 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
Protecting Facial Privacy: Generating Adversarial Identity Masks via Style-robust Makeup Transfer
Mar 28, 2022
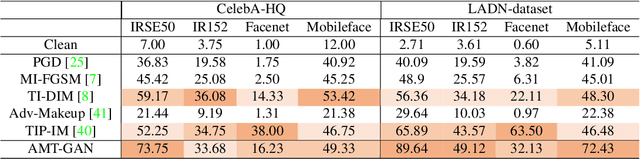
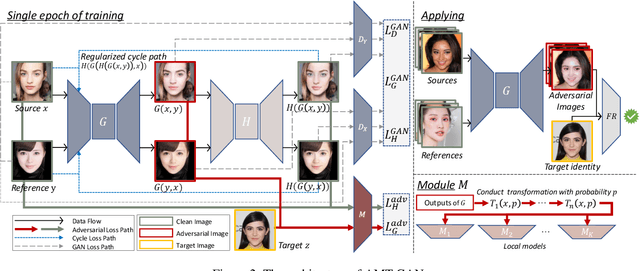
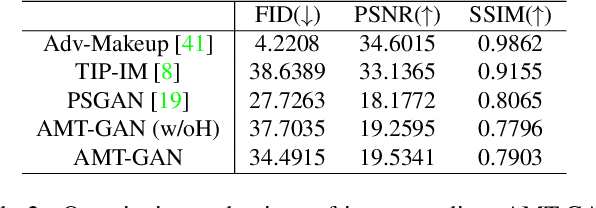
While deep face recognition (FR) systems have shown amazing performance in identification and verification, they also arouse privacy concerns for their excessive surveillance on users, especially for public face images widely spread on social networks. Recently, some studies adopt adversarial examples to protect photos from being identified by unauthorized face recognition systems. However, existing methods of generating adversarial face images suffer from many limitations, such as awkward visual, white-box setting, weak transferability, making them difficult to be applied to protect face privacy in reality. In this paper, we propose adversarial makeup transfer GAN (AMT-GAN), a novel face protection method aiming at constructing adversarial face images that preserve stronger black-box transferability and better visual quality simultaneously. AMT-GAN leverages generative adversarial networks (GAN) to synthesize adversarial face images with makeup transferred from reference images. In particular, we introduce a new regularization module along with a joint training strategy to reconcile the conflicts between the adversarial noises and the cycle consistence loss in makeup transfer, achieving a desirable balance between the attack strength and visual changes. Extensive experiments verify that compared with state of the arts, AMT-GAN can not only preserve a comfortable visual quality, but also achieve a higher attack success rate over commercial FR APIs, including Face++, Aliyun, and Microsoft.
Domain-Aware Universal Style Transfer
Aug 17, 2021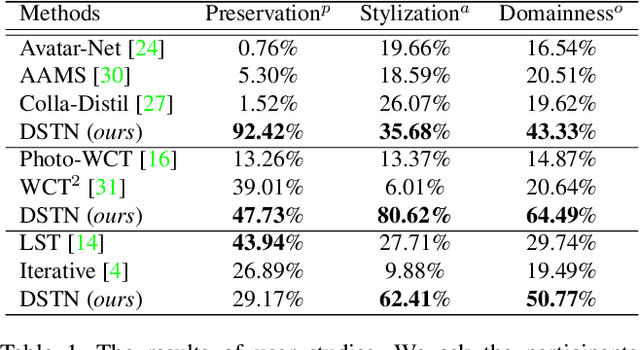
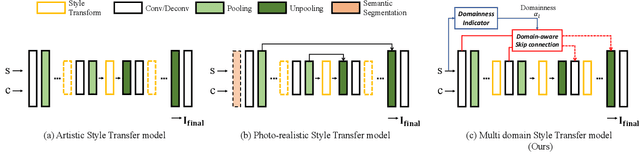
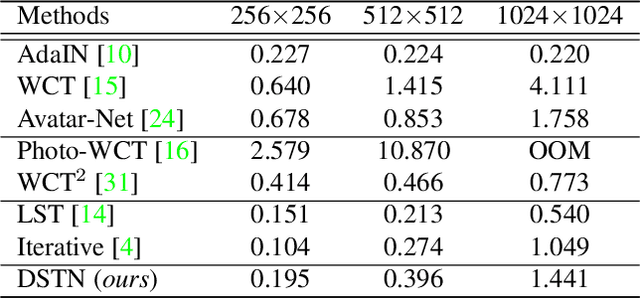
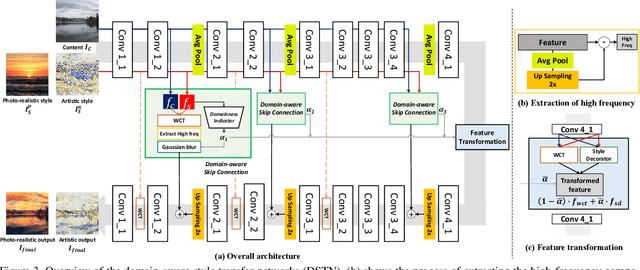
Style transfer aims to reproduce content images with the styles from reference images. Existing universal style transfer methods successfully deliver arbitrary styles to original images either in an artistic or a photo-realistic way. However, the range of 'arbitrary style' defined by existing works is bounded in the particular domain due to their structural limitation. Specifically, the degrees of content preservation and stylization are established according to a predefined target domain. As a result, both photo-realistic and artistic models have difficulty in performing the desired style transfer for the other domain. To overcome this limitation, we propose a unified architecture, Domain-aware Style Transfer Networks (DSTN) that transfer not only the style but also the property of domain (i.e., domainness) from a given reference image. To this end, we design a novel domainness indicator that captures the domainness value from the texture and structural features of reference images. Moreover, we introduce a unified framework with domain-aware skip connection to adaptively transfer the stroke and palette to the input contents guided by the domainness indicator. Our extensive experiments validate that our model produces better qualitative results and outperforms previous methods in terms of proxy metrics on both artistic and photo-realistic stylizations.
Photo style transfer with consistency losses
May 09, 2020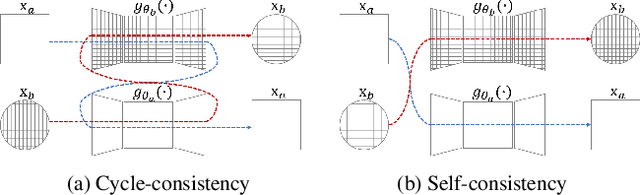


We address the problem of style transfer between two photos and propose a new way to preserve photorealism. Using the single pair of photos available as input, we train a pair of deep convolution networks (convnets), each of which transfers the style of one photo to the other. To enforce photorealism, we introduce a content preserving mechanism by combining a cycle-consistency loss with a self-consistency loss. Experimental results show that this method does not suffer from typical artifacts observed in methods working in the same settings. We then further analyze some properties of these trained convnets. First, we notice that they can be used to stylize other unseen images with same known style. Second, we show that retraining only a small subset of the network parameters can be sufficient to adapt these convnets to new styles.
Good Artists Copy, Great Artists Steal: Model Extraction Attacks Against Image Translation Generative Adversarial Networks
Apr 26, 2021
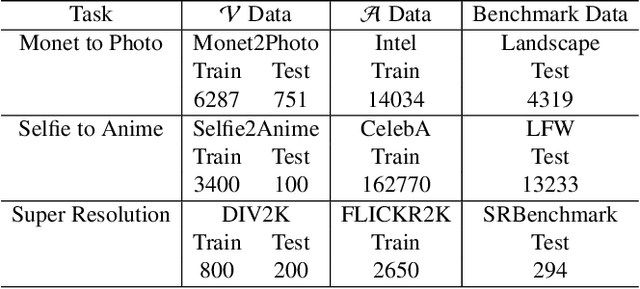

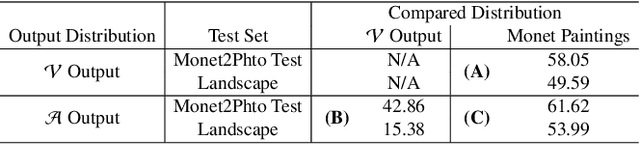
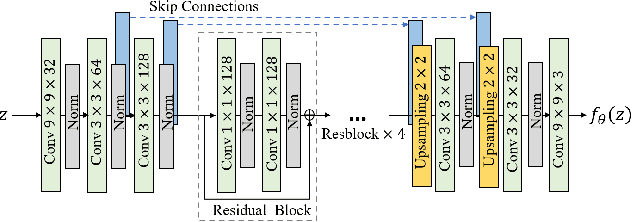
Machine learning models are typically made available to potential client users via inference APIs. Model extraction attacks occur when a malicious client uses information gleaned from queries to the inference API of a victim model $F_V$ to build a surrogate model $F_A$ that has comparable functionality. Recent research has shown successful model extraction attacks against image classification, and NLP models. In this paper, we show the first model extraction attack against real-world generative adversarial network (GAN) image translation models. We present a framework for conducting model extraction attacks against image translation models, and show that the adversary can successfully extract functional surrogate models. The adversary is not required to know $F_V$'s architecture or any other information about it beyond its intended image translation task, and queries $F_V$'s inference interface using data drawn from the same domain as the training data for $F_V$. We evaluate the effectiveness of our attacks using three different instances of two popular categories of image translation: (1) Selfie-to-Anime and (2) Monet-to-Photo (image style transfer), and (3) Super-Resolution (super resolution). Using standard performance metrics for GANs, we show that our attacks are effective in each of the three cases -- the differences between $F_V$ and $F_A$, compared to the target are in the following ranges: Selfie-to-Anime: FID $13.36-68.66$, Monet-to-Photo: FID $3.57-4.40$, and Super-Resolution: SSIM: $0.06-0.08$ and PSNR: $1.43-4.46$. Furthermore, we conducted a large scale (125 participants) user study on Selfie-to-Anime and Monet-to-Photo to show that human perception of the images produced by the victim and surrogate models can be considered equivalent, within an equivalence bound of Cohen's $d=0.3$.
Filter Style Transfer between Photos
Jul 15, 2020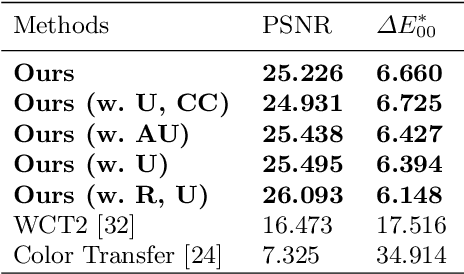
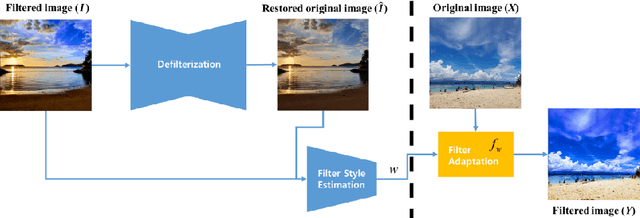


Over the past few years, image-to-image style transfer has risen to the frontiers of neural image processing. While conventional methods were successful in various tasks such as color and texture transfer between images, none could effectively work with the custom filter effects that are applied by users through various platforms like Instagram. In this paper, we introduce a new concept of style transfer, Filter Style Transfer (FST). Unlike conventional style transfer, new technique FST can extract and transfer custom filter style from a filtered style image to a content image. FST first infers the original image from a filtered reference via image-to-image translation. Then it estimates filter parameters from the difference between them. To resolve the ill-posed nature of reconstructing the original image from the reference, we represent each pixel color of an image to class mean and deviation. Besides, to handle the intra-class color variation, we propose an uncertainty based weighted least square method for restoring an original image. To the best of our knowledge, FST is the first style transfer method that can transfer custom filter effects between FHD image under 2ms on a mobile device without any textual context loss.
Sketch3T: Test-Time Training for Zero-Shot SBIR
Mar 28, 2022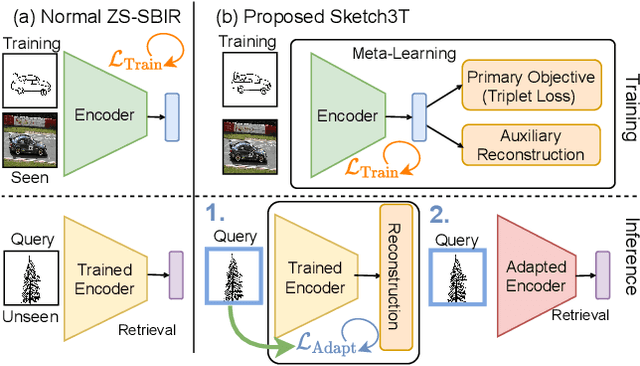
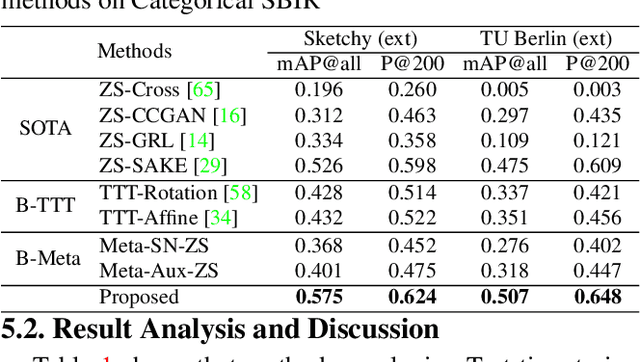
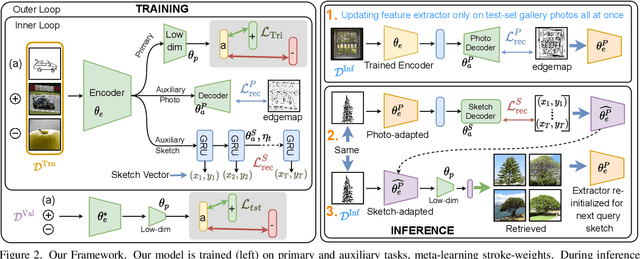
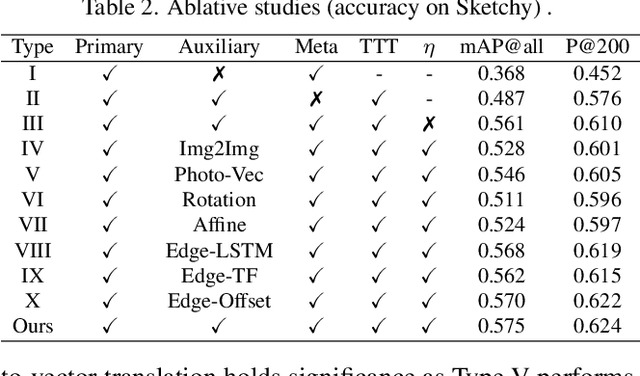
Zero-shot sketch-based image retrieval typically asks for a trained model to be applied as is to unseen categories. In this paper, we question to argue that this setup by definition is not compatible with the inherent abstract and subjective nature of sketches, i.e., the model might transfer well to new categories, but will not understand sketches existing in different test-time distribution as a result. We thus extend ZS-SBIR asking it to transfer to both categories and sketch distributions. Our key contribution is a test-time training paradigm that can adapt using just one sketch. Since there is no paired photo, we make use of a sketch raster-vector reconstruction module as a self-supervised auxiliary task. To maintain the fidelity of the trained cross-modal joint embedding during test-time update, we design a novel meta-learning based training paradigm to learn a separation between model updates incurred by this auxiliary task from those off the primary objective of discriminative learning. Extensive experiments show our model to outperform state of-the-arts, thanks to the proposed test-time adaption that not only transfers to new categories but also accommodates to new sketching styles.
Deep Preset: Blending and Retouching Photos with Color Style Transfer
Jul 21, 2020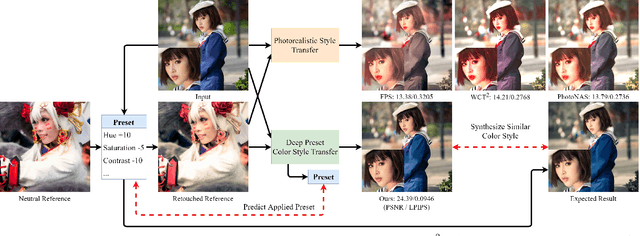
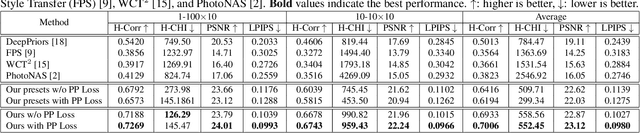

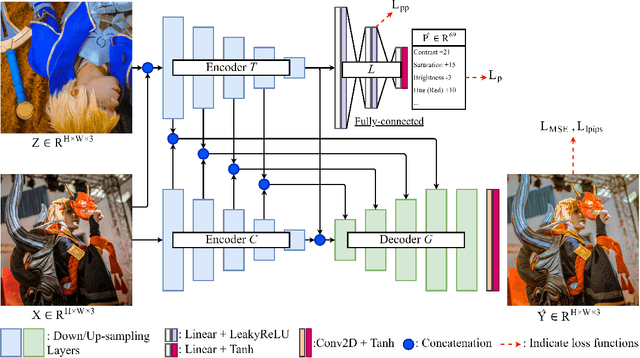
End-users, without knowledge in photography, desire to beautify their photos to have a similar color style as a well-retouched reference. However, recent works in image style transfer are overused. They usually synthesize undesirable results due to transferring exact colors to the wrong destination. It becomes even worse in sensitive cases such as portraits. In this work, we concentrate on learning low-level image transformation, especially color-shifting methods, rather than mixing contextual features, then present a novel scheme to train color style transfer with ground-truth. Furthermore, we propose a color style transfer named Deep Preset. It is designed to 1) generalize the features representing the color transformation from content with natural colors to retouched reference, then blend it into the contextual features of content, 2) predict hyper-parameters (settings or preset) of the applied low-level color transformation methods, 3) stylize content to have a similar color style as reference. We script Lightroom, a powerful tool in editing photos, to generate 600,000 training samples using 1,200 images from the Flick2K dataset and 500 user-generated presets with 69 settings. Experimental results show that our Deep Preset outperforms the previous works in color style transfer quantitatively and qualitatively.
Data Augmentation using Random Image Cropping for High-resolution Virtual Try-On (VITON-CROP)
Nov 16, 2021

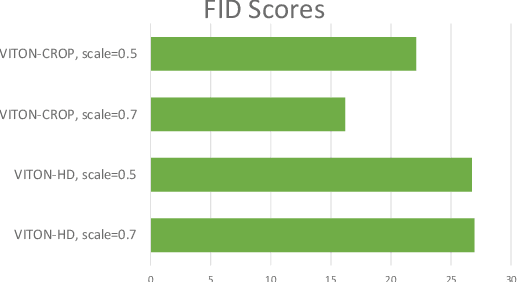
Image-based virtual try-on provides the capacity to transfer a clothing item onto a photo of a given person, which is usually accomplished by warping the item to a given human pose and adjusting the warped item to the person. However, the results of real-world synthetic images (e.g., selfies) from the previous method is not realistic because of the limitations which result in the neck being misrepresented and significant changes to the style of the garment. To address these challenges, we propose a novel method to solve this unique issue, called VITON-CROP. VITON-CROP synthesizes images more robustly when integrated with random crop augmentation compared to the existing state-of-the-art virtual try-on models. In the experiments, we demonstrate that VITON-CROP is superior to VITON-HD both qualitatively and quantitatively.
Bridging Unpaired Facial Photos And Sketches By Line-drawings
Feb 25, 2021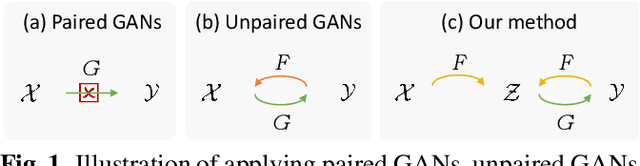
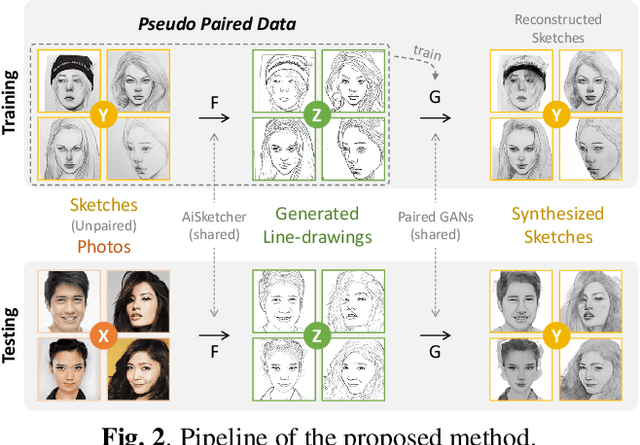
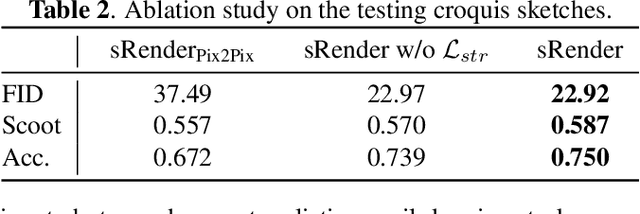
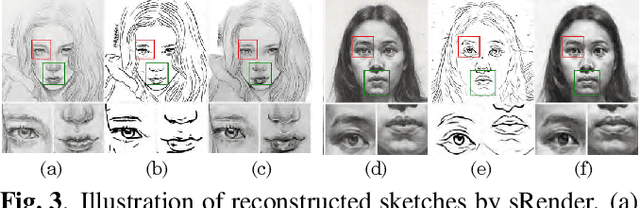
In this paper, we propose a novel method to learn face sketch synthesis models by using unpaired data. Our main idea is bridging the photo domain $\mathcal{X}$ and the sketch domain $Y$ by using the line-drawing domain $\mathcal{Z}$. Specially, we map both photos and sketches to line-drawings by using a neural style transfer method, i.e. $F: \mathcal{X}/\mathcal{Y} \mapsto \mathcal{Z}$. Consequently, we obtain \textit{pseudo paired data} $(\mathcal{Z}, \mathcal{Y})$, and can learn the mapping $G:\mathcal{Z} \mapsto \mathcal{Y}$ in a supervised learning manner. In the inference stage, given a facial photo, we can first transfer it to a line-drawing and then to a sketch by $G \circ F$. Additionally, we propose a novel stroke loss for generating different types of strokes. Our method, termed sRender, accords well with human artists' rendering process. Experimental results demonstrate that sRender can generate multi-style sketches, and significantly outperforms existing unpaired image-to-image translation methods.
Spatial Content Alignment For Pose Transfer
Mar 31, 2021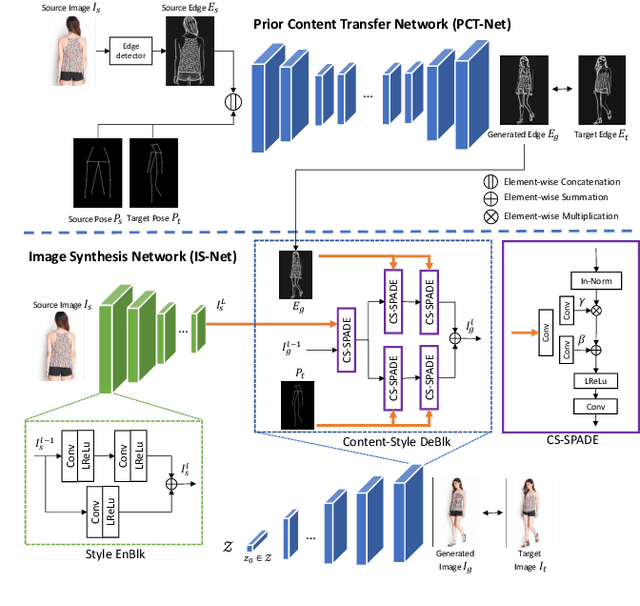
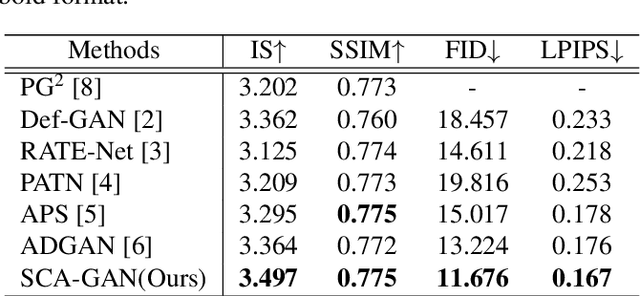
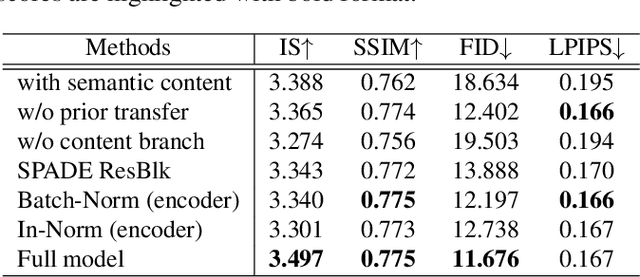

Due to unreliable geometric matching and content misalignment, most conventional pose transfer algorithms fail to generate fine-trained person images. In this paper, we propose a novel framework Spatial Content Alignment GAN (SCAGAN) which aims to enhance the content consistency of garment textures and the details of human characteristics. We first alleviate the spatial misalignment by transferring the edge content to the target pose in advance. Secondly, we introduce a new Content-Style DeBlk which can progressively synthesize photo-realistic person images based on the appearance features of the source image, the target pose heatmap and the prior transferred content in edge domain. We compare the proposed framework with several state-of-the-art methods to show its superiority in quantitative and qualitative analysis. Moreover, detailed ablation study results demonstrate the efficacy of our contributions. Codes are publicly available at github.com/rocketappslab/SCA-GAN.