 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Attend and Translate: Unpaired Multi-Domain Image-to-Image Translation with Visual Attention
Paper and Code
Nov 19, 2018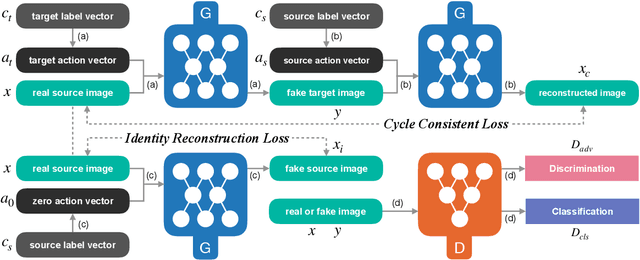

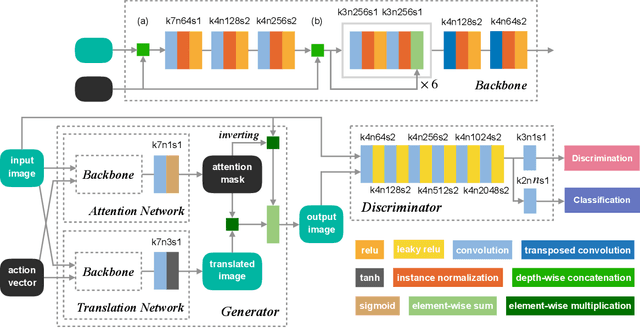

Recently unpaired multi-domain image-to-image translation has attracted great interests and obtained remarkable progress, where a label vector is utilized to indicate multi-domain information. In this paper, we propose SAT (Show, Attend and Translate), an unified and explainable generative adversarial network equipped with visual attention that can perform unpaired image-to-image translation for multiple domains. By introducing an action vector, we treat the original translation tasks as problems of arithmetic addition and subtraction. Visual attention is applied to guarantee that only the regions relevant to the target domains are translated. Extensive experiments on a facial attribute dataset demonstrate the superiority of our approach and the generated attention masks better explain what SAT attends when translating images.