 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Video Segmentation Machine Learning Pipeline
Jul 09, 2025Visual effects (VFX) production often struggles with slow, resource-intensive mask generation. This paper presents an automated video segmentation pipeline that creates temporally consistent instance masks. It employs machine learning for: (1) flexible object detection via text prompts, (2) refined per-frame image segmentation and (3) robust video tracking to ensure temporal stability. Deployed using containerization and leveraging a structured output format, the pipeline was quickly adopted by our artists. It significantly reduces manual effort, speeds up the creation of preliminary composites, and provides comprehensive segmentation data, thereby enhancing overall VFX production efficiency.
UNIST: Unpaired Neural Implicit Shape Translation Network
Dec 10, 2021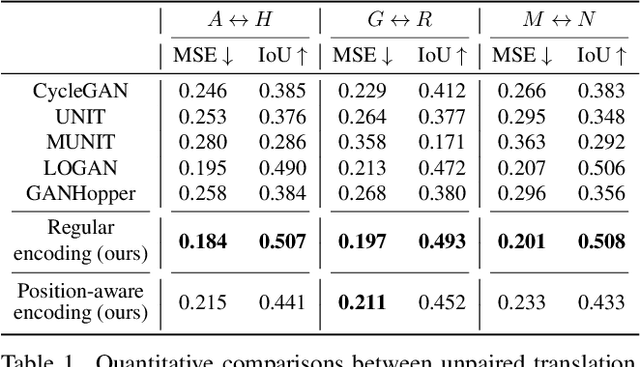
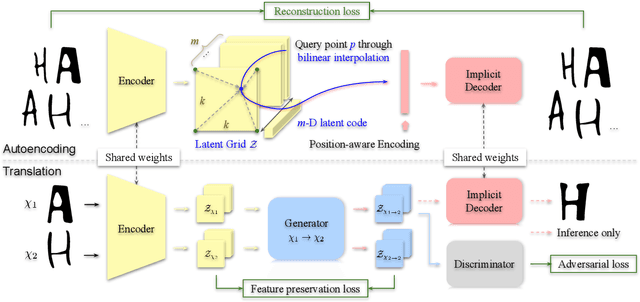
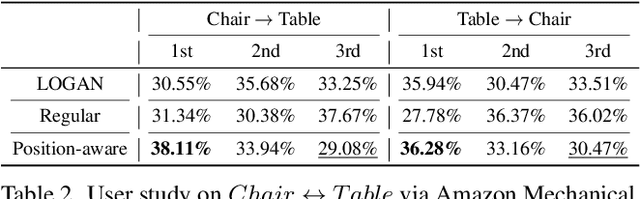
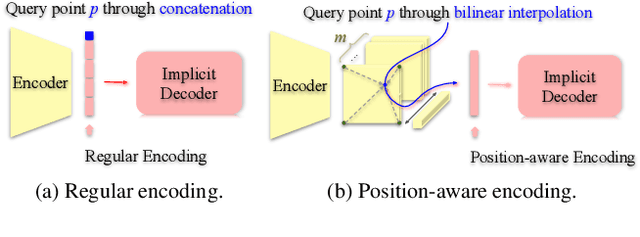
We introduce UNIST, the first deep neural implicit model for general-purpose, unpaired shape-to-shape translation, in both 2D and 3D domains. Our model is built on autoencoding implicit fields, rather than point clouds which represents the state of the art. Furthermore, our translation network is trained to perform the task over a latent grid representation which combines the merits of both latent-space processing and position awareness, to not only enable drastic shape transforms but also well preserve spatial features and fine local details for natural shape translations. With the same network architecture and only dictated by the input domain pairs, our model can learn both style-preserving content alteration and content-preserving style transfer. We demonstrate the generality and quality of the translation results, and compare them to well-known baselines.
GANHopper: Multi-Hop GAN for Unsupervised Image-to-Image Translation
Feb 29, 2020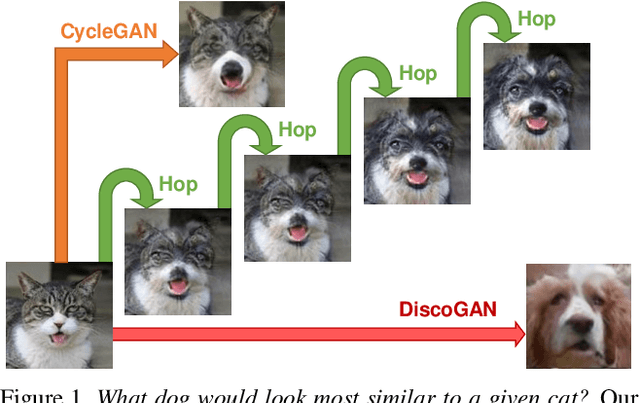
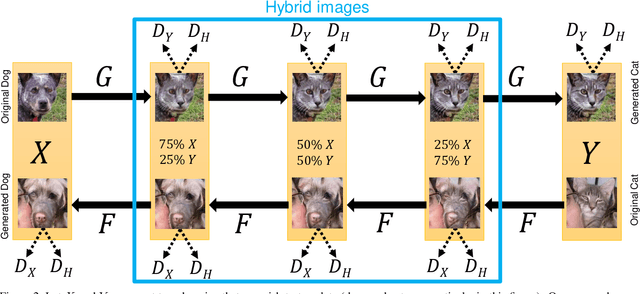
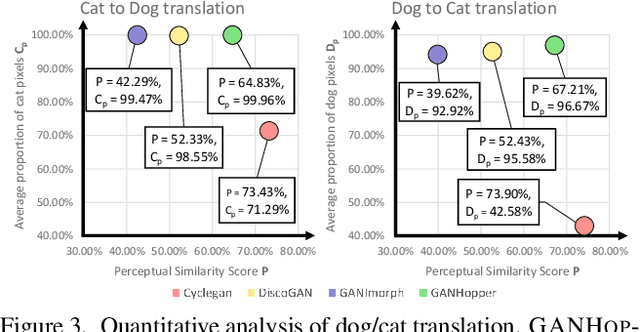
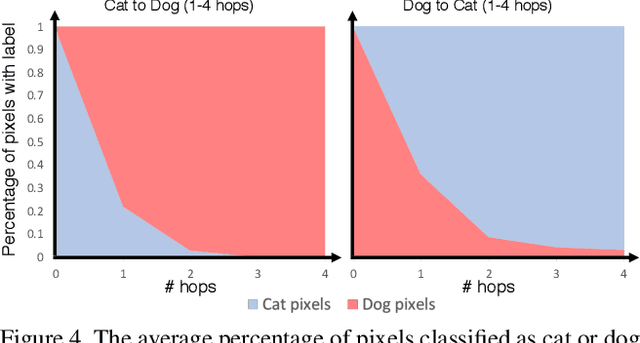
We introduce GANHopper, an unsupervised image-to-image translation network that transforms images gradually between two domains, through multiple hops. Instead of executing translation directly, we steer the translation by requiring the network to produce in-between images which resemble weighted hybrids between images from the two in-put domains. Our network is trained on unpaired images from the two domains only, without any in-between images.All hops are produced using a single generator along each direction. In addition to the standard cycle-consistency and adversarial losses, we introduce a new hybrid discrimina-tor, which is trained to classify the intermediate images produced by the generator as weighted hybrids, with weights based on a predetermined hop count. We also introduce a smoothness term to constrain the magnitude of each hop,further regularizing the translation. Compared to previous methods, GANHopper excels at image translations involving domain-specific image features and geometric variations while also preserving non-domain-specific features such as backgrounds and general color schemes.