 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Survey of Geometric Optimization for Deep Learning: From Euclidean Space to Riemannian Manifold
Feb 16, 2023
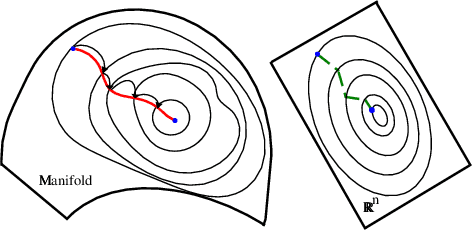
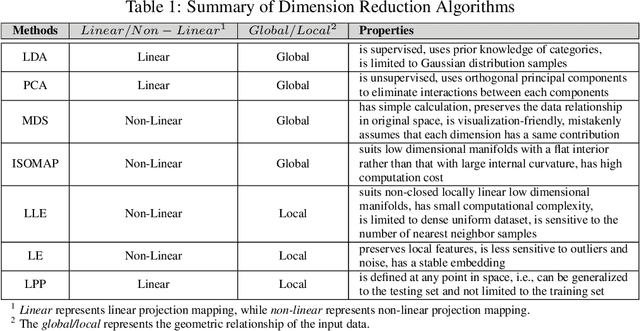
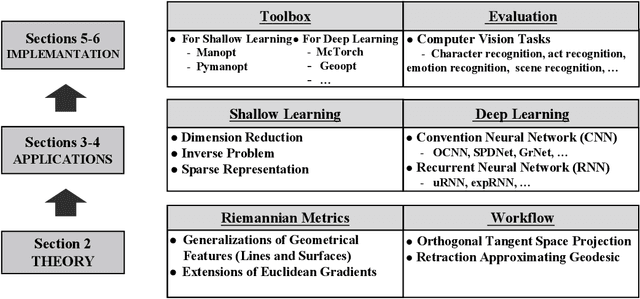
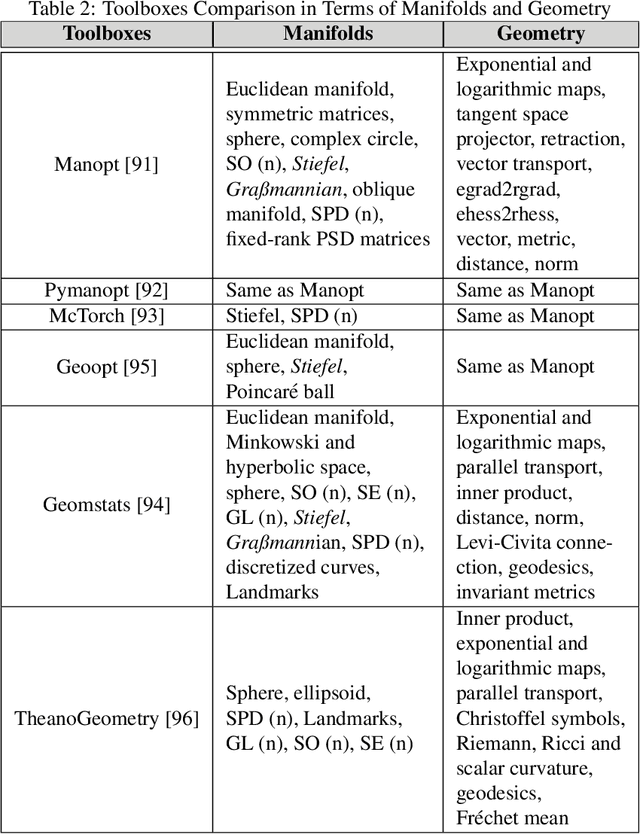
Although Deep Learning (DL) has achieved success in complex Artificial Intelligence (AI) tasks, it suffers from various notorious problems (e.g., feature redundancy, and vanishing or exploding gradients), since updating parameters in Euclidean space cannot fully exploit the geometric structure of the solution space. As a promising alternative solution, Riemannian-based DL uses geometric optimization to update parameters on Riemannian manifolds and can leverage the underlying geometric information. Accordingly, this article presents a comprehensive survey of applying geometric optimization in DL. At first, this article introduces the basic procedure of the geometric optimization, including various geometric optimizers and some concepts of Riemannian manifold. Subsequently, this article investigates the application of geometric optimization in different DL networks in various AI tasks, e.g., convolution neural network, recurrent neural network, transfer learning, and optimal transport. Additionally, typical public toolboxes that implement optimization on manifold are also discussed. Finally, this article makes a performance comparison between different deep geometric optimization methods under image recognition scenarios.
WISE: Whitebox Image Stylization by Example-based Learning
Jul 29, 2022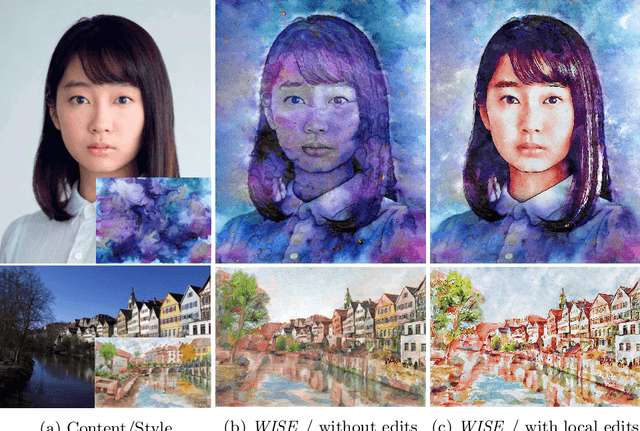
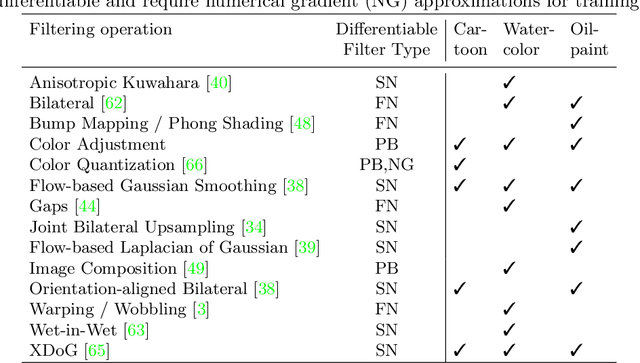
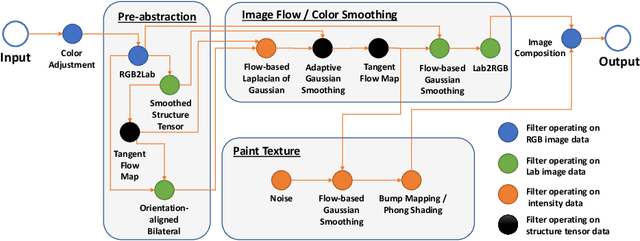
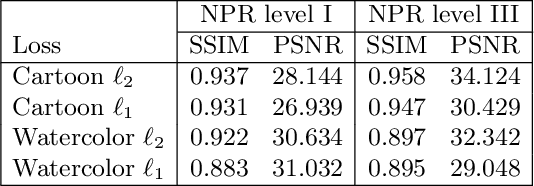
Image-based artistic rendering can synthesize a variety of expressive styles using algorithmic image filtering. In contrast to deep learning-based methods, these heuristics-based filtering techniques can operate on high-resolution images, are interpretable, and can be parameterized according to various design aspects. However, adapting or extending these techniques to produce new styles is often a tedious and error-prone task that requires expert knowledge. We propose a new paradigm to alleviate this problem: implementing algorithmic image filtering techniques as differentiable operations that can learn parametrizations aligned to certain reference styles. To this end, we present WISE, an example-based image-processing system that can handle a multitude of stylization techniques, such as watercolor, oil or cartoon stylization, within a common framework. By training parameter prediction networks for global and local filter parameterizations, we can simultaneously adapt effects to reference styles and image content, e.g., to enhance facial features. Our method can be optimized in a style-transfer framework or learned in a generative-adversarial setting for image-to-image translation. We demonstrate that jointly training an XDoG filter and a CNN for postprocessing can achieve comparable results to a state-of-the-art GAN-based method.
IDAN: Image Difference Attention Network for Change Detection
Aug 17, 2022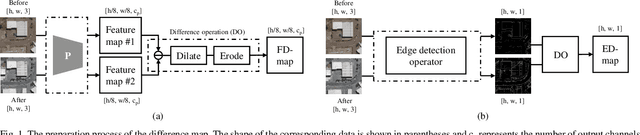
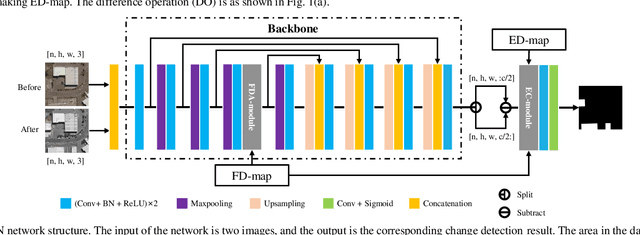
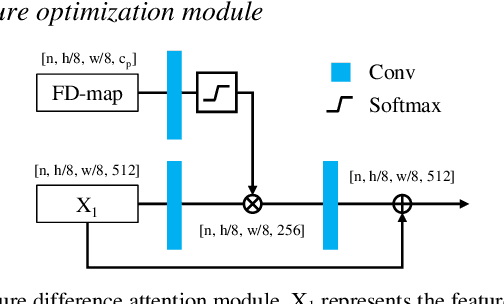
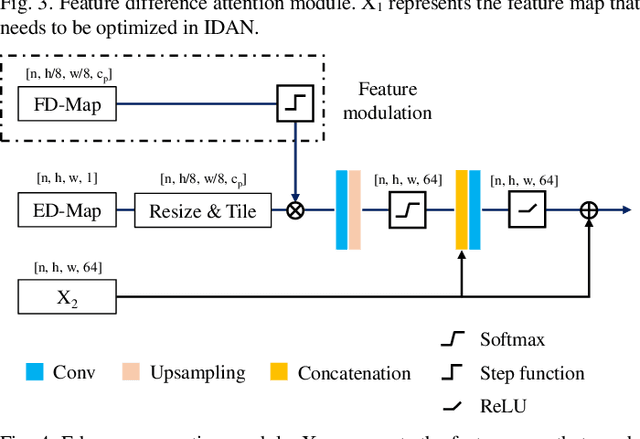
Remote sensing image change detection is of great importance in disaster assessment and urban planning. The mainstream method is to use encoder-decoder models to detect the change region of two input images. Since the change content of remote sensing images has the characteristics of wide scale range and variety, it is necessary to improve the detection accuracy of the network by increasing the attention mechanism, which commonly includes: Squeeze-and-Excitation block, Non-local and Convolutional Block Attention Module, among others. These methods consider the importance of different location features between channels or within channels, but fail to perceive the differences between input images. In this paper, we propose a novel image difference attention network (IDAN). In the image preprocessing stage, we use a pre-training model to extract the feature differences between two input images to obtain the feature difference map (FD-map), and Canny for edge detection to obtain the edge difference map (ED-map). In the image feature extracting stage, the FD-map and ED-map are input to the feature difference attention module and edge compensation module, respectively, to optimize the features extracted by IDAN. Finally, the change detection result is obtained through the feature difference operation. IDAN comprehensively considers the differences in regional and edge features of images and thus optimizes the extracted image features. The experimental results demonstrate that the F1-score of IDAN improves 1.62% and 1.98% compared to the baseline model on WHU dataset and LEVIR-CD dataset, respectively.
FusionVAE: A Deep Hierarchical Variational Autoencoder for RGB Image Fusion
Sep 22, 2022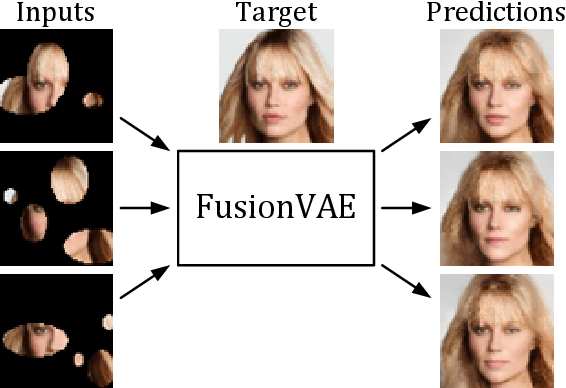
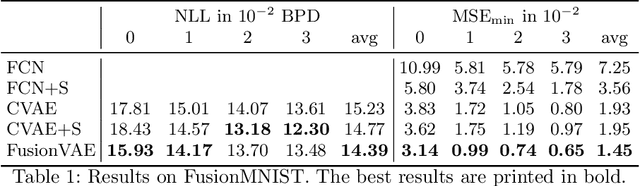
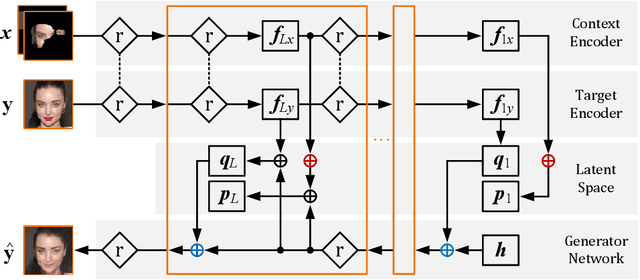
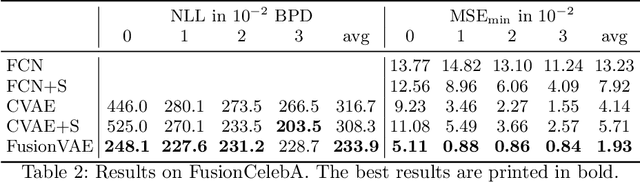
Sensor fusion can significantly improve the performance of many computer vision tasks. However, traditional fusion approaches are either not data-driven and cannot exploit prior knowledge nor find regularities in a given dataset or they are restricted to a single application. We overcome this shortcoming by presenting a novel deep hierarchical variational autoencoder called FusionVAE that can serve as a basis for many fusion tasks. Our approach is able to generate diverse image samples that are conditioned on multiple noisy, occluded, or only partially visible input images. We derive and optimize a variational lower bound for the conditional log-likelihood of FusionVAE. In order to assess the fusion capabilities of our model thoroughly, we created three novel datasets for image fusion based on popular computer vision datasets. In our experiments, we show that FusionVAE learns a representation of aggregated information that is relevant to fusion tasks. The results demonstrate that our approach outperforms traditional methods significantly. Furthermore, we present the advantages and disadvantages of different design choices.
Referential communication in heterogeneous communities of pre-trained visual deep networks
Feb 04, 2023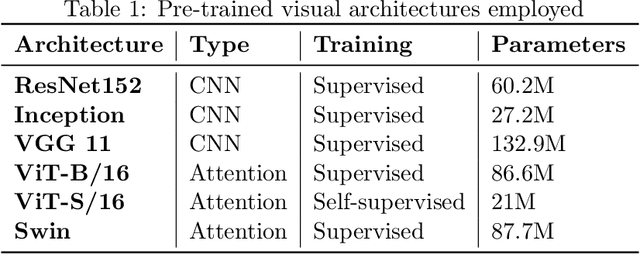
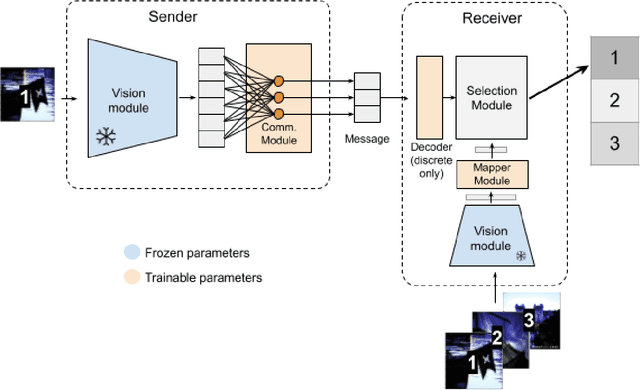

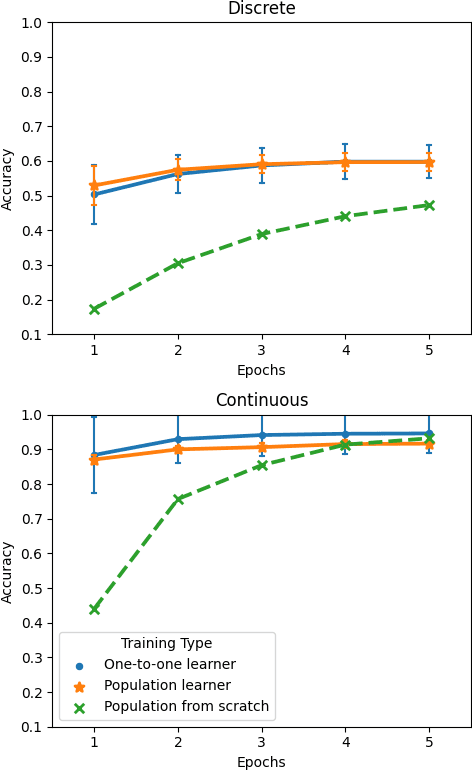
As large pre-trained image-processing neural networks are being embedded in autonomous agents such as self-driving cars or robots, the question arises of how such systems can communicate with each other about the surrounding world, despite their different architectures and training regimes. As a first step in this direction, we systematically explore the task of referential communication in a community of state-of-the-art pre-trained visual networks, showing that they can develop a shared protocol to refer to a target image among a set of candidates. Such shared protocol, induced in a self-supervised way, can to some extent be used to communicate about previously unseen object categories, as well as to make more granular distinctions compared to the categories taught to the original networks. Contradicting a common view in multi-agent emergent communication research, we find that imposing a discrete bottleneck on communication hampers the emergence of a general code. Moreover, we show that a new neural network can learn the shared protocol developed in a community with remarkable ease, and the process of integrating a new agent into a community more stably succeeds when the original community includes a larger set of heterogeneous networks. Finally, we illustrate the independent benefits of developing a shared communication layer by using it to directly transfer an object classifier from a network to another, and we qualitatively and quantitatively study its emergent properties.
Unsupervised visualization of image datasets using contrastive learning
Oct 18, 2022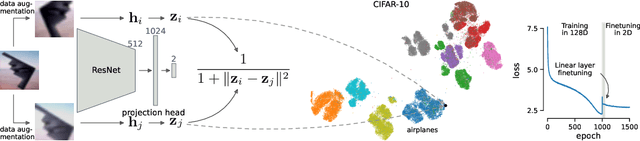
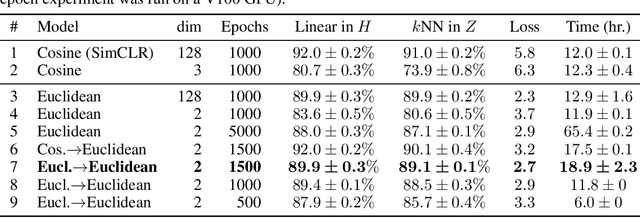
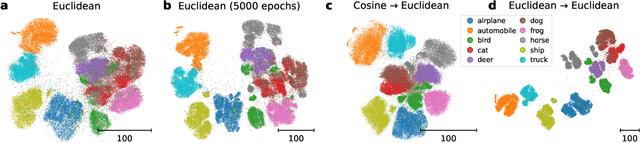
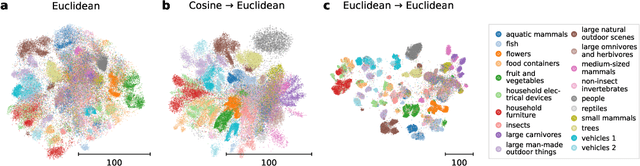
Visualization methods based on the nearest neighbor graph, such as t-SNE or UMAP, are widely used for visualizing high-dimensional data. Yet, these approaches only produce meaningful results if the nearest neighbors themselves are meaningful. For images represented in pixel space this is not the case, as distances in pixel space are often not capturing our sense of similarity and therefore neighbors are not semantically close. This problem can be circumvented by self-supervised approaches based on contrastive learning, such as SimCLR, relying on data augmentation to generate implicit neighbors, but these methods do not produce two-dimensional embeddings suitable for visualization. Here, we present a new method, called t-SimCNE, for unsupervised visualization of image data. T-SimCNE combines ideas from contrastive learning and neighbor embeddings, and trains a parametric mapping from the high-dimensional pixel space into two dimensions. We show that the resulting 2D embeddings achieve classification accuracy comparable to the state-of-the-art high-dimensional SimCLR representations, thus faithfully capturing semantic relationships. Using t-SimCNE, we obtain informative visualizations of the CIFAR-10 and CIFAR-100 datasets, showing rich cluster structure and highlighting artifacts and outliers.
A Privacy Preserving Method with a Random Orthogonal Matrix for ConvMixer Models
Jan 17, 2023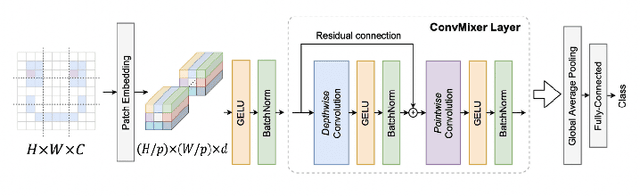

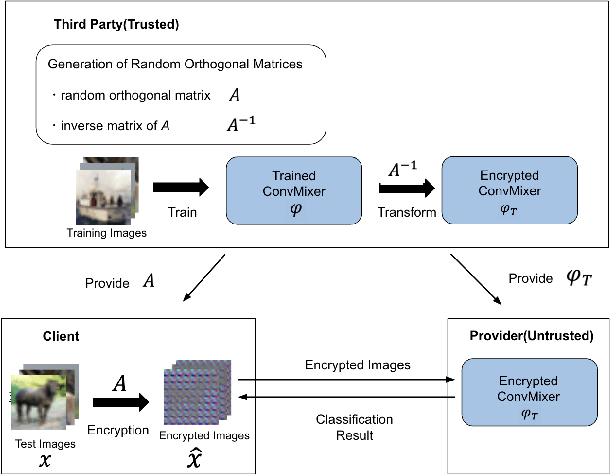
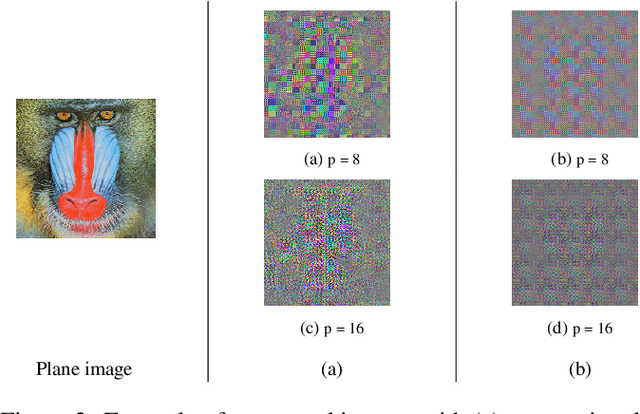
In this paper, a privacy preserving image classification method is proposed under the use of ConvMixer models. To protect the visual information of test images, a test image is divided into blocks, and then every block is encrypted by using a random orthogonal matrix. Moreover, a ConvMixer model trained with plain images is transformed by the random orthogonal matrix used for encrypting test images, on the basis of the embedding structure of ConvMixer. The proposed method allows us not only to use the same classification accuracy as that of ConvMixer models without considering privacy protection but to also enhance robustness against various attacks compared to conventional privacy-preserving learning.
A Vision-Based Algorithm for a Path Following Problem
Feb 09, 2023
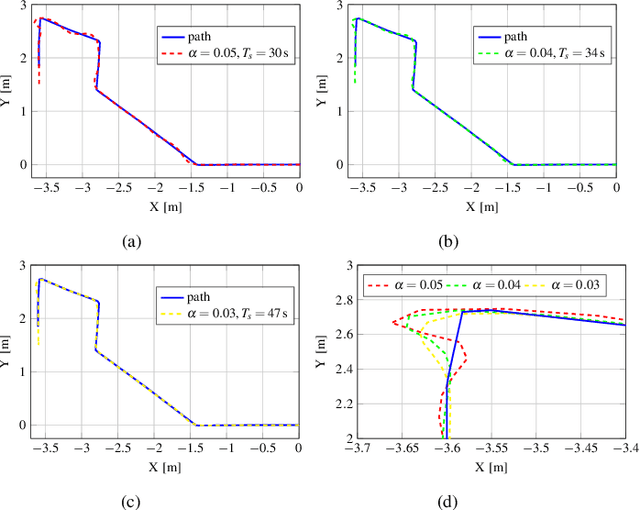
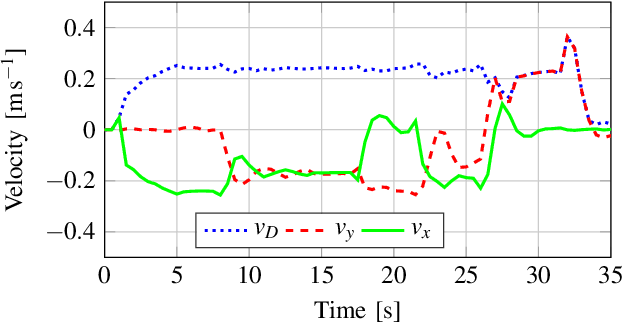
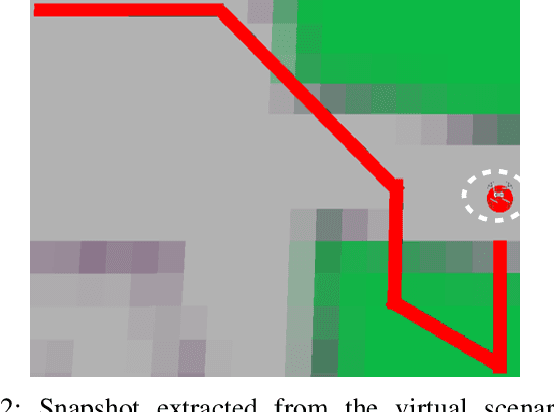
A novel prize-winner algorithm designed for a path following problem within the Unmanned Aerial Vehicle (UAV) field is presented in this paper. The proposed approach exploits the advantages offered by the pure pursuing algorithm to set up an intuitive and simple control framework. A path fora quad-rotor UAV is obtained by using downward facing camera images implementing an Image-Based Visual Servoing (IBVS) approach. Numerical simulations in MATLAB together with the MathWorks Virtual Reality (VR) toolbox demonstrate the validity and the effectiveness of the proposed solution. The code is released as open-source making it possible to go through any part of the system and to replicate the obtained results.
* 6 pages, 11 figures, conference
Raw or Cooked? Object Detection on RAW Images
Jan 21, 2023


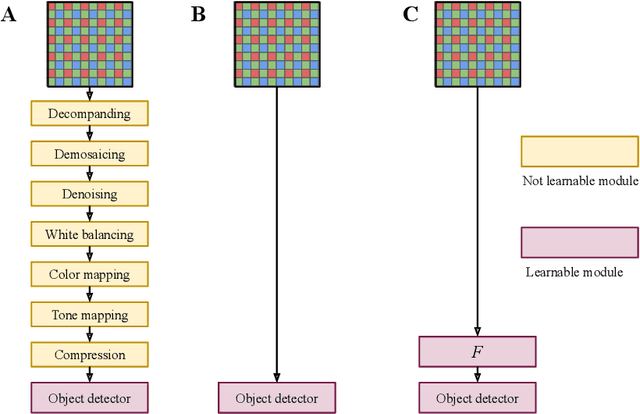
Images fed to a deep neural network have in general undergone several handcrafted image signal processing (ISP) operations, all of which have been optimized to produce visually pleasing images. In this work, we investigate the hypothesis that the intermediate representation of visually pleasing images is sub-optimal for downstream computer vision tasks compared to the RAW image representation. We suggest that the operations of the ISP instead should be optimized towards the end task, by learning the parameters of the operations jointly during training. We extend previous works on this topic and propose a new learnable operation that enables an object detector to achieve superior performance when compared to both previous works and traditional RGB images. In experiments on the open PASCALRAW dataset, we empirically confirm our hypothesis.
MaxGNR: A Dynamic Weight Strategy via Maximizing Gradient-to-Noise Ratio for Multi-Task Learning
Feb 18, 2023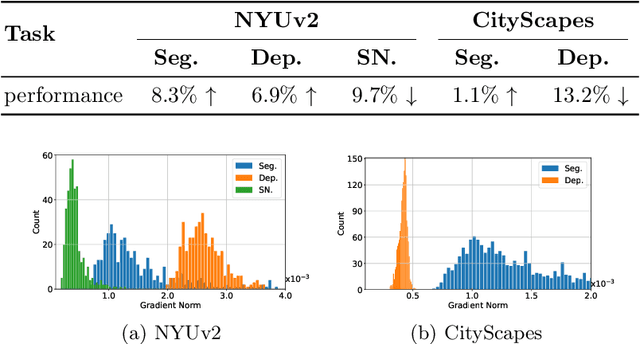
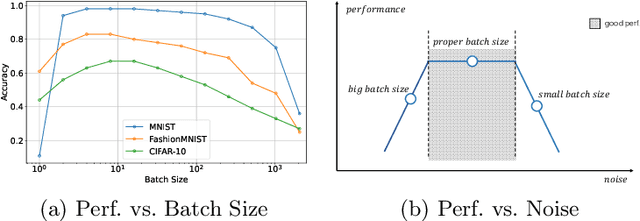
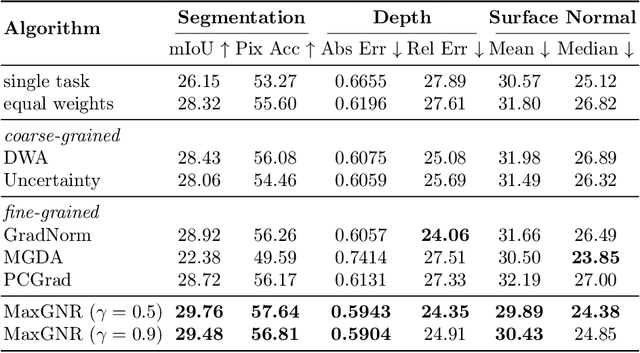
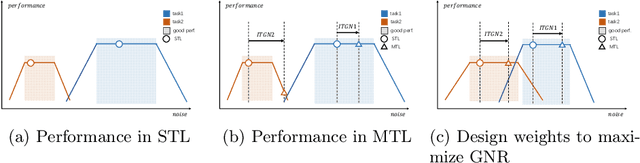
When modeling related tasks in computer vision, Multi-Task Learning (MTL) can outperform Single-Task Learning (STL) due to its ability to capture intrinsic relatedness among tasks. However, MTL may encounter the insufficient training problem, i.e., some tasks in MTL may encounter non-optimal situation compared with STL. A series of studies point out that too much gradient noise would lead to performance degradation in STL, however, in the MTL scenario, Inter-Task Gradient Noise (ITGN) is an additional source of gradient noise for each task, which can also affect the optimization process. In this paper, we point out ITGN as a key factor leading to the insufficient training problem. We define the Gradient-to-Noise Ratio (GNR) to measure the relative magnitude of gradient noise and design the MaxGNR algorithm to alleviate the ITGN interference of each task by maximizing the GNR of each task. We carefully evaluate our MaxGNR algorithm on two standard image MTL datasets: NYUv2 and Cityscapes. The results show that our algorithm outperforms the baselines under identical experimental conditions.