 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Hue-Net: Intensity-based Image-to-Image Translation with Differentiable Histogram Loss Functions
Dec 12, 2019

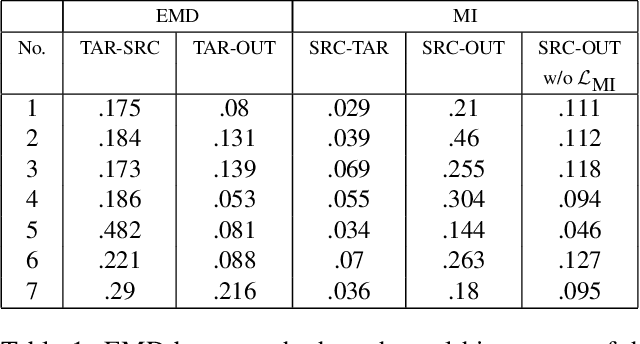
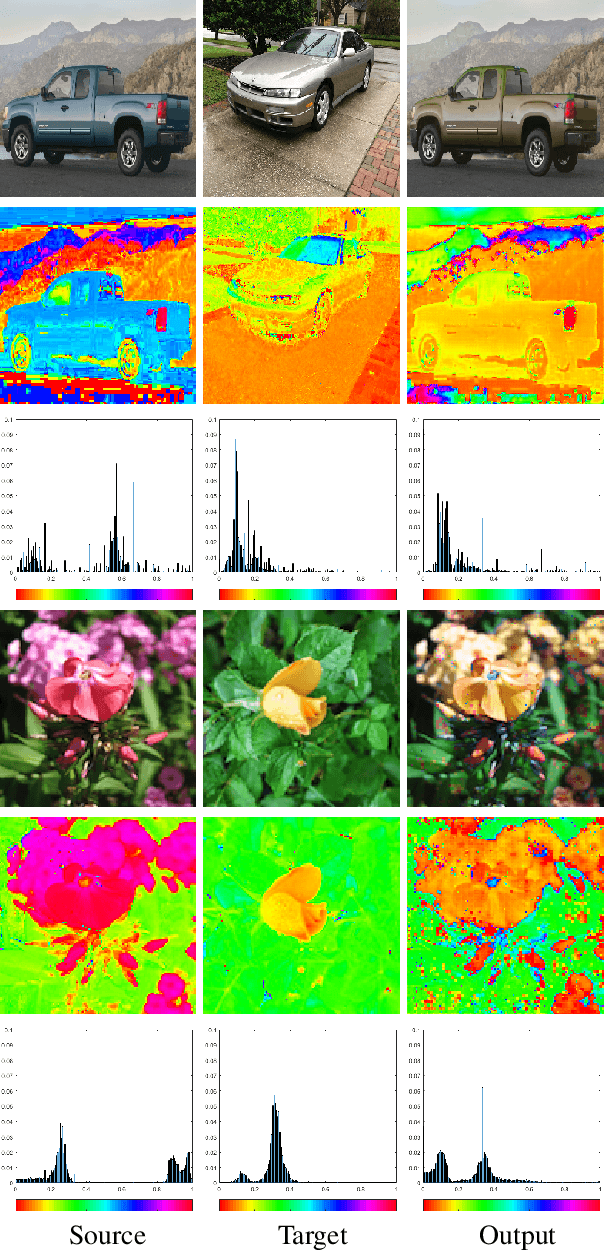
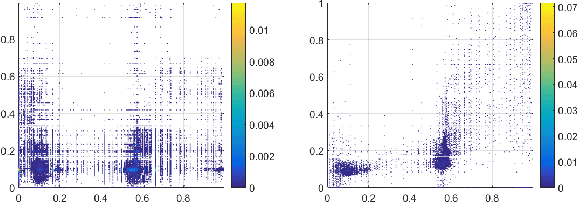
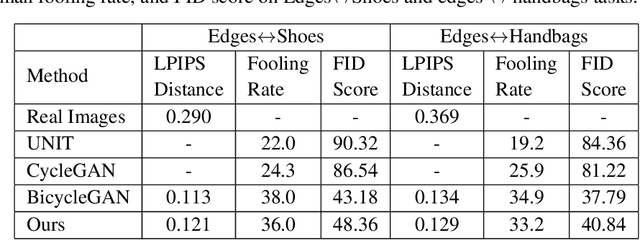
We present the Hue-Net - a novel Deep Learning framework for Intensity-based Image-to-Image Translation. The key idea is a new technique termed network augmentation which allows a differentiable construction of intensity histograms from images. We further introduce differentiable representations of (1D) cyclic and joint (2D) histograms and use them for defining loss functions based on cyclic Earth Mover's Distance (EMD) and Mutual Information (MI). While the Hue-Net can be applied to several image-to-image translation tasks, we choose to demonstrate its strength on color transfer problems, where the aim is to paint a source image with the colors of a different target image. Note that the desired output image does not exist and therefore cannot be used for supervised pixel-to-pixel learning. This is accomplished by using the HSV color-space and defining an intensity-based loss that is built on the EMD between the cyclic hue histograms of the output and the target images. To enforce color-free similarity between the source and the output images, we define a semantic-based loss by a differentiable approximation of the MI of these images. The incorporation of histogram loss functions in addition to an adversarial loss enables the construction of semantically meaningful and realistic images. Promising results are presented for different datasets.
Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Nov 29, 2018
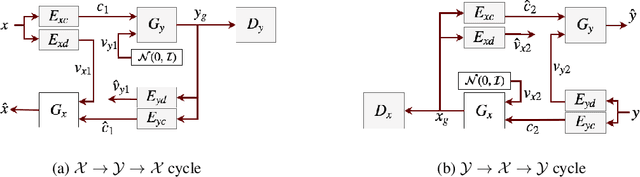
Unsupervised image-to-image translation is a class of computer vision problems which aims at modeling conditional distribution of images in the target domain, given a set of unpaired images in the source and target domains. An image in the source domain might have multiple representations in the target domain. Therefore, ambiguity in modeling of the conditional distribution arises, specially when the images in the source and target domains come from different modalities. Current approaches mostly rely on simplifying assumptions to map both domains into a shared-latent space. Consequently, they are only able to model the domain-invariant information between the two modalities. These approaches usually fail to model domain-specific information which has no representation in the target domain. In this work, we propose an unsupervised image-to-image translation framework which maximizes a domain-specific variational information bound and learns the target domain-invariant representation of the two domain. The proposed framework makes it possible to map a single source image into multiple images in the target domain, utilizing several target domain-specific codes sampled randomly from the prior distribution, or extracted from reference images.
MaskSketch: Unpaired Structure-guided Masked Image Generation
Feb 10, 2023
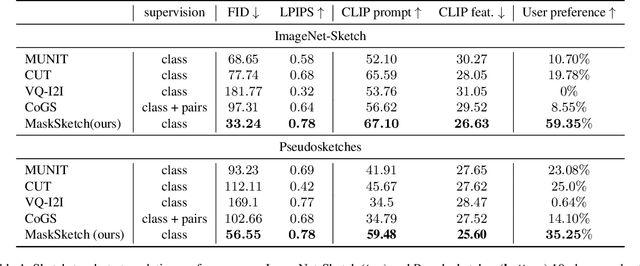

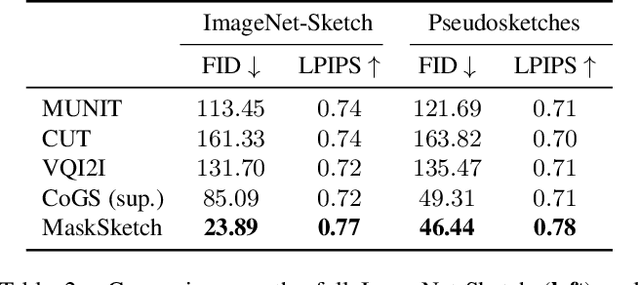
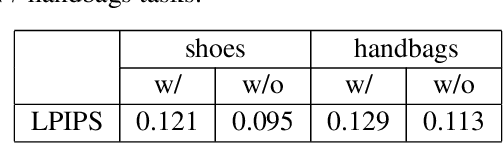
Recent conditional image generation methods produce images of remarkable diversity, fidelity and realism. However, the majority of these methods allow conditioning only on labels or text prompts, which limits their level of control over the generation result. In this paper, we introduce MaskSketch, an image generation method that allows spatial conditioning of the generation result using a guiding sketch as an extra conditioning signal during sampling. MaskSketch utilizes a pre-trained masked generative transformer, requiring no model training or paired supervision, and works with input sketches of different levels of abstraction. We show that intermediate self-attention maps of a masked generative transformer encode important structural information of the input image, such as scene layout and object shape, and we propose a novel sampling method based on this observation to enable structure-guided generation. Our results show that MaskSketch achieves high image realism and fidelity to the guiding structure. Evaluated on standard benchmark datasets, MaskSketch outperforms state-of-the-art methods for sketch-to-image translation, as well as unpaired image-to-image translation approaches.
Exemplar Guided Unsupervised Image-to-Image Translation with Semantic Consistency
Oct 13, 2018

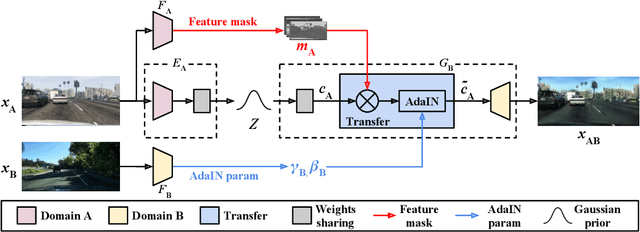

Image-to-image translation has recently received significant attention due to advances in deep learning. Most works focus on learning either a one-to-one mapping in an unsupervised way or a many-to-many mapping in a supervised way. However, a more practical setting is many-to-many mapping in an unsupervised way, which is harder due to the lack of supervision and the complex inner- and cross-domain variations. To alleviate these issues, we propose the Exemplar Guided & Semantically Consistent Image-to-image Translation (EGSC-IT) network which conditions the translation process on an exemplar image in the target domain. We assume that an image comprises of a content component which is shared across domains, and a style component specific to each domain. Under the guidance of an exemplar from the target domain we apply Adaptive Instance Normalization to the shared content component, which allows us to transfer the style information of the target domain to the source domain. To avoid semantic inconsistencies during translation that naturally appear due to the large inner- and cross-domain variations, we introduce the concept of feature masks that provide coarse semantic guidance without requiring the use of any semantic labels. Experimental results on various datasets show that EGSC-IT does not only translate the source image to diverse instances in the target domain, but also preserves the semantic consistency during the process.
CoopInit: Initializing Generative Adversarial Networks via Cooperative Learning
Mar 21, 2023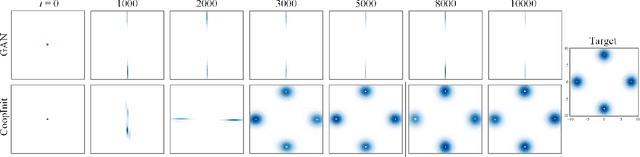
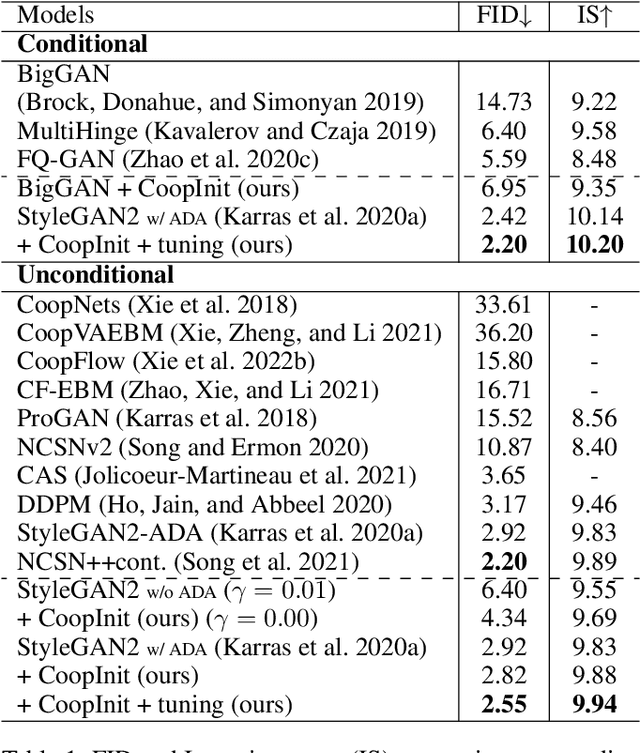
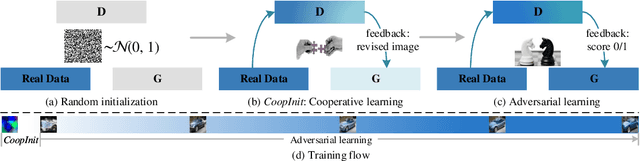

Numerous research efforts have been made to stabilize the training of the Generative Adversarial Networks (GANs), such as through regularization and architecture design. However, we identify the instability can also arise from the fragile balance at the early stage of adversarial learning. This paper proposes the CoopInit, a simple yet effective cooperative learning-based initialization strategy that can quickly learn a good starting point for GANs, with a very small computation overhead during training. The proposed algorithm consists of two learning stages: (i) Cooperative initialization stage: The discriminator of GAN is treated as an energy-based model (EBM) and is optimized via maximum likelihood estimation (MLE), with the help of the GAN's generator to provide synthetic data to approximate the learning gradients. The EBM also guides the MLE learning of the generator via MCMC teaching; (ii) Adversarial finalization stage: After a few iterations of initialization, the algorithm seamlessly transits to the regular mini-max adversarial training until convergence. The motivation is that the MLE-based initialization stage drives the model towards mode coverage, which is helpful in alleviating the issue of mode dropping during the adversarial learning stage. We demonstrate the effectiveness of the proposed approach on image generation and one-sided unpaired image-to-image translation tasks through extensive experiments.
* 9 pages of main text, 2 pages of references
Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
Feb 15, 2023
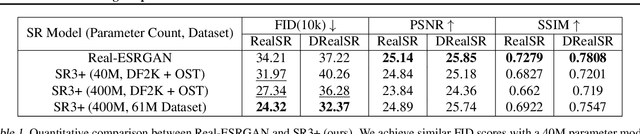
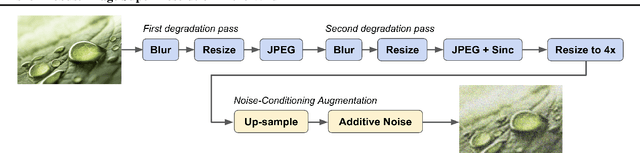
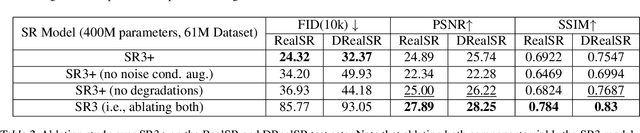
Diffusion models have shown promising results on single-image super-resolution and other image- to-image translation tasks. Despite this success, they have not outperformed state-of-the-art GAN models on the more challenging blind super-resolution task, where the input images are out of distribution, with unknown degradations. This paper introduces SR3+, a diffusion-based model for blind super-resolution, establishing a new state-of-the-art. To this end, we advocate self-supervised training with a combination of composite, parameterized degradations for self-supervised training, and noise-conditioing augmentation during training and testing. With these innovations, a large-scale convolutional architecture, and large-scale datasets, SR3+ greatly outperforms SR3. It outperforms Real-ESRGAN when trained on the same data, with a DRealSR FID score of 36.82 vs. 37.22, which further improves to FID of 32.37 with larger models, and further still with larger training sets.
GANHopper: Multi-Hop GAN for Unsupervised Image-to-Image Translation
Feb 29, 2020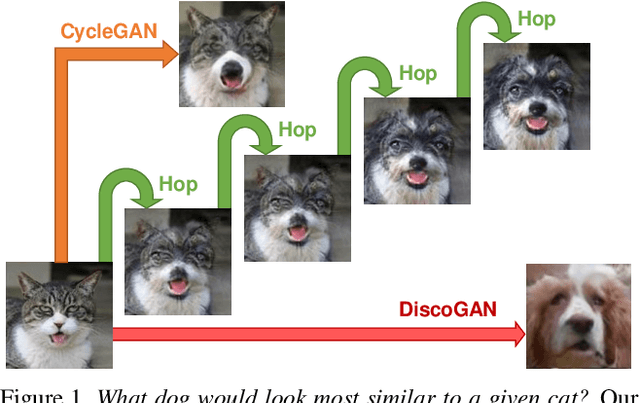
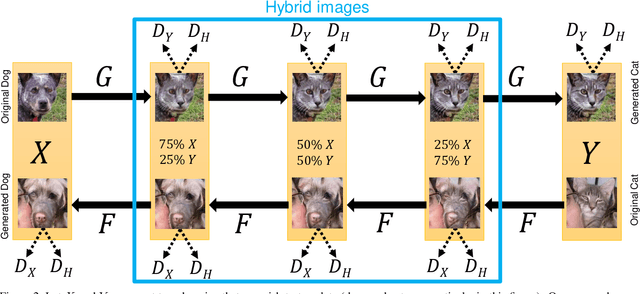
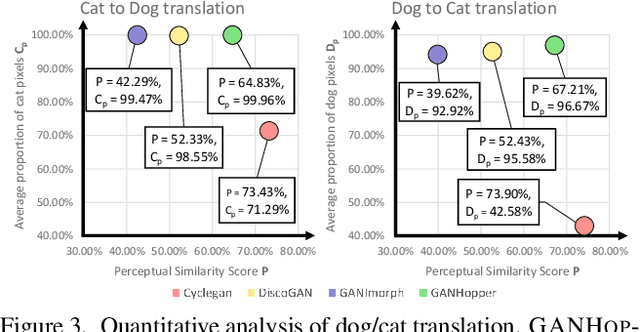
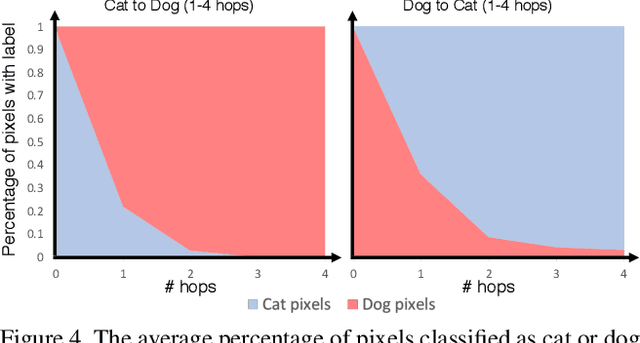
We introduce GANHopper, an unsupervised image-to-image translation network that transforms images gradually between two domains, through multiple hops. Instead of executing translation directly, we steer the translation by requiring the network to produce in-between images which resemble weighted hybrids between images from the two in-put domains. Our network is trained on unpaired images from the two domains only, without any in-between images.All hops are produced using a single generator along each direction. In addition to the standard cycle-consistency and adversarial losses, we introduce a new hybrid discrimina-tor, which is trained to classify the intermediate images produced by the generator as weighted hybrids, with weights based on a predetermined hop count. We also introduce a smoothness term to constrain the magnitude of each hop,further regularizing the translation. Compared to previous methods, GANHopper excels at image translations involving domain-specific image features and geometric variations while also preserving non-domain-specific features such as backgrounds and general color schemes.
Monocular Depth Estimation using Diffusion Models
Feb 28, 2023
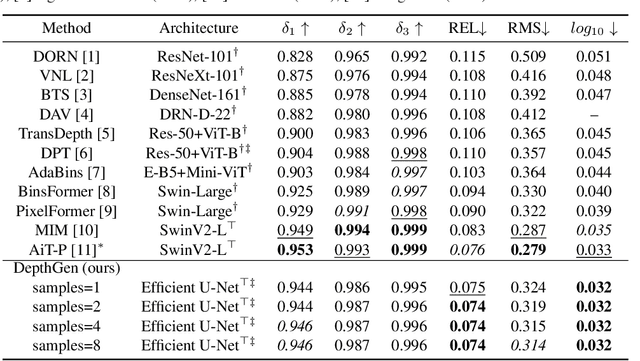
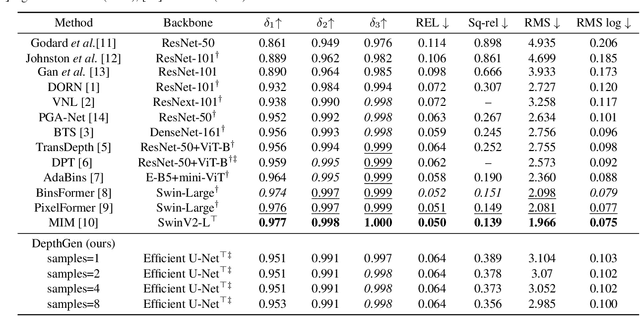

We formulate monocular depth estimation using denoising diffusion models, inspired by their recent successes in high fidelity image generation. To that end, we introduce innovations to address problems arising due to noisy, incomplete depth maps in training data, including step-unrolled denoising diffusion, an $L_1$ loss, and depth infilling during training. To cope with the limited availability of data for supervised training, we leverage pre-training on self-supervised image-to-image translation tasks. Despite the simplicity of the approach, with a generic loss and architecture, our DepthGen model achieves SOTA performance on the indoor NYU dataset, and near SOTA results on the outdoor KITTI dataset. Further, with a multimodal posterior, DepthGen naturally represents depth ambiguity (e.g., from transparent surfaces), and its zero-shot performance combined with depth imputation, enable a simple but effective text-to-3D pipeline. Project page: https://depth-gen.github.io
Show, Attend and Translate: Unpaired Multi-Domain Image-to-Image Translation with Visual Attention
Nov 19, 2018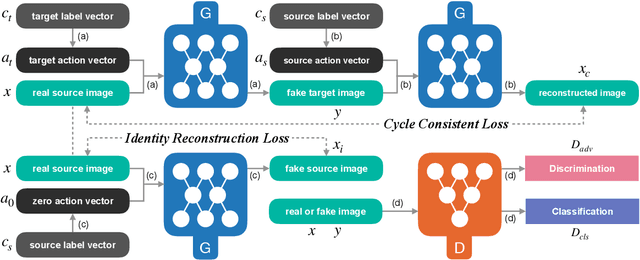

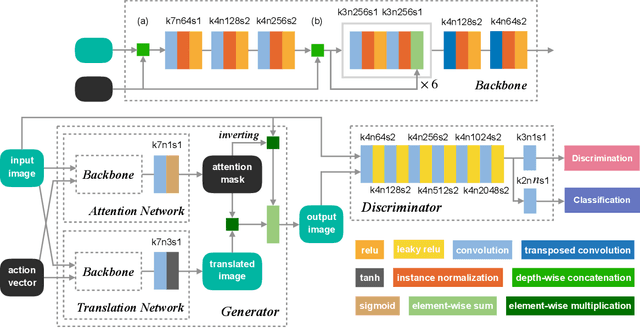

Recently unpaired multi-domain image-to-image translation has attracted great interests and obtained remarkable progress, where a label vector is utilized to indicate multi-domain information. In this paper, we propose SAT (Show, Attend and Translate), an unified and explainable generative adversarial network equipped with visual attention that can perform unpaired image-to-image translation for multiple domains. By introducing an action vector, we treat the original translation tasks as problems of arithmetic addition and subtraction. Visual attention is applied to guarantee that only the regions relevant to the target domains are translated. Extensive experiments on a facial attribute dataset demonstrate the superiority of our approach and the generated attention masks better explain what SAT attends when translating images.