 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Rectification for Parameter-Efficient Adaptation of Foundation Models in Colonoscopy Depth Estimation
Mar 16, 2026Accurate monocular depth estimation is critical in colonoscopy for lesion localization and navigation. Foundation models trained on natural images fail to generalize directly to colonoscopy. We identify the core issue not as a semantic gap, but as a statistical shift in the frequency domain: colonoscopy images lack the strong high-frequency edge and texture gradients that these models rely on for geometric reasoning. To address this, we propose SpecDepth, a parameter-efficient adaptation framework that preserves the robust geometric representations of the pre-trained models while adapting to the colonoscopy domain. Its key innovation is an adaptive spectral rectification module, which uses a learnable wavelet decomposition to explicitly model and amplify the attenuated high-frequency components in feature maps. Different from conventional fine-tuning that risks distorting high-level semantic features, this targeted, low-level adjustment realigns the input signal with the original inductive bias of the foundational model. On the public C3VD and SimCol3D datasets, SpecDepth achieved state-of-the-art performance with an absolute relative error of 0.022 and 0.027, respectively. Our work demonstrates that directly addressing spectral mismatches is a highly effective strategy for adapting vision foundation models to specialized medical imaging tasks. The code will be released publicly after the manuscript is accepted for publication.
Multiple Instance Learning Framework with Masked Hard Instance Mining for Whole Slide Image Classification
Jul 31, 2023



The whole slide image (WSI) classification is often formulated as a multiple instance learning (MIL) problem. Since the positive tissue is only a small fraction of the gigapixel WSI, existing MIL methods intuitively focus on identifying salient instances via attention mechanisms. However, this leads to a bias towards easy-to-classify instances while neglecting hard-to-classify instances. Some literature has revealed that hard examples are beneficial for modeling a discriminative boundary accurately. By applying such an idea at the instance level, we elaborate a novel MIL framework with masked hard instance mining (MHIM-MIL), which uses a Siamese structure (Teacher-Student) with a consistency constraint to explore the potential hard instances. With several instance masking strategies based on attention scores, MHIM-MIL employs a momentum teacher to implicitly mine hard instances for training the student model, which can be any attention-based MIL model. This counter-intuitive strategy essentially enables the student to learn a better discriminating boundary. Moreover, the student is used to update the teacher with an exponential moving average (EMA), which in turn identifies new hard instances for subsequent training iterations and stabilizes the optimization. Experimental results on the CAMELYON-16 and TCGA Lung Cancer datasets demonstrate that MHIM-MIL outperforms other latest methods in terms of performance and training cost. The code is available at: https://github.com/DearCaat/MHIM-MIL.
PicT: A Slim Weakly Supervised Vision Transformer for Pavement Distress Classification
Sep 21, 2022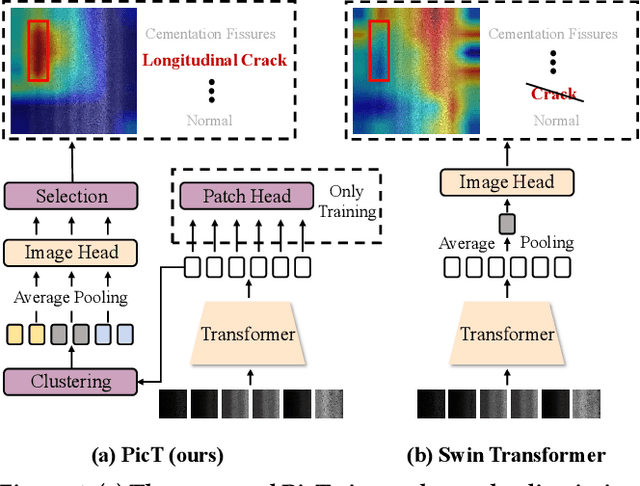
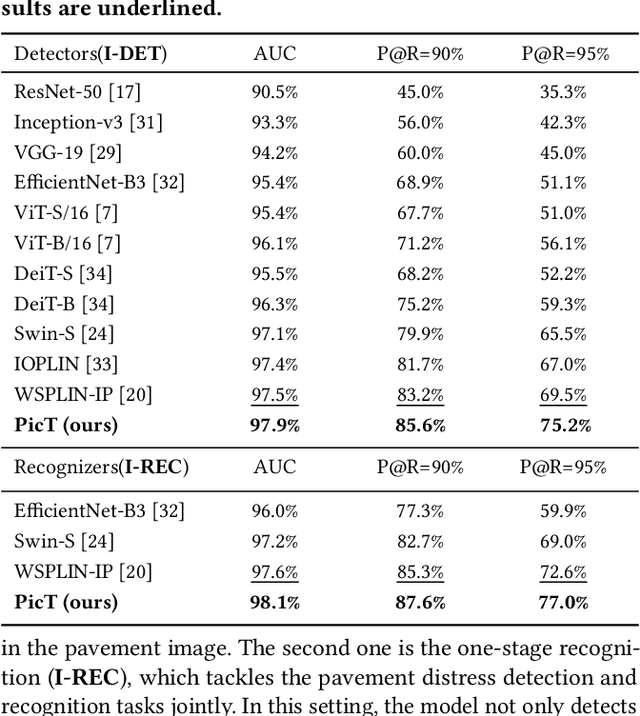
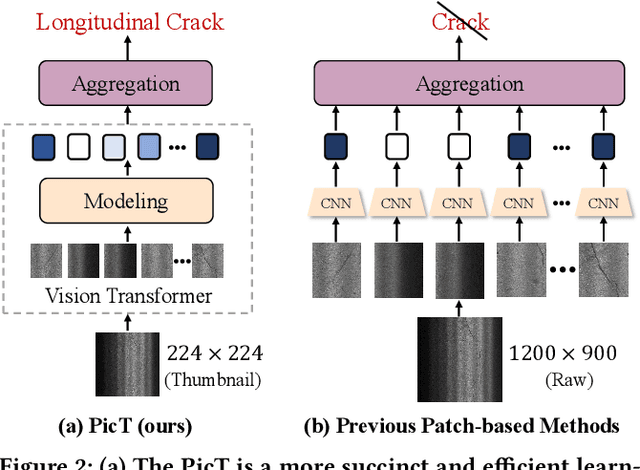
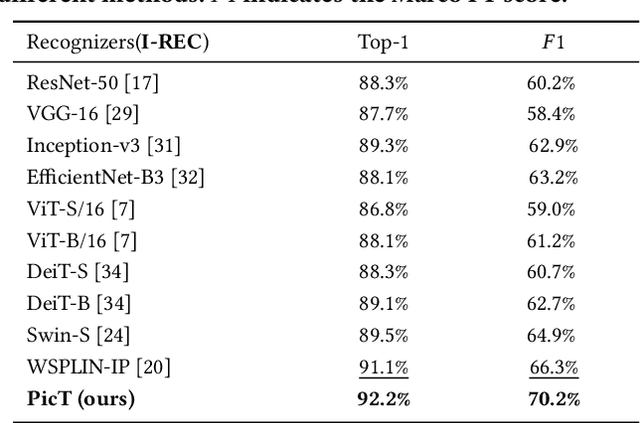
Automatic pavement distress classification facilitates improving the efficiency of pavement maintenance and reducing the cost of labor and resources. A recently influential branch of this task divides the pavement image into patches and addresses these issues from the perspective of multi-instance learning. However, these methods neglect the correlation between patches and suffer from a low efficiency in the model optimization and inference. Meanwhile, Swin Transformer is able to address both of these issues with its unique strengths. Built upon Swin Transformer, we present a vision Transformer named \textbf{P}avement \textbf{I}mage \textbf{C}lassification \textbf{T}ransformer (\textbf{PicT}) for pavement distress classification. In order to better exploit the discriminative information of pavement images at the patch level, the \textit{Patch Labeling Teacher} is proposed to leverage a teacher model to dynamically generate pseudo labels of patches from image labels during each iteration, and guides the model to learn the discriminative features of patches. The broad classification head of Swin Transformer may dilute the discriminative features of distressed patches in the feature aggregation step due to the small distressed area ratio of the pavement image. To overcome this drawback, we present a \textit{Patch Refiner} to cluster patches into different groups and only select the highest distress-risk group to yield a slim head for the final image classification. We evaluate our method on CQU-BPDD. Extensive results show that \textbf{PicT} outperforms the second-best performed model by a large margin of $+2.4\%$ in P@R on detection task, $+3.9\%$ in $F1$ on recognition task, and 1.8x throughput, while enjoying 7x faster training speed using the same computing resources. Our codes and models have been released on \href{https://github.com/DearCaat/PicT}{https://github.com/DearCaat/PicT}.