 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Style Transfer: from Artistic to Photorealistic
Mar 12, 2022



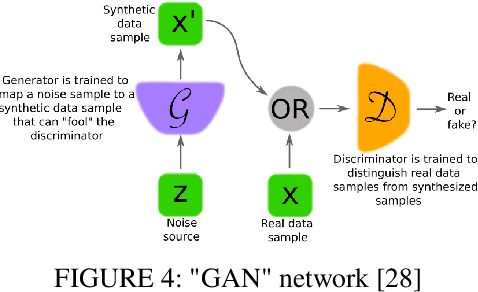
The rapid advancement of deep learning has significantly boomed the development of photorealistic style transfer. In this review, we reviewed the development of photorealistic style transfer starting from artistic style transfer and the contribution of traditional image processing techniques on photorealistic style transfer, including some work that had been completed in the Multimedia lab at the University of Alberta. Many techniques were discussed in this review. However, our focus is on VGG-based techniques, whitening and coloring transform (WCTs) based techniques, the combination of deep learning with traditional image processing techniques.
HiVLP: Hierarchical Vision-Language Pre-Training for Fast Image-Text Retrieval
May 24, 2022
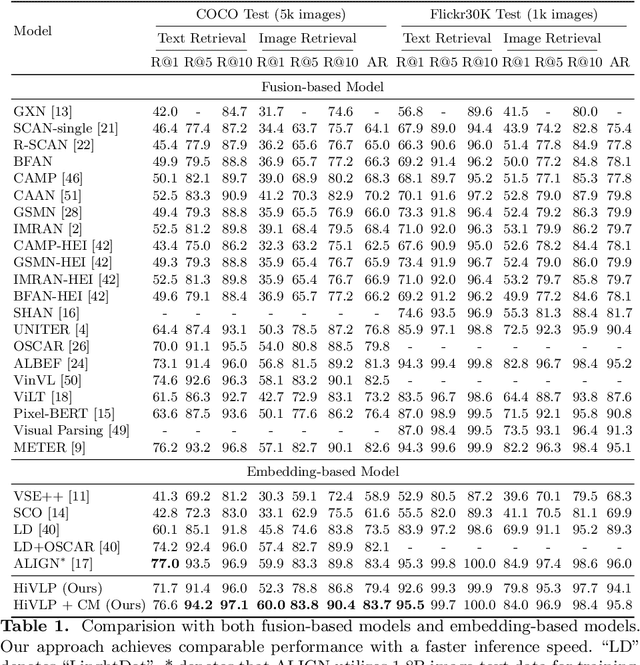
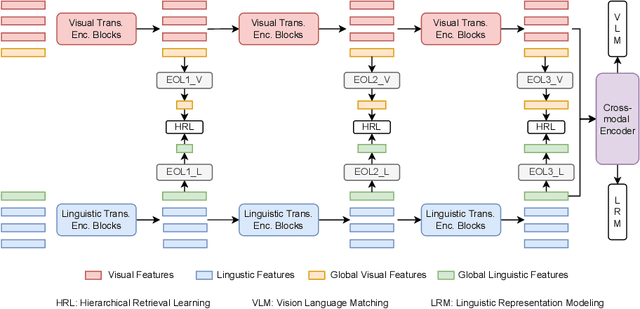
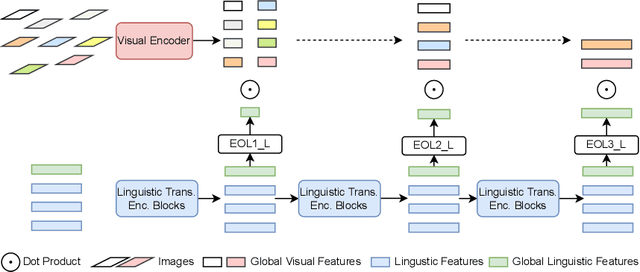
In the past few years, the emergence of vision-language pre-training (VLP) has brought cross-modal retrieval to a new era. However, due to the latency and computation demand, it is commonly challenging to apply VLP in a real-time online retrieval system. To alleviate the defect, this paper proposes a \textbf{Hi}erarchical \textbf{V}ision-\textbf{}Language \textbf{P}re-Training (\textbf{HiVLP}) for fast Image-Text Retrieval (ITR). Specifically, we design a novel hierarchical retrieval objective, which uses the representation of different dimensions for coarse-to-fine ITR, i.e., using low-dimensional representation for large-scale coarse retrieval and high-dimensional representation for small-scale fine retrieval. We evaluate our proposed HiVLP on two popular image-text retrieval benchmarks, i.e., Flickr30k and COCO. Extensive experiments demonstrate that our HiVLP not only has fast inference speed but also can be easily scaled to large-scale ITR scenarios. The detailed results show that HiVLP is $1,427$$\sim$$120,649\times$ faster than the fusion-based model UNITER and 2$\sim$5 faster than the fastest embedding-based model LightingDot in different candidate scenarios. It also achieves about +4.9 AR on COCO and +3.8 AR on Flickr30K than LightingDot and achieves comparable performance with the state-of-the-art (SOTA) fusion-based model METER.
SISL:Self-Supervised Image Signature Learning for Splicing Detection and Localization
Mar 15, 2022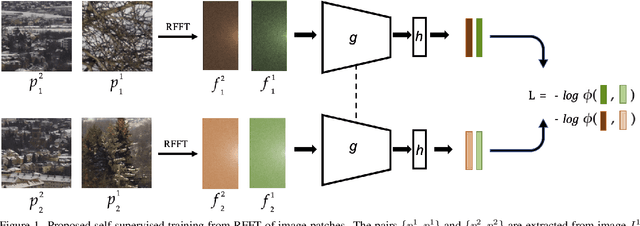
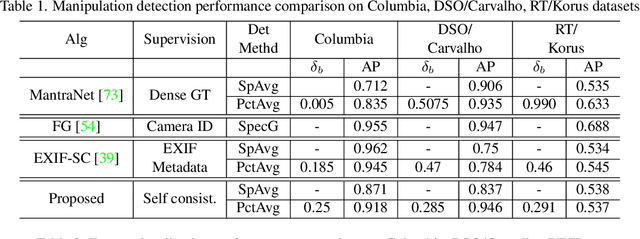
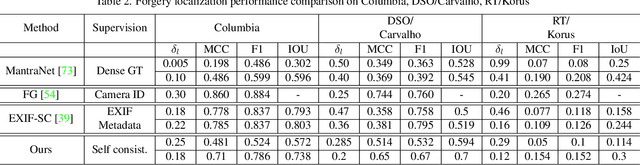

Recent algorithms for image manipulation detection almost exclusively use deep network models. These approaches require either dense pixelwise groundtruth masks, camera ids, or image metadata to train the networks. On one hand, constructing a training set to represent the countless tampering possibilities is impractical. On the other hand, social media platforms or commercial applications are often constrained to remove camera ids as well as metadata from images. A self-supervised algorithm for training manipulation detection models without dense groundtruth or camera/image metadata would be extremely useful for many forensics applications. In this paper, we propose self-supervised approach for training splicing detection/localization models from frequency transforms of images. To identify the spliced regions, our deep network learns a representation to capture an image specific signature by enforcing (image) self consistency . We experimentally demonstrate that our proposed model can yield similar or better performances of multiple existing methods on standard datasets without relying on labels or metadata.
U-Net and its variants for Medical Image Segmentation : A short review
Apr 17, 2022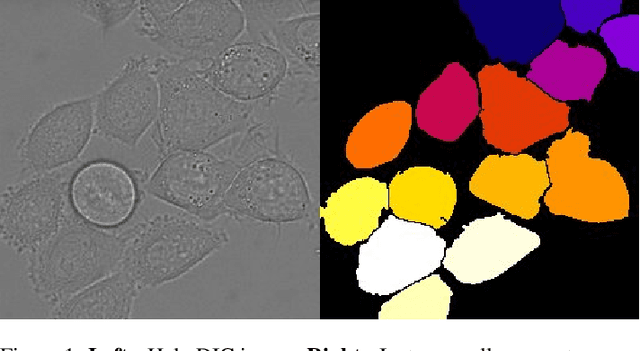
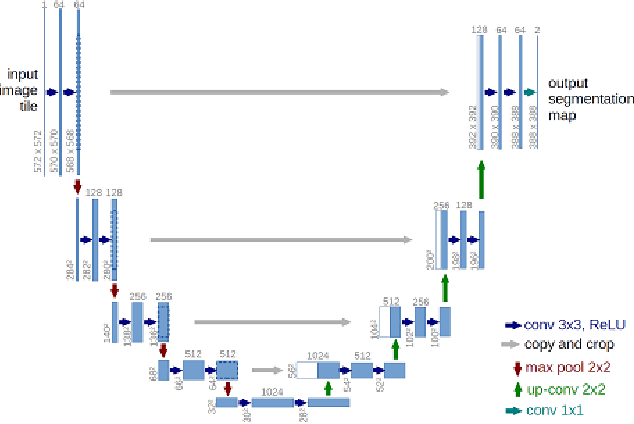
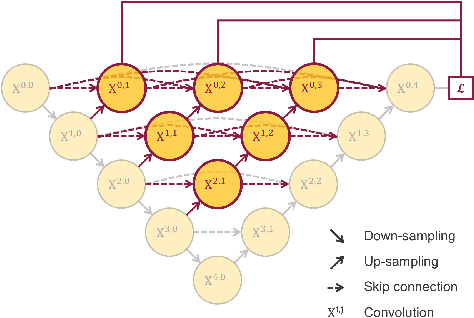
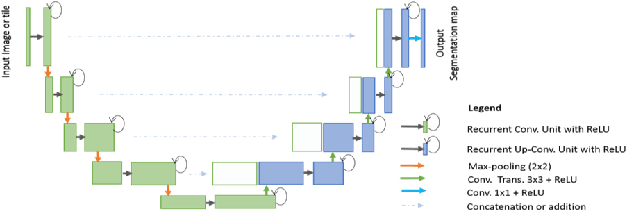
The paper is a short review of medical image segmentation using U-Net and its variants. As we understand going through a medical images is not an easy job for any clinician either radiologist or pathologist. Analysing medical images is the only way to perform non-invasive diagnosis. Segmenting out the regions of interest has significant importance in medical images and is key for diagnosis. This paper also gives a bird eye view of how medical image segmentation has evolved. Also discusses challenge's and success of the deep neural architectures. Following how different hybrid architectures have built upon strong techniques from visual recognition tasks. In the end we will see current challenges and future directions for medical image segmentation(MIS).
A Fast Alternating Minimization Algorithm for Coded Aperture Snapshot Spectral Imaging Based on Sparsity and Deep Image Priors
Jun 12, 2022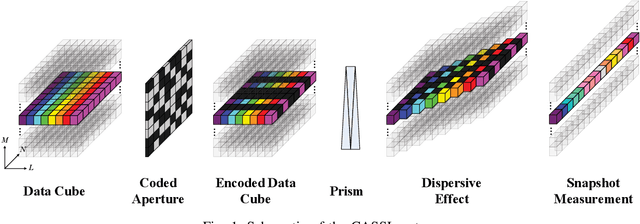
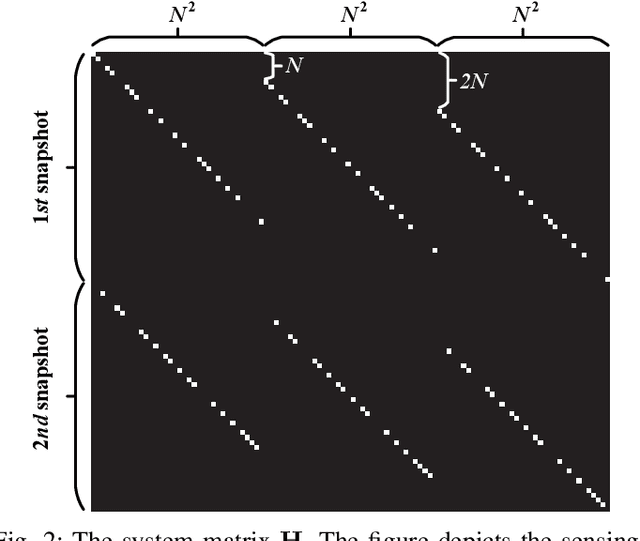
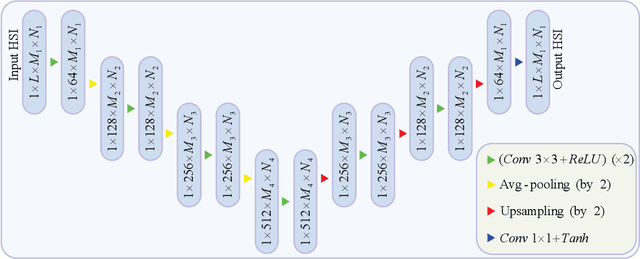

Coded aperture snapshot spectral imaging (CASSI) is a technique used to reconstruct three-dimensional hyperspectral images (HSIs) from one or several two-dimensional projection measurements. However, fewer projection measurements or more spectral channels leads to a severly ill-posed problem, in which case regularization methods have to be applied. In order to significantly improve the accuracy of reconstruction, this paper proposes a fast alternating minimization algorithm based on the sparsity and deep image priors (Fama-SDIP) of natural images. By integrating deep image prior (DIP) into the principle of compressive sensing (CS) reconstruction, the proposed algorithm can achieve state-of-the-art results without any training dataset. Extensive experiments show that Fama-SDIP method significantly outperforms prevailing leading methods on simulation and real HSI datasets.
Incremental Predictive Coding: A Parallel and Fully Automatic Learning Algorithm
Nov 16, 2022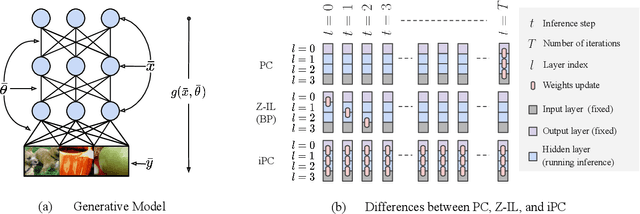
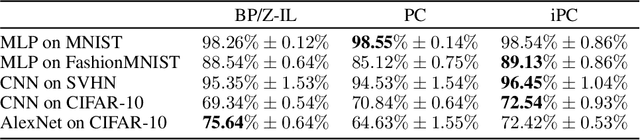


Neuroscience-inspired models, such as predictive coding, have the potential to play an important role in the future of machine intelligence. However, they are not yet used in industrial applications due to some limitations, such as the lack of efficiency. In this work, we address this by proposing incremental predictive coding (iPC), a variation of the original framework derived from the incremental expectation maximization algorithm, where every operation can be performed in parallel without external control. We show both theoretically and empirically that iPC is much faster than the original algorithm originally developed by Rao and Ballard, while maintaining performance comparable to backpropagation in image classification tasks. This work impacts several areas, has general applications in computational neuroscience and machine learning, and specific applications in scenarios where automatization and parallelization are important, such as distributed computing and implementations of deep learning models on analog and neuromorphic chips.
Interclass Prototype Relation for Few-Shot Segmentation
Nov 16, 2022Traditional semantic segmentation requires a large labeled image dataset and can only be predicted within predefined classes. To solve this problem, few-shot segmentation, which requires only a handful of annotations for the new target class, is important. However, with few-shot segmentation, the target class data distribution in the feature space is sparse and has low coverage because of the slight variations in the sample data. Setting the classification boundary that properly separates the target class from other classes is an impossible task. In particular, it is difficult to classify classes that are similar to the target class near the boundary. This study proposes the Interclass Prototype Relation Network (IPRNet), which improves the separation performance by reducing the similarity between other classes. We conducted extensive experiments with Pascal-5i and COCO-20i and showed that IPRNet provides the best segmentation performance compared with previous research.
ChartParser: Automatic Chart Parsing for Print-Impaired
Nov 16, 2022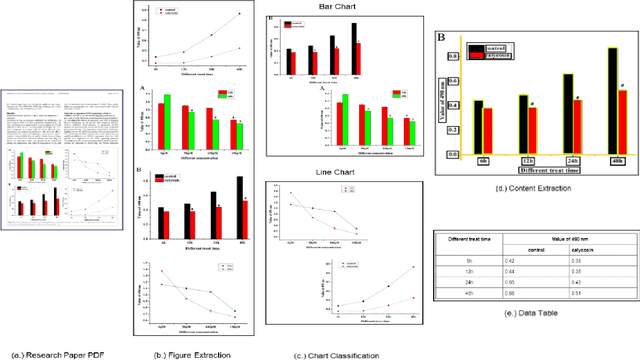
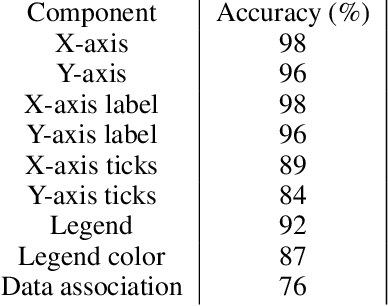
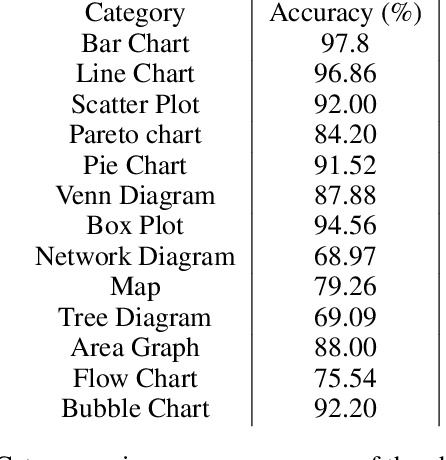
Infographics are often an integral component of scientific documents for reporting qualitative or quantitative findings as they make it much simpler to comprehend the underlying complex information. However, their interpretation continues to be a challenge for the blind, low-vision, and other print-impaired (BLV) individuals. In this paper, we propose ChartParser, a fully automated pipeline that leverages deep learning, OCR, and image processing techniques to extract all figures from a research paper, classify them into various chart categories (bar chart, line chart, etc.) and obtain relevant information from them, specifically bar charts (including horizontal, vertical, stacked horizontal and stacked vertical charts) which already have several exciting challenges. Finally, we present the retrieved content in a tabular format that is screen-reader friendly and accessible to the BLV users. We present a thorough evaluation of our approach by applying our pipeline to sample real-world annotated bar charts from research papers.
Object Class Aware Video Anomaly Detection through Image Translation
May 03, 2022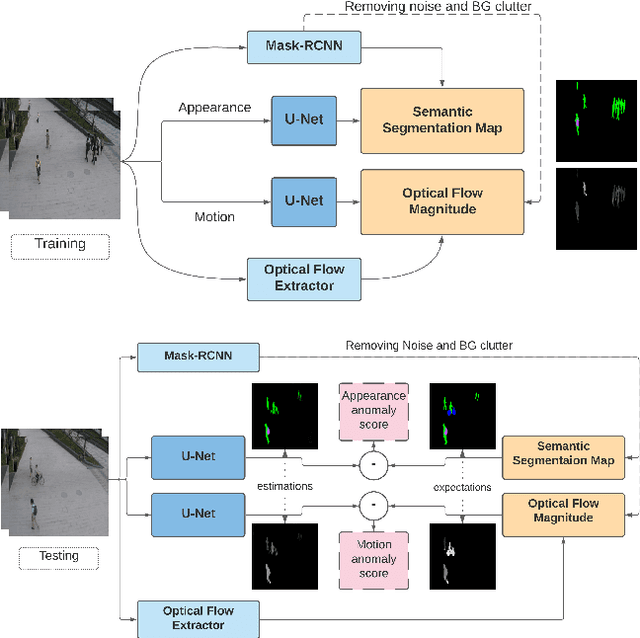
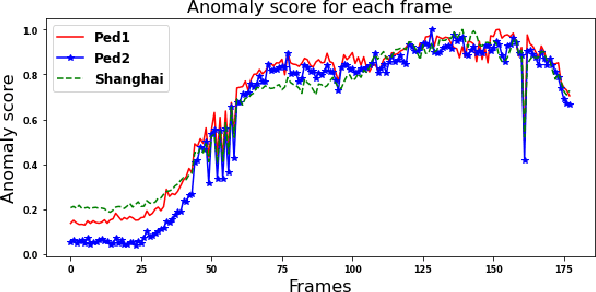
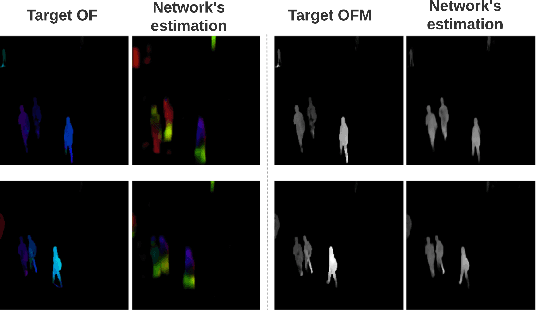
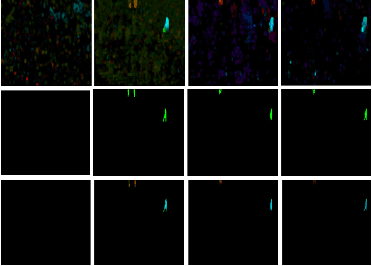
Semi-supervised video anomaly detection (VAD) methods formulate the task of anomaly detection as detection of deviations from the learned normal patterns. Previous works in the field (reconstruction or prediction-based methods) suffer from two drawbacks: 1) They focus on low-level features, and they (especially holistic approaches) do not effectively consider the object classes. 2) Object-centric approaches neglect some of the context information (such as location). To tackle these challenges, this paper proposes a novel two-stream object-aware VAD method that learns the normal appearance and motion patterns through image translation tasks. The appearance branch translates the input image to the target semantic segmentation map produced by Mask-RCNN, and the motion branch associates each frame with its expected optical flow magnitude. Any deviation from the expected appearance or motion in the inference stage shows the degree of potential abnormality. We evaluated our proposed method on the ShanghaiTech, UCSD-Ped1, and UCSD-Ped2 datasets and the results show competitive performance compared with state-of-the-art works. Most importantly, the results show that, as significant improvements to previous methods, detections by our method are completely explainable and anomalies are localized accurately in the frames.
Spot the fake lungs: Generating Synthetic Medical Images using Neural Diffusion Models
Nov 02, 2022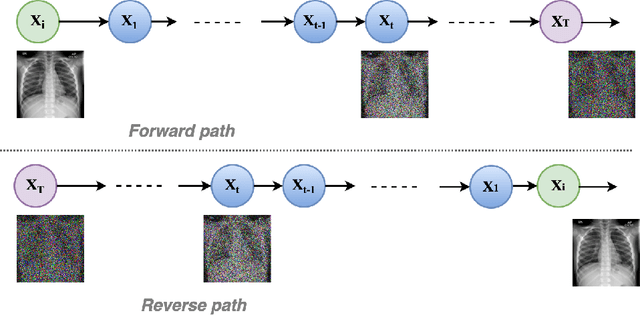
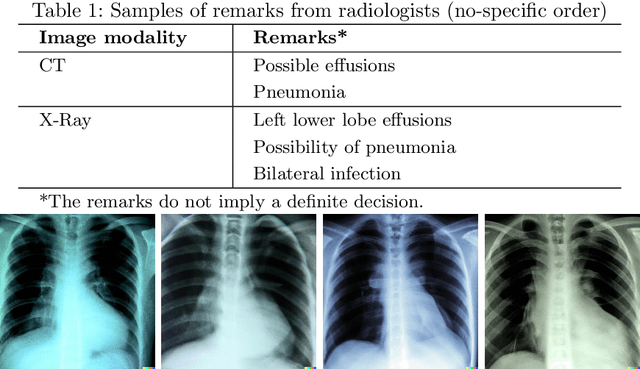
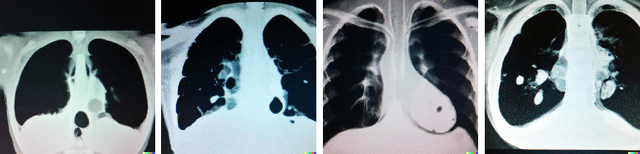
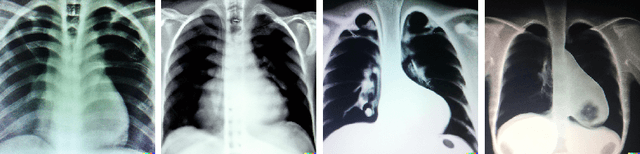
Generative models are becoming popular for the synthesis of medical images. Recently, neural diffusion models have demonstrated the potential to generate photo-realistic images of objects. However, their potential to generate medical images is not explored yet. In this work, we explore the possibilities of synthesis of medical images using neural diffusion models. First, we use a pre-trained DALLE2 model to generate lungs X-Ray and CT images from an input text prompt. Second, we train a stable diffusion model with 3165 X-Ray images and generate synthetic images. We evaluate the synthetic image data through a qualitative analysis where two independent radiologists label randomly chosen samples from the generated data as real, fake, or unsure. Results demonstrate that images generated with the diffusion model can translate characteristics that are otherwise very specific to certain medical conditions in chest X-Ray or CT images. Careful tuning of the model can be very promising. To the best of our knowledge, this is the first attempt to generate lungs X-Ray and CT images using neural diffusion models. This work aims to introduce a new dimension in artificial intelligence for medical imaging. Given that this is a new topic, the paper will serve as an introduction and motivation for the research community to explore the potential of diffusion models for medical image synthesis. We have released the synthetic images on https://www.kaggle.com/datasets/hazrat/awesomelungs.