 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A survey on text generation using generative adversarial networks
Dec 20, 2022

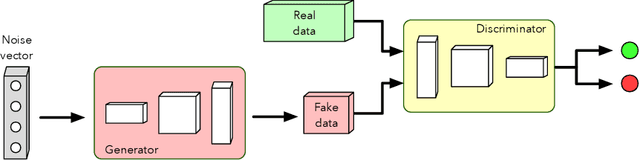
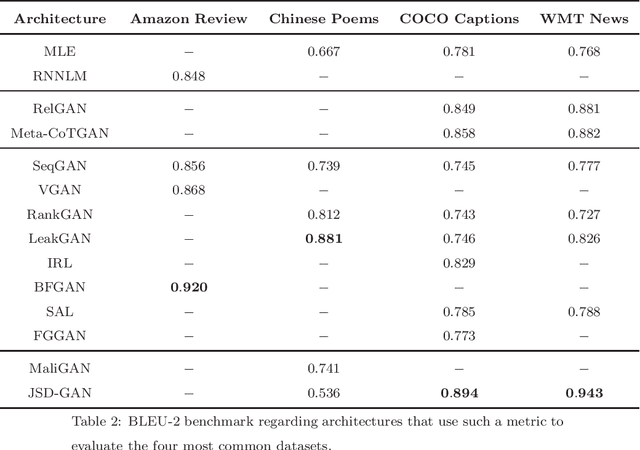
This work presents a thorough review concerning recent studies and text generation advancements using Generative Adversarial Networks. The usage of adversarial learning for text generation is promising as it provides alternatives to generate the so-called "natural" language. Nevertheless, adversarial text generation is not a simple task as its foremost architecture, the Generative Adversarial Networks, were designed to cope with continuous information (image) instead of discrete data (text). Thus, most works are based on three possible options, i.e., Gumbel-Softmax differentiation, Reinforcement Learning, and modified training objectives. All alternatives are reviewed in this survey as they present the most recent approaches for generating text using adversarial-based techniques. The selected works were taken from renowned databases, such as Science Direct, IEEEXplore, Springer, Association for Computing Machinery, and arXiv, whereas each selected work has been critically analyzed and assessed to present its objective, methodology, and experimental results.
Truncate-Split-Contrast: A Framework for Learning from Mislabeled Videos
Dec 29, 2022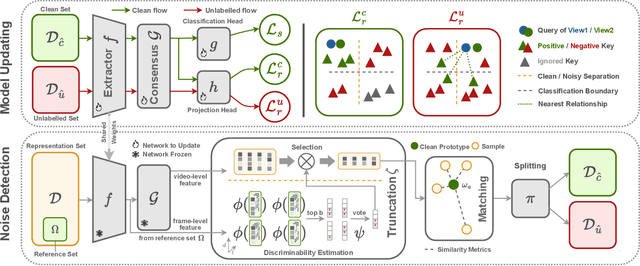
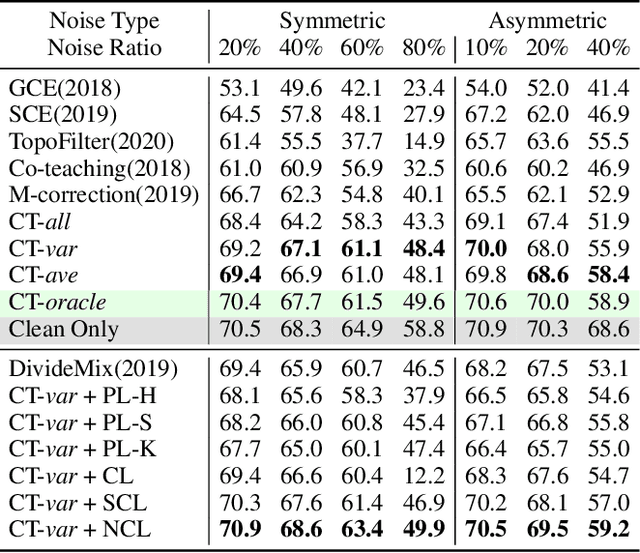
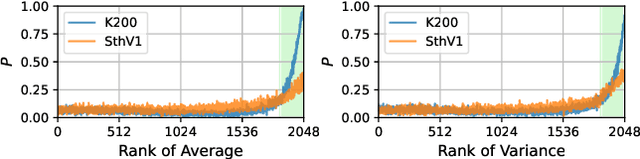
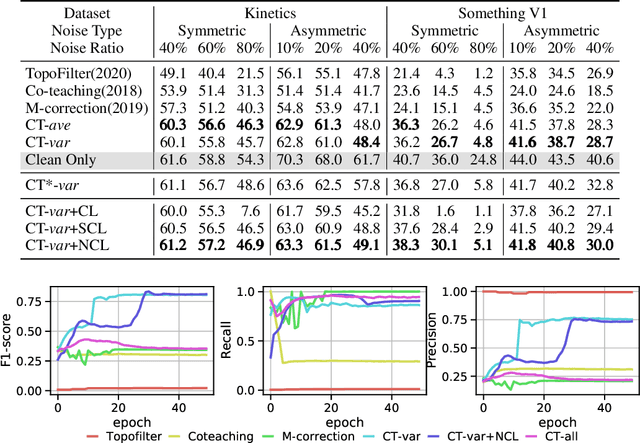
Learning with noisy label (LNL) is a classic problem that has been extensively studied for image tasks, but much less for video in the literature. A straightforward migration from images to videos without considering the properties of videos, such as computational cost and redundant information, is not a sound choice. In this paper, we propose two new strategies for video analysis with noisy labels: 1) A lightweight channel selection method dubbed as Channel Truncation for feature-based label noise detection. This method selects the most discriminative channels to split clean and noisy instances in each category; 2) A novel contrastive strategy dubbed as Noise Contrastive Learning, which constructs the relationship between clean and noisy instances to regularize model training. Experiments on three well-known benchmark datasets for video classification show that our proposed tru{\bf N}cat{\bf E}-split-contr{\bf A}s{\bf T} (NEAT) significantly outperforms the existing baselines. By reducing the dimension to 10\% of it, our method achieves over 0.4 noise detection F1-score and 5\% classification accuracy improvement on Mini-Kinetics dataset under severe noise (symmetric-80\%). Thanks to Noise Contrastive Learning, the average classification accuracy improvement on Mini-Kinetics and Sth-Sth-V1 is over 1.6\%.
Bidirectional Cross-Modal Knowledge Exploration for Video Recognition with Pre-trained Vision-Language Models
Dec 31, 2022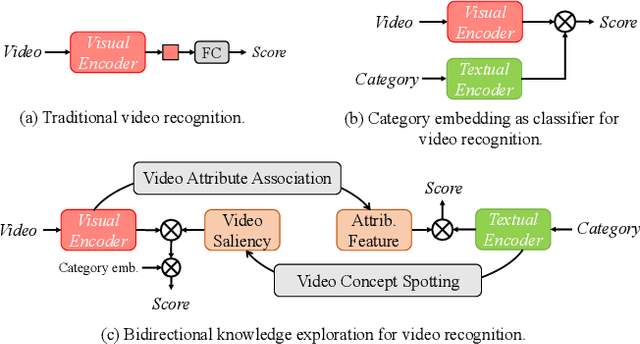
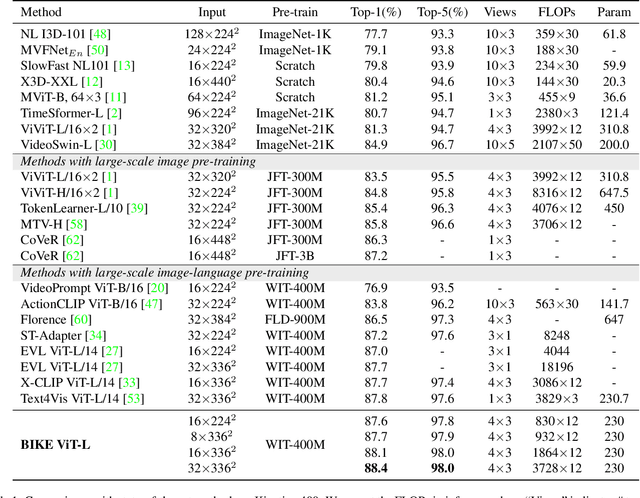
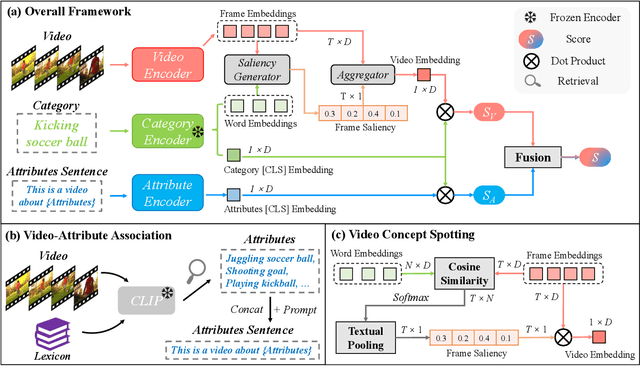
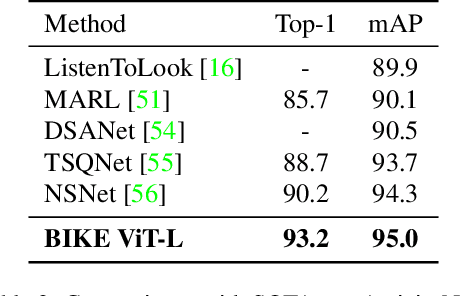
Vision-language models (VLMs) that are pre-trained on large-scale image-text pairs have demonstrated impressive transferability on a wide range of visual tasks. Transferring knowledge from such powerful pre-trained VLMs is emerging as a promising direction for building effective video recognition models. However, the current exploration is still limited. In our opinion, the greatest charm of pre-trained vision-language models is to build a bridge between visual and textual domains. In this paper, we present a novel framework called BIKE which utilizes the cross-modal bridge to explore bidirectional knowledge: i) We propose a Video Attribute Association mechanism which leverages the Video-to-Text knowledge to generate textual auxiliary attributes to complement video recognition. ii) We also present a Temporal Concept Spotting mechanism which uses the Text-to-Video expertise to capture temporal saliency in a parameter-free manner to yield enhanced video representation. The extensive studies on popular video datasets (ie, Kinetics-400 & 600, UCF-101, HMDB-51 and ActivityNet) show that our method achieves state-of-the-art performance in most recognition scenarios, eg, general, zero-shot, and few-shot video recognition. To the best of our knowledge, our best model achieves a state-of-the-art accuracy of 88.4% on challenging Kinetics-400 with the released CLIP pre-trained model.
Cross-Domain Ensemble Distillation for Domain Generalization
Nov 25, 2022Domain generalization is the task of learning models that generalize to unseen target domains. We propose a simple yet effective method for domain generalization, named cross-domain ensemble distillation (XDED), that learns domain-invariant features while encouraging the model to converge to flat minima, which recently turned out to be a sufficient condition for domain generalization. To this end, our method generates an ensemble of the output logits from training data with the same label but from different domains and then penalizes each output for the mismatch with the ensemble. Also, we present a de-stylization technique that standardizes features to encourage the model to produce style-consistent predictions even in an arbitrary target domain. Our method greatly improves generalization capability in public benchmarks for cross-domain image classification, cross-dataset person re-ID, and cross-dataset semantic segmentation. Moreover, we show that models learned by our method are robust against adversarial attacks and image corruptions.
ShadowNeuS: Neural SDF Reconstruction by Shadow Ray Supervision
Nov 25, 2022

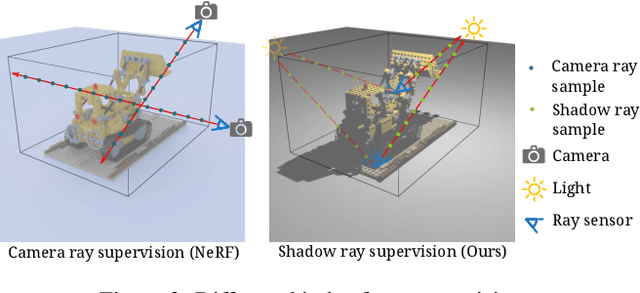

By supervising camera rays between a scene and multi-view image planes, NeRF reconstructs a neural scene representation for the task of novel view synthesis. On the other hand, shadow rays between the light source and the scene have yet to be considered. Therefore, we propose a novel shadow ray supervision scheme that optimizes both the samples along the ray and the ray location. By supervising shadow rays, we successfully reconstruct a neural SDF of the scene from single-view pure shadow or RGB images under multiple lighting conditions. Given single-view binary shadows, we train a neural network to reconstruct a complete scene not limited by the camera's line of sight. By further modeling the correlation between the image colors and the shadow rays, our technique can also be effectively extended to RGB inputs. We compare our method with previous works on challenging tasks of shape reconstruction from single-view binary shadow or RGB images and observe significant improvements. The code and data will be released.
GOOD: Exploring Geometric Cues for Detecting Objects in an Open World
Dec 24, 2022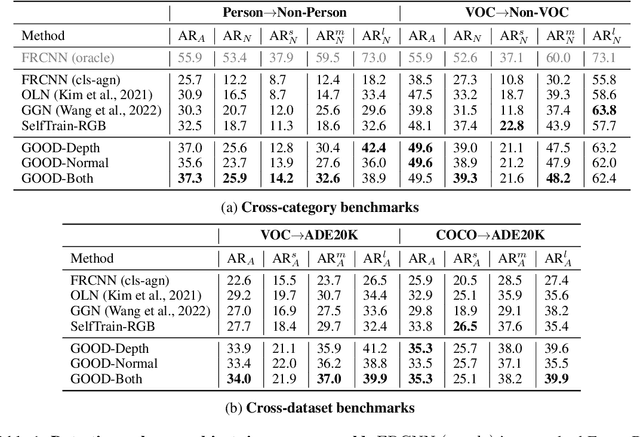

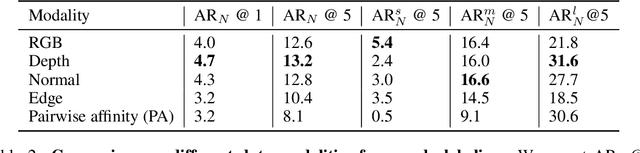
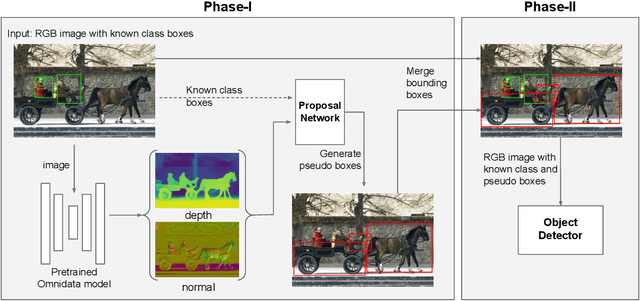
We address the task of open-world class-agnostic object detection, i.e., detecting every object in an image by learning from a limited number of base object classes. State-of-the-art RGB-based models suffer from overfitting the training classes and often fail at detecting novel-looking objects. This is because RGB-based models primarily rely on appearance similarity to detect novel objects and are also prone to overfitting short-cut cues such as textures and discriminative parts. To address these shortcomings of RGB-based object detectors, we propose incorporating geometric cues such as depth and normals, predicted by general-purpose monocular estimators. Specifically, we use the geometric cues to train an object proposal network for pseudo-labeling unannotated novel objects in the training set. Our resulting Geometry-guided Open-world Object Detector (GOOD) significantly improves detection recall for novel object categories and already performs well with only a few training classes. Using a single "person" class for training on the COCO dataset, GOOD surpasses SOTA methods by 5.0% AR@100, a relative improvement of 24%.
Artificial Pupil Dilation for Data Augmentation in Iris Semantic Segmentation
Dec 24, 2022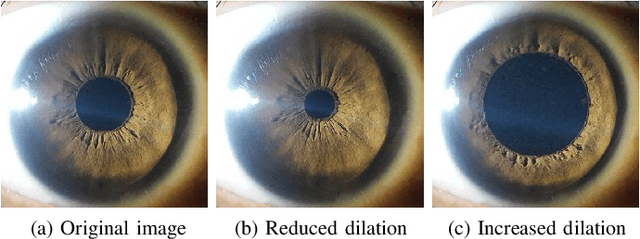

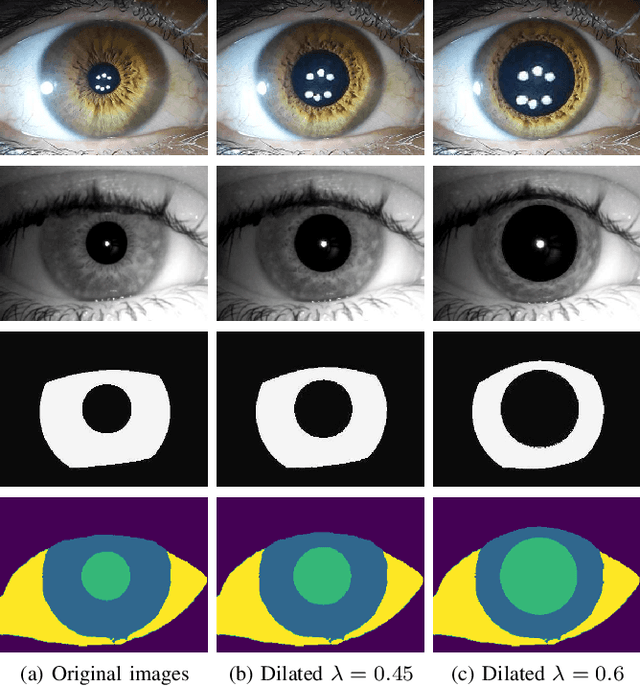
Biometrics is the science of identifying an individual based on their intrinsic anatomical or behavioural characteristics, such as fingerprints, face, iris, gait, and voice. Iris recognition is one of the most successful methods because it exploits the rich texture of the human iris, which is unique even for twins and does not degrade with age. Modern approaches to iris recognition utilize deep learning to segment the valid portion of the iris from the rest of the eye, so it can then be encoded, stored and compared. This paper aims to improve the accuracy of iris semantic segmentation systems by introducing a novel data augmentation technique. Our method can transform an iris image with a certain dilation level into any desired dilation level, thus augmenting the variability and number of training examples from a small dataset. The proposed method is fast and does not require training. The results indicate that our data augmentation method can improve segmentation accuracy up to 15% for images with high pupil dilation, which creates a more reliable iris recognition pipeline, even under extreme dilation.
* 6 pages, 7 figures, 2 tables
Bayesian posterior approximation with stochastic ensembles
Dec 15, 2022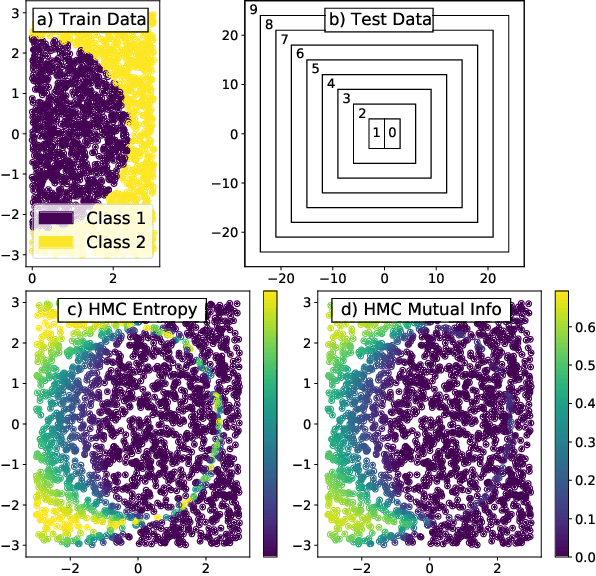
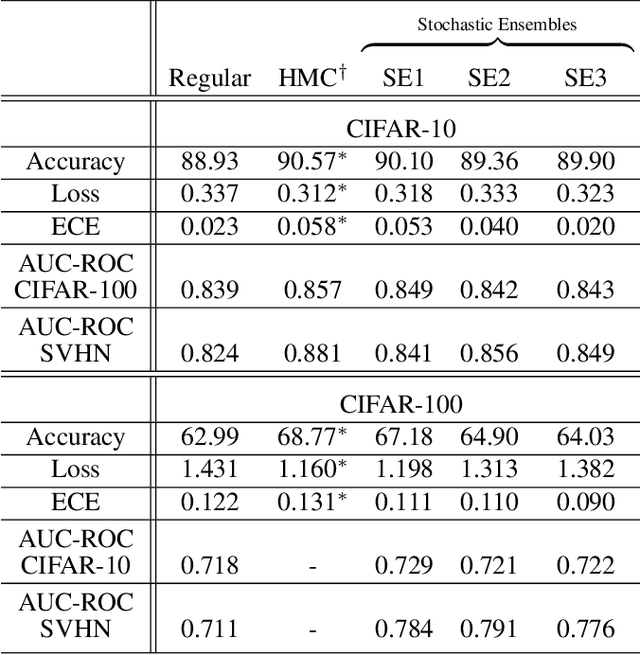
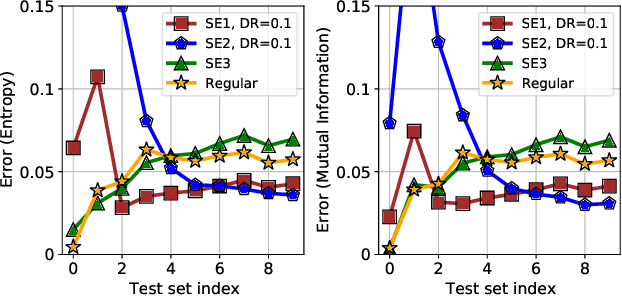
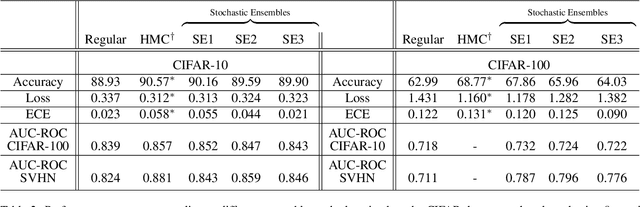
We introduce ensembles of stochastic neural networks to approximate the Bayesian posterior, combining stochastic methods such as dropout with deep ensembles. The stochastic ensembles are formulated as families of distributions and trained to approximate the Bayesian posterior with variational inference. We implement stochastic ensembles based on Monte Carlo dropout, DropConnect and a novel non-parametric version of dropout and evaluate them on a toy problem and CIFAR image classification. For CIFAR, the stochastic ensembles are quantitatively compared to published Hamiltonian Monte Carlo results for a ResNet-20 architecture. We also test the quality of the posteriors directly against Hamiltonian Monte Carlo simulations in a simplified toy model. Our results show that in a number of settings, stochastic ensembles provide more accurate posterior estimates than regular deep ensembles.
Learn2Trust: A video and streamlit-based educational programme for AI-based medical image analysis targeted towards medical students
Aug 15, 2022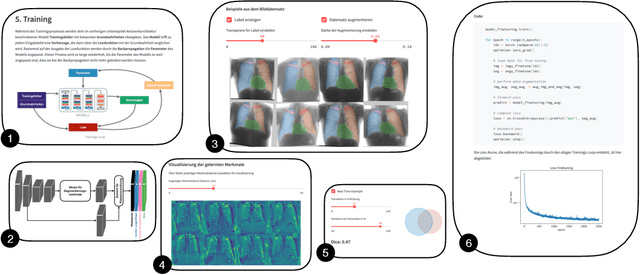
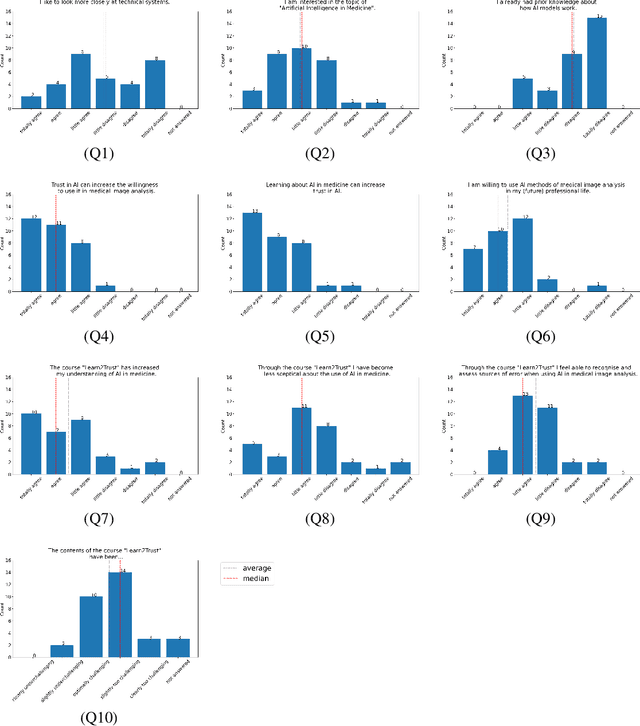
In order to be able to use artificial intelligence (AI) in medicine without scepticism and to recognise and assess its growing potential, a basic understanding of this topic is necessary among current and future medical staff. Under the premise of "trust through understanding", we developed an innovative online course as a learning opportunity within the framework of the German KI Campus (AI campus) project, which is a self-guided course that teaches the basics of AI for the analysis of medical image data. The main goal is to provide a learning environment for a sufficient understanding of AI in medical image analysis so that further interest in this topic is stimulated and inhibitions towards its use can be overcome by means of positive application experience. The focus was on medical applications and the fundamentals of machine learning. The online course was divided into consecutive lessons, which include theory in the form of explanatory videos, practical exercises in the form of Streamlit and practical exercises and/or quizzes to check learning progress. A survey among the participating medical students in the first run of the course was used to analyse our research hypotheses quantitatively.
Clustering as Attention: Unified Image Segmentation with Hierarchical Clustering
May 20, 2022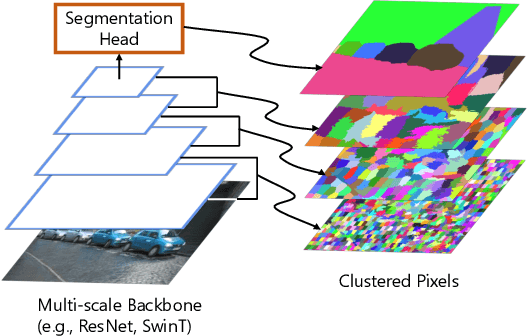
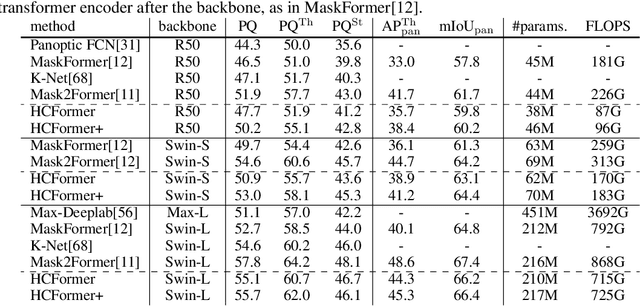
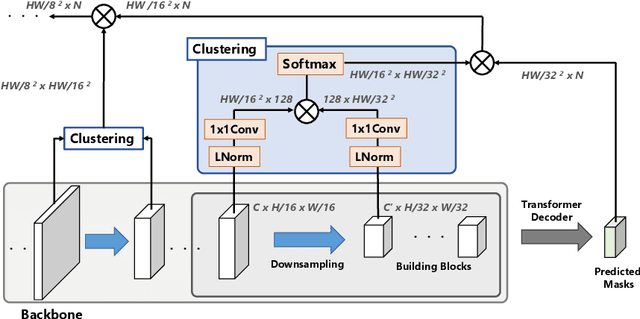
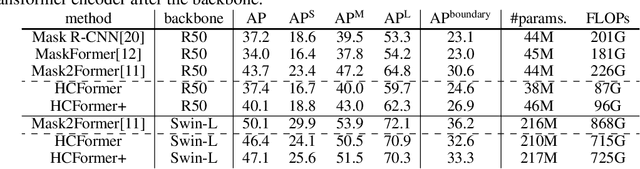
We propose a hierarchical clustering-based image segmentation scheme for deep neural networks, called HCFormer. We interpret image segmentation, including semantic, instance, and panoptic segmentation, as a pixel clustering problem, and accomplish it by bottom-up, hierarchical clustering with deep neural networks. Our hierarchical clustering removes the pixel decoder from conventional segmentation models and simplifies the segmentation pipeline, resulting in improved segmentation accuracies and interpretability. HCFormer can address semantic, instance, and panoptic segmentation with the same architecture because the pixel clustering is a common approach for various image segmentation. In experiments, HCFormer achieves comparable or superior segmentation accuracies compared to baseline methods on semantic segmentation (55.5 mIoU on ADE20K), instance segmentation (47.1 AP on COCO), and panoptic segmentation (55.7 PQ on COCO).