 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-supervised Domain Adaptive Medical Image Segmentation through Consistency Regularized Disentangled Contrastive Learning
Jul 06, 2023
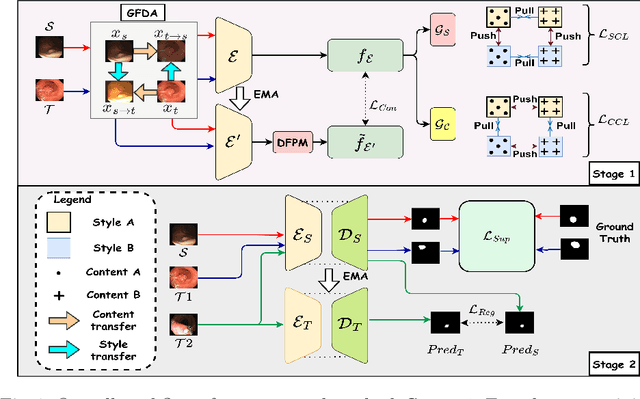
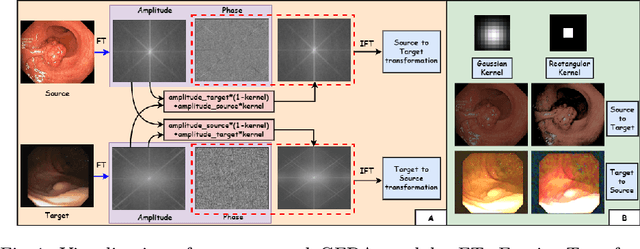

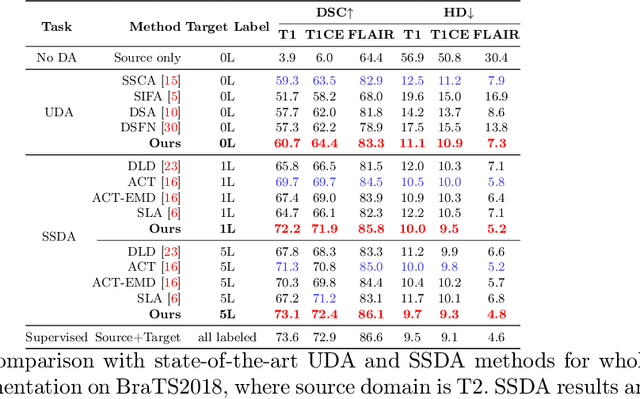
Although unsupervised domain adaptation (UDA) is a promising direction to alleviate domain shift, they fall short of their supervised counterparts. In this work, we investigate relatively less explored semi-supervised domain adaptation (SSDA) for medical image segmentation, where access to a few labeled target samples can improve the adaptation performance substantially. Specifically, we propose a two-stage training process. First, an encoder is pre-trained in a self-learning paradigm using a novel domain-content disentangled contrastive learning (CL) along with a pixel-level feature consistency constraint. The proposed CL enforces the encoder to learn discriminative content-specific but domain-invariant semantics on a global scale from the source and target images, whereas consistency regularization enforces the mining of local pixel-level information by maintaining spatial sensitivity. This pre-trained encoder, along with a decoder, is further fine-tuned for the downstream task, (i.e. pixel-level segmentation) using a semi-supervised setting. Furthermore, we experimentally validate that our proposed method can easily be extended for UDA settings, adding to the superiority of the proposed strategy. Upon evaluation on two domain adaptive image segmentation tasks, our proposed method outperforms the SoTA methods, both in SSDA and UDA settings. Code is available at https://github.com/hritam-98/GFDA-disentangled
DGCNet: An Efficient 3D-Densenet based on Dynamic Group Convolution for Hyperspectral Remote Sensing Image Classification
Jul 13, 2023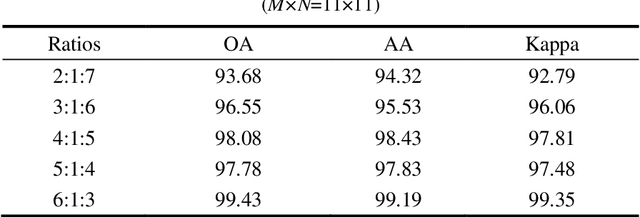
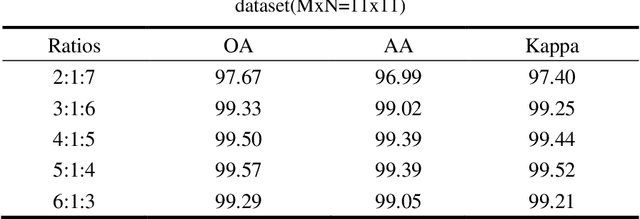
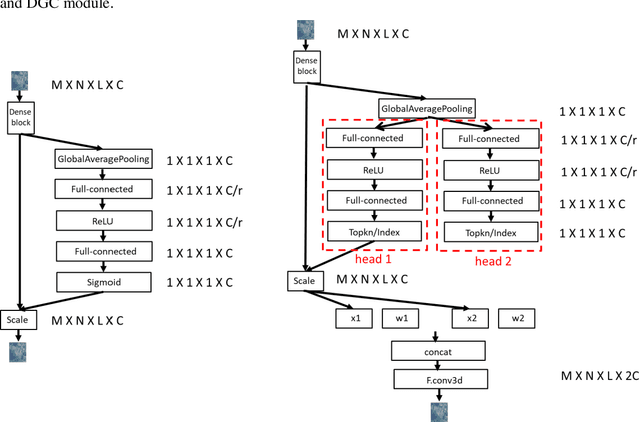
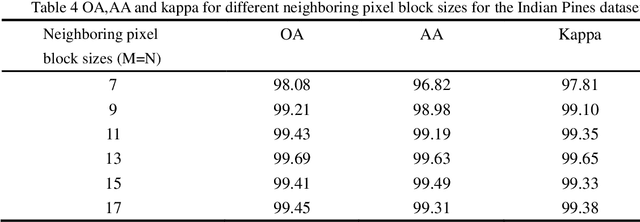
Deep neural networks face many problems in the field of hyperspectral image classification, lack of effective utilization of spatial spectral information, gradient disappearance and overfitting as the model depth increases. In order to accelerate the deployment of the model on edge devices with strict latency requirements and limited computing power, we introduce a lightweight model based on the improved 3D-Densenet model and designs DGCNet. It improves the disadvantage of group convolution. Referring to the idea of dynamic network, dynamic group convolution(DGC) is designed on 3d convolution kernel. DGC introduces small feature selectors for each grouping to dynamically decide which part of the input channel to connect based on the activations of all input channels. Multiple groups can capture different and complementary visual and semantic features of input images, allowing convolution neural network(CNN) to learn rich features. 3D convolution extracts high-dimensional and redundant hyperspectral data, and there is also a lot of redundant information between convolution kernels. DGC module allows 3D-Densenet to select channel information with richer semantic features and discard inactive regions. The 3D-CNN passing through the DGC module can be regarded as a pruned network. DGC not only allows 3D-CNN to complete sufficient feature extraction, but also takes into account the requirements of speed and calculation amount. The inference speed and accuracy have been improved, with outstanding performance on the IN, Pavia and KSC datasets, ahead of the mainstream hyperspectral image classification methods.
How To Overcome Confirmation Bias in Semi-Supervised Image Classification By Active Learning
Aug 16, 2023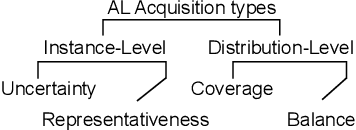
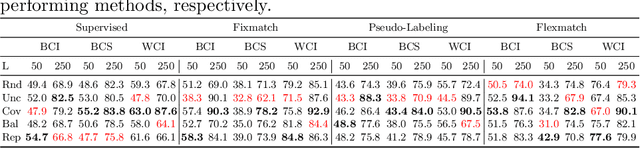
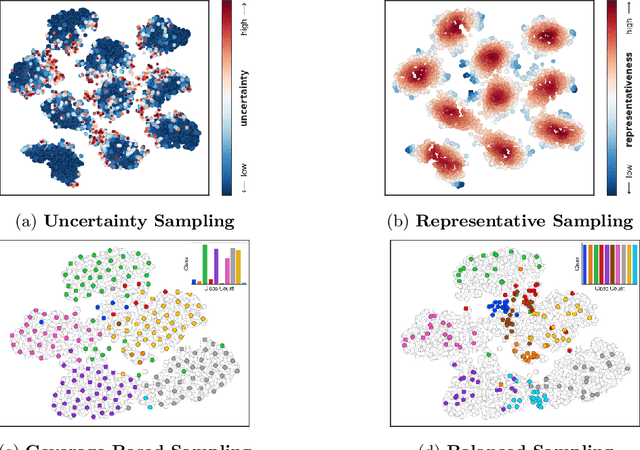
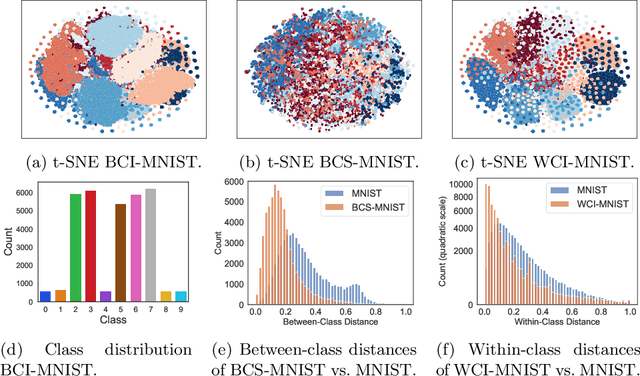
Do we need active learning? The rise of strong deep semi-supervised methods raises doubt about the usability of active learning in limited labeled data settings. This is caused by results showing that combining semi-supervised learning (SSL) methods with a random selection for labeling can outperform existing active learning (AL) techniques. However, these results are obtained from experiments on well-established benchmark datasets that can overestimate the external validity. However, the literature lacks sufficient research on the performance of active semi-supervised learning methods in realistic data scenarios, leaving a notable gap in our understanding. Therefore we present three data challenges common in real-world applications: between-class imbalance, within-class imbalance, and between-class similarity. These challenges can hurt SSL performance due to confirmation bias. We conduct experiments with SSL and AL on simulated data challenges and find that random sampling does not mitigate confirmation bias and, in some cases, leads to worse performance than supervised learning. In contrast, we demonstrate that AL can overcome confirmation bias in SSL in these realistic settings. Our results provide insights into the potential of combining active and semi-supervised learning in the presence of common real-world challenges, which is a promising direction for robust methods when learning with limited labeled data in real-world applications.
Automatic Generation of Semantic Parts for Face Image Synthesis
Jul 11, 2023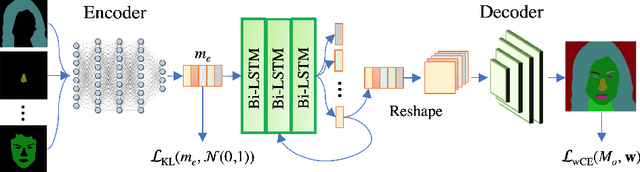
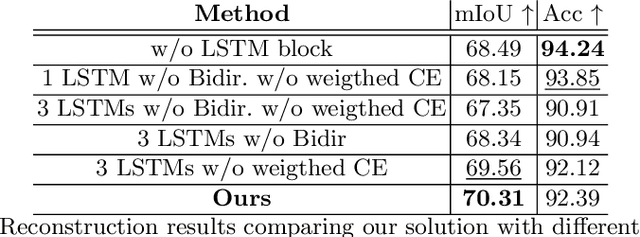
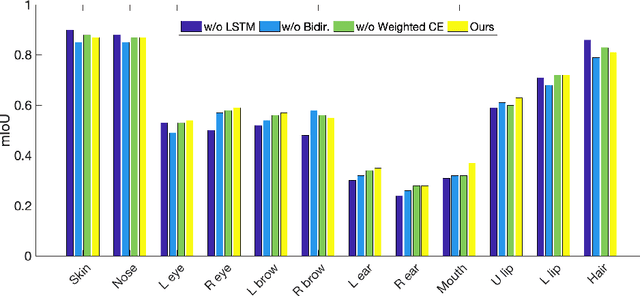
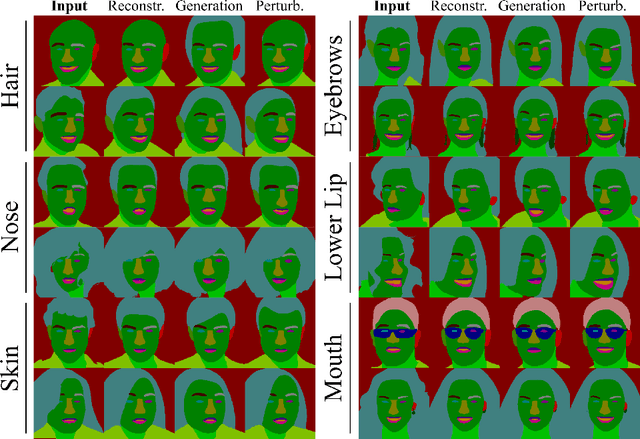
Semantic image synthesis (SIS) refers to the problem of generating realistic imagery given a semantic segmentation mask that defines the spatial layout of object classes. Most of the approaches in the literature, other than the quality of the generated images, put effort in finding solutions to increase the generation diversity in terms of style i.e. texture. However, they all neglect a different feature, which is the possibility of manipulating the layout provided by the mask. Currently, the only way to do so is manually by means of graphical users interfaces. In this paper, we describe a network architecture to address the problem of automatically manipulating or generating the shape of object classes in semantic segmentation masks, with specific focus on human faces. Our proposed model allows embedding the mask class-wise into a latent space where each class embedding can be independently edited. Then, a bi-directional LSTM block and a convolutional decoder output a new, locally manipulated mask. We report quantitative and qualitative results on the CelebMask-HQ dataset, which show our model can both faithfully reconstruct and modify a segmentation mask at the class level. Also, we show our model can be put before a SIS generator, opening the way to a fully automatic generation control of both shape and texture. Code available at https://github.com/TFonta/Semantic-VAE.
Chatting Makes Perfect -- Chat-based Image Retrieval
May 31, 2023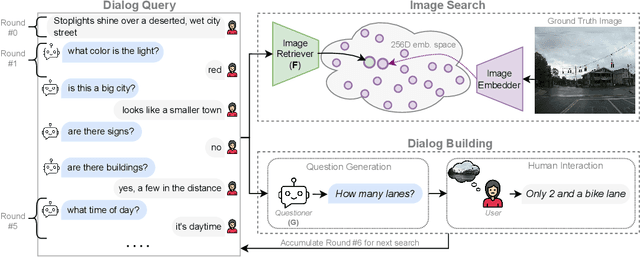
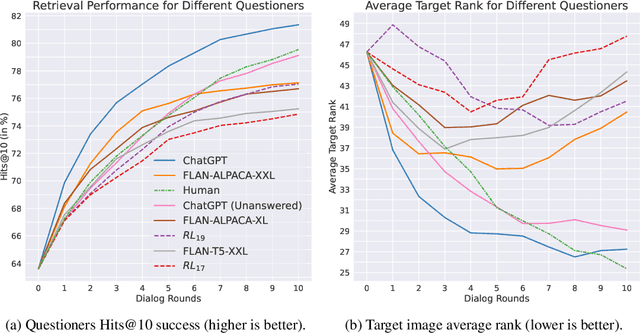
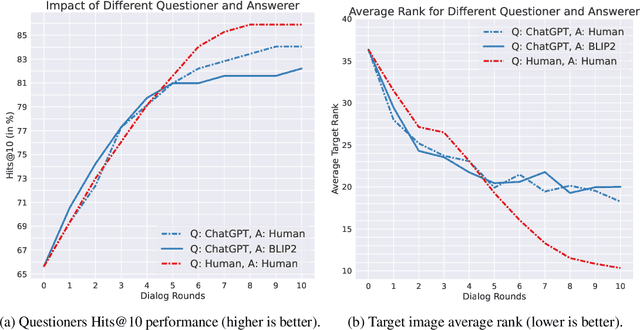
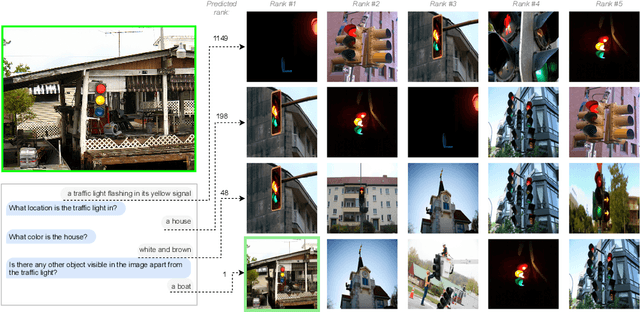
Chats emerge as an effective user-friendly approach for information retrieval, and are successfully employed in many domains, such as customer service, healthcare, and finance. However, existing image retrieval approaches typically address the case of a single query-to-image round, and the use of chats for image retrieval has been mostly overlooked. In this work, we introduce ChatIR: a chat-based image retrieval system that engages in a conversation with the user to elicit information, in addition to an initial query, in order to clarify the user's search intent. Motivated by the capabilities of today's foundation models, we leverage Large Language Models to generate follow-up questions to an initial image description. These questions form a dialog with the user in order to retrieve the desired image from a large corpus. In this study, we explore the capabilities of such a system tested on a large dataset and reveal that engaging in a dialog yields significant gains in image retrieval. We start by building an evaluation pipeline from an existing manually generated dataset and explore different modules and training strategies for ChatIR. Our comparison includes strong baselines derived from related applications trained with Reinforcement Learning. Our system is capable of retrieving the target image from a pool of 50K images with over 78% success rate after 5 dialogue rounds, compared to 75% when questions are asked by humans, and 64% for a single shot text-to-image retrieval. Extensive evaluations reveal the strong capabilities and examine the limitations of CharIR under different settings.
CNN based Cuneiform Sign Detection Learned from Annotated 3D Renderings and Mapped Photographs with Illumination Augmentation
Aug 22, 2023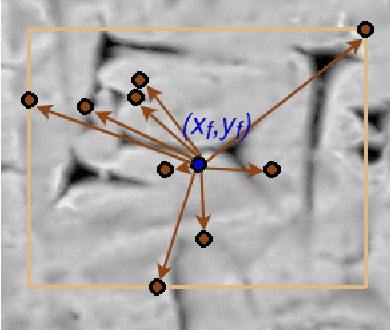

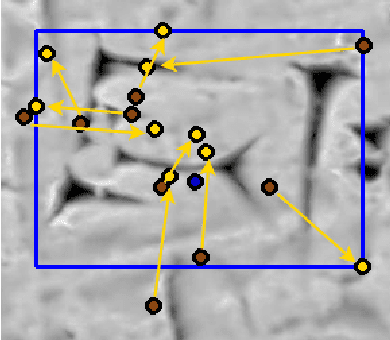
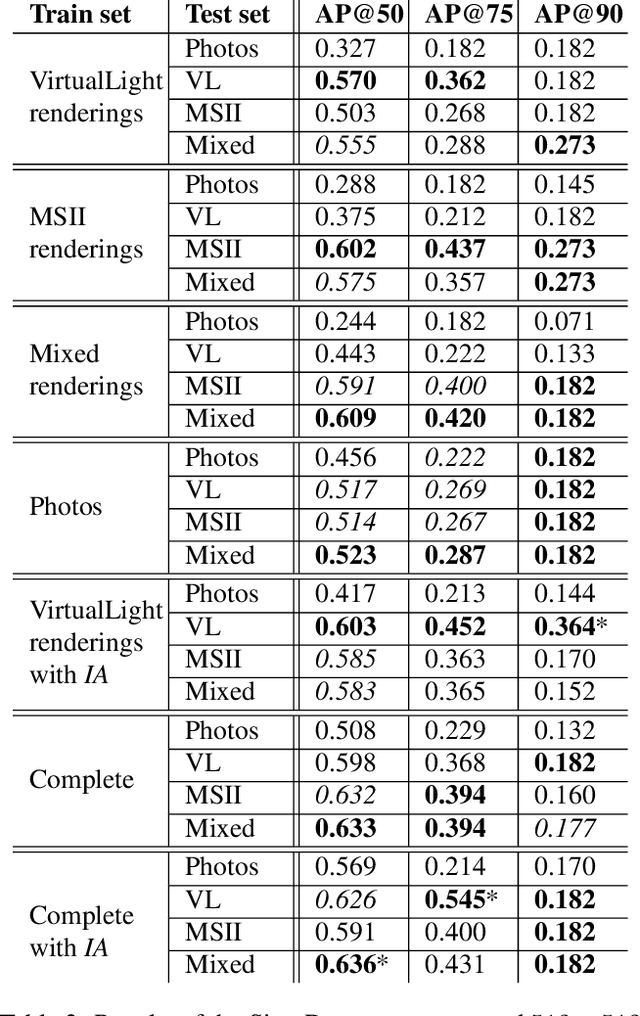
Motivated by the challenges of the Digital Ancient Near Eastern Studies (DANES) community, we develop digital tools for processing cuneiform script being a 3D script imprinted into clay tablets used for more than three millennia and at least eight major languages. It consists of thousands of characters that have changed over time and space. Photographs are the most common representations usable for machine learning, while ink drawings are prone to interpretation. Best suited 3D datasets that are becoming available. We created and used the HeiCuBeDa and MaiCuBeDa datasets, which consist of around 500 annotated tablets. For our novel OCR-like approach to mixed image data, we provide an additional mapping tool for transferring annotations between 3D renderings and photographs. Our sign localization uses a RepPoints detector to predict the locations of characters as bounding boxes. We use image data from GigaMesh's MSII (curvature, see https://gigamesh.eu) based rendering, Phong-shaded 3D models, and photographs as well as illumination augmentation. The results show that using rendered 3D images for sign detection performs better than other work on photographs. In addition, our approach gives reasonably good results for photographs only, while it is best used for mixed datasets. More importantly, the Phong renderings, and especially the MSII renderings, improve the results on photographs, which is the largest dataset on a global scale.
Two-in-One Depth: Bridging the Gap Between Monocular and Binocular Self-supervised Depth Estimation
Sep 02, 2023Monocular and binocular self-supervised depth estimations are two important and related tasks in computer vision, which aim to predict scene depths from single images and stereo image pairs respectively. In literature, the two tasks are usually tackled separately by two different kinds of models, and binocular models generally fail to predict depth from single images, while the prediction accuracy of monocular models is generally inferior to binocular models. In this paper, we propose a Two-in-One self-supervised depth estimation network, called TiO-Depth, which could not only compatibly handle the two tasks, but also improve the prediction accuracy. TiO-Depth employs a Siamese architecture and each sub-network of it could be used as a monocular depth estimation model. For binocular depth estimation, a Monocular Feature Matching module is proposed for incorporating the stereo knowledge between the two images, and the full TiO-Depth is used to predict depths. We also design a multi-stage joint-training strategy for improving the performances of TiO-Depth in both two tasks by combining the relative advantages of them. Experimental results on the KITTI, Cityscapes, and DDAD datasets demonstrate that TiO-Depth outperforms both the monocular and binocular state-of-the-art methods in most cases, and further verify the feasibility of a two-in-one network for monocular and binocular depth estimation. The code is available at https://github.com/ZM-Zhou/TiO-Depth_pytorch.
Diffusion Self-Guidance for Controllable Image Generation
Jun 11, 2023
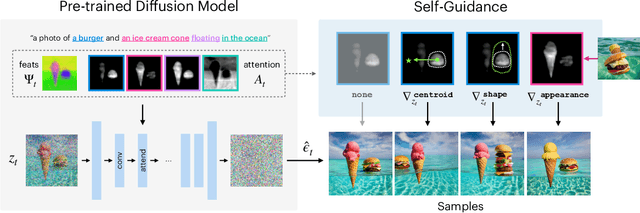


Large-scale generative models are capable of producing high-quality images from detailed text descriptions. However, many aspects of an image are difficult or impossible to convey through text. We introduce self-guidance, a method that provides greater control over generated images by guiding the internal representations of diffusion models. We demonstrate that properties such as the shape, location, and appearance of objects can be extracted from these representations and used to steer sampling. Self-guidance works similarly to classifier guidance, but uses signals present in the pretrained model itself, requiring no additional models or training. We show how a simple set of properties can be composed to perform challenging image manipulations, such as modifying the position or size of objects, merging the appearance of objects in one image with the layout of another, composing objects from many images into one, and more. We also show that self-guidance can be used to edit real images. For results and an interactive demo, see our project page at https://dave.ml/selfguidance/
RT-MonoDepth: Real-time Monocular Depth Estimation on Embedded Systems
Aug 21, 2023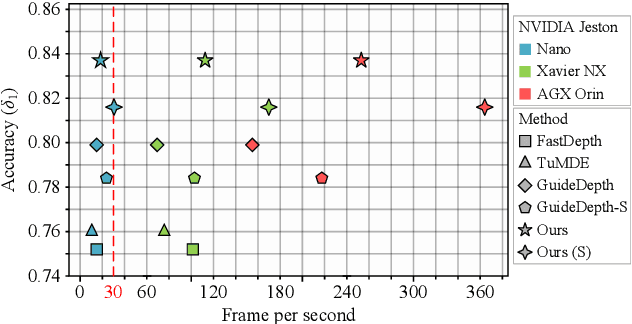
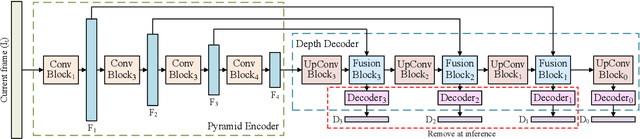
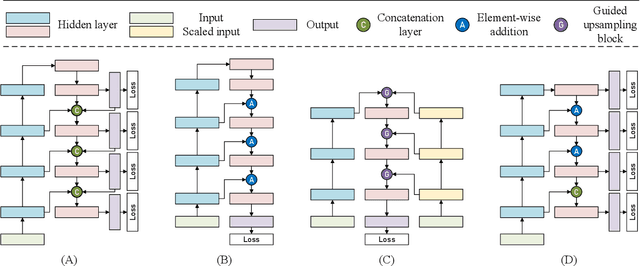

Depth sensing is a crucial function of unmanned aerial vehicles and autonomous vehicles. Due to the small size and simple structure of monocular cameras, there has been a growing interest in depth estimation from a single RGB image. However, state-of-the-art monocular CNN-based depth estimation methods using fairly complex deep neural networks are too slow for real-time inference on embedded platforms. This paper addresses the problem of real-time depth estimation on embedded systems. We propose two efficient and lightweight encoder-decoder network architectures, RT-MonoDepth and RT-MonoDepth-S, to reduce computational complexity and latency. Our methodologies demonstrate that it is possible to achieve similar accuracy as prior state-of-the-art works on depth estimation at a faster inference speed. Our proposed networks, RT-MonoDepth and RT-MonoDepth-S, runs at 18.4\&30.5 FPS on NVIDIA Jetson Nano and 253.0\&364.1 FPS on NVIDIA Jetson AGX Orin on a single RGB image of resolution 640$\times$192, and achieve relative state-of-the-art accuracy on the KITTI dataset. To the best of the authors' knowledge, this paper achieves the best accuracy and fastest inference speed compared with existing fast monocular depth estimation methods.
EigenPlaces: Training Viewpoint Robust Models for Visual Place Recognition
Aug 21, 2023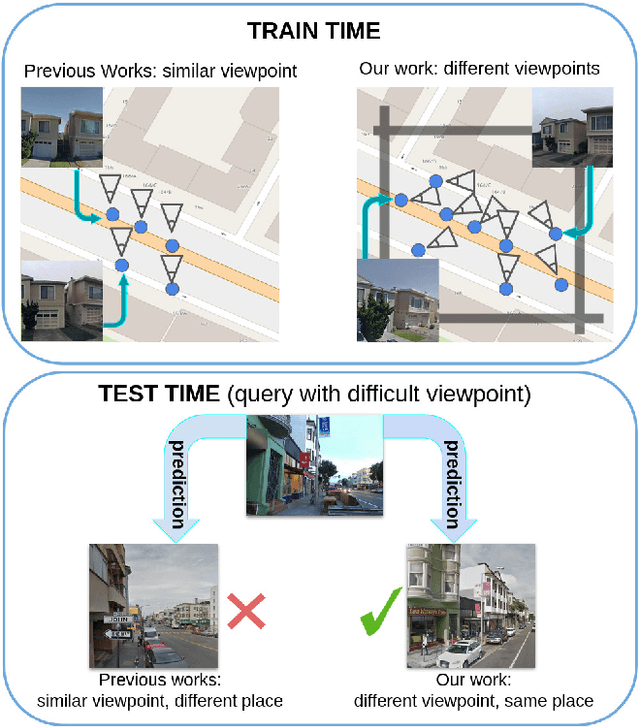



Visual Place Recognition is a task that aims to predict the place of an image (called query) based solely on its visual features. This is typically done through image retrieval, where the query is matched to the most similar images from a large database of geotagged photos, using learned global descriptors. A major challenge in this task is recognizing places seen from different viewpoints. To overcome this limitation, we propose a new method, called EigenPlaces, to train our neural network on images from different point of views, which embeds viewpoint robustness into the learned global descriptors. The underlying idea is to cluster the training data so as to explicitly present the model with different views of the same points of interest. The selection of this points of interest is done without the need for extra supervision. We then present experiments on the most comprehensive set of datasets in literature, finding that EigenPlaces is able to outperform previous state of the art on the majority of datasets, while requiring 60\% less GPU memory for training and using 50\% smaller descriptors. The code and trained models for EigenPlaces are available at {\small{\url{https://github.com/gmberton/EigenPlaces}}}, while results with any other baseline can be computed with the codebase at {\small{\url{https://github.com/gmberton/auto_VPR}}}.