 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTECCI: Tricky Edits of Collected and Curated Images
May 31, 2026Despite tremendous recent progress, current text-guided image editing methods still struggle with many aspects of editing involving instruction following, minimally editing the source image, and ensuring high visual quality. These problems are especially apparent when the requested edit is challenging, such as those that involve position, motion, viewpoint, scale and creative edits. To systematically test generative image editors, we propose a novel image editing benchmark -- TECCI: Tricky Edits of Collected and Curated Images. TECCI consists of a completely new set of images we are releasing. The images in TECCI span 7 image categories. The images and these categories were curated intentionally to target weaknesses of existing methods. The edit instructions in TECCI are automatically generated by Gemini, covering 5 edit types per source image. We also curated a set of 530 images for which we created challenging manually written edit instructions. Overall, TECCI contains 7550 pairs of images and edit instructions. We conduct human evaluations of five leading image editing models on TECCI. Humans judge outputs along three dimensions: 1) instruction following, 2) minimality of the edits, and 3) visual quality. To scale-up the evaluation, we also build an auto-rater using Gemini that achieves 74.7% accuracy in matching human evaluations. Our evaluations reveal that: 1) none of the models exceed a 22% overall success rate, demonstrating the challenging nature of TECCI, 2) Nano Banana Pro is the best performing model overall, 3) models perform significantly better at instruction following compared to minimal edits and visual quality, 4) models struggle with editing architecture and nature images which require strong understanding of spatial layout and intricate visual details. 5) reasoning and creative edits are the most difficult, whereas color and appearance edits are the easiest.
Editor's Choice: Evaluating Abstract Intent in Image Editing through Atomic Entity Analysis
May 14, 2026Humans naturally communicate through abstract concepts like "mood". However, current image editing benchmarks focus primarily on explicit, literal commands, leaving abstract instructions largely underexplored. In this work, we first formalize the definition and taxonomy of abstract image editing. To measure instruction-following in this challenging domain, we introduce Entity-Rubrics, a framework that breaks down abstract edits into individual, entity-level assessments and achieves strong correlation with human judgment. Alongside this framework, we contribute AbstractEdit, the first benchmark dedicated to abstract image editing across diverse real-world scenes. Evaluating 11 leading models on this dataset reveals a fundamental challenge: standard architectures struggle to balance intent and preservation, commonly defaulting to under-editing or over-editing. Our analysis demonstrates that driving meaningful improvements relies heavily on integrating advanced LLM text encoders and iterative thinking. Looking forward, our entity-based paradigm can generalize beyond assessment to serve as a reward model, enable models to correctly interpret abstract communication, or highlight specific failures in test-time critique loops. Ultimately, we hope this work serves as a stepping stone toward seamless multimodal interaction, closing the gap between rigid machine execution and the natural, open-ended way humans communicate.
A conformalized learning of a prediction set with applications to medical imaging classification
Aug 09, 2024

Medical imaging classifiers can achieve high predictive accuracy, but quantifying their uncertainty remains an unresolved challenge, which prevents their deployment in medical clinics. We present an algorithm that can modify any classifier to produce a prediction set containing the true label with a user-specified probability, such as 90%. We train a network to predict an instance-based version of the Conformal Prediction threshold. The threshold is then conformalized to ensure the required coverage. We applied the proposed algorithm to several standard medical imaging classification datasets. The experimental results demonstrate that our method outperforms current approaches in terms of smaller average size of the prediction set while maintaining the desired coverage.
On the Semantic Latent Space of Diffusion-Based Text-to-Speech Models
Feb 19, 2024



The incorporation of Denoising Diffusion Models (DDMs) in the Text-to-Speech (TTS) domain is rising, providing great value in synthesizing high quality speech. Although they exhibit impressive audio quality, the extent of their semantic capabilities is unknown, and controlling their synthesized speech's vocal properties remains a challenge. Inspired by recent advances in image synthesis, we explore the latent space of frozen TTS models, which is composed of the latent bottleneck activations of the DDM's denoiser. We identify that this space contains rich semantic information, and outline several novel methods for finding semantic directions within it, both supervised and unsupervised. We then demonstrate how these enable off-the-shelf audio editing, without any further training, architectural changes or data requirements. We present evidence of the semantic and acoustic qualities of the edited audio, and provide supplemental samples: https://latent-analysis-grad-tts.github.io/speech-samples/.
Weakly-Supervised Surgical Phase Recognition
Oct 26, 2023


A key element of computer-assisted surgery systems is phase recognition of surgical videos. Existing phase recognition algorithms require frame-wise annotation of a large number of videos, which is time and money consuming. In this work we join concepts of graph segmentation with self-supervised learning to derive a random-walk solution for per-frame phase prediction. Furthermore, we utilize within our method two forms of weak supervision: sparse timestamps or few-shot learning. The proposed algorithm enjoys low complexity and can operate in lowdata regimes. We validate our method by running experiments with the public Cholec80 dataset of laparoscopic cholecystectomy videos, demonstrating promising performance in multiple setups.
Efficient Discovery and Effective Evaluation of Visual Perceptual Similarity: A Benchmark and Beyond
Aug 28, 2023



Visual similarities discovery (VSD) is an important task with broad e-commerce applications. Given an image of a certain object, the goal of VSD is to retrieve images of different objects with high perceptual visual similarity. Although being a highly addressed problem, the evaluation of proposed methods for VSD is often based on a proxy of an identification-retrieval task, evaluating the ability of a model to retrieve different images of the same object. We posit that evaluating VSD methods based on identification tasks is limited, and faithful evaluation must rely on expert annotations. In this paper, we introduce the first large-scale fashion visual similarity benchmark dataset, consisting of more than 110K expert-annotated image pairs. Besides this major contribution, we share insight from the challenges we faced while curating this dataset. Based on these insights, we propose a novel and efficient labeling procedure that can be applied to any dataset. Our analysis examines its limitations and inductive biases, and based on these findings, we propose metrics to mitigate those limitations. Though our primary focus lies on visual similarity, the methodologies we present have broader applications for discovering and evaluating perceptual similarity across various domains.
Self-Supervised Learning for Endoscopic Video Analysis
Aug 23, 2023Self-supervised learning (SSL) has led to important breakthroughs in computer vision by allowing learning from large amounts of unlabeled data. As such, it might have a pivotal role to play in biomedicine where annotating data requires a highly specialized expertise. Yet, there are many healthcare domains for which SSL has not been extensively explored. One such domain is endoscopy, minimally invasive procedures which are commonly used to detect and treat infections, chronic inflammatory diseases or cancer. In this work, we study the use of a leading SSL framework, namely Masked Siamese Networks (MSNs), for endoscopic video analysis such as colonoscopy and laparoscopy. To fully exploit the power of SSL, we create sizable unlabeled endoscopic video datasets for training MSNs. These strong image representations serve as a foundation for secondary training with limited annotated datasets, resulting in state-of-the-art performance in endoscopic benchmarks like surgical phase recognition during laparoscopy and colonoscopic polyp characterization. Additionally, we achieve a 50% reduction in annotated data size without sacrificing performance. Thus, our work provides evidence that SSL can dramatically reduce the need of annotated data in endoscopy.
Cold Item Integration in Deep Hybrid Recommenders via Tunable Stochastic Gates
Dec 12, 2021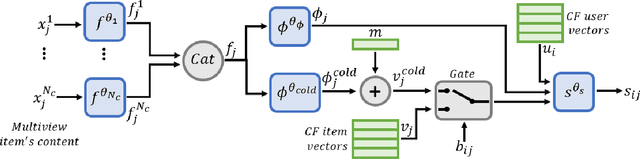
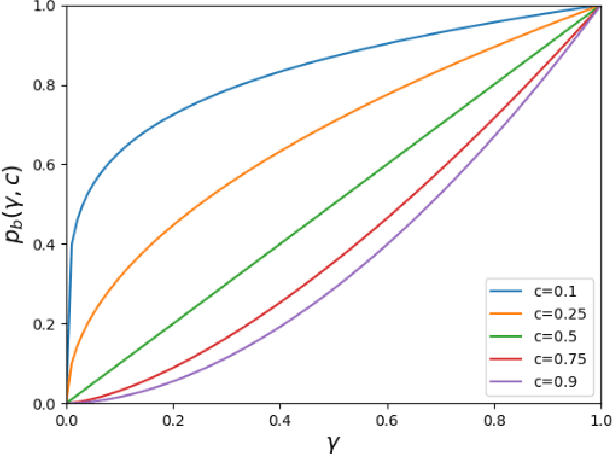
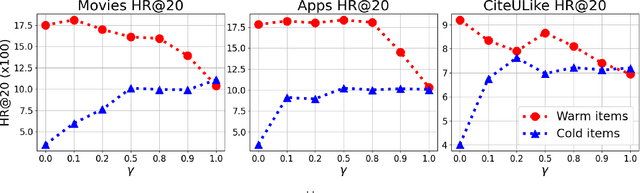
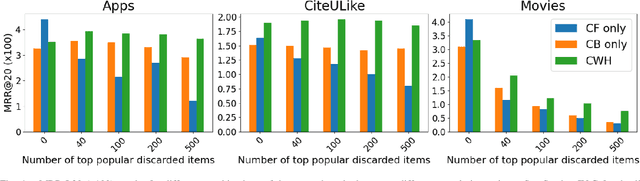
A major challenge in collaborative filtering methods is how to produce recommendations for cold items (items with no ratings), or integrate cold item into an existing catalog. Over the years, a variety of hybrid recommendation models have been proposed to address this problem by utilizing items' metadata and content along with their ratings or usage patterns. In this work, we wish to revisit the cold start problem in order to draw attention to an overlooked challenge: the ability to integrate and balance between (regular) warm items and completely cold items. In this case, two different challenges arise: (1) preserving high quality performance on warm items, while (2) learning to promote cold items to relevant users. First, we show that these two objectives are in fact conflicting, and the balance between them depends on the business needs and the application at hand. Next, we propose a novel hybrid recommendation algorithm that bridges these two conflicting objectives and enables a harmonized balance between preserving high accuracy for warm items while effectively promoting completely cold items. We demonstrate the effectiveness of the proposed algorithm on movies, apps, and articles recommendations, and provide an empirical analysis of the cold-warm trade-off.