 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Boosting Adversarial Transferability by Block Shuffle and Rotation
Aug 22, 2023

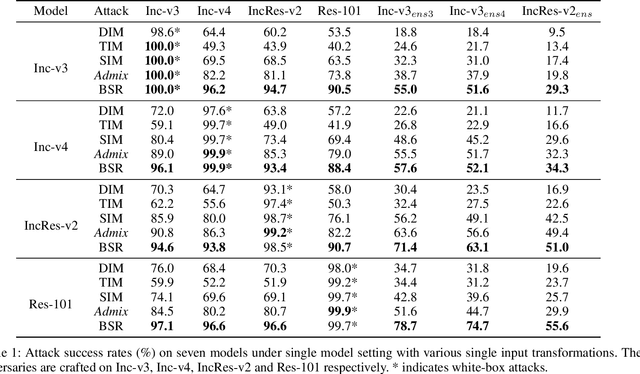
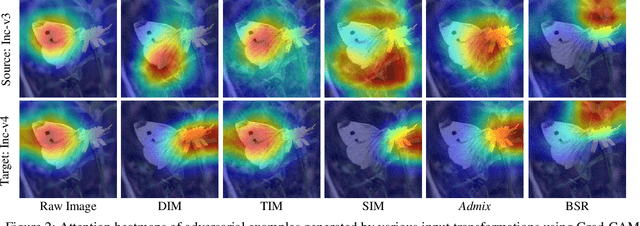
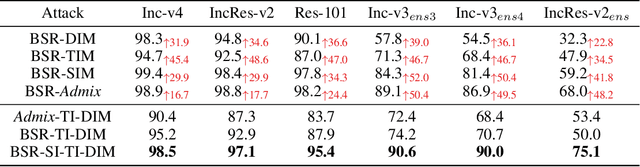
Adversarial examples mislead deep neural networks with imperceptible perturbations and have brought significant threats to deep learning. An important aspect is their transferability, which refers to their ability to deceive other models, thus enabling attacks in the black-box setting. Though various methods have been proposed to boost transferability, the performance still falls short compared with white-box attacks. In this work, we observe that existing input transformation based attacks, one of the mainstream transfer-based attacks, result in different attention heatmaps on various models, which might limit the transferability. We also find that breaking the intrinsic relation of the image can disrupt the attention heatmap of the original image. Based on this finding, we propose a novel input transformation based attack called block shuffle and rotation (BSR). Specifically, BSR splits the input image into several blocks, then randomly shuffles and rotates these blocks to construct a set of new images for gradient calculation. Empirical evaluations on the ImageNet dataset demonstrate that BSR could achieve significantly better transferability than the existing input transformation based methods under single-model and ensemble-model settings. Combining BSR with the current input transformation method can further improve the transferability, which significantly outperforms the state-of-the-art methods.
DatasetEquity: Are All Samples Created Equal? In The Quest For Equity Within Datasets
Aug 22, 2023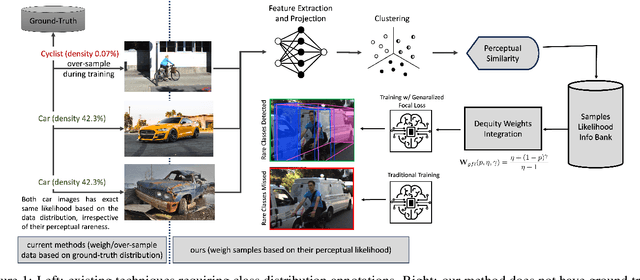

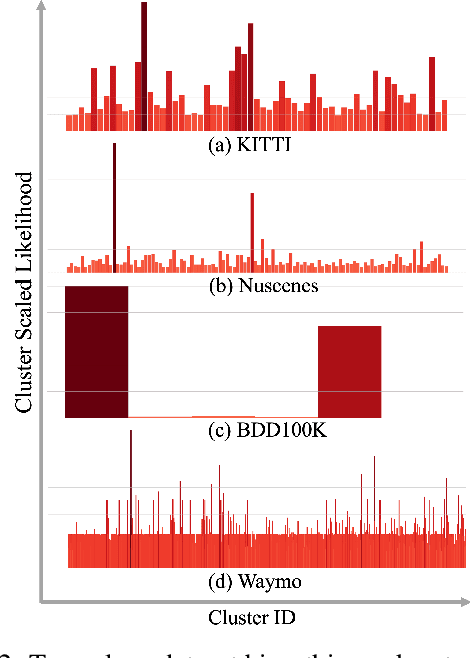
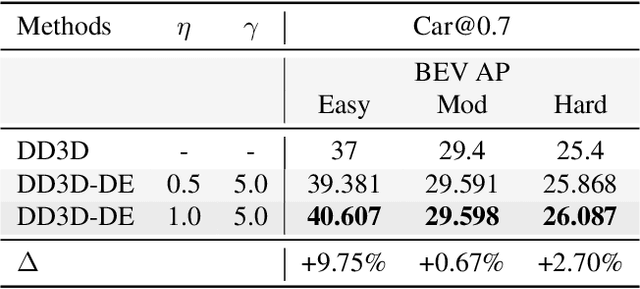
Data imbalance is a well-known issue in the field of machine learning, attributable to the cost of data collection, the difficulty of labeling, and the geographical distribution of the data. In computer vision, bias in data distribution caused by image appearance remains highly unexplored. Compared to categorical distributions using class labels, image appearance reveals complex relationships between objects beyond what class labels provide. Clustering deep perceptual features extracted from raw pixels gives a richer representation of the data. This paper presents a novel method for addressing data imbalance in machine learning. The method computes sample likelihoods based on image appearance using deep perceptual embeddings and clustering. It then uses these likelihoods to weigh samples differently during training with a proposed $\textbf{Generalized Focal Loss}$ function. This loss can be easily integrated with deep learning algorithms. Experiments validate the method's effectiveness across autonomous driving vision datasets including KITTI and nuScenes. The loss function improves state-of-the-art 3D object detection methods, achieving over $200\%$ AP gains on under-represented classes (Cyclist) in the KITTI dataset. The results demonstrate the method is generalizable, complements existing techniques, and is particularly beneficial for smaller datasets and rare classes. Code is available at: https://github.com/towardsautonomy/DatasetEquity
MDTD: A Multi Domain Trojan Detector for Deep Neural Networks
Aug 30, 2023

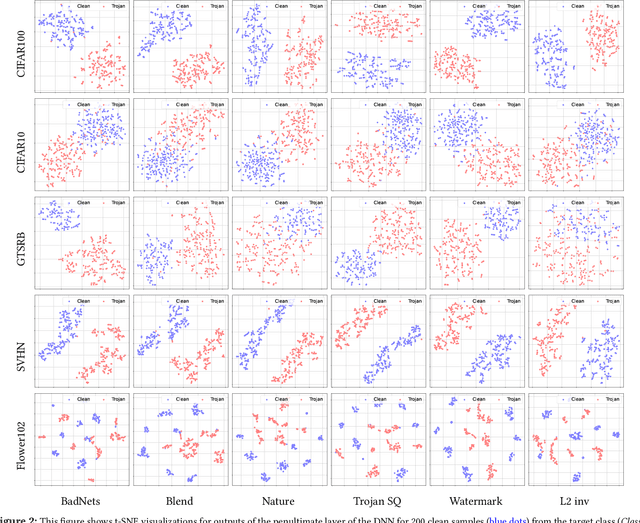

Machine learning models that use deep neural networks (DNNs) are vulnerable to backdoor attacks. An adversary carrying out a backdoor attack embeds a predefined perturbation called a trigger into a small subset of input samples and trains the DNN such that the presence of the trigger in the input results in an adversary-desired output class. Such adversarial retraining however needs to ensure that outputs for inputs without the trigger remain unaffected and provide high classification accuracy on clean samples. In this paper, we propose MDTD, a Multi-Domain Trojan Detector for DNNs, which detects inputs containing a Trojan trigger at testing time. MDTD does not require knowledge of trigger-embedding strategy of the attacker and can be applied to a pre-trained DNN model with image, audio, or graph-based inputs. MDTD leverages an insight that input samples containing a Trojan trigger are located relatively farther away from a decision boundary than clean samples. MDTD estimates the distance to a decision boundary using adversarial learning methods and uses this distance to infer whether a test-time input sample is Trojaned or not. We evaluate MDTD against state-of-the-art Trojan detection methods across five widely used image-based datasets: CIFAR100, CIFAR10, GTSRB, SVHN, and Flowers102; four graph-based datasets: AIDS, WinMal, Toxicant, and COLLAB; and the SpeechCommand audio dataset. MDTD effectively identifies samples that contain different types of Trojan triggers. We evaluate MDTD against adaptive attacks where an adversary trains a robust DNN to increase (decrease) distance of benign (Trojan) inputs from a decision boundary.
Realistic Saliency Guided Image Enhancement
Jun 09, 2023

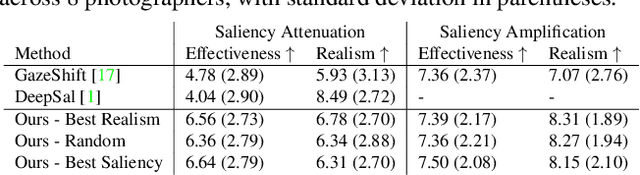
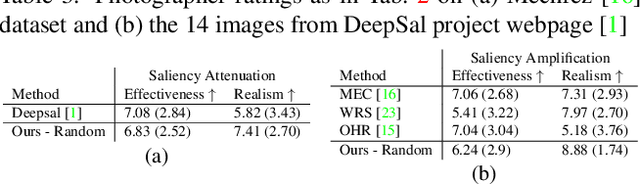
Common editing operations performed by professional photographers include the cleanup operations: de-emphasizing distracting elements and enhancing subjects. These edits are challenging, requiring a delicate balance between manipulating the viewer's attention while maintaining photo realism. While recent approaches can boast successful examples of attention attenuation or amplification, most of them also suffer from frequent unrealistic edits. We propose a realism loss for saliency-guided image enhancement to maintain high realism across varying image types, while attenuating distractors and amplifying objects of interest. Evaluations with professional photographers confirm that we achieve the dual objective of realism and effectiveness, and outperform the recent approaches on their own datasets, while requiring a smaller memory footprint and runtime. We thus offer a viable solution for automating image enhancement and photo cleanup operations.
* For more info visit http://yaksoy.github.io/realisticEditing/
DRMC: A Generalist Model with Dynamic Routing for Multi-Center PET Image Synthesis
Jul 11, 2023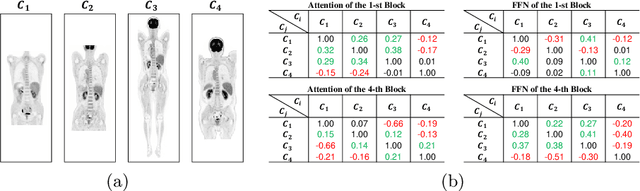

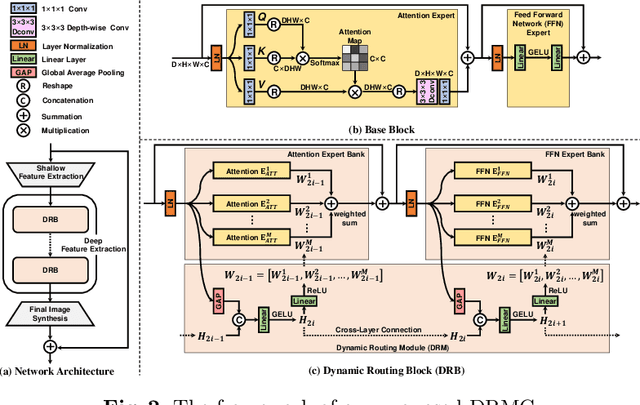
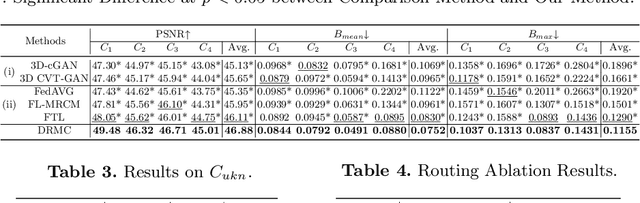
Multi-center positron emission tomography (PET) image synthesis aims at recovering low-dose PET images from multiple different centers. The generalizability of existing methods can still be suboptimal for a multi-center study due to domain shifts, which result from non-identical data distribution among centers with different imaging systems/protocols. While some approaches address domain shifts by training specialized models for each center, they are parameter inefficient and do not well exploit the shared knowledge across centers. To address this, we develop a generalist model that shares architecture and parameters across centers to utilize the shared knowledge. However, the generalist model can suffer from the center interference issue, \textit{i.e.} the gradient directions of different centers can be inconsistent or even opposite owing to the non-identical data distribution. To mitigate such interference, we introduce a novel dynamic routing strategy with cross-layer connections that routes data from different centers to different experts. Experiments show that our generalist model with dynamic routing (DRMC) exhibits excellent generalizability across centers. Code and data are available at: https://github.com/Yaziwel/Multi-Center-PET-Image-Synthesis.
Personalized Image Enhancement Featuring Masked Style Modeling
Jun 15, 2023

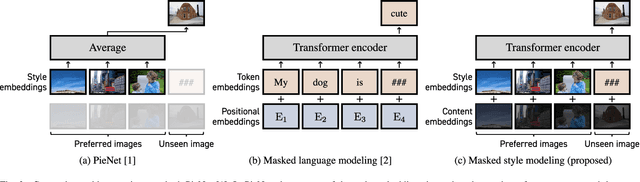
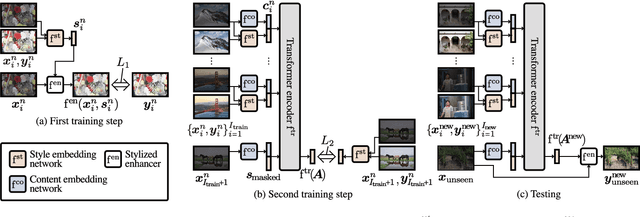
We address personalized image enhancement in this study, where we enhance input images for each user based on the user's preferred images. Previous methods apply the same preferred style to all input images (i.e., only one style for each user); in contrast to these methods, we aim to achieve content-aware personalization by applying different styles to each image considering the contents. For content-aware personalization, we make two contributions. First, we propose a method named masked style modeling, which can predict a style for an input image considering the contents by using the framework of masked language modeling. Second, to allow this model to consider the contents of images, we propose a novel training scheme where we download images from Flickr and create pseudo input and retouched image pairs using a degrading model. We conduct quantitative evaluations and a user study, and our method trained using our training scheme successfully achieves content-aware personalization; moreover, our method outperforms other previous methods in this field. Our source code is available at https://github.com/satoshi-kosugi/masked-style-modeling.
Histopathology Image Classification using Deep Manifold Contrastive Learning
Jun 26, 2023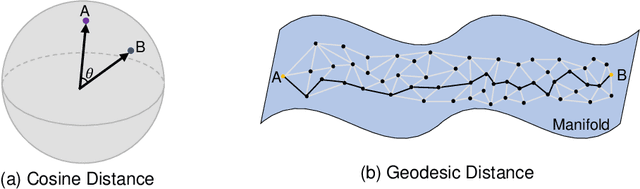
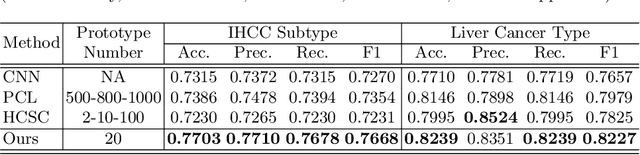
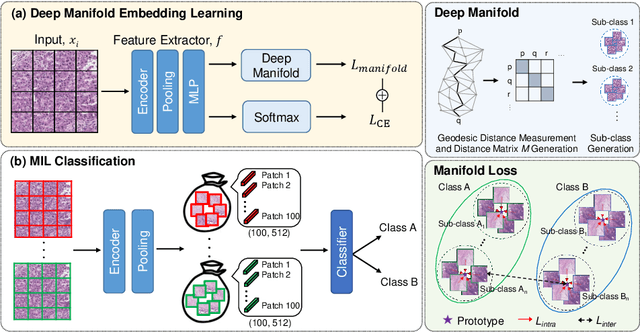

Contrastive learning has gained popularity due to its robustness with good feature representation performance. However, cosine distance, the commonly used similarity metric in contrastive learning, is not well suited to represent the distance between two data points, especially on a nonlinear feature manifold. Inspired by manifold learning, we propose a novel extension of contrastive learning that leverages geodesic distance between features as a similarity metric for histopathology whole slide image classification. To reduce the computational overhead in manifold learning, we propose geodesic-distance-based feature clustering for efficient contrastive loss evaluation using prototypes without time-consuming pairwise feature similarity comparison. The efficacy of the proposed method is evaluated on two real-world histopathology image datasets. Results demonstrate that our method outperforms state-of-the-art cosine-distance-based contrastive learning methods.
Content-Preserving Diffusion Model for Unsupervised AS-OCT image Despeckling
Jun 30, 2023
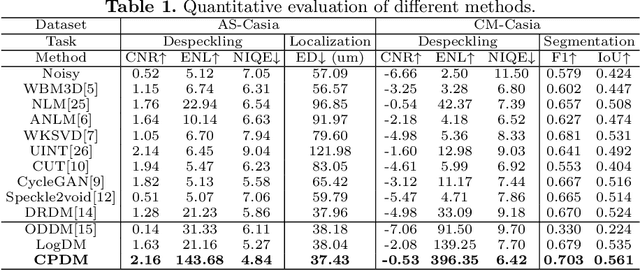
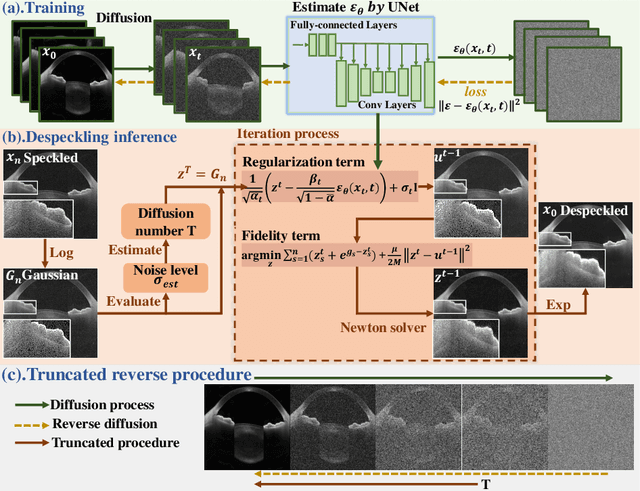
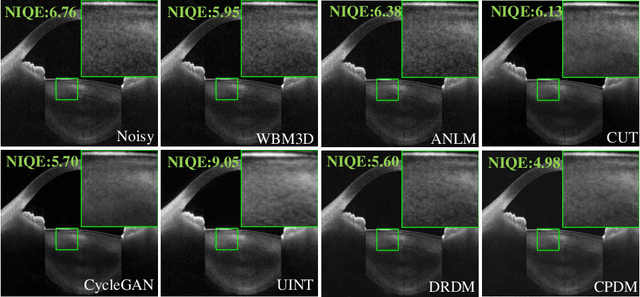
Anterior segment optical coherence tomography (AS-OCT) is a non-invasive imaging technique that is highly valuable for ophthalmic diagnosis. However, speckles in AS-OCT images can often degrade the image quality and affect clinical analysis. As a result, removing speckles in AS-OCT images can greatly benefit automatic ophthalmology analysis. Unfortunately, challenges still exist in deploying effective AS-OCT image denoising algorithms, including collecting sufficient paired training data and the requirement to preserve consistent content in medical images. To address these practical issues, we propose an unsupervised AS-OCT despeckling algorithm via Content Preserving Diffusion Model (CPDM) with statistical knowledge. At the training stage, a Markov chain transforms clean images to white Gaussian noise by repeatedly adding random noise and removes the predicted noise in a reverse procedure. At the inference stage, we first analyze the statistical distribution of speckles and convert it into a Gaussian distribution, aiming to match the fast truncated reverse diffusion process. We then explore the posterior distribution of observed images as a fidelity term to ensure content consistency in the iterative procedure. Our experimental results show that CPDM significantly improves image quality compared to competitive methods. Furthermore, we validate the benefits of CPDM for subsequent clinical analysis, including ciliary muscle (CM) segmentation and scleral spur (SS) localization.
Robot Localization and Mapping Final Report -- Sequential Adversarial Learning for Self-Supervised Deep Visual Odometry
Sep 08, 2023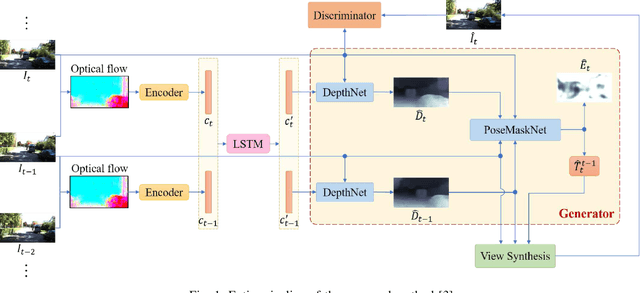

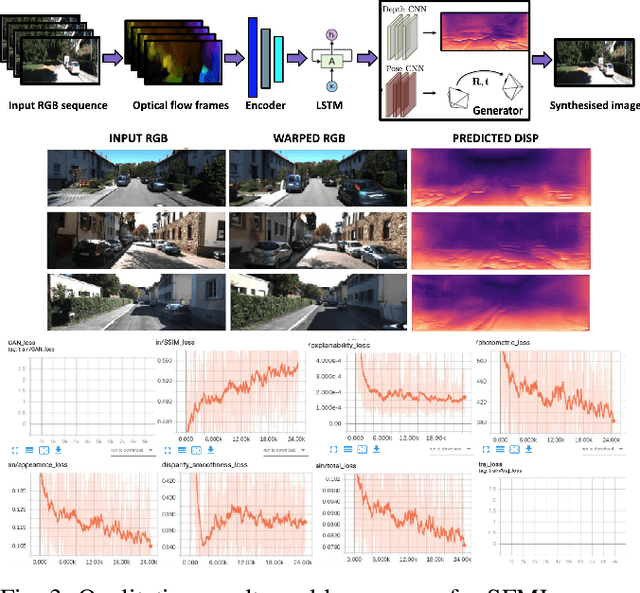
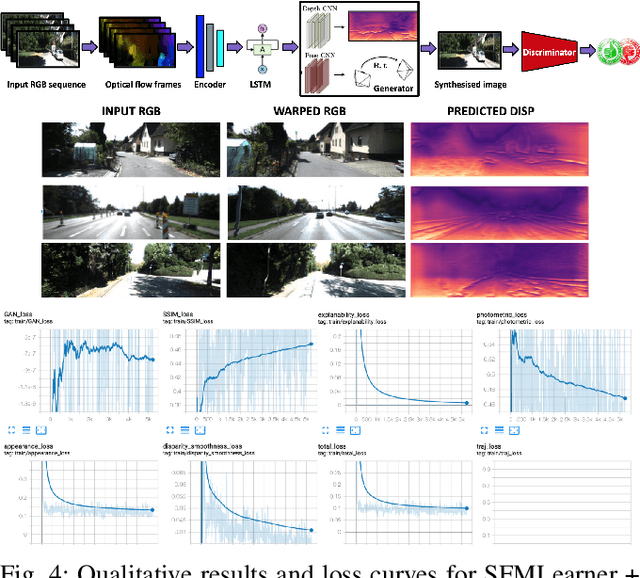
Visual odometry (VO) and SLAM have been using multi-view geometry via local structure from motion for decades. These methods have a slight disadvantage in challenging scenarios such as low-texture images, dynamic scenarios, etc. Meanwhile, use of deep neural networks to extract high level features is ubiquitous in computer vision. For VO, we can use these deep networks to extract depth and pose estimates using these high level features. The visual odometry task then can be modeled as an image generation task where the pose estimation is the by-product. This can also be achieved in a self-supervised manner, thereby eliminating the data (supervised) intensive nature of training deep neural networks. Although some works tried the similar approach [1], the depth and pose estimation in the previous works are vague sometimes resulting in accumulation of error (drift) along the trajectory. The goal of this work is to tackle these limitations of past approaches and to develop a method that can provide better depths and pose estimates. To address this, a couple of approaches are explored: 1) Modeling: Using optical flow and recurrent neural networks (RNN) in order to exploit spatio-temporal correlations which can provide more information to estimate depth. 2) Loss function: Generative adversarial network (GAN) [2] is deployed to improve the depth estimation (and thereby pose too), as shown in Figure 1. This additional loss term improves the realism in generated images and reduces artifacts.
Debiasing Counterfactuals In the Presence of Spurious Correlations
Aug 21, 2023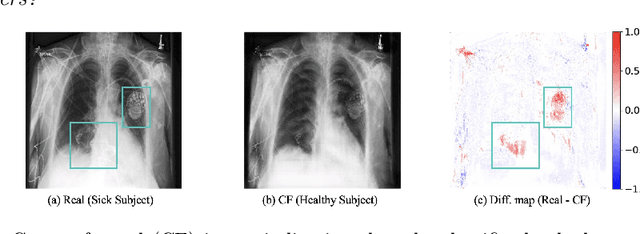

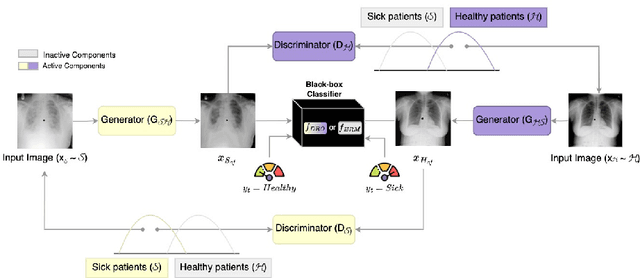
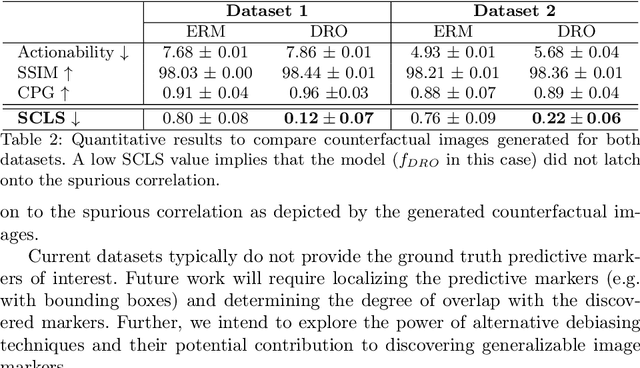
Deep learning models can perform well in complex medical imaging classification tasks, even when basing their conclusions on spurious correlations (i.e. confounders), should they be prevalent in the training dataset, rather than on the causal image markers of interest. This would thereby limit their ability to generalize across the population. Explainability based on counterfactual image generation can be used to expose the confounders but does not provide a strategy to mitigate the bias. In this work, we introduce the first end-to-end training framework that integrates both (i) popular debiasing classifiers (e.g. distributionally robust optimization (DRO)) to avoid latching onto the spurious correlations and (ii) counterfactual image generation to unveil generalizable imaging markers of relevance to the task. Additionally, we propose a novel metric, Spurious Correlation Latching Score (SCLS), to quantify the extent of the classifier reliance on the spurious correlation as exposed by the counterfactual images. Through comprehensive experiments on two public datasets (with the simulated and real visual artifacts), we demonstrate that the debiasing method: (i) learns generalizable markers across the population, and (ii) successfully ignores spurious correlations and focuses on the underlying disease pathology.