 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The Five-Dollar Model: Generating Game Maps and Sprites from Sentence Embeddings
Aug 08, 2023
The five-dollar model is a lightweight text-to-image generative architecture that generates low dimensional images from an encoded text prompt. This model can successfully generate accurate and aesthetically pleasing content in low dimensional domains, with limited amounts of training data. Despite the small size of both the model and datasets, the generated images are still able to maintain the encoded semantic meaning of the textual prompt. We apply this model to three small datasets: pixel art video game maps, video game sprite images, and down-scaled emoji images and apply novel augmentation strategies to improve the performance of our model on these limited datasets. We evaluate our models performance using cosine similarity score between text-image pairs generated by the CLIP VIT-B/32 model.
Making the V in Text-VQA Matter
Aug 01, 2023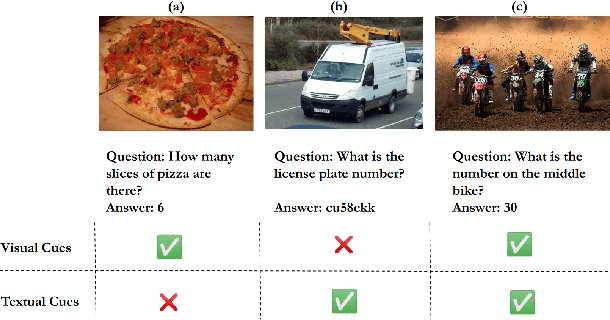


Text-based VQA aims at answering questions by reading the text present in the images. It requires a large amount of scene-text relationship understanding compared to the VQA task. Recent studies have shown that the question-answer pairs in the dataset are more focused on the text present in the image but less importance is given to visual features and some questions do not require understanding the image. The models trained on this dataset predict biased answers due to the lack of understanding of visual context. For example, in questions like "What is written on the signboard?", the answer predicted by the model is always "STOP" which makes the model to ignore the image. To address these issues, we propose a method to learn visual features (making V matter in TextVQA) along with the OCR features and question features using VQA dataset as external knowledge for Text-based VQA. Specifically, we combine the TextVQA dataset and VQA dataset and train the model on this combined dataset. Such a simple, yet effective approach increases the understanding and correlation between the image features and text present in the image, which helps in the better answering of questions. We further test the model on different datasets and compare their qualitative and quantitative results.
S2R: Exploring a Double-Win Transformer-Based Framework for Ideal and Blind Super-Resolution
Aug 16, 2023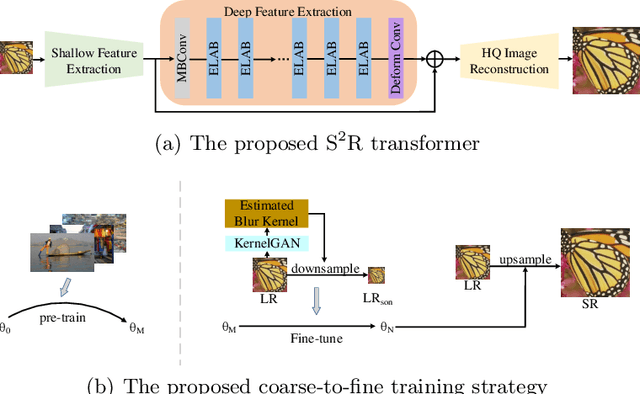
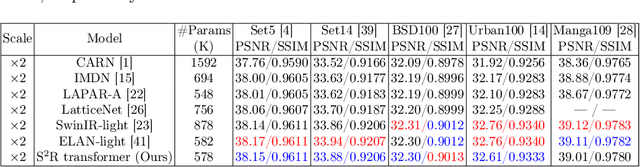


Nowadays, deep learning based methods have demonstrated impressive performance on ideal super-resolution (SR) datasets, but most of these methods incur dramatically performance drops when directly applied in real-world SR reconstruction tasks with unpredictable blur kernels. To tackle this issue, blind SR methods are proposed to improve the visual results on random blur kernels, which causes unsatisfactory reconstruction effects on ideal low-resolution images similarly. In this paper, we propose a double-win framework for ideal and blind SR task, named S2R, including a light-weight transformer-based SR model (S2R transformer) and a novel coarse-to-fine training strategy, which can achieve excellent visual results on both ideal and random fuzzy conditions. On algorithm level, S2R transformer smartly combines some efficient and light-weight blocks to enhance the representation ability of extracted features with relatively low number of parameters. For training strategy, a coarse-level learning process is firstly performed to improve the generalization of the network with the help of a large-scale external dataset, and then, a fast fine-tune process is developed to transfer the pre-trained model to real-world SR tasks by mining the internal features of the image. Experimental results show that the proposed S2R outperforms other single-image SR models in ideal SR condition with only 578K parameters. Meanwhile, it can achieve better visual results than regular blind SR models in blind fuzzy conditions with only 10 gradient updates, which improve convergence speed by 300 times, significantly accelerating the transfer-learning process in real-world situations.
Robotic Scene Segmentation with Memory Network for Runtime Surgical Context Inference
Aug 24, 2023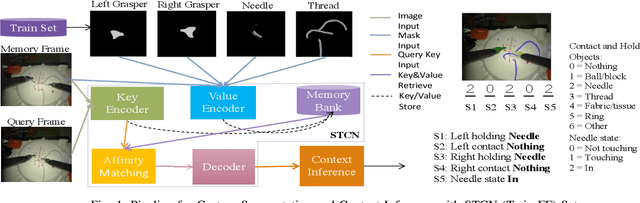
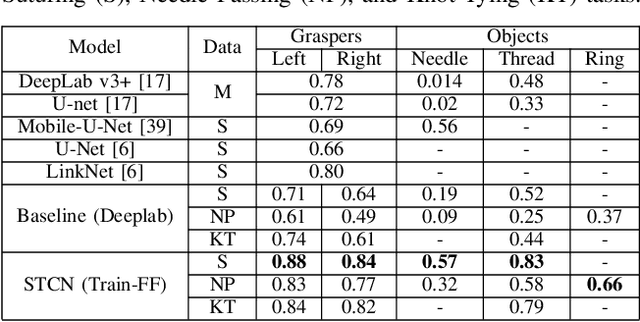
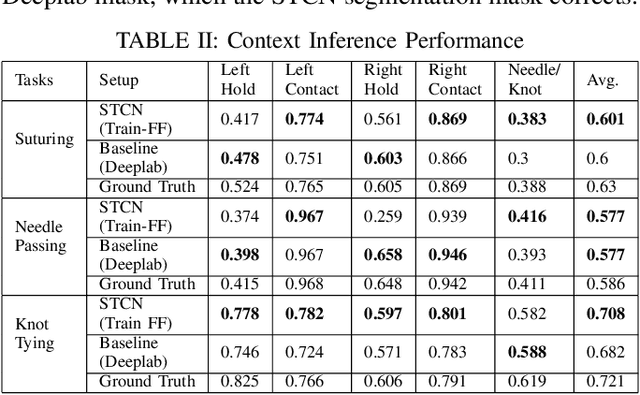

Surgical context inference has recently garnered significant attention in robot-assisted surgery as it can facilitate workflow analysis, skill assessment, and error detection. However, runtime context inference is challenging since it requires timely and accurate detection of the interactions among the tools and objects in the surgical scene based on the segmentation of video data. On the other hand, existing state-of-the-art video segmentation methods are often biased against infrequent classes and fail to provide temporal consistency for segmented masks. This can negatively impact the context inference and accurate detection of critical states. In this study, we propose a solution to these challenges using a Space Time Correspondence Network (STCN). STCN is a memory network that performs binary segmentation and minimizes the effects of class imbalance. The use of a memory bank in STCN allows for the utilization of past image and segmentation information, thereby ensuring consistency of the masks. Our experiments using the publicly available JIGSAWS dataset demonstrate that STCN achieves superior segmentation performance for objects that are difficult to segment, such as needle and thread, and improves context inference compared to the state-of-the-art. We also demonstrate that segmentation and context inference can be performed at runtime without compromising performance.
WS-SfMLearner: Self-supervised Monocular Depth and Ego-motion Estimation on Surgical Videos with Unknown Camera Parameters
Aug 22, 2023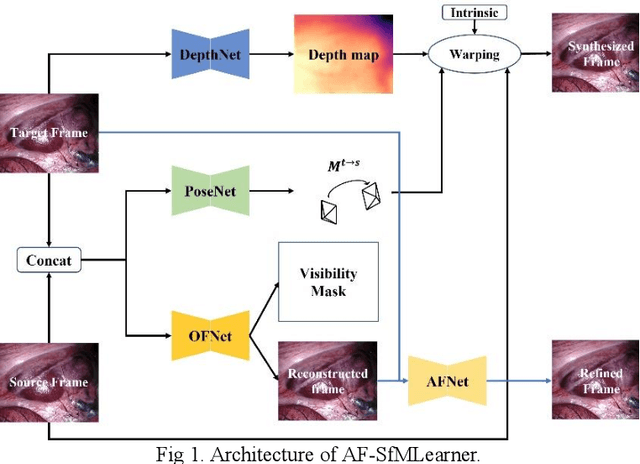
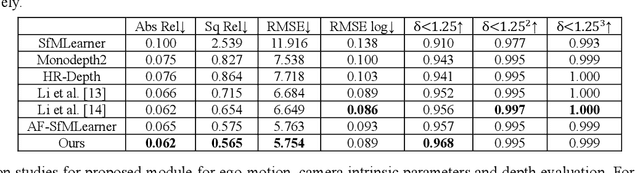
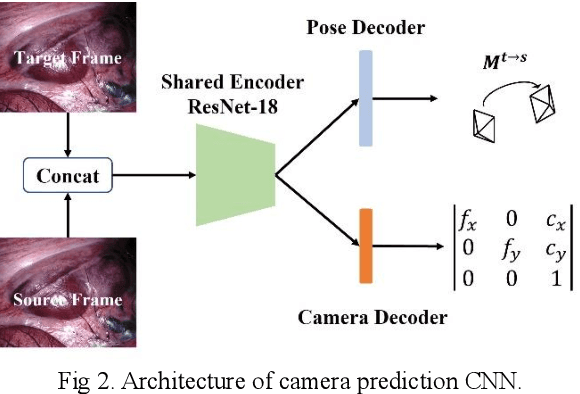
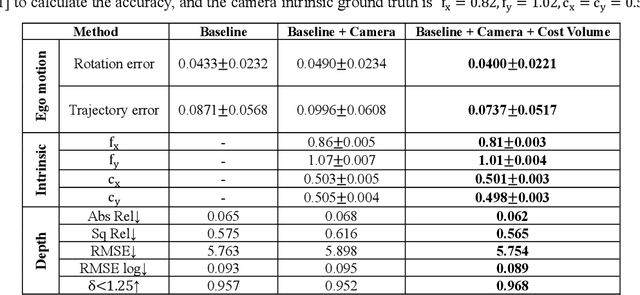
Depth estimation in surgical video plays a crucial role in many image-guided surgery procedures. However, it is difficult and time consuming to create depth map ground truth datasets in surgical videos due in part to inconsistent brightness and noise in the surgical scene. Therefore, building an accurate and robust self-supervised depth and camera ego-motion estimation system is gaining more attention from the computer vision community. Although several self-supervision methods alleviate the need for ground truth depth maps and poses, they still need known camera intrinsic parameters, which are often missing or not recorded. Moreover, the camera intrinsic prediction methods in existing works depend heavily on the quality of datasets. In this work, we aimed to build a self-supervised depth and ego-motion estimation system which can predict not only accurate depth maps and camera pose, but also camera intrinsic parameters. We proposed a cost-volume-based supervision manner to give the system auxiliary supervision for camera parameters prediction. The experimental results showed that the proposed method improved the accuracy of estimated camera parameters, ego-motion, and depth estimation.
Coarse-to-Fine Multi-Scene Pose Regression with Transformers
Aug 22, 2023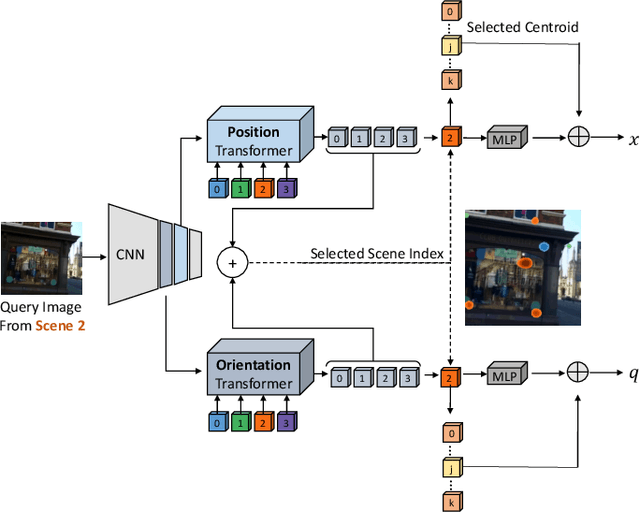
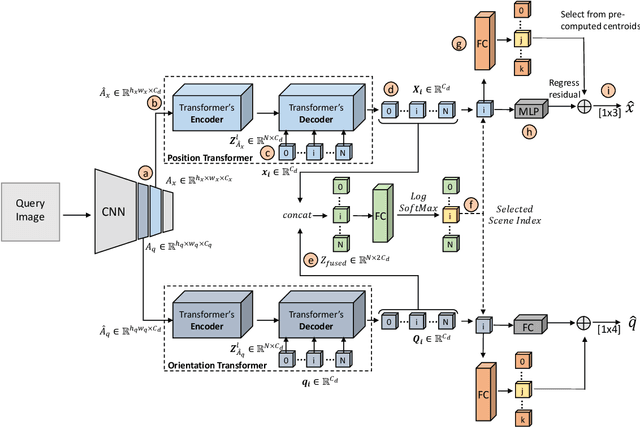


Absolute camera pose regressors estimate the position and orientation of a camera given the captured image alone. Typically, a convolutional backbone with a multi-layer perceptron (MLP) head is trained using images and pose labels to embed a single reference scene at a time. Recently, this scheme was extended to learn multiple scenes by replacing the MLP head with a set of fully connected layers. In this work, we propose to learn multi-scene absolute camera pose regression with Transformers, where encoders are used to aggregate activation maps with self-attention and decoders transform latent features and scenes encoding into pose predictions. This allows our model to focus on general features that are informative for localization, while embedding multiple scenes in parallel. We extend our previous MS-Transformer approach \cite{shavit2021learning} by introducing a mixed classification-regression architecture that improves the localization accuracy. Our method is evaluated on commonly benchmark indoor and outdoor datasets and has been shown to exceed both multi-scene and state-of-the-art single-scene absolute pose regressors.
WMFormer++: Nested Transformer for Visible Watermark Removal via Implict Joint Learning
Aug 22, 2023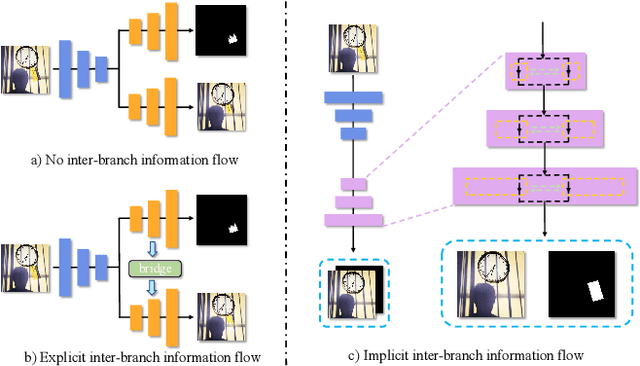
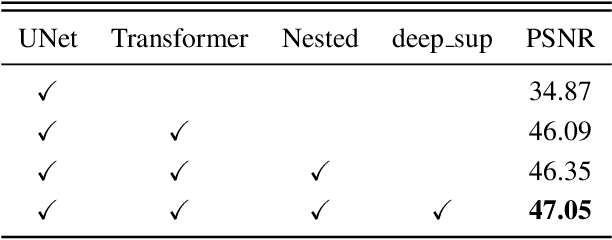

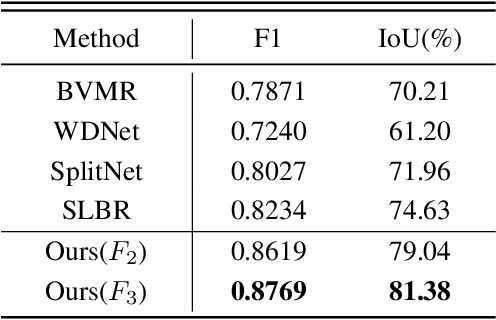
Watermarking serves as a widely adopted approach to safeguard media copyright. In parallel, the research focus has extended to watermark removal techniques, offering an adversarial means to enhance watermark robustness and foster advancements in the watermarking field. Existing watermark removal methods mainly rely on UNet with task-specific decoder branches--one for watermark localization and the other for background image restoration. However, watermark localization and background restoration are not isolated tasks; precise watermark localization inherently implies regions necessitating restoration, and the background restoration process contributes to more accurate watermark localization. To holistically integrate information from both branches, we introduce an implicit joint learning paradigm. This empowers the network to autonomously navigate the flow of information between implicit branches through a gate mechanism. Furthermore, we employ cross-channel attention to facilitate local detail restoration and holistic structural comprehension, while harnessing nested structures to integrate multi-scale information. Extensive experiments are conducted on various challenging benchmarks to validate the effectiveness of our proposed method. The results demonstrate our approach's remarkable superiority, surpassing existing state-of-the-art methods by a large margin.
Three Towers: Flexible Contrastive Learning with Pretrained Image Models
May 29, 2023
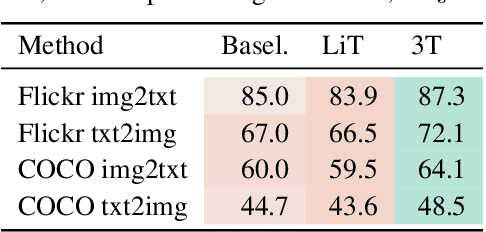
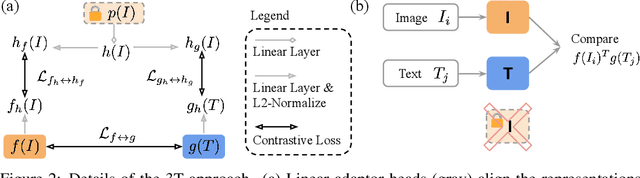
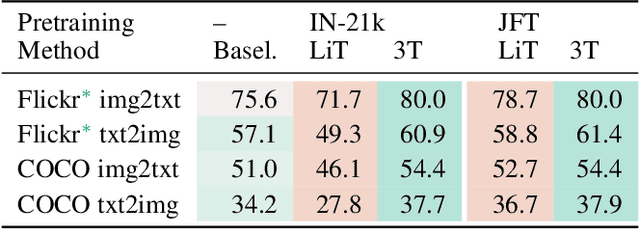
We introduce Three Towers (3T), a flexible method to improve the contrastive learning of vision-language models by incorporating pretrained image classifiers. While contrastive models are usually trained from scratch, LiT (Zhai et al., 2022) has recently shown performance gains from using pretrained classifier embeddings. However, LiT directly replaces the image tower with the frozen embeddings, excluding any potential benefits of contrastively training the image tower. With 3T, we propose a more flexible strategy that allows the image tower to benefit from both pretrained embeddings and contrastive training. To achieve this, we introduce a third tower that contains the frozen pretrained embeddings, and we encourage alignment between this third tower and the main image-text towers. Empirically, 3T consistently improves over LiT and the CLIP-style from-scratch baseline for retrieval tasks. For classification, 3T reliably improves over the from-scratch baseline, and while it underperforms relative to LiT for JFT-pretrained models, it outperforms LiT for ImageNet-21k and Places365 pretraining.
Self-Supervised Learning for Endoscopic Video Analysis
Aug 23, 2023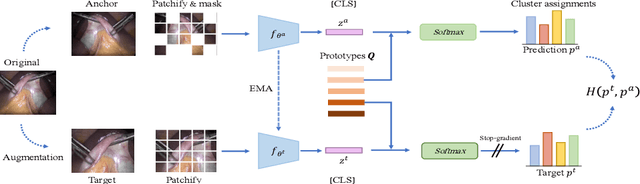
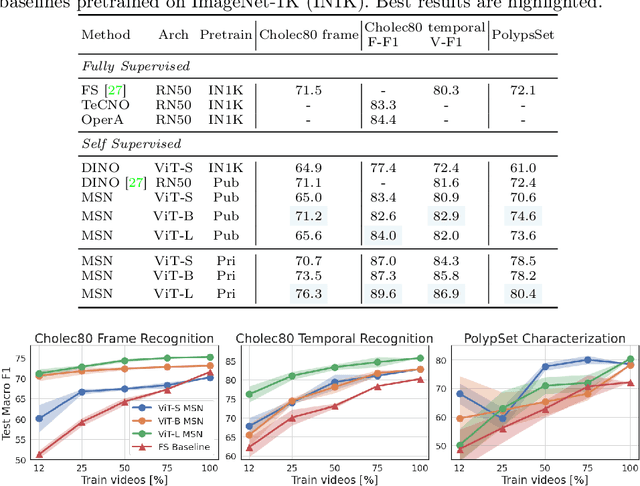
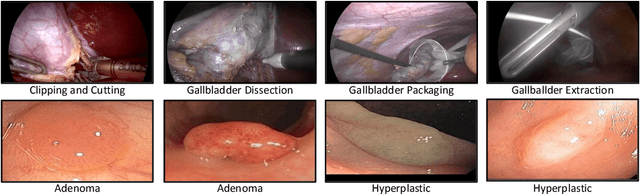
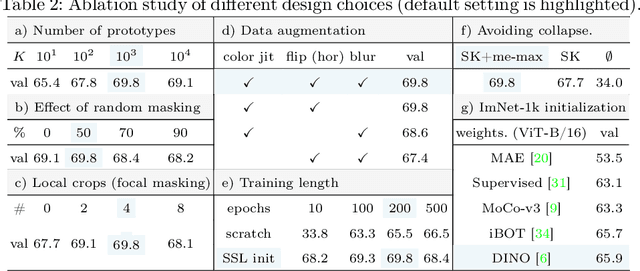
Self-supervised learning (SSL) has led to important breakthroughs in computer vision by allowing learning from large amounts of unlabeled data. As such, it might have a pivotal role to play in biomedicine where annotating data requires a highly specialized expertise. Yet, there are many healthcare domains for which SSL has not been extensively explored. One such domain is endoscopy, minimally invasive procedures which are commonly used to detect and treat infections, chronic inflammatory diseases or cancer. In this work, we study the use of a leading SSL framework, namely Masked Siamese Networks (MSNs), for endoscopic video analysis such as colonoscopy and laparoscopy. To fully exploit the power of SSL, we create sizable unlabeled endoscopic video datasets for training MSNs. These strong image representations serve as a foundation for secondary training with limited annotated datasets, resulting in state-of-the-art performance in endoscopic benchmarks like surgical phase recognition during laparoscopy and colonoscopic polyp characterization. Additionally, we achieve a 50% reduction in annotated data size without sacrificing performance. Thus, our work provides evidence that SSL can dramatically reduce the need of annotated data in endoscopy.
Anisotropic Hybrid Networks for liver tumor segmentation with uncertainty quantification
Aug 23, 2023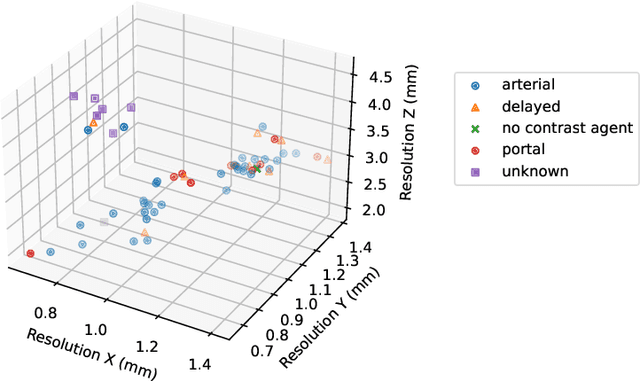
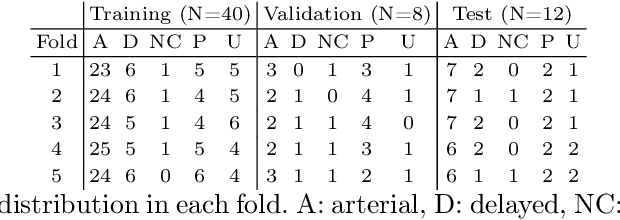
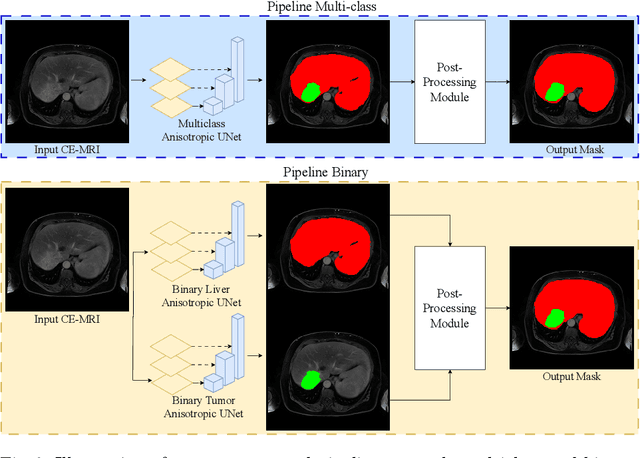
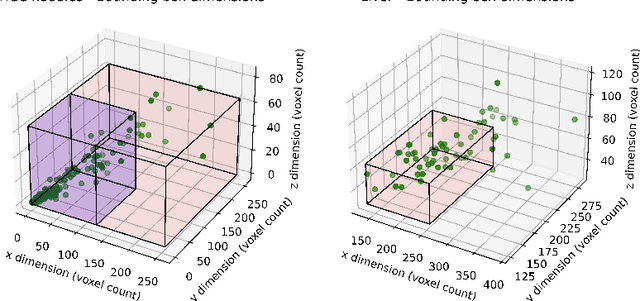
The burden of liver tumors is important, ranking as the fourth leading cause of cancer mortality. In case of hepatocellular carcinoma (HCC), the delineation of liver and tumor on contrast-enhanced magnetic resonance imaging (CE-MRI) is performed to guide the treatment strategy. As this task is time-consuming, needs high expertise and could be subject to inter-observer variability there is a strong need for automatic tools. However, challenges arise from the lack of available training data, as well as the high variability in terms of image resolution and MRI sequence. In this work we propose to compare two different pipelines based on anisotropic models to obtain the segmentation of the liver and tumors. The first pipeline corresponds to a baseline multi-class model that performs the simultaneous segmentation of the liver and tumor classes. In the second approach, we train two distinct binary models, one segmenting the liver only and the other the tumors. Our results show that both pipelines exhibit different strengths and weaknesses. Moreover we propose an uncertainty quantification strategy allowing the identification of potential false positive tumor lesions. Both solutions were submitted to the MICCAI 2023 Atlas challenge regarding liver and tumor segmentation.