 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ReFeree: Radar-based efficient global descriptor using a Feature and Free space for Place Recognition
Mar 21, 2024
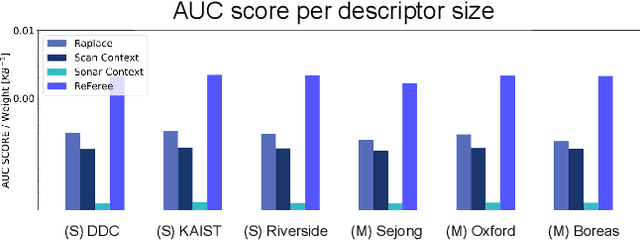
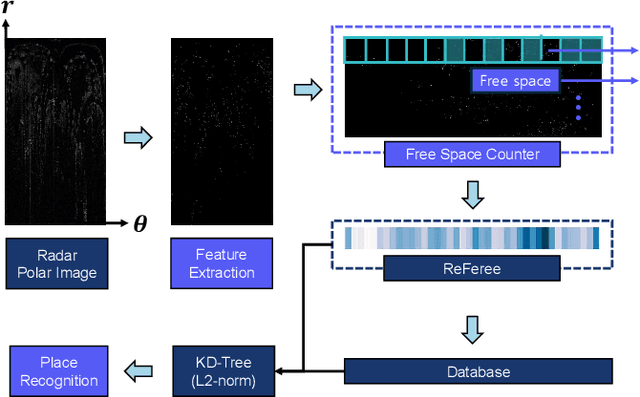
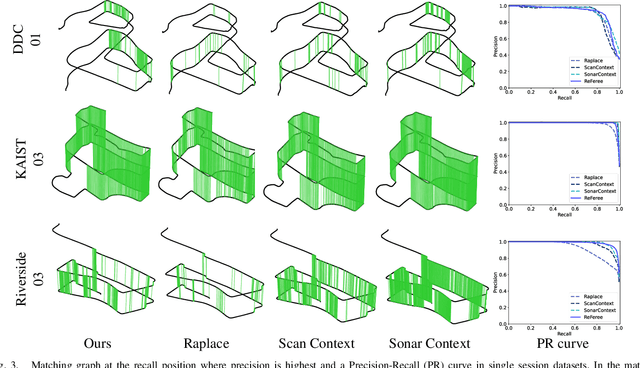
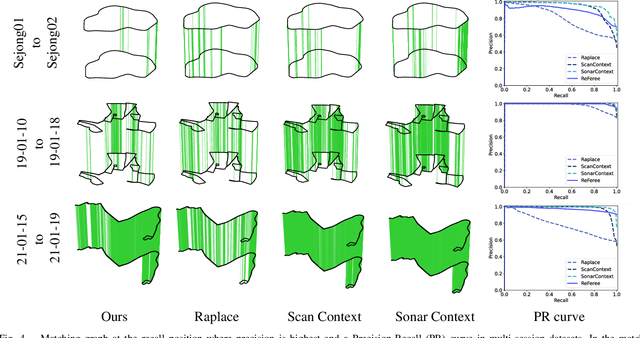
Radar is highlighted for robust sensing capabilities in adverse weather conditions (e.g. dense fog, heavy rain, or snowfall). In addition, Radar can cover wide areas and penetrate small particles. Despite these advantages, Radar-based place recognition remains in the early stages compared to other sensors due to its unique characteristics such as low resolution, and significant noise. In this paper, we propose a Radarbased place recognition utilizing a descriptor called ReFeree using a feature and free space. Unlike traditional methods, we overwhelmingly summarize the Radar image. Despite being lightweight, it contains semi-metric information and is also outstanding from the perspective of place recognition performance. For concrete validation, we test a single session from the MulRan dataset and a multi-session from the Oxford Radar RobotCar and the Boreas dataset.
PrimeComposer: Faster Progressively Combined Diffusion for Image Composition with Attention Steering
Mar 08, 2024
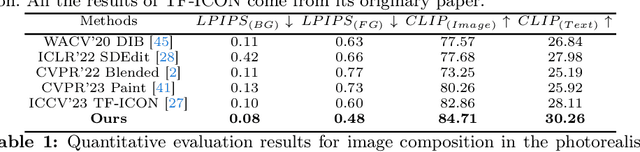

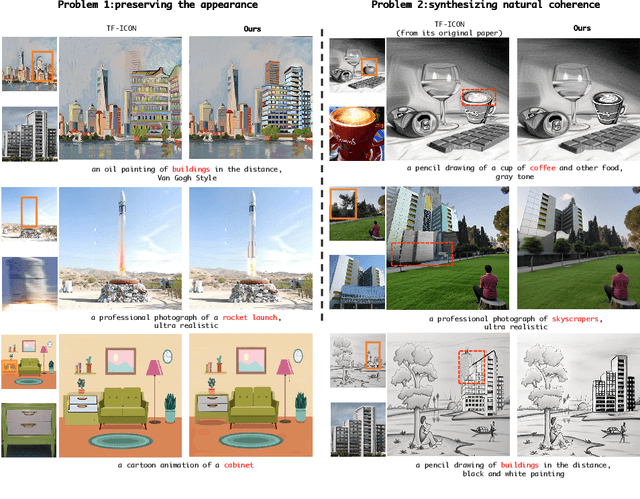
Image composition involves seamlessly integrating given objects into a specific visual context. The current training-free methods rely on composing attention weights from several samplers to guide the generator. However, since these weights are derived from disparate contexts, their combination leads to coherence confusion in synthesis and loss of appearance information. These issues worsen with their excessive focus on background generation, even when unnecessary in this task. This not only slows down inference but also compromises foreground generation quality. Moreover, these methods introduce unwanted artifacts in the transition area. In this paper, we formulate image composition as a subject-based local editing task, solely focusing on foreground generation. At each step, the edited foreground is combined with the noisy background to maintain scene consistency. To address the remaining issues, we propose PrimeComposer, a faster training-free diffuser that composites the images by well-designed attention steering across different noise levels. This steering is predominantly achieved by our Correlation Diffuser, utilizing its self-attention layers at each step. Within these layers, the synthesized subject interacts with both the referenced object and background, capturing intricate details and coherent relationships. This prior information is encoded into the attention weights, which are then integrated into the self-attention layers of the generator to guide the synthesis process. Besides, we introduce a Region-constrained Cross-Attention to confine the impact of specific subject-related words to desired regions, addressing the unwanted artifacts shown in the prior method thereby further improving the coherence in the transition area. Our method exhibits the fastest inference efficiency and extensive experiments demonstrate our superiority both qualitatively and quantitatively.
A Simple Framework Uniting Visual In-context Learning with Masked Image Modeling to Improve Ultrasound Segmentation
Mar 08, 2024Conventional deep learning models deal with images one-by-one, requiring costly and time-consuming expert labeling in the field of medical imaging, and domain-specific restriction limits model generalizability. Visual in-context learning (ICL) is a new and exciting area of research in computer vision. Unlike conventional deep learning, ICL emphasizes the model's ability to adapt to new tasks based on given examples quickly. Inspired by MAE-VQGAN, we proposed a new simple visual ICL method called SimICL, combining visual ICL pairing images with masked image modeling (MIM) designed for self-supervised learning. We validated our method on bony structures segmentation in a wrist ultrasound (US) dataset with limited annotations, where the clinical objective was to segment bony structures to help with further fracture detection. We used a test set containing 3822 images from 18 patients for bony region segmentation. SimICL achieved an remarkably high Dice coeffient (DC) of 0.96 and Jaccard Index (IoU) of 0.92, surpassing state-of-the-art segmentation and visual ICL models (a maximum DC 0.86 and IoU 0.76), with SimICL DC and IoU increasing up to 0.10 and 0.16. This remarkably high agreement with limited manual annotations indicates SimICL could be used for training AI models even on small US datasets. This could dramatically decrease the human expert time required for image labeling compared to conventional approaches, and enhance the real-world use of AI assistance in US image analysis.
FairerCLIP: Debiasing CLIP's Zero-Shot Predictions using Functions in RKHSs
Mar 22, 2024Large pre-trained vision-language models such as CLIP provide compact and general-purpose representations of text and images that are demonstrably effective across multiple downstream zero-shot prediction tasks. However, owing to the nature of their training process, these models have the potential to 1) propagate or amplify societal biases in the training data and 2) learn to rely on spurious features. This paper proposes FairerCLIP, a general approach for making zero-shot predictions of CLIP more fair and robust to spurious correlations. We formulate the problem of jointly debiasing CLIP's image and text representations in reproducing kernel Hilbert spaces (RKHSs), which affords multiple benefits: 1) Flexibility: Unlike existing approaches, which are specialized to either learn with or without ground-truth labels, FairerCLIP is adaptable to learning in both scenarios. 2) Ease of Optimization: FairerCLIP lends itself to an iterative optimization involving closed-form solvers, which leads to $4\times$-$10\times$ faster training than the existing methods. 3) Sample Efficiency: Under sample-limited conditions, FairerCLIP significantly outperforms baselines when they fail entirely. And, 4) Performance: Empirically, FairerCLIP achieves appreciable accuracy gains on benchmark fairness and spurious correlation datasets over their respective baselines.
Do not trust what you trust: Miscalibration in Semi-supervised Learning
Mar 22, 2024State-of-the-art semi-supervised learning (SSL) approaches rely on highly confident predictions to serve as pseudo-labels that guide the training on unlabeled samples. An inherent drawback of this strategy stems from the quality of the uncertainty estimates, as pseudo-labels are filtered only based on their degree of uncertainty, regardless of the correctness of their predictions. Thus, assessing and enhancing the uncertainty of network predictions is of paramount importance in the pseudo-labeling process. In this work, we empirically demonstrate that SSL methods based on pseudo-labels are significantly miscalibrated, and formally demonstrate the minimization of the min-entropy, a lower bound of the Shannon entropy, as a potential cause for miscalibration. To alleviate this issue, we integrate a simple penalty term, which enforces the logit distances of the predictions on unlabeled samples to remain low, preventing the network predictions to become overconfident. Comprehensive experiments on a variety of SSL image classification benchmarks demonstrate that the proposed solution systematically improves the calibration performance of relevant SSL models, while also enhancing their discriminative power, being an appealing addition to tackle SSL tasks.
SiMBA: Simplified Mamba-Based Architecture for Vision and Multivariate Time series
Mar 22, 2024Transformers have widely adopted attention networks for sequence mixing and MLPs for channel mixing, playing a pivotal role in achieving breakthroughs across domains. However, recent literature highlights issues with attention networks, including low inductive bias and quadratic complexity concerning input sequence length. State Space Models (SSMs) like S4 and others (Hippo, Global Convolutions, liquid S4, LRU, Mega, and Mamba), have emerged to address the above issues to help handle longer sequence lengths. Mamba, while being the state-of-the-art SSM, has a stability issue when scaled to large networks for computer vision datasets. We propose SiMBA, a new architecture that introduces Einstein FFT (EinFFT) for channel modeling by specific eigenvalue computations and uses the Mamba block for sequence modeling. Extensive performance studies across image and time-series benchmarks demonstrate that SiMBA outperforms existing SSMs, bridging the performance gap with state-of-the-art transformers. Notably, SiMBA establishes itself as the new state-of-the-art SSM on ImageNet and transfer learning benchmarks such as Stanford Car and Flower as well as task learning benchmarks as well as seven time series benchmark datasets. The project page is available on this website ~\url{https://github.com/badripatro/Simba}.
Self-Supervised Backbone Framework for Diverse Agricultural Vision Tasks
Mar 22, 2024Computer vision in agriculture is game-changing with its ability to transform farming into a data-driven, precise, and sustainable industry. Deep learning has empowered agriculture vision to analyze vast, complex visual data, but heavily rely on the availability of large annotated datasets. This remains a bottleneck as manual labeling is error-prone, time-consuming, and expensive. The lack of efficient labeling approaches inspired us to consider self-supervised learning as a paradigm shift, learning meaningful feature representations from raw agricultural image data. In this work, we explore how self-supervised representation learning unlocks the potential applicability to diverse agriculture vision tasks by eliminating the need for large-scale annotated datasets. We propose a lightweight framework utilizing SimCLR, a contrastive learning approach, to pre-train a ResNet-50 backbone on a large, unannotated dataset of real-world agriculture field images. Our experimental analysis and results indicate that the model learns robust features applicable to a broad range of downstream agriculture tasks discussed in the paper. Additionally, the reduced reliance on annotated data makes our approach more cost-effective and accessible, paving the way for broader adoption of computer vision in agriculture.
An In-Depth Analysis of Data Reduction Methods for Sustainable Deep Learning
Mar 22, 2024In recent years, Deep Learning has gained popularity for its ability to solve complex classification tasks, increasingly delivering better results thanks to the development of more accurate models, the availability of huge volumes of data and the improved computational capabilities of modern computers. However, these improvements in performance also bring efficiency problems, related to the storage of datasets and models, and to the waste of energy and time involved in both the training and inference processes. In this context, data reduction can help reduce energy consumption when training a deep learning model. In this paper, we present up to eight different methods to reduce the size of a tabular training dataset, and we develop a Python package to apply them. We also introduce a representativeness metric based on topology to measure how similar are the reduced datasets and the full training dataset. Additionally, we develop a methodology to apply these data reduction methods to image datasets for object detection tasks. Finally, we experimentally compare how these data reduction methods affect the representativeness of the reduced dataset, the energy consumption and the predictive performance of the model.
Mora: Enabling Generalist Video Generation via A Multi-Agent Framework
Mar 22, 2024
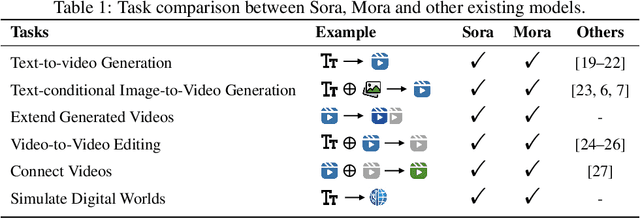
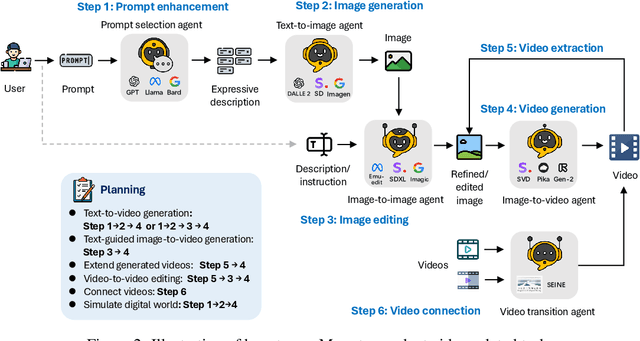
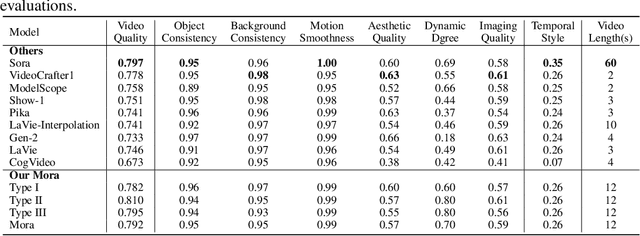
Sora is the first large-scale generalist video generation model that garnered significant attention across society. Since its launch by OpenAI in February 2024, no other video generation models have paralleled {Sora}'s performance or its capacity to support a broad spectrum of video generation tasks. Additionally, there are only a few fully published video generation models, with the majority being closed-source. To address this gap, this paper proposes a new multi-agent framework Mora, which incorporates several advanced visual AI agents to replicate generalist video generation demonstrated by Sora. In particular, Mora can utilize multiple visual agents and successfully mimic Sora's video generation capabilities in various tasks, such as (1) text-to-video generation, (2) text-conditional image-to-video generation, (3) extend generated videos, (4) video-to-video editing, (5) connect videos and (6) simulate digital worlds. Our extensive experimental results show that Mora achieves performance that is proximate to that of Sora in various tasks. However, there exists an obvious performance gap between our work and Sora when assessed holistically. In summary, we hope this project can guide the future trajectory of video generation through collaborative AI agents.
Multi-Spectral Remote Sensing Image Retrieval Using Geospatial Foundation Models
Mar 04, 2024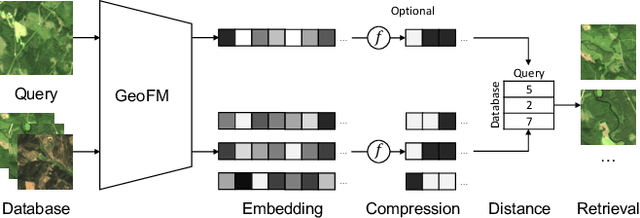
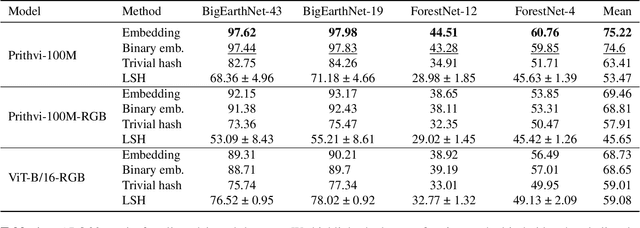
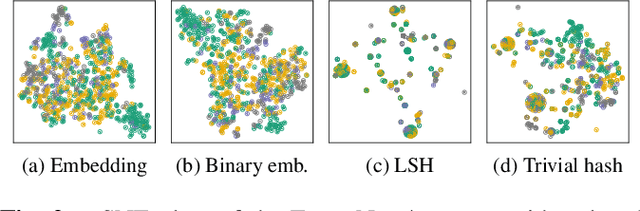

Image retrieval enables an efficient search through vast amounts of satellite imagery and returns similar images to a query. Deep learning models can identify images across various semantic concepts without the need for annotations. This work proposes to use Geospatial Foundation Models, like Prithvi, for remote sensing image retrieval with multiple benefits: i) the models encode multi-spectral satellite data and ii) generalize without further fine-tuning. We introduce two datasets to the retrieval task and observe a strong performance: Prithvi processes six bands and achieves a mean Average Precision of 97.62\% on BigEarthNet-43 and 44.51\% on ForestNet-12, outperforming other RGB-based models. Further, we evaluate three compression methods with binarized embeddings balancing retrieval speed and accuracy. They match the retrieval speed of much shorter hash codes while maintaining the same accuracy as floating-point embeddings but with a 32-fold compression. The code is available at https://github.com/IBM/remote-sensing-image-retrieval.