directly manipulated with ImageScope), (2) glomerular image patches with segmentation masks, and (3) different lesion types. To leverage the performance of the Glo-In-One toolkit, we introduce self-supervised deep learning to glomerular quantification via large-scale web image mining. The GGS fine-grained classification model achieved a decent performance compared with baseline supervised methods while only using 10% of the annotated data. The glomerular detection achieved an average precision of 0.627 with circle representations, while the glomerular segmentation achieved a 0.955 patch-wise Dice Similarity Coefficient (DSC).
Large Scale Real-World Multi-Person Tracking
Nov 03, 2022
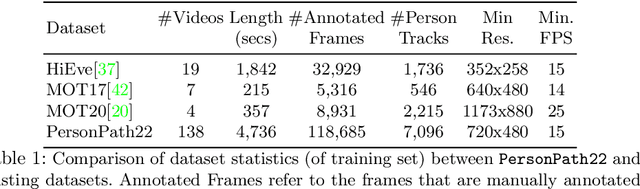
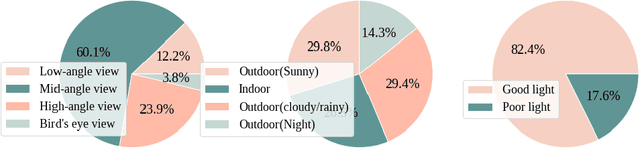
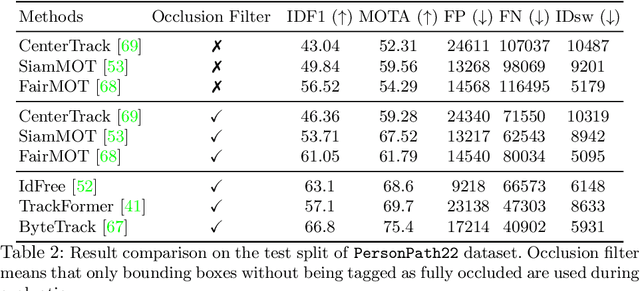
This paper presents a new large scale multi-person tracking dataset -- \texttt{PersonPath22}, which is over an order of magnitude larger than currently available high quality multi-object tracking datasets such as MOT17, HiEve, and MOT20 datasets. The lack of large scale training and test data for this task has limited the community's ability to understand the performance of their tracking systems on a wide range of scenarios and conditions such as variations in person density, actions being performed, weather, and time of day. \texttt{PersonPath22} dataset was specifically sourced to provide a wide variety of these conditions and our annotations include rich meta-data such that the performance of a tracker can be evaluated along these different dimensions. The lack of training data has also limited the ability to perform end-to-end training of tracking systems. As such, the highest performing tracking systems all rely on strong detectors trained on external image datasets. We hope that the release of this dataset will enable new lines of research that take advantage of large scale video based training data.
Selective Residual M-Net for Real Image Denoising
Mar 03, 2022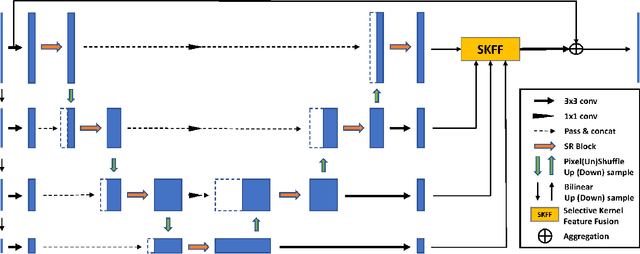
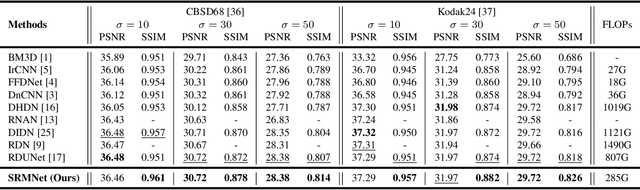
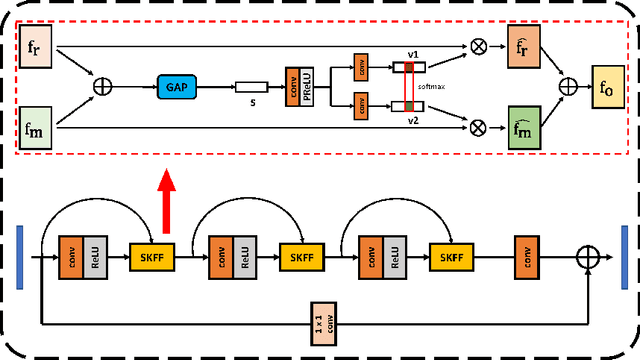
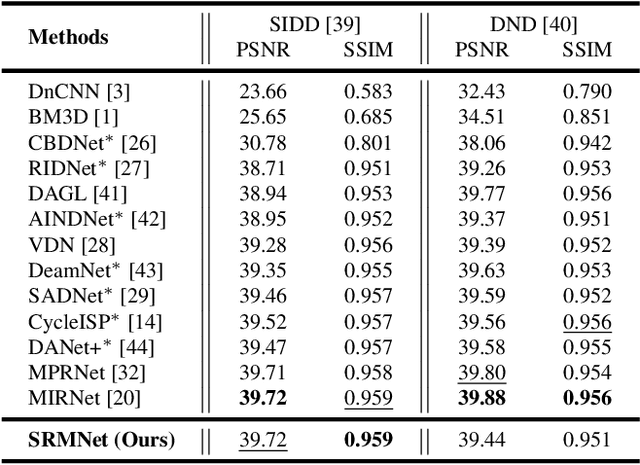
Image restoration is a low-level vision task which is to restore degraded images to noise-free images. With the success of deep neural networks, the convolutional neural networks surpass the traditional restoration methods and become the mainstream in the computer vision area. To advance the performanceof denoising algorithms, we propose a blind real image denoising network (SRMNet) by employing a hierarchical architecture improved from U-Net. Specifically, we use a selective kernel with residual block on the hierarchical structure called M-Net to enrich the multi-scale semantic information. Furthermore, our SRMNet has competitive performance results on two synthetic and two real-world noisy datasets in terms of quantitative metrics and visual quality. The source code and pretrained model are available at https://github.com/TentativeGitHub/SRMNet.
PicT: A Slim Weakly Supervised Vision Transformer for Pavement Distress Classification
Sep 21, 2022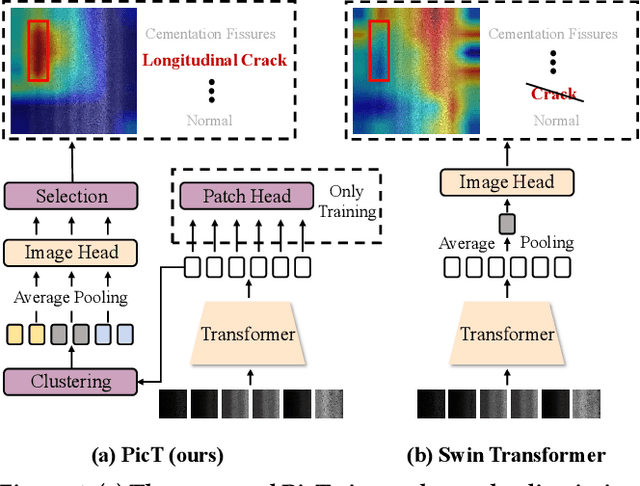
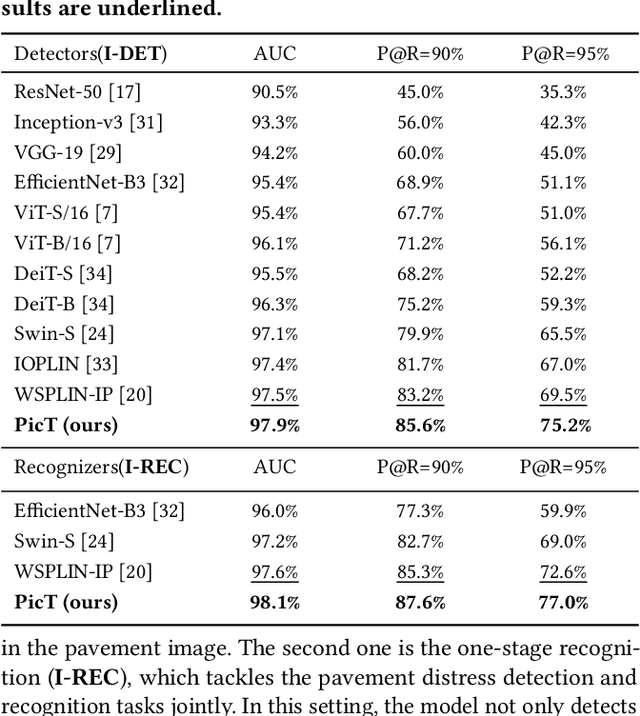
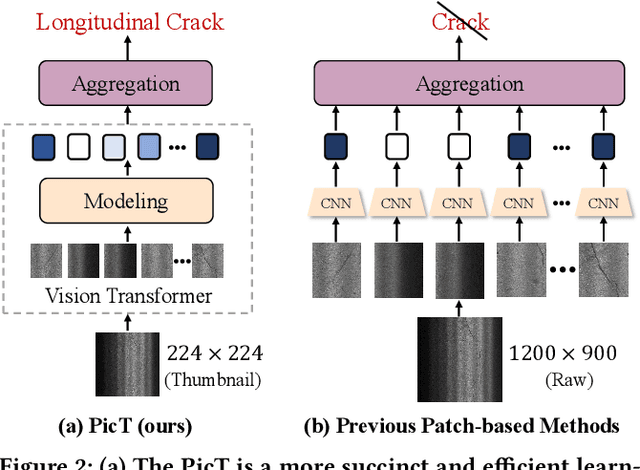
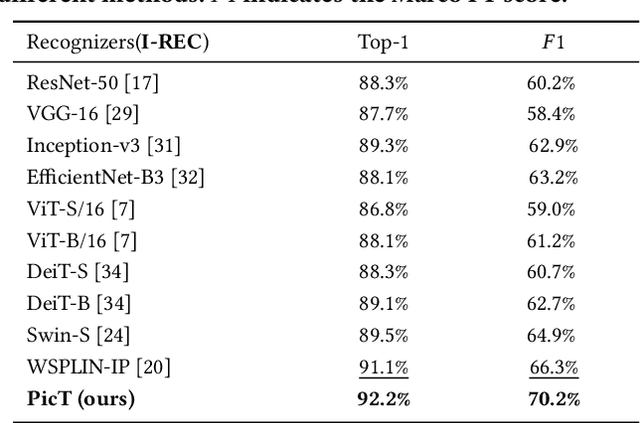
Automatic pavement distress classification facilitates improving the efficiency of pavement maintenance and reducing the cost of labor and resources. A recently influential branch of this task divides the pavement image into patches and addresses these issues from the perspective of multi-instance learning. However, these methods neglect the correlation between patches and suffer from a low efficiency in the model optimization and inference. Meanwhile, Swin Transformer is able to address both of these issues with its unique strengths. Built upon Swin Transformer, we present a vision Transformer named \textbf{P}avement \textbf{I}mage \textbf{C}lassification \textbf{T}ransformer (\textbf{PicT}) for pavement distress classification. In order to better exploit the discriminative information of pavement images at the patch level, the \textit{Patch Labeling Teacher} is proposed to leverage a teacher model to dynamically generate pseudo labels of patches from image labels during each iteration, and guides the model to learn the discriminative features of patches. The broad classification head of Swin Transformer may dilute the discriminative features of distressed patches in the feature aggregation step due to the small distressed area ratio of the pavement image. To overcome this drawback, we present a \textit{Patch Refiner} to cluster patches into different groups and only select the highest distress-risk group to yield a slim head for the final image classification. We evaluate our method on CQU-BPDD. Extensive results show that \textbf{PicT} outperforms the second-best performed model by a large margin of $+2.4\%$ in P@R on detection task, $+3.9\%$ in $F1$ on recognition task, and 1.8x throughput, while enjoying 7x faster training speed using the same computing resources. Our codes and models have been released on \href{https://github.com/DearCaat/PicT}{https://github.com/DearCaat/PicT}.
Physically-Based Face Rendering for NIR-VIS Face Recognition
Nov 11, 2022



Near infrared (NIR) to Visible (VIS) face matching is challenging due to the significant domain gaps as well as a lack of sufficient data for cross-modality model training. To overcome this problem, we propose a novel method for paired NIR-VIS facial image generation. Specifically, we reconstruct 3D face shape and reflectance from a large 2D facial dataset and introduce a novel method of transforming the VIS reflectance to NIR reflectance. We then use a physically-based renderer to generate a vast, high-resolution and photorealistic dataset consisting of various poses and identities in the NIR and VIS spectra. Moreover, to facilitate the identity feature learning, we propose an IDentity-based Maximum Mean Discrepancy (ID-MMD) loss, which not only reduces the modality gap between NIR and VIS images at the domain level but encourages the network to focus on the identity features instead of facial details, such as poses and accessories. Extensive experiments conducted on four challenging NIR-VIS face recognition benchmarks demonstrate that the proposed method can achieve comparable performance with the state-of-the-art (SOTA) methods without requiring any existing NIR-VIS face recognition datasets. With slightly fine-tuning on the target NIR-VIS face recognition datasets, our method can significantly surpass the SOTA performance. Code and pretrained models are released under the insightface (https://github.com/deepinsight/insightface/tree/master/recognition).
MDFlow: Unsupervised Optical Flow Learning by Reliable Mutual Knowledge Distillation
Nov 11, 2022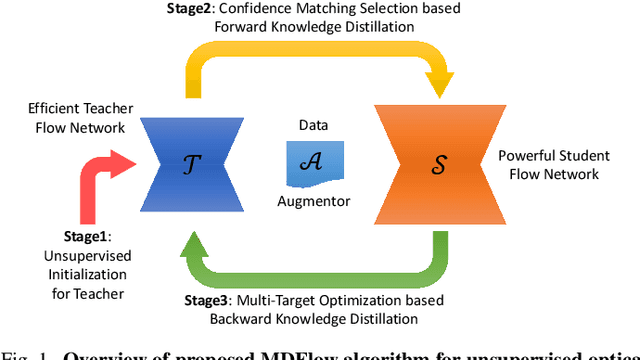
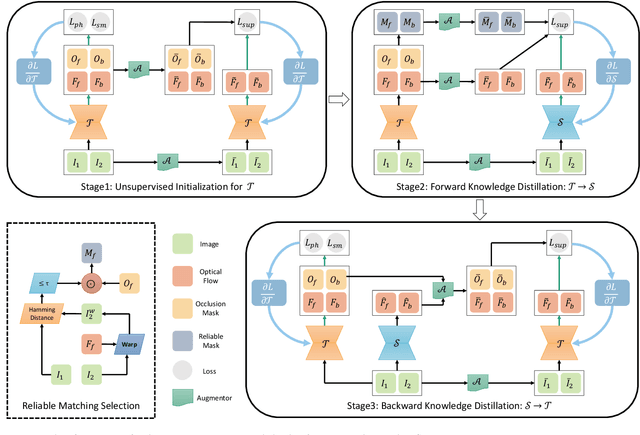
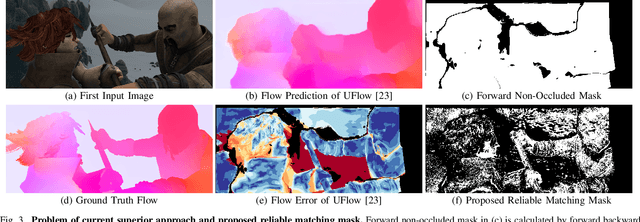
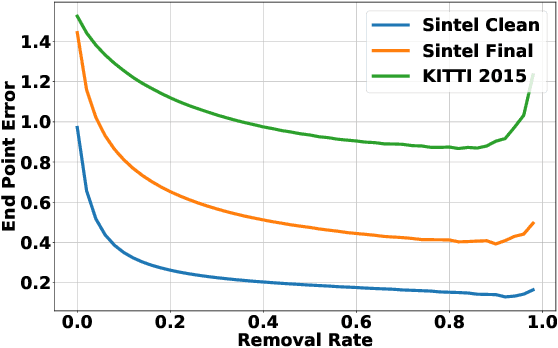
Recent works have shown that optical flow can be learned by deep networks from unlabelled image pairs based on brightness constancy assumption and smoothness prior. Current approaches additionally impose an augmentation regularization term for continual self-supervision, which has been proved to be effective on difficult matching regions. However, this method also amplify the inevitable mismatch in unsupervised setting, blocking the learning process towards optimal solution. To break the dilemma, we propose a novel mutual distillation framework to transfer reliable knowledge back and forth between the teacher and student networks for alternate improvement. Concretely, taking estimation of off-the-shelf unsupervised approach as pseudo labels, our insight locates at defining a confidence selection mechanism to extract relative good matches, and then add diverse data augmentation for distilling adequate and reliable knowledge from teacher to student. Thanks to the decouple nature of our method, we can choose a stronger student architecture for sufficient learning. Finally, better student prediction is adopted to transfer knowledge back to the efficient teacher without additional costs in real deployment. Rather than formulating it as a supervised task, we find that introducing an extra unsupervised term for multi-target learning achieves best final results. Extensive experiments show that our approach, termed MDFlow, achieves state-of-the-art real-time accuracy and generalization ability on challenging benchmarks. Code is available at https://github.com/ltkong218/MDFlow.
VLMAE: Vision-Language Masked Autoencoder
Aug 19, 2022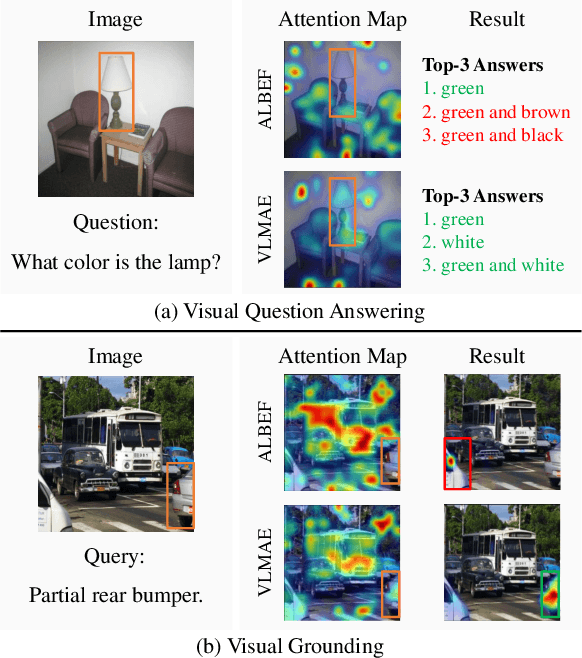
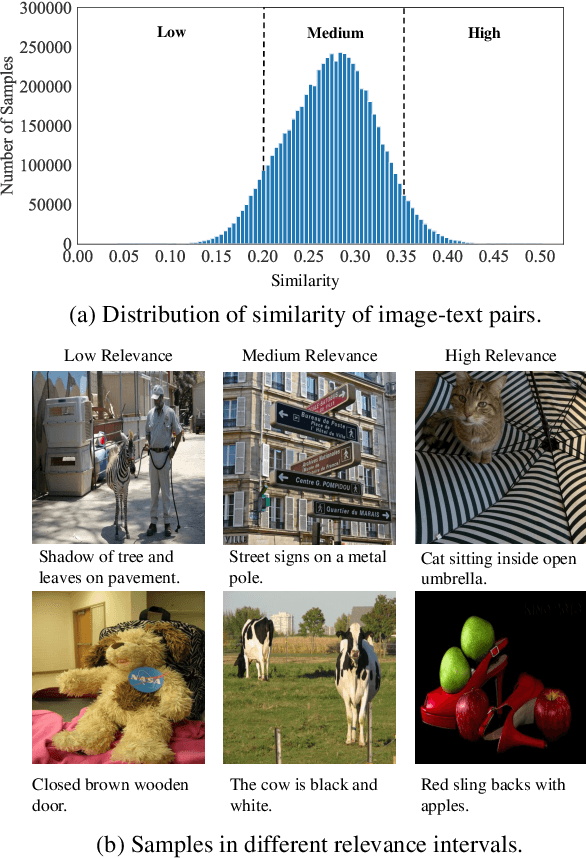
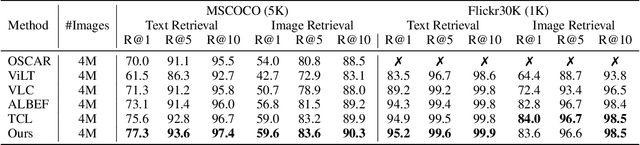
Image and language modeling is of crucial importance for vision-language pre-training (VLP), which aims to learn multi-modal representations from large-scale paired image-text data. However, we observe that most existing VLP methods focus on modeling the interactions between image and text features while neglecting the information disparity between image and text, thus suffering from focal bias. To address this problem, we propose a vision-language masked autoencoder framework (VLMAE). VLMAE employs visual generative learning, facilitating the model to acquire fine-grained and unbiased features. Unlike the previous works, VLMAE pays attention to almost all critical patches in an image, providing more comprehensive understanding. Extensive experiments demonstrate that VLMAE achieves better performance in various vision-language downstream tasks, including visual question answering, image-text retrieval and visual grounding, even with up to 20% pre-training speedup.