 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dual Complementary Dynamic Convolution for Image Recognition
Nov 11, 2022
As a powerful engine, vanilla convolution has promoted huge breakthroughs in various computer tasks. However, it often suffers from sample and content agnostic problems, which limits the representation capacities of the convolutional neural networks (CNNs). In this paper, we for the first time model the scene features as a combination of the local spatial-adaptive parts owned by the individual and the global shift-invariant parts shared to all individuals, and then propose a novel two-branch dual complementary dynamic convolution (DCDC) operator to flexibly deal with these two types of features. The DCDC operator overcomes the limitations of vanilla convolution and most existing dynamic convolutions who capture only spatial-adaptive features, and thus markedly boosts the representation capacities of CNNs. Experiments show that the DCDC operator based ResNets (DCDC-ResNets) significantly outperform vanilla ResNets and most state-of-the-art dynamic convolutional networks on image classification, as well as downstream tasks including object detection, instance and panoptic segmentation tasks, while with lower FLOPs and parameters.
Posterior Annealing: Fast Calibrated Uncertainty for Regression
Feb 21, 2023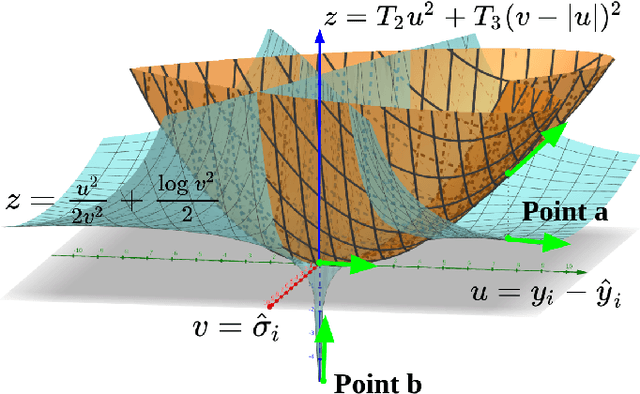
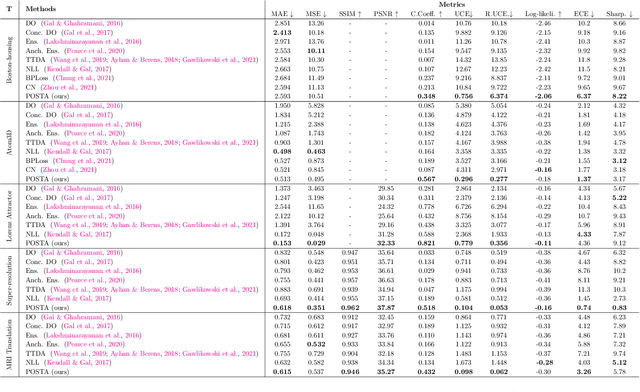
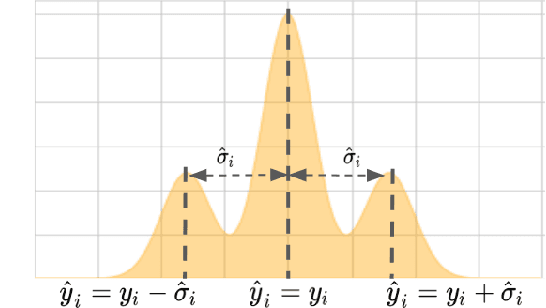
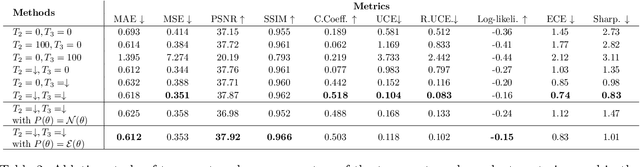
Bayesian deep learning approaches that allow uncertainty estimation for regression problems often converge slowly and yield poorly calibrated uncertainty estimates that can not be effectively used for quantification. Recently proposed post hoc calibration techniques are seldom applicable to regression problems and often add overhead to an already slow model training phase. This work presents a fast calibrated uncertainty estimation method for regression tasks, called posterior annealing, that consistently improves the convergence of deep regression models and yields calibrated uncertainty without any post hoc calibration phase. Unlike previous methods for calibrated uncertainty in regression that focus only on low-dimensional regression problems, our method works well on a wide spectrum of regression problems. Our empirical analysis shows that our approach is generalizable to various network architectures including, multilayer perceptrons, 1D/2D convolutional networks, and graph neural networks, on five vastly diverse tasks, i.e., chaotic particle trajectory denoising, physical property prediction of molecules using 3D atomistic representation, natural image super-resolution, and medical image translation using MRI images.
MaskedKD: Efficient Distillation of Vision Transformers with Masked Images
Feb 21, 2023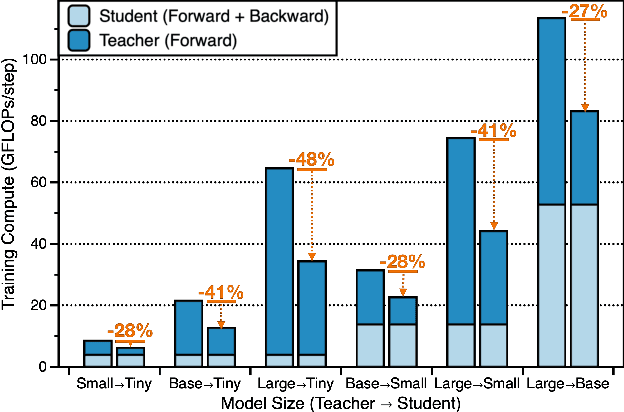
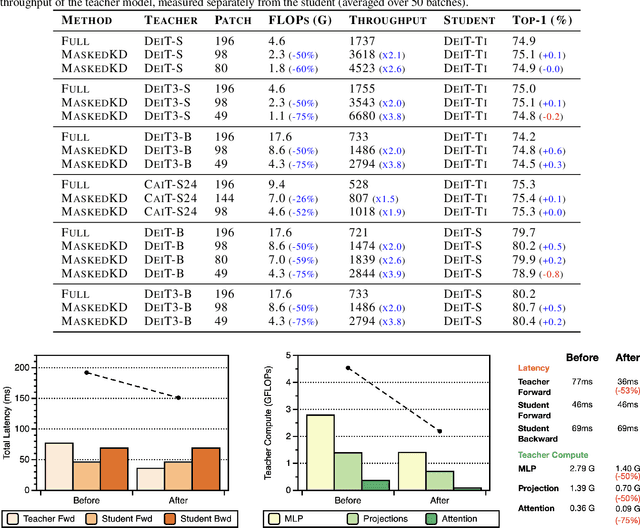
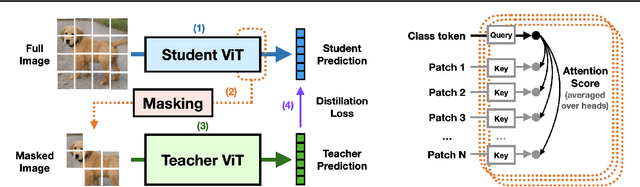

Knowledge distillation is a popular and effective regularization technique for training lightweight models, but it also adds significant overhead to the training cost. The drawback is most pronounced when we use large-scale models as our teachers, such as vision transformers (ViTs). We present MaskedKD, a simple yet effective method for reducing the training cost of ViT distillation. MaskedKD masks a fraction of image patch tokens fed to the teacher to save the teacher inference cost. The tokens to mask are determined based on the last layer attention score of the student model, to which we provide the full image. Without requiring any architectural change of the teacher or making sacrifices in the student performance, MaskedKD dramatically reduces the computations and time required for distilling ViTs. We demonstrate that MaskedKD can save up to $50\%$ of the cost of running inference on the teacher model without any performance drop on the student, leading to approximately $28\%$ drop in the teacher and student compute combined.
Efficient Context Integration through Factorized Pyramidal Learning for Ultra-Lightweight Semantic Segmentation
Feb 23, 2023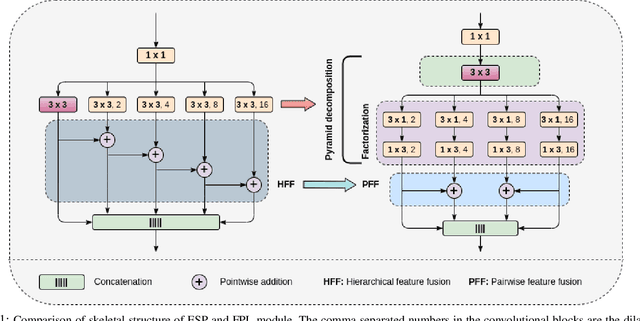
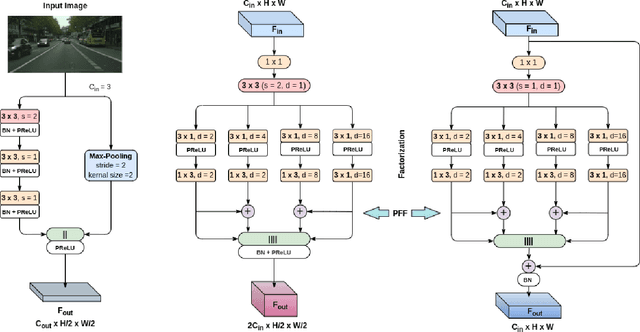
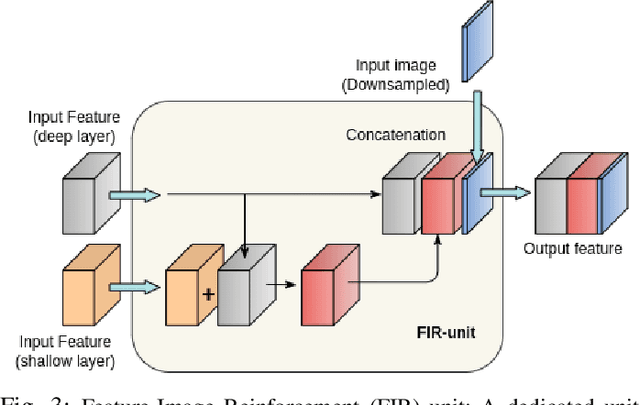
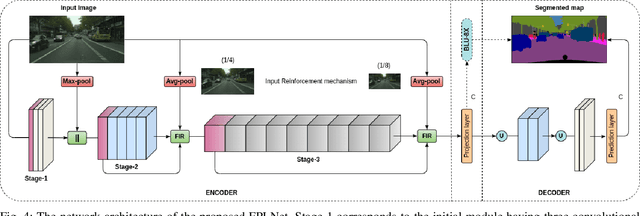
Semantic segmentation is a pixel-level prediction task to classify each pixel of the input image. Deep learning models, such as convolutional neural networks (CNNs), have been extremely successful in achieving excellent performances in this domain. However, mobile application, such as autonomous driving, demand real-time processing of incoming stream of images. Hence, achieving efficient architectures along with enhanced accuracy is of paramount importance. Since, accuracy and model size of CNNs are intrinsically contentious in nature, the challenge is to achieve a decent trade-off between accuracy and model size. To address this, we propose a novel Factorized Pyramidal Learning (FPL) module to aggregate rich contextual information in an efficient manner. On one hand, it uses a bank of convolutional filters with multiple dilation rates which leads to multi-scale context aggregation; crucial in achieving better accuracy. On the other hand, parameters are reduced by a careful factorization of the employed filters; crucial in achieving lightweight models. Moreover, we decompose the spatial pyramid into two stages which enables a simple and efficient feature fusion within the module to solve the notorious checkerboard effect. We also design a dedicated Feature-Image Reinforcement (FIR) unit to carry out the fusion operation of shallow and deep features with the downsampled versions of the input image. This gives an accuracy enhancement without increasing model parameters. Based on the FPL module and FIR unit, we propose an ultra-lightweight real-time network, called FPLNet, which achieves state-of-the-art accuracy-efficiency trade-off. More specifically, with only less than 0.5 million parameters, the proposed network achieves 66.93\% and 66.28\% mIoU on Cityscapes validation and test set, respectively. Moreover, FPLNet has a processing speed of 95.5 frames per second (FPS).
Test-Time Mixup Augmentation for Data and Class-Specific Uncertainty Estimation in Multi-Class Image Classification
Dec 01, 2022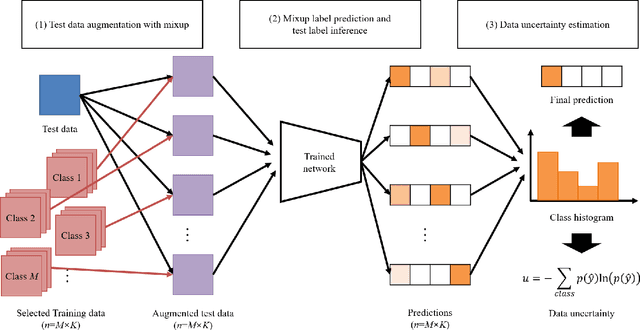
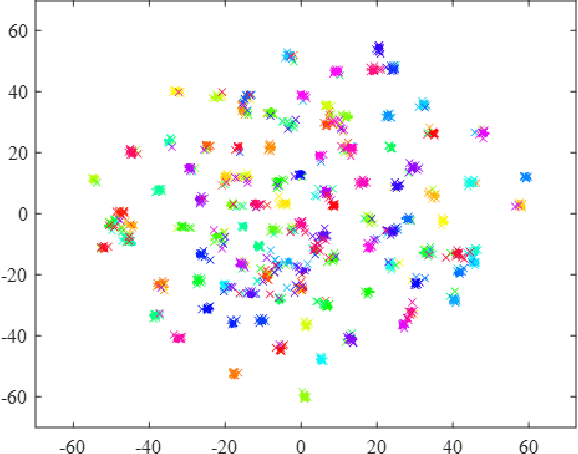

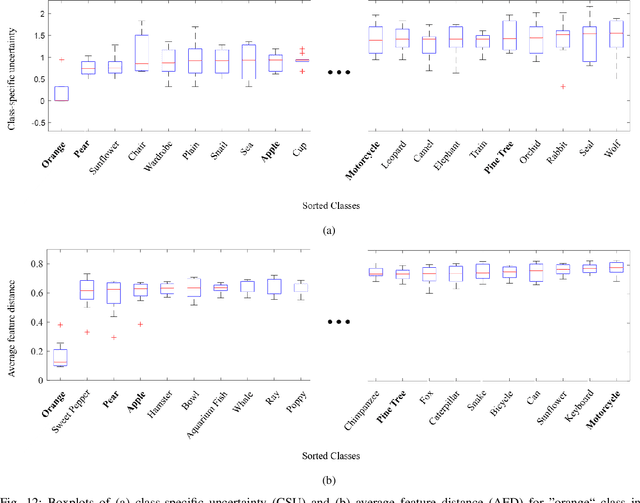
Uncertainty estimation of the trained deep learning network provides important information for improving the learning efficiency or evaluating the reliability of the network prediction. In this paper, we propose a method for the uncertainty estimation for multi-class image classification using test-time mixup augmentation (TTMA). To improve the discrimination ability between the correct and incorrect prediction of the existing aleatoric uncertainty, we propose the data uncertainty by applying the mixup augmentation on the test data and measuring the entropy of the histogram of predicted labels. In addition to the data uncertainty, we propose a class-specific uncertainty presenting the aleatoric uncertainty associated with the specific class, which can provide information on the class confusion and class similarity of the trained network. The proposed methods are validated on two public datasets, the ISIC-18 skin lesion diagnosis dataset, and the CIFAR-100 real-world image classification dataset. The experiments demonstrate that (1) the proposed data uncertainty better separates the correct and incorrect prediction than the existing uncertainty measures thanks to the mixup perturbation, and (2) the proposed class-specific uncertainty provides information on the class confusion and class similarity of the trained network for both datasets.
Divide and Compose with Score Based Generative Models
Feb 05, 2023



While score based generative models, or diffusion models, have found success in image synthesis, they are often coupled with text data or image label to be able to manipulate and conditionally generate images. Even though manipulation of images by changing the text prompt is possible, our understanding of the text embedding and our ability to modify it to edit images is quite limited. Towards the direction of having more control over image manipulation and conditional generation, we propose to learn image components in an unsupervised manner so that we can compose those components to generate and manipulate images in informed manner. Taking inspiration from energy based models, we interpret different score components as the gradient of different energy functions. We show how score based learning allows us to learn interesting components and we can visualize them through generation. We also show how this novel decomposition allows us to compose, generate and modify images in interesting ways akin to dreaming. We make our code available at https://github.com/sandeshgh/Score-based-disentanglement
Domain Generalisation via Domain Adaptation: An Adversarial Fourier Amplitude Approach
Feb 23, 2023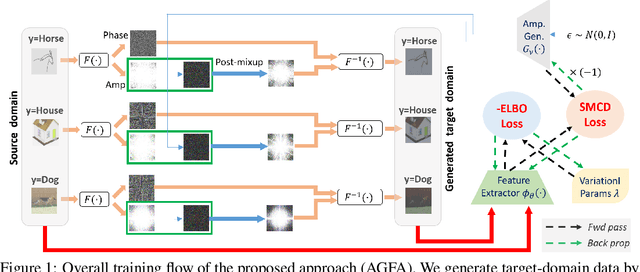
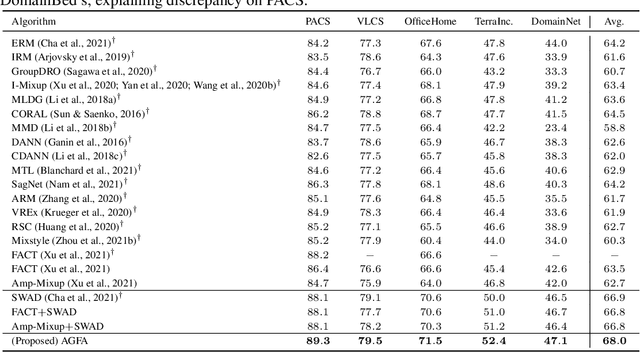
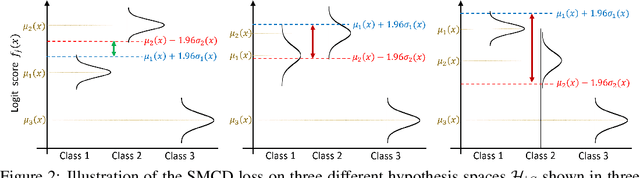
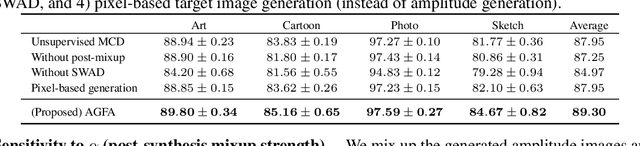
We tackle the domain generalisation (DG) problem by posing it as a domain adaptation (DA) task where we adversarially synthesise the worst-case target domain and adapt a model to that worst-case domain, thereby improving the model's robustness. To synthesise data that is challenging yet semantics-preserving, we generate Fourier amplitude images and combine them with source domain phase images, exploiting the widely believed conjecture from signal processing that amplitude spectra mainly determines image style, while phase data mainly captures image semantics. To synthesise a worst-case domain for adaptation, we train the classifier and the amplitude generator adversarially. Specifically, we exploit the maximum classifier discrepancy (MCD) principle from DA that relates the target domain performance to the discrepancy of classifiers in the model hypothesis space. By Bayesian hypothesis modeling, we express the model hypothesis space effectively as a posterior distribution over classifiers given the source domains, making adversarial MCD minimisation feasible. On the DomainBed benchmark including the large-scale DomainNet dataset, the proposed approach yields significantly improved domain generalisation performance over the state-of-the-art.
A Gradient Boosting Approach for Training Convolutional and Deep Neural Networks
Feb 23, 2023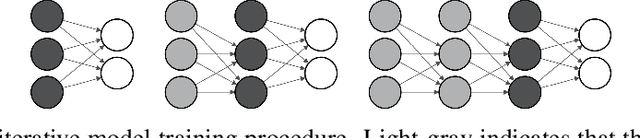
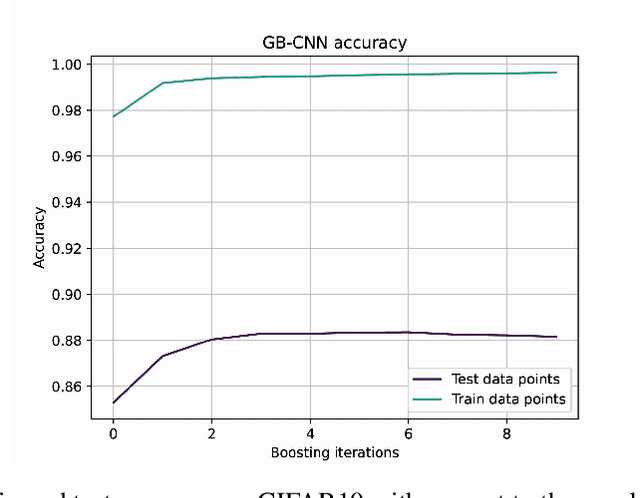
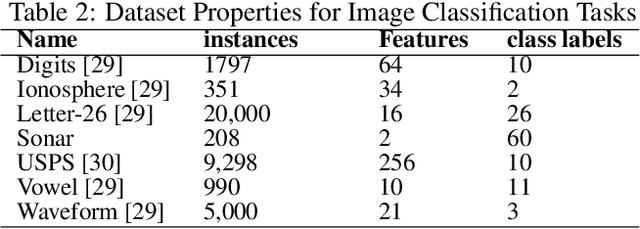
Deep learning has revolutionized the computer vision and image classification domains. In this context Convolutional Neural Networks (CNNs) based architectures are the most widely applied models. In this article, we introduced two procedures for training Convolutional Neural Networks (CNNs) and Deep Neural Network based on Gradient Boosting (GB), namely GB-CNN and GB-DNN. These models are trained to fit the gradient of the loss function or pseudo-residuals of previous models. At each iteration, the proposed method adds one dense layer to an exact copy of the previous deep NN model. The weights of the dense layers trained on previous iterations are frozen to prevent over-fitting, permitting the model to fit the new dense as well as to fine-tune the convolutional layers (for GB-CNN) while still utilizing the information already learned. Through extensive experimentation on different 2D-image classification and tabular datasets, the presented models show superior performance in terms of classification accuracy with respect to standard CNN and Deep-NN with the same architectures.
PLU-Net: Extraction of multi-scale feature fusion
Feb 23, 2023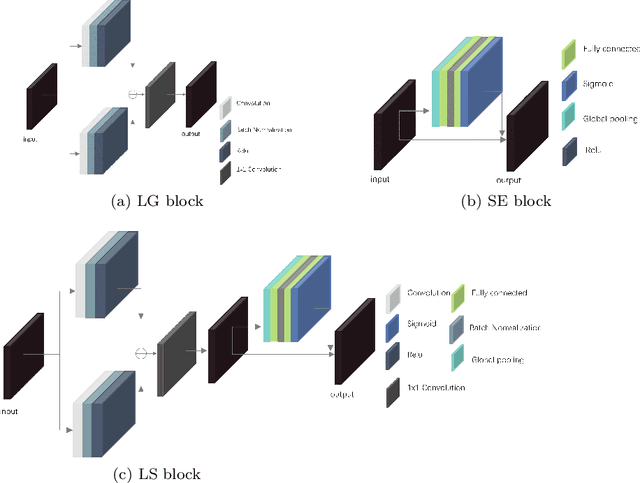

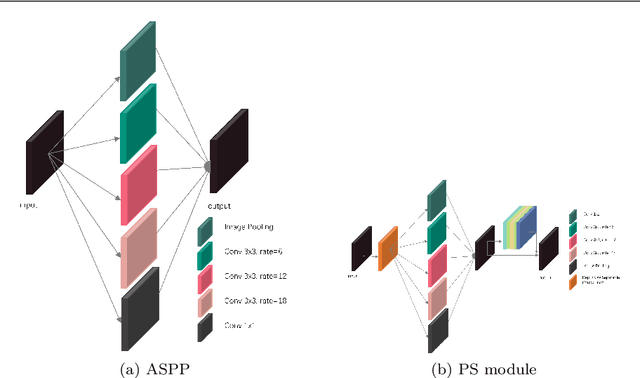
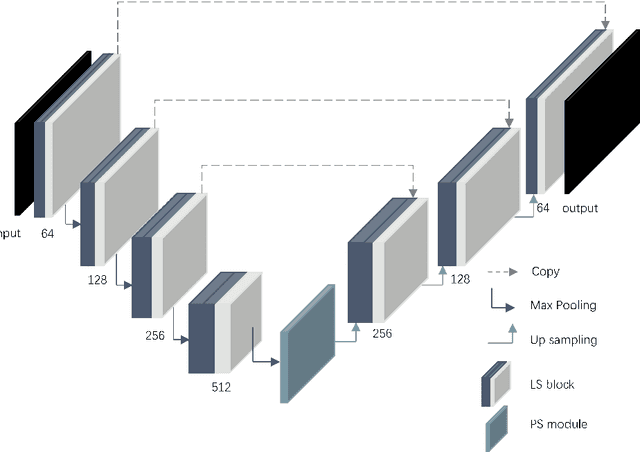
Deep learning algorithms have achieved remarkable results in medical image segmentation in recent years. These networks are unable to handle with image boundaries and details with enormous parameters, resulting in poor segmentation results. To address the issue, we develop atrous spatial pyramid pooling (ASPP) and combine it with the Squeeze-and-Excitation block (SE block), as well as present the PS module, which employs a broader and multi-scale receptive field at the network's bottom to obtain more detailed semantic information. We also propose the Local Guided block (LG block) and also its combination with the SE block to form the LS block, which can obtain more abundant local features in the feature map, so that more edge information can be retained in each down sampling process, thereby improving the performance of boundary segmentation. We propose PLU-Net and integrate our PS module and LS block into U-Net. We put our PLU-Net to the test on three benchmark datasets, and the results show that by fewer parameters and FLOPs, it outperforms on medical semantic segmentation tasks.
Use Cases for Time-Frequency Image Representations and Deep Learning Techniques for Improved Signal Classification
Feb 22, 2023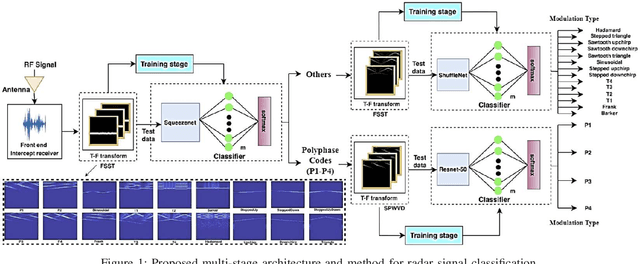
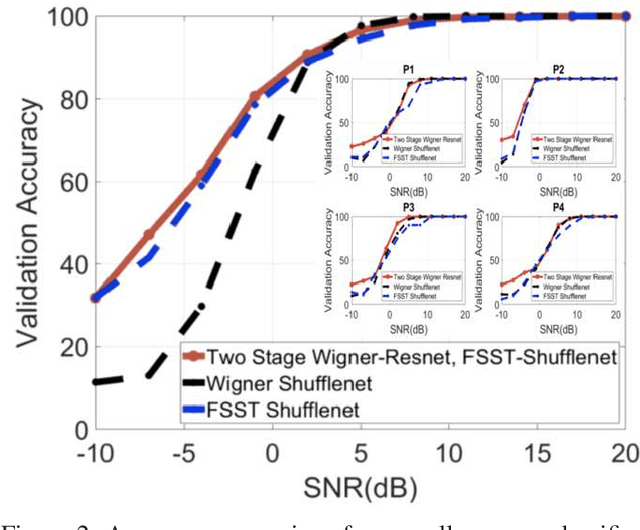
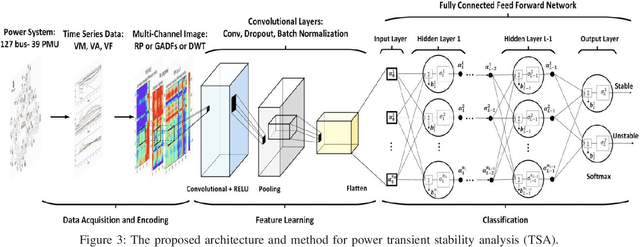
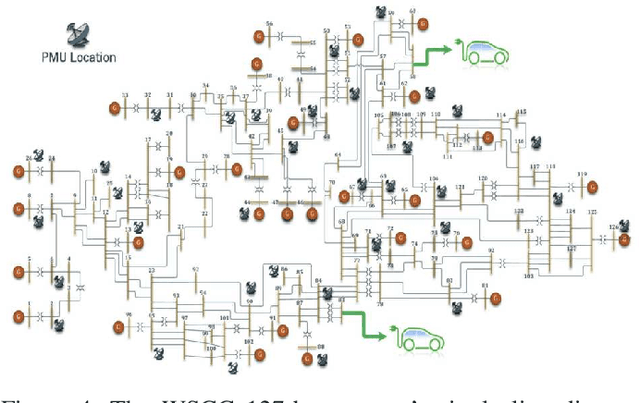
Time-frequency images (TFIs) provide a joint time-frequency representation of a signal and have become an effective tool for analyzing, characterizing, and processing non-stationary signals. Deep learning (DL) techniques have become versatile for signal classification, enabling the automatic extraction of relevant features from raw data. In this paper, we present two use cases on the time-frequency transformation and deep learning techniques for signal classification, where signals are first pre-processed and transformed into TFIs, and their features are then extracted through deep learning neural networks and classification algorithms. The specific methods and algorithms used may vary depending on the particular application, therefore different methods for creating TFIs; the Short-Time Fourier Transform (STFT), Fourier-based Synchrosqueezing Transform (FSST), Wigner Ville distribution (WVD), Smoothed Pseudo-Wigner distribution (SPWD), Choi-Williams distribution (CWD), and Continuous Wavelet Transform (CWT) are investigated. The performance of various deep learning, and convolutional neural network (CNN) models such as ResNet-50, ShuffleNet, and Squeezenet are evaluated for their accuracy of classification in different applications and the results are compared with the results of the conventional machine learning and ensemble methods such as Multilayer Perceptrons (MLP), Support Vector Machine (SVM), Random Forest (RF), Decision Tree (DT), and XGboost. The results of this research demonstrate that significant improvements in signal classification accuracy can be achieved by leveraging the combined power of TFIs, and deep learning models. These advances have found practical applications in a wide range of fields, including radar signal classification, stability analysis of power systems, speech and music recognition, and biomedical signal characterization.