 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unified Multimodal Model with Unlikelihood Training for Visual Dialog
Nov 23, 2022
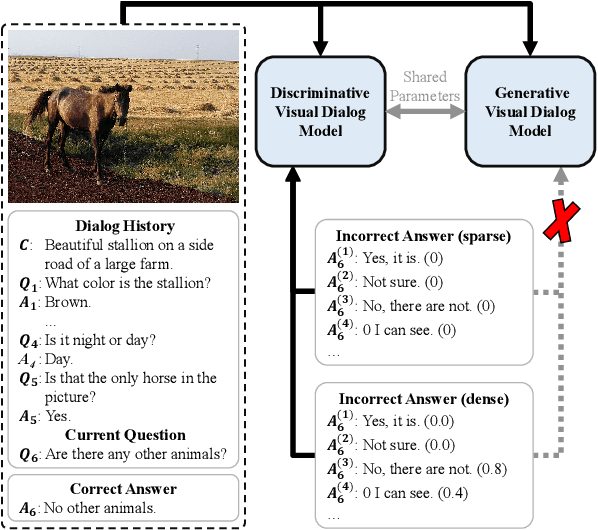
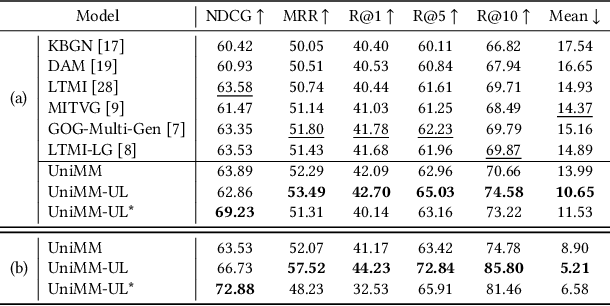
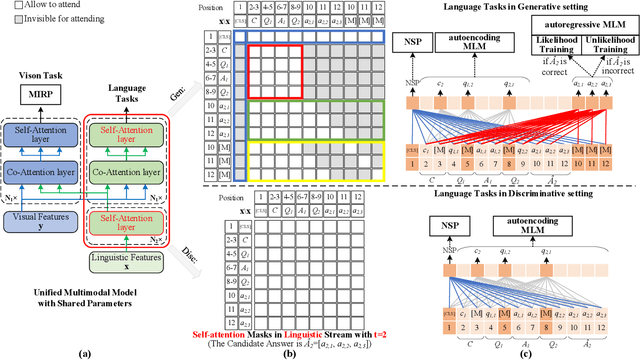
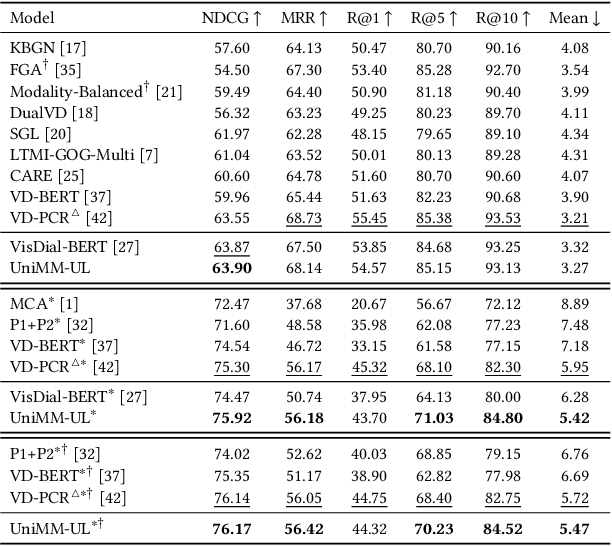
The task of visual dialog requires a multimodal chatbot to answer sequential questions from humans about image content. Prior work performs the standard likelihood training for answer generation on the positive instances (involving correct answers). However, the likelihood objective often leads to frequent and dull outputs and fails to exploit the useful knowledge from negative instances (involving incorrect answers). In this paper, we propose a Unified Multimodal Model with UnLikelihood Training, named UniMM-UL, to tackle this problem. First, to improve visual dialog understanding and generation by multi-task learning, our model extends ViLBERT from only supporting answer discrimination to holding both answer discrimination and answer generation seamlessly by different attention masks. Specifically, in order to make the original discriminative model compatible with answer generation, we design novel generative attention masks to implement the autoregressive Masked Language Modeling (autoregressive MLM) task. And to attenuate the adverse effects of the likelihood objective, we exploit unlikelihood training on negative instances to make the model less likely to generate incorrect answers. Then, to utilize dense annotations, we adopt different fine-tuning methods for both generating and discriminating answers, rather than just for discriminating answers as in the prior work. Finally, on the VisDial dataset, our model achieves the best generative results (69.23 NDCG score). And our model also yields comparable discriminative results with the state-of-the-art in both single-model and ensemble settings (75.92 and 76.17 NDCG scores).
SS-CXR: Multitask Representation Learning using Self Supervised Pre-training from Chest X-Rays
Nov 23, 2022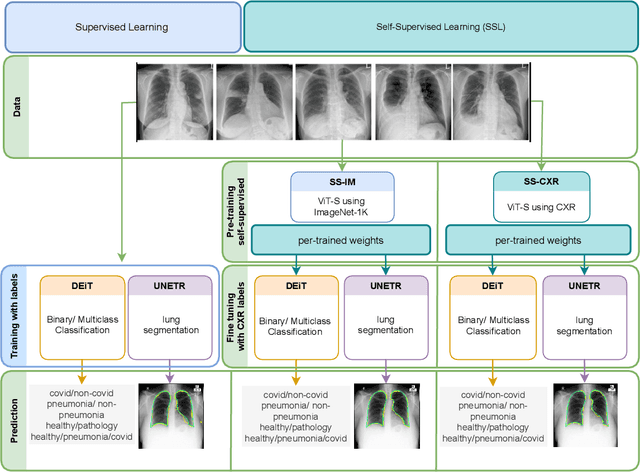

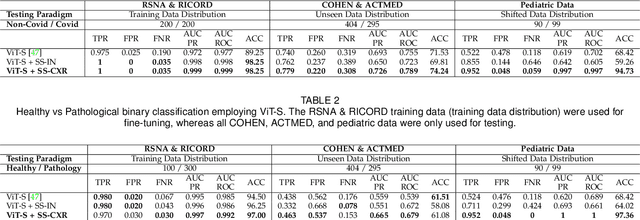

Chest X-rays (CXRs) are a widely used imaging modality for the diagnosis and prognosis of lung disease. The image analysis tasks vary. Examples include pathology detection and lung segmentation. There is a large body of work where machine learning algorithms are developed for specific tasks. A significant recent example is Coronavirus disease (covid-19) detection using CXR data. However, the traditional diagnostic tool design methods based on supervised learning are burdened by the need to provide training data annotation, which should be of good quality for better clinical outcomes. Here, we propose an alternative solution, a new self-supervised paradigm, where a general representation from CXRs is learned using a group-masked self-supervised framework. The pre-trained model is then fine-tuned for domain-specific tasks such as covid-19, pneumonia detection, and general health screening. We show that the same pre-training can be used for the lung segmentation task. Our proposed paradigm shows robust performance in multiple downstream tasks which demonstrates the success of the pre-training. Moreover, the performance of the pre-trained models on data with significant drift during test time proves the learning of a better generic representation. The methods are further validated by covid-19 detection in a unique small-scale pediatric data set. The performance gain in accuracy (~25\%) is significant when compared to a supervised transformer-based method. This adds credence to the strength and reliability of our proposed framework and pre-training strategy.
Benchmarking Adversarially Robust Quantum Machine Learning at Scale
Nov 23, 2022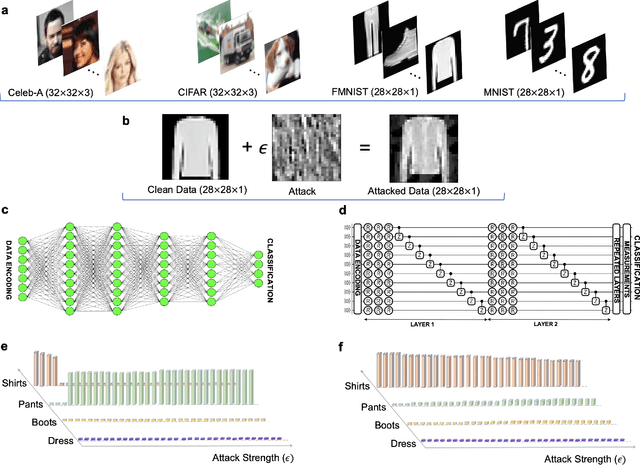
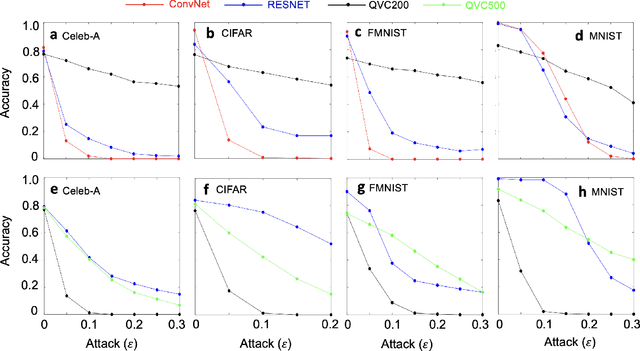

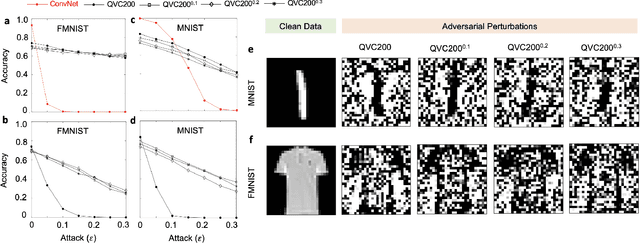
Machine learning (ML) methods such as artificial neural networks are rapidly becoming ubiquitous in modern science, technology and industry. Despite their accuracy and sophistication, neural networks can be easily fooled by carefully designed malicious inputs known as adversarial attacks. While such vulnerabilities remain a serious challenge for classical neural networks, the extent of their existence is not fully understood in the quantum ML setting. In this work, we benchmark the robustness of quantum ML networks, such as quantum variational classifiers (QVC), at scale by performing rigorous training for both simple and complex image datasets and through a variety of high-end adversarial attacks. Our results show that QVCs offer a notably enhanced robustness against classical adversarial attacks by learning features which are not detected by the classical neural networks, indicating a possible quantum advantage for ML tasks. Contrarily, and remarkably, the converse is not true, with attacks on quantum networks also capable of deceiving classical neural networks. By combining quantum and classical network outcomes, we propose a novel adversarial attack detection technology. Traditionally quantum advantage in ML systems has been sought through increased accuracy or algorithmic speed-up, but our work has revealed the potential for a new kind of quantum advantage through superior robustness of ML models, whose practical realisation will address serious security concerns and reliability issues of ML algorithms employed in a myriad of applications including autonomous vehicles, cybersecurity, and surveillance robotic systems.
Semantic-assisted image compression
Jan 29, 2022Conventional image compression methods typically aim at pixel-level consistency while ignoring the performance of downstream AI tasks.To solve this problem, this paper proposes a Semantic-Assisted Image Compression method (SAIC), which can maintain semantic-level consistency to enable high performance of downstream AI tasks.To this end, we train the compression network using semantic-level loss function. In particular, semantic-level loss is measured using gradient-based semantic weights mechanism (GSW). GSW directly consider downstream AI tasks' perceptual results. Then, this paper proposes a semantic-level distortion evaluation metric to quantify the amount of semantic information retained during the compression process. Experimental results show that the proposed SAIC method can retain more semantic-level information and achieve better performance of downstream AI tasks compared to the traditional deep learning-based method and the advanced perceptual method at the same compression ratio.
Green Hierarchical Vision Transformer for Masked Image Modeling
May 26, 2022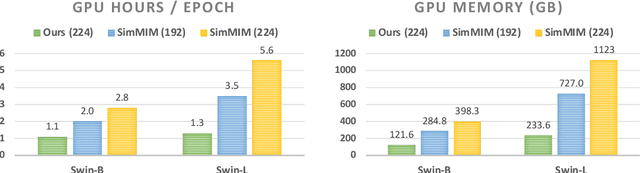
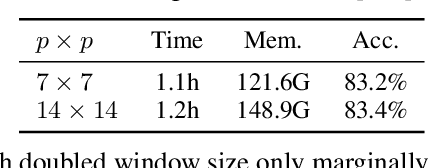
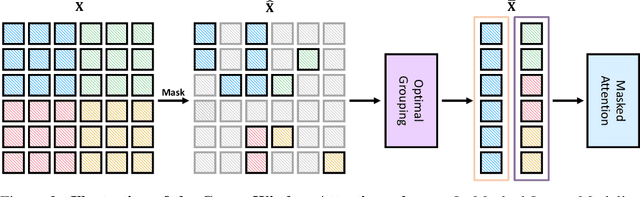
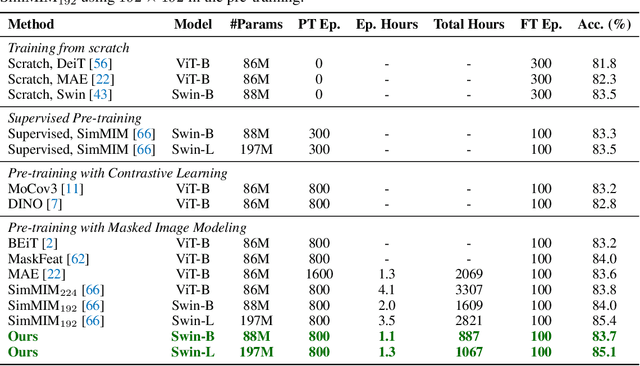
We present an efficient approach for Masked Image Modeling (MIM) with hierarchical Vision Transformers (ViTs), e.g., Swin Transformer, allowing the hierarchical ViTs to discard masked patches and operate only on the visible ones. Our approach consists of two key components. First, for the window attention, we design a Group Window Attention scheme following the Divide-and-Conquer strategy. To mitigate the quadratic complexity of the self-attention w.r.t. the number of patches, group attention encourages a uniform partition that visible patches within each local window of arbitrary size can be grouped with equal size, where masked self-attention is then performed within each group. Second, we further improve the grouping strategy via the Dynamic Programming algorithm to minimize the overall computation cost of the attention on the grouped patches. As a result, MIM now can work on hierarchical ViTs in a green and efficient way. For example, we can train the hierarchical ViTs about 2.7$\times$ faster and reduce the GPU memory usage by 70%, while still enjoying competitive performance on ImageNet classification and the superiority on downstream COCO object detection benchmarks. Code and pre-trained models have been made publicly available at https://github.com/LayneH/GreenMIM.
Investigating and Explaining the Frequency Bias in Image Classification
May 06, 2022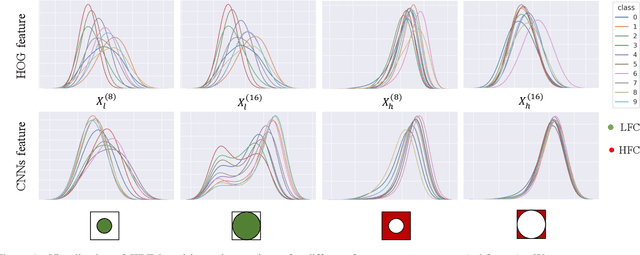
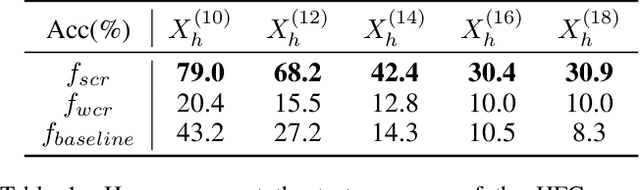
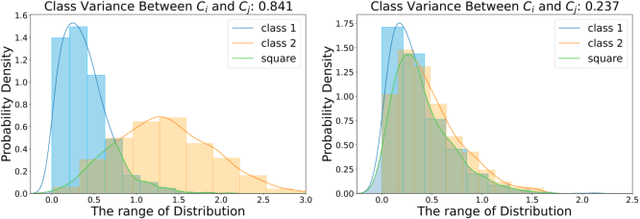
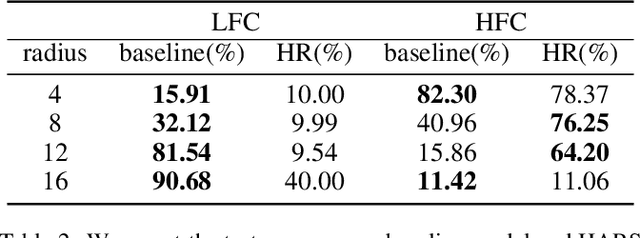
CNNs exhibit many behaviors different from humans, one of which is the capability of employing high-frequency components. This paper discusses the frequency bias phenomenon in image classification tasks: the high-frequency components are actually much less exploited than the low- and mid-frequency components. We first investigate the frequency bias phenomenon by presenting two observations on feature discrimination and learning priority. Furthermore, we hypothesize that (i) the spectral density, (ii) class consistency directly affect the frequency bias. Specifically, our investigations verify that the spectral density of datasets mainly affects the learning priority, while the class consistency mainly affects the feature discrimination.
Text2LIVE: Text-Driven Layered Image and Video Editing
Apr 05, 2022


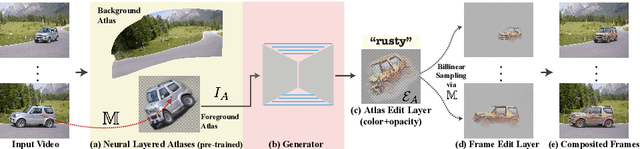
We present a method for zero-shot, text-driven appearance manipulation in natural images and videos. Given an input image or video and a target text prompt, our goal is to edit the appearance of existing objects (e.g., object's texture) or augment the scene with visual effects (e.g., smoke, fire) in a semantically meaningful manner. We train a generator using an internal dataset of training examples, extracted from a single input (image or video and target text prompt), while leveraging an external pre-trained CLIP model to establish our losses. Rather than directly generating the edited output, our key idea is to generate an edit layer (color+opacity) that is composited over the original input. This allows us to constrain the generation process and maintain high fidelity to the original input via novel text-driven losses that are applied directly to the edit layer. Our method neither relies on a pre-trained generator nor requires user-provided edit masks. We demonstrate localized, semantic edits on high-resolution natural images and videos across a variety of objects and scenes.
ARIA: Adversarially Robust Image Attribution for Content Provenance
Feb 25, 2022
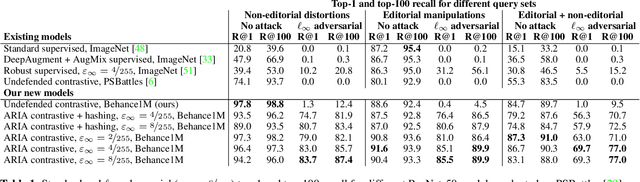

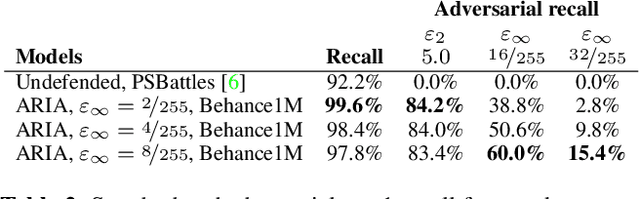
Image attribution -- matching an image back to a trusted source -- is an emerging tool in the fight against online misinformation. Deep visual fingerprinting models have recently been explored for this purpose. However, they are not robust to tiny input perturbations known as adversarial examples. First we illustrate how to generate valid adversarial images that can easily cause incorrect image attribution. Then we describe an approach to prevent imperceptible adversarial attacks on deep visual fingerprinting models, via robust contrastive learning. The proposed training procedure leverages training on $\ell_\infty$-bounded adversarial examples, it is conceptually simple and incurs only a small computational overhead. The resulting models are substantially more robust, are accurate even on unperturbed images, and perform well even over a database with millions of images. In particular, we achieve 91.6% standard and 85.1% adversarial recall under $\ell_\infty$-bounded perturbations on manipulated images compared to 80.1% and 0.0% from prior work. We also show that robustness generalizes to other types of imperceptible perturbations unseen during training. Finally, we show how to train an adversarially robust image comparator model for detecting editorial changes in matched images.
Can segmentation models be trained with fully synthetically generated data?
Sep 17, 2022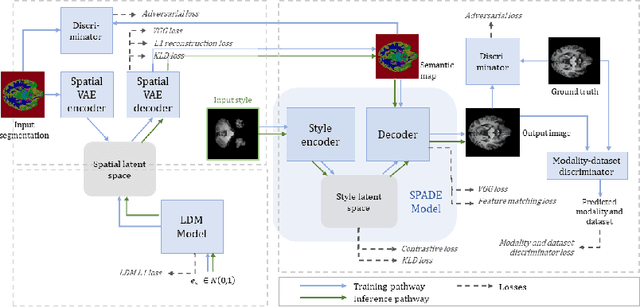

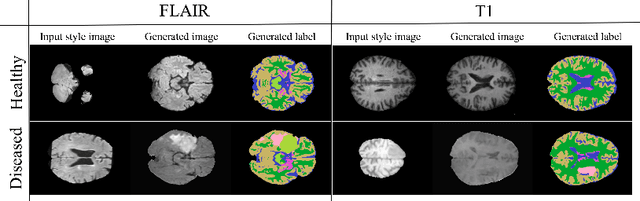
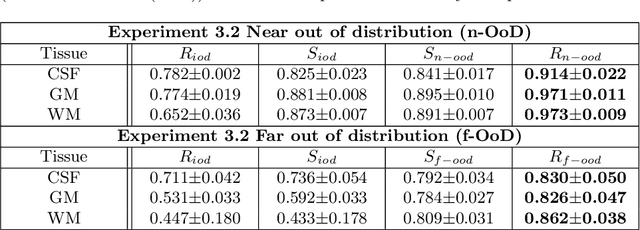
In order to achieve good performance and generalisability, medical image segmentation models should be trained on sizeable datasets with sufficient variability. Due to ethics and governance restrictions, and the costs associated with labelling data, scientific development is often stifled, with models trained and tested on limited data. Data augmentation is often used to artificially increase the variability in the data distribution and improve model generalisability. Recent works have explored deep generative models for image synthesis, as such an approach would enable the generation of an effectively infinite amount of varied data, addressing the generalisability and data access problems. However, many proposed solutions limit the user's control over what is generated. In this work, we propose brainSPADE, a model which combines a synthetic diffusion-based label generator with a semantic image generator. Our model can produce fully synthetic brain labels on-demand, with or without pathology of interest, and then generate a corresponding MRI image of an arbitrary guided style. Experiments show that brainSPADE synthetic data can be used to train segmentation models with performance comparable to that of models trained on real data.
A Hitchhiker`s Guide through the Bio-image Analysis Software Universe
Apr 15, 2022
Modern research in the life sciences is unthinkable without computational methods for extracting, quantifying and visualizing information derived from biological microscopy imaging data. In the past decade, we observed a dramatic increase in available software packages for these purposes. As it is increasingly difficult to keep track of the number of available image analysis platforms, tool collections, components and emerging technologies, we provide a conservative overview of software we use in daily routine and give insights into emerging new tools. We give guidance on which aspects to consider when choosing the right platform, including aspects such as image data type, skills of the team, infrastructure and community at the institute and availability of time and budget.