 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ActiveLab: Active Learning with Re-Labeling by Multiple Annotators
Jan 27, 2023
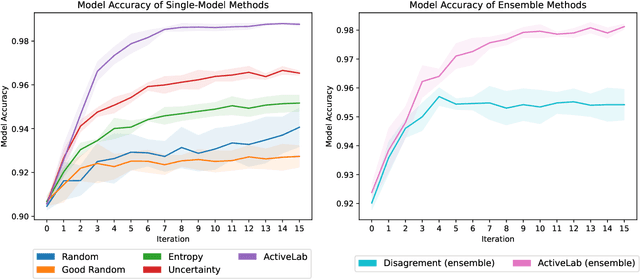
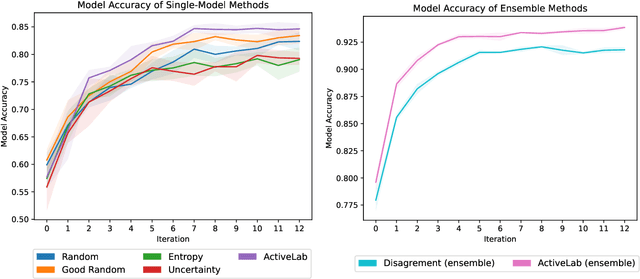
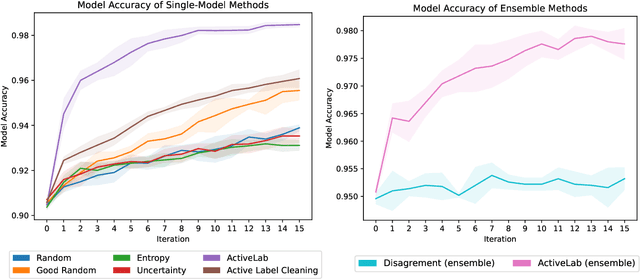
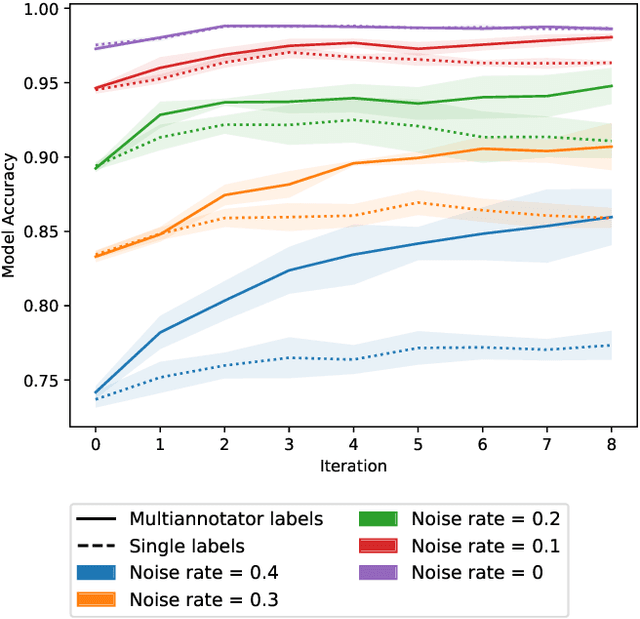
In real-world data labeling applications, annotators often provide imperfect labels. It is thus common to employ multiple annotators to label data with some overlap between their examples. We study active learning in such settings, aiming to train an accurate classifier by collecting a dataset with the fewest total annotations. Here we propose ActiveLab, a practical method to decide what to label next that works with any classifier model and can be used in pool-based batch active learning with one or multiple annotators. ActiveLab automatically estimates when it is more informative to re-label examples vs. labeling entirely new ones. This is a key aspect of producing high quality labels and trained models within a limited annotation budget. In experiments on image and tabular data, ActiveLab reliably trains more accurate classifiers with far fewer annotations than a wide variety of popular active learning methods.
Unsupervised Misaligned Infrared and Visible Image Fusion via Cross-Modality Image Generation and Registration
May 24, 2022
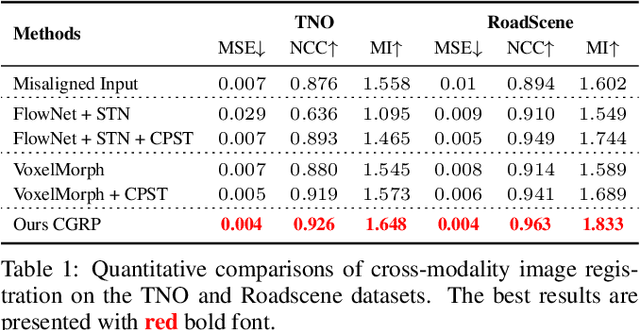
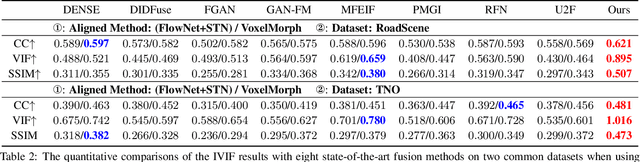

Recent learning-based image fusion methods have marked numerous progress in pre-registered multi-modality data, but suffered serious ghosts dealing with misaligned multi-modality data, due to the spatial deformation and the difficulty narrowing cross-modality discrepancy. To overcome the obstacles, in this paper, we present a robust cross-modality generation-registration paradigm for unsupervised misaligned infrared and visible image fusion (IVIF). Specifically, we propose a Cross-modality Perceptual Style Transfer Network (CPSTN) to generate a pseudo infrared image taking a visible image as input. Benefiting from the favorable geometry preservation ability of the CPSTN, the generated pseudo infrared image embraces a sharp structure, which is more conducive to transforming cross-modality image alignment into mono-modality registration coupled with the structure-sensitive of the infrared image. In this case, we introduce a Multi-level Refinement Registration Network (MRRN) to predict the displacement vector field between distorted and pseudo infrared images and reconstruct registered infrared image under the mono-modality setting. Moreover, to better fuse the registered infrared images and visible images, we present a feature Interaction Fusion Module (IFM) to adaptively select more meaningful features for fusion in the Dual-path Interaction Fusion Network (DIFN). Extensive experimental results suggest that the proposed method performs superior capability on misaligned cross-modality image fusion.
GDB: Gated convolutions-based Document Binarization
Feb 04, 2023
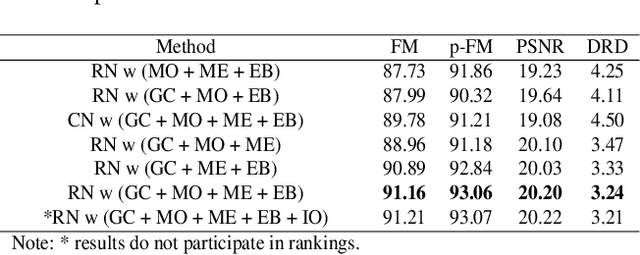
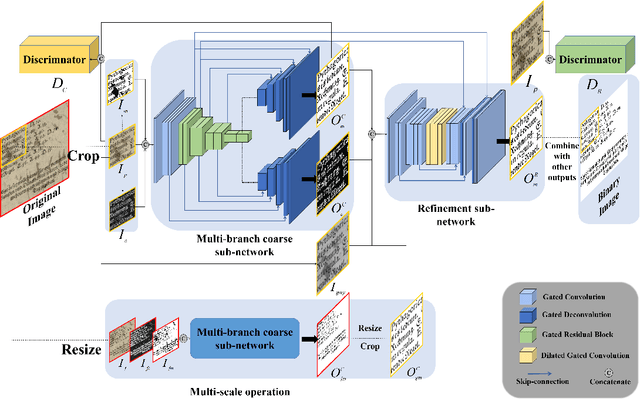
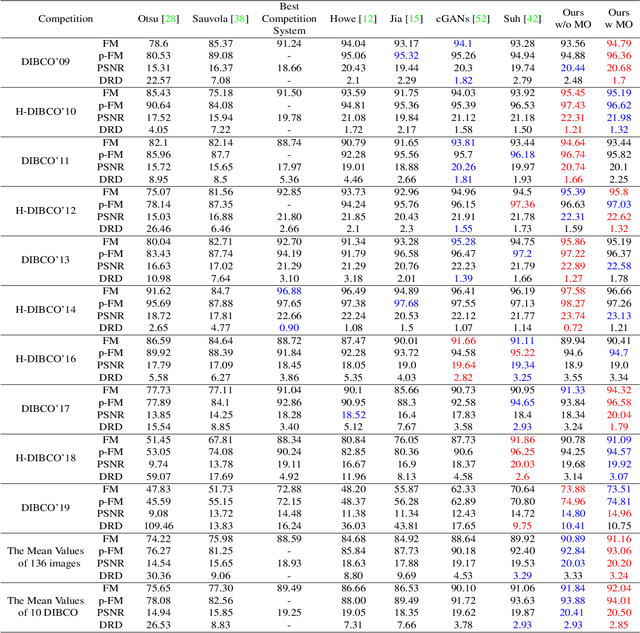
Document binarization is a key pre-processing step for many document analysis tasks. However, existing methods can not extract stroke edges finely, mainly due to the fair-treatment nature of vanilla convolutions and the extraction of stroke edges without adequate supervision by boundary-related information. In this paper, we formulate text extraction as the learning of gating values and propose an end-to-end gated convolutions-based network (GDB) to solve the problem of imprecise stroke edge extraction. The gated convolutions are applied to selectively extract the features of strokes with different attention. Our proposed framework consists of two stages. Firstly, a coarse sub-network with an extra edge branch is trained to get more precise feature maps by feeding a priori mask and edge. Secondly, a refinement sub-network is cascaded to refine the output of the first stage by gated convolutions based on the sharp edge. For global information, GDB also contains a multi-scale operation to combine local and global features. We conduct comprehensive experiments on ten Document Image Binarization Contest (DIBCO) datasets from 2009 to 2019. Experimental results show that our proposed methods outperform the state-of-the-art methods in terms of all metrics on average and achieve top ranking on six benchmark datasets.
High Dynamic Range and Super-Resolution from Raw Image Bursts
Jul 29, 2022
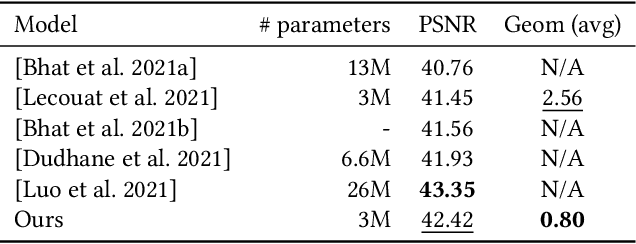
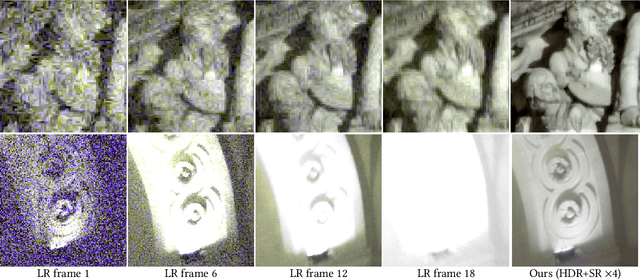
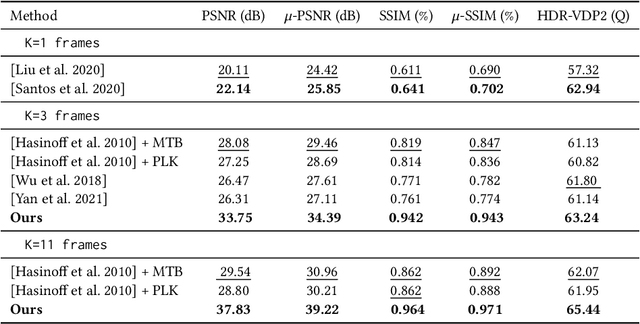
Photographs captured by smartphones and mid-range cameras have limited spatial resolution and dynamic range, with noisy response in underexposed regions and color artefacts in saturated areas. This paper introduces the first approach (to the best of our knowledge) to the reconstruction of high-resolution, high-dynamic range color images from raw photographic bursts captured by a handheld camera with exposure bracketing. This method uses a physically-accurate model of image formation to combine an iterative optimization algorithm for solving the corresponding inverse problem with a learned image representation for robust alignment and a learned natural image prior. The proposed algorithm is fast, with low memory requirements compared to state-of-the-art learning-based approaches to image restoration, and features that are learned end to end from synthetic yet realistic data. Extensive experiments demonstrate its excellent performance with super-resolution factors of up to $\times 4$ on real photographs taken in the wild with hand-held cameras, and high robustness to low-light conditions, noise, camera shake, and moderate object motion.
Towards Layer-wise Image Vectorization
Jun 09, 2022
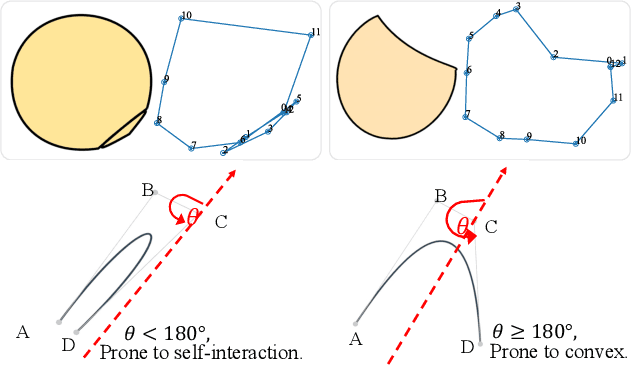


Image rasterization is a mature technique in computer graphics, while image vectorization, the reverse path of rasterization, remains a major challenge. Recent advanced deep learning-based models achieve vectorization and semantic interpolation of vector graphs and demonstrate a better topology of generating new figures. However, deep models cannot be easily generalized to out-of-domain testing data. The generated SVGs also contain complex and redundant shapes that are not quite convenient for further editing. Specifically, the crucial layer-wise topology and fundamental semantics in images are still not well understood and thus not fully explored. In this work, we propose Layer-wise Image Vectorization, namely LIVE, to convert raster images to SVGs and simultaneously maintain its image topology. LIVE can generate compact SVG forms with layer-wise structures that are semantically consistent with human perspective. We progressively add new bezier paths and optimize these paths with the layer-wise framework, newly designed loss functions, and component-wise path initialization technique. Our experiments demonstrate that LIVE presents more plausible vectorized forms than prior works and can be generalized to new images. With the help of this newly learned topology, LIVE initiates human editable SVGs for both designers and other downstream applications. Codes are made available at https://github.com/Picsart-AI-Research/LIVE-Layerwise-Image-Vectorization.
The Biased Artist: Exploiting Cultural Biases via Homoglyphs in Text-Guided Image Generation Models
Sep 19, 2022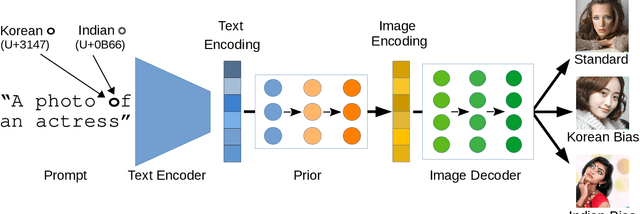



Text-guided image generation models, such as DALL-E 2 and Stable Diffusion, have recently received much attention from academia and the general public. Provided with textual descriptions, these models are capable of generating high-quality images depicting various concepts and styles. However, such models are trained on large amounts of public data and implicitly learn relationships from their training data that are not immediately apparent. We demonstrate that common multimodal models implicitly learned cultural biases that can be triggered and injected into the generated images by simply replacing single characters in the textual description with visually similar non-Latin characters. These so-called homoglyph replacements enable malicious users or service providers to induce biases into the generated images and even render the whole generation process useless. We practically illustrate such attacks on DALL-E 2 and Stable Diffusion as text-guided image generation models and further show that CLIP also behaves similarly. Our results further indicate that text encoders trained on multilingual data provide a way to mitigate the effects of homoglyph replacements.
Unsupervised Domain Adaptive Fundus Image Segmentation with Few Labeled Source Data
Oct 10, 2022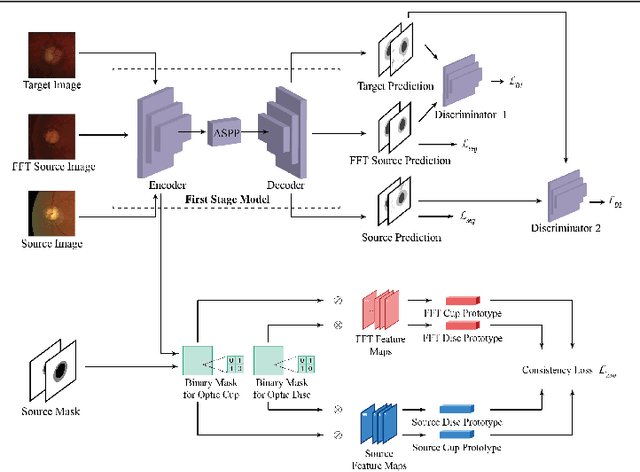
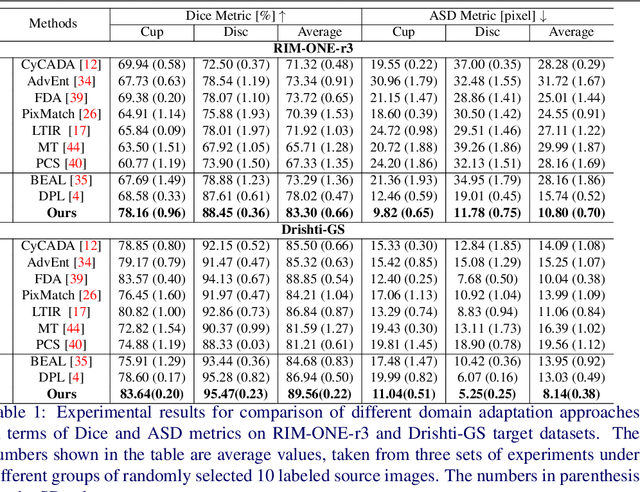
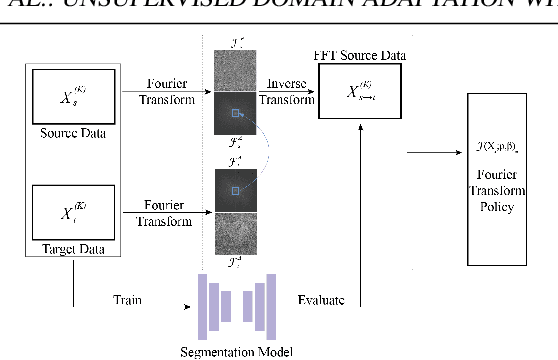
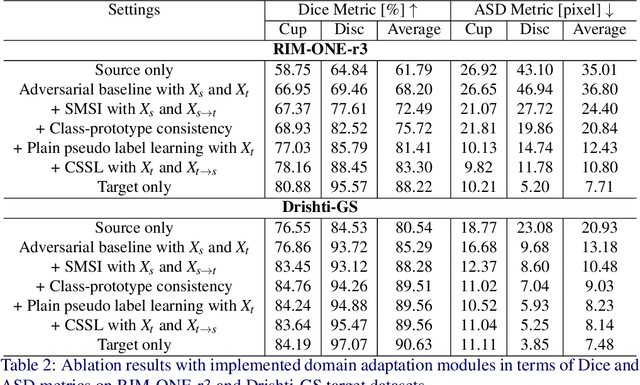
Deep learning-based segmentation methods have been widely employed for automatic glaucoma diagnosis and prognosis. In practice, fundus images obtained by different fundus cameras vary significantly in terms of illumination and intensity. Although recent unsupervised domain adaptation (UDA) methods enhance the models' generalization ability on the unlabeled target fundus datasets, they always require sufficient labeled data from the source domain, bringing auxiliary data acquisition and annotation costs. To further facilitate the data efficiency of the cross-domain segmentation methods on the fundus images, we explore UDA optic disc and cup segmentation problems using few labeled source data in this work. We first design a Searching-based Multi-style Invariant Mechanism to diversify the source data style as well as increase the data amount. Next, a prototype consistency mechanism on the foreground objects is proposed to facilitate the feature alignment for each kind of tissue under different image styles. Moreover, a cross-style self-supervised learning stage is further designed to improve the segmentation performance on the target images. Our method has outperformed several state-of-the-art UDA segmentation methods under the UDA fundus segmentation with few labeled source data.
Application of Unsupervised Domain Adaptation for Structural MRI Analysis
Dec 26, 2022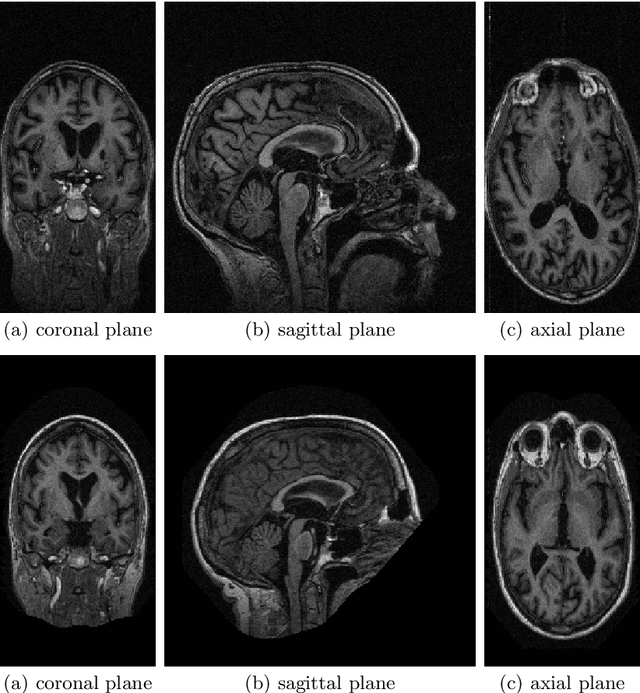
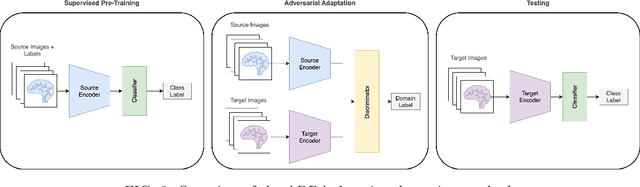
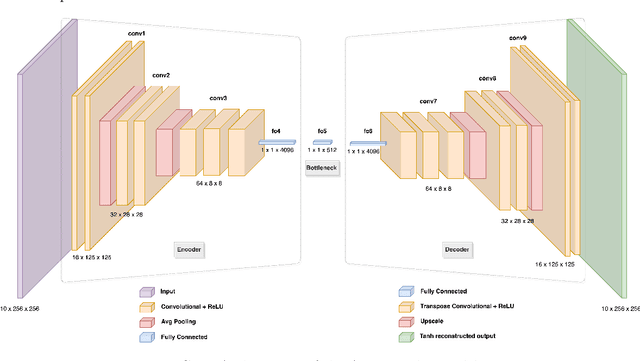
The primary goal of this work is to study the effectiveness of an unsupervised domain adaptation approach for various applications such as binary classification and anomaly detection in the context of Alzheimer's disease (AD) detection for the OASIS datasets. We also explore image reconstruction and image synthesis for analyzing and generating 3D structural MRI data to establish performance benchmarks for anomaly detection. We successfully demonstrate that domain adaptation improves the performance of AD detection when implemented in both supervised and unsupervised settings. Additionally, the proposed methodology achieves state-of-the-art performance for binary classification on the OASIS-1 dataset.
A Topological Loss Function for Low-Light Image Denoising
Aug 18, 2022
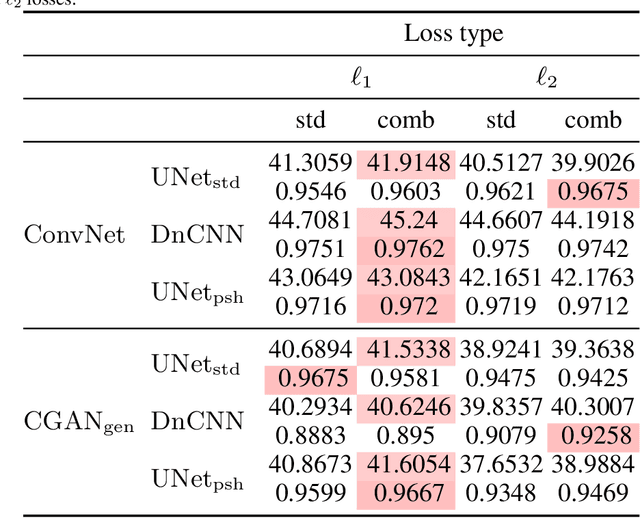

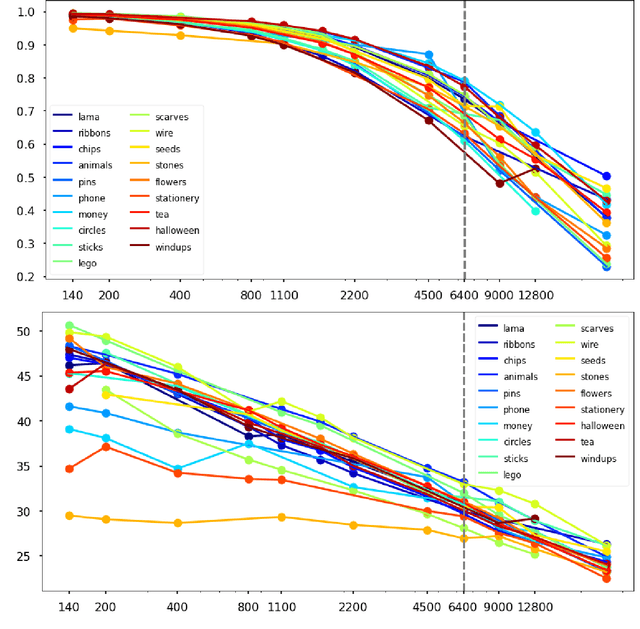
Although image denoising algorithms have attracted significant research attention, surprisingly few have been proposed for, or evaluated on, noise from imagery acquired under real low-light conditions. Moreover, noise characteristics are often assumed to be spatially invariant, leading to edges and textures being distorted after denoising. Here, we introduce a novel topological loss function which is based on persistent homology, offering true features with resistance to noise across multiple scales. The method performs in the space of image patches, where topological invariants are calculated and represented in persistent diagrams. The loss function is a combination of $\ell_1$ or $\ell_2$ losses with the new persistence-based topological loss. We compare its performance across popular denoising architectures, training the networks on our new comprehensive dataset of natural images captured in low-light conditions -- BVI-LOWLIGHT. Analysis reveals that this approach outperforms existing methods, adapting well to edges and complex structures and suppressing common artifacts.
Task-specific Scene Structure Representations
Jan 02, 2023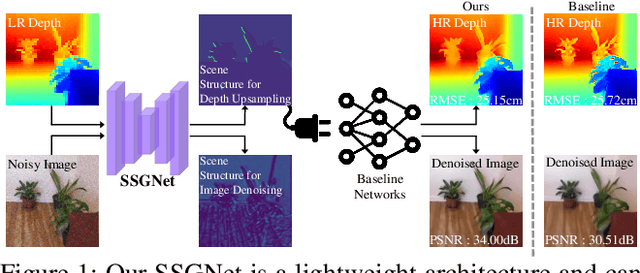
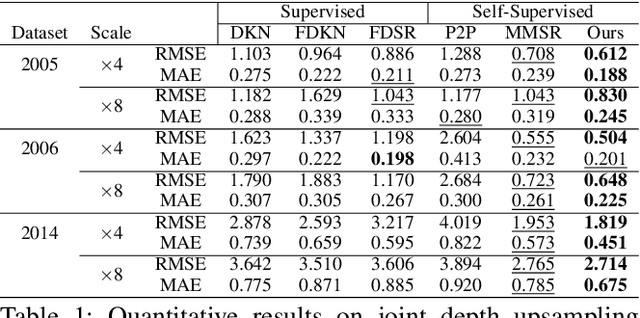
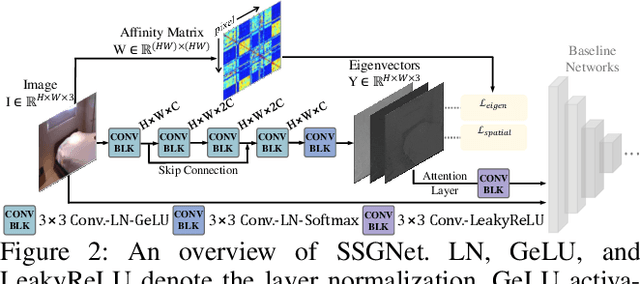
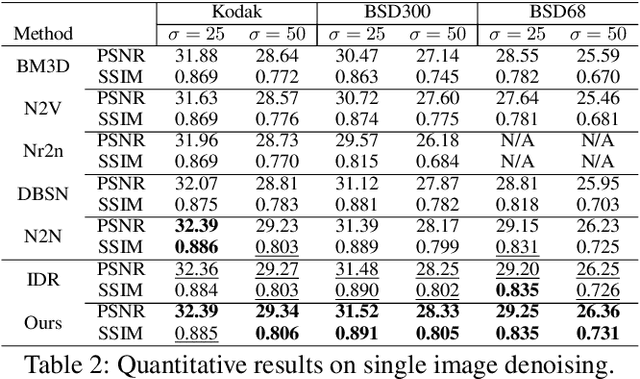
Understanding the informative structures of scenes is essential for low-level vision tasks. Unfortunately, it is difficult to obtain a concrete visual definition of the informative structures because influences of visual features are task-specific. In this paper, we propose a single general neural network architecture for extracting task-specific structure guidance for scenes. To do this, we first analyze traditional spectral clustering methods, which computes a set of eigenvectors to model a segmented graph forming small compact structures on image domains. We then unfold the traditional graph-partitioning problem into a learnable network, named \textit{Scene Structure Guidance Network (SSGNet)}, to represent the task-specific informative structures. The SSGNet yields a set of coefficients of eigenvectors that produces explicit feature representations of image structures. In addition, our SSGNet is light-weight ($\sim$ 55K parameters), and can be used as a plug-and-play module for off-the-shelf architectures. We optimize the SSGNet without any supervision by proposing two novel training losses that enforce task-specific scene structure generation during training. Our main contribution is to show that such a simple network can achieve state-of-the-art results for several low-level vision applications including joint upsampling and image denoising. We also demonstrate that our SSGNet generalizes well on unseen datasets, compared to existing methods which use structural embedding frameworks. Our source codes are available at https://github.com/jsshin98/SSGNet.