 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiBCLaG: A Trigger-induced Bistable Compliant Laparoscopic Grasper
Mar 19, 2026Industrial laparoscopic graspers use multi-link rigid mechanisms manufactured to tight tolerances, resulting in high manufacturing and assembly costs. This work presents the design and proof-of-concept validation of a monolithic, fully compliant, bistable, laparoscopic grasper that eliminates the need for multiple rigid links, thereby reducing part count. The device integrates a compliant trigger and a compliant gripper end-effector, coupled via a control push-rod, to achieve stable grasping without continuous user input. The trigger mechanism is synthesized using a Two-Element Beam Constraint Model as a design framework to control the deformation and stiffness of V-beam-like elements. This technique enables elastic energy storage while preventing snap-through instability. The end-effector is designed as a compliant gripper to achieve adaptive grasping through elastic deformation. Jaws' opening-and-closing performance is demonstrated using nonlinear finite element analysis. The laparoscopic design presented here is fabricated using fused deposition 3D printing. The fabricated prototype demonstrates reliable bistable actuation, confirming the feasibility of such compliant laparoscopic grasper architectures.
ROAD: Reflective Optimization via Automated Debugging for Zero-Shot Agent Alignment
Dec 30, 2025Automatic Prompt Optimization (APO) has emerged as a critical technique for enhancing Large Language Model (LLM) performance, yet current state-of-the-art methods typically rely on large, labeled gold-standard development sets to compute fitness scores for evolutionary or Reinforcement Learning (RL) approaches. In real-world software engineering, however, such curated datasets are rarely available during the initial cold start of agent development, where engineers instead face messy production logs and evolving failure modes. We present ROAD (Reflective Optimization via Automated Debugging), a novel framework that bypasses the need for refined datasets by treating optimization as a dynamic debugging investigation rather than a stochastic search. Unlike traditional mutation strategies, ROAD utilizes a specialized multi-agent architecture, comprising an Analyzer for root-cause analysis, an Optimizer for pattern aggregation, and a Coach for strategy integration, to convert unstructured failure logs into robust, structured Decision Tree Protocols. We evaluated ROAD across both a standardized academic benchmark and a live production Knowledge Management engine. Experimental results demonstrate that ROAD is highly sample-efficient, achieving a 5.6 percent increase in success rate (73.6 percent to 79.2 percent) and a 3.8 percent increase in search accuracy within just three automated iterations. Furthermore, on complex reasoning tasks in the retail domain, ROAD improved agent performance by approximately 19 percent relative to the baseline. These findings suggest that mimicking the human engineering loop of failure analysis and patching offers a viable, data-efficient alternative to resource-intensive RL training for deploying reliable LLM agents.
Automated design of pneumatic soft grippers through design-dependent multi-material topology optimization
Nov 25, 2022



In recent years, soft robotic grasping has rapidly spread through the academic robotics community and pushed into industrial applications. At the same time, multimaterial 3D printing has become widely available, enabling monolithic manufacture of devices containing rigid and elastic section. We propose a novel design technique which leverages both of these technologies and is able to automatically design bespoke soft robotic grippers for fruit-picking and similar applications. We demonstrate the novel topology optimisation formulation which generates multi-material soft gippers and is able to solve both the internal and external pressure boundaries, and investigate methods to produce air-tight designs. Compared to existing methods, it vastly expands the searchable design space whilst increasing simulation accuracy.
SISL:Self-Supervised Image Signature Learning for Splicing Detection and Localization
Mar 15, 2022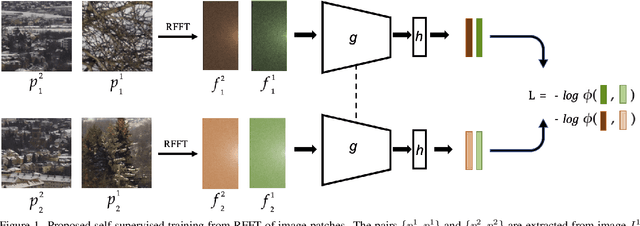
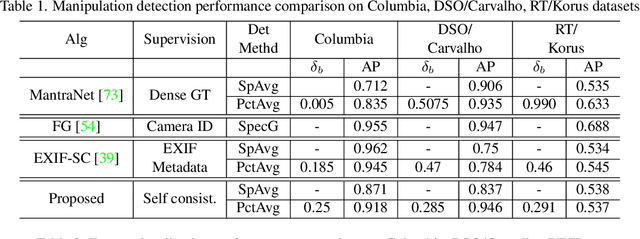
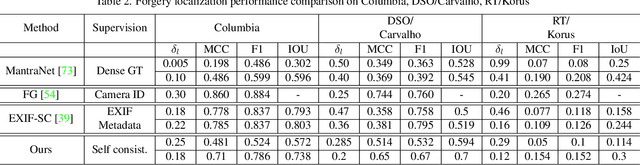

Recent algorithms for image manipulation detection almost exclusively use deep network models. These approaches require either dense pixelwise groundtruth masks, camera ids, or image metadata to train the networks. On one hand, constructing a training set to represent the countless tampering possibilities is impractical. On the other hand, social media platforms or commercial applications are often constrained to remove camera ids as well as metadata from images. A self-supervised algorithm for training manipulation detection models without dense groundtruth or camera/image metadata would be extremely useful for many forensics applications. In this paper, we propose self-supervised approach for training splicing detection/localization models from frequency transforms of images. To identify the spliced regions, our deep network learns a representation to capture an image specific signature by enforcing (image) self consistency . We experimentally demonstrate that our proposed model can yield similar or better performances of multiple existing methods on standard datasets without relying on labels or metadata.
Detecting Face2Face Facial Reenactment in Videos
Jan 21, 2020


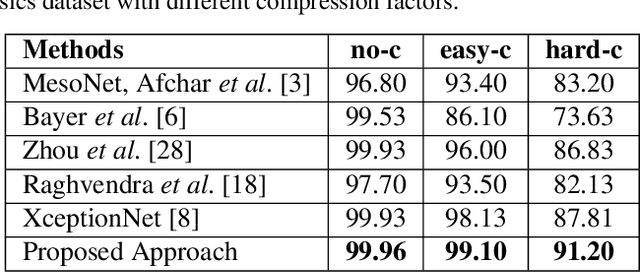
Visual content has become the primary source of information, as evident in the billions of images and videos, shared and uploaded on the Internet every single day. This has led to an increase in alterations in images and videos to make them more informative and eye-catching for the viewers worldwide. Some of these alterations are simple, like copy-move, and are easily detectable, while other sophisticated alterations like reenactment based DeepFakes are hard to detect. Reenactment alterations allow the source to change the target expressions and create photo-realistic images and videos. While technology can be potentially used for several applications, the malicious usage of automatic reenactment has a very large social implication. It is therefore important to develop detection techniques to distinguish real images and videos with the altered ones. This research proposes a learning-based algorithm for detecting reenactment based alterations. The proposed algorithm uses a multi-stream network that learns regional artifacts and provides a robust performance at various compression levels. We also propose a loss function for the balanced learning of the streams for the proposed network. The performance is evaluated on the publicly available FaceForensics dataset. The results show state-of-the-art classification accuracy of 99.96%, 99.10%, and 91.20% for no, easy, and hard compression factors, respectively.
A Reinforcement Learning Approach to Target Tracking in a Camera Network
Jul 26, 2018
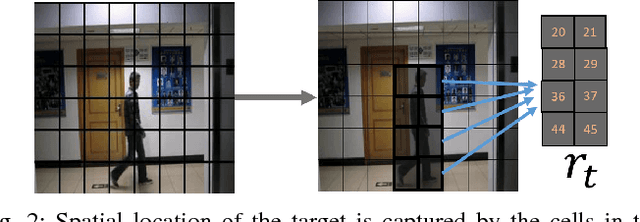
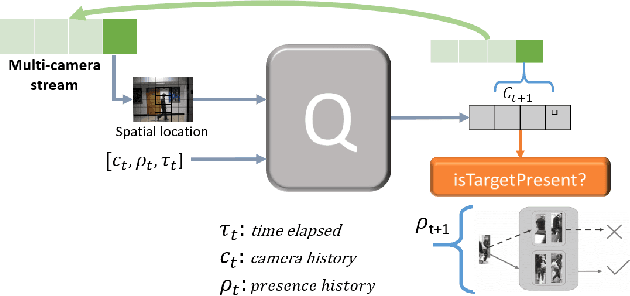
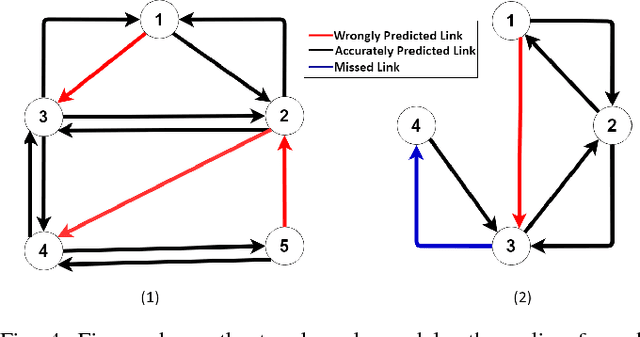
Target tracking in a camera network is an important task for surveillance and scene understanding. The task is challenging due to disjoint views and illumination variation in different cameras. In this direction, many graph-based methods were proposed using appearance-based features. However, the appearance information fades with high illumination variation in the different camera FOVs. We, in this paper, use spatial and temporal information as the state of the target to learn a policy that predicts the next camera given the current state. The policy is trained using Q-learning and it does not assume any information about the topology of the camera network. We will show that the policy learns the camera network topology. We demonstrate the performance of the proposed method on the NLPR MCT dataset.
Foresee: Attentive Future Projections of Chaotic Road Environments with Online Training
May 30, 2018
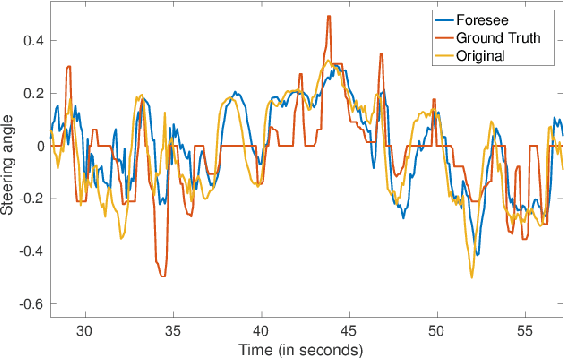
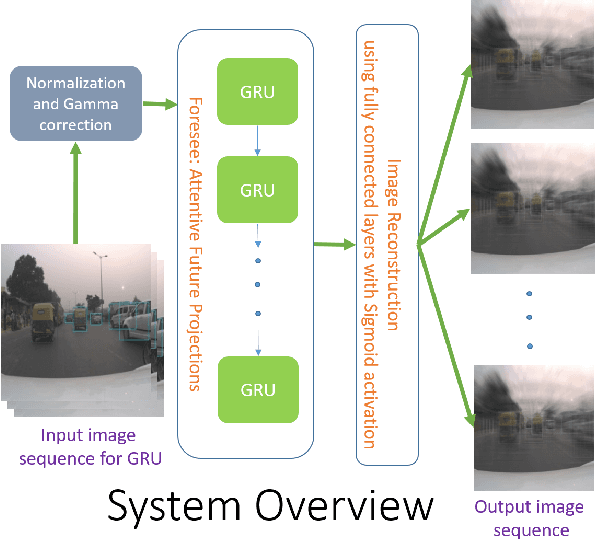
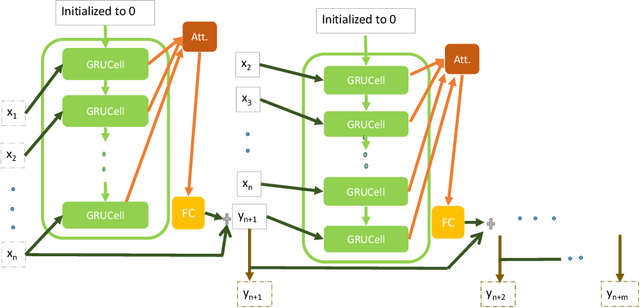
In this paper, we train a recurrent neural network to learn dynamics of a chaotic road environment and to project the future of the environment on an image. Future projection can be used to anticipate an unseen environment for example, in autonomous driving. Road environment is highly dynamic and complex due to the interaction among traffic participants such as vehicles and pedestrians. Even in this complex environment, a human driver is efficacious to safely drive on chaotic roads irrespective of the number of traffic participants. The proliferation of deep learning research has shown the efficacy of neural networks in learning this human behavior. In the same direction, we investigate recurrent neural networks to understand the chaotic road environment which is shared by pedestrians, vehicles (cars, trucks, bicycles etc.), and sometimes animals as well. We propose \emph{Foresee}, a unidirectional gated recurrent units (GRUs) network with attention to project future of the environment in the form of images. We have collected several videos on Delhi roads consisting of various traffic participants, background and infrastructure differences (like 3D pedestrian crossing) at various times on various days. We train \emph{Foresee} in an unsupervised way and we use online training to project frames up to $0.5$ seconds in advance. We show that our proposed model performs better than state of the art methods (prednet and Enc. Dec. LSTM) and finally, we show that our trained model generalizes to a public dataset for future projections.