 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Colluding Adversaries in Machine Learning Pipelines
Jun 08, 2026Machine learning (ML) models are susceptible to various security, privacy, and fairness risks. Adversaries with different characteristics (i.e., objectives, knowledge, and capabilities) can collude by executing one attack to amplify others. Existing work lacks a systematic framework to explore collusion among adversaries, and to study the implications of the adversaries' characteristics. We present a framework covering collusion (a) between train- and inference-time adversaries, and (b) among inference-time adversaries. Our framework accounts for factors enabling collusion between adversaries. We propose a guideline to conjecture about the potential for collusion using enabling factors. We use it to explain prior work, conjecture about unexplored collusions, and empirically validate five such cases. Finally, we discuss how adversaries' characteristics influence the potential for collusion.
Amulet: a Python Library for Assessing Interactions Among ML Defenses and Risks
Sep 15, 2025



ML models are susceptible to risks to security, privacy, and fairness. Several defenses are designed to protect against their intended risks, but can inadvertently affect susceptibility to other unrelated risks, known as unintended interactions. Several jurisdictions are preparing ML regulatory frameworks that require ML practitioners to assess the susceptibility of ML models to different risks. A library for valuating unintended interactions that can be used by (a) practitioners to evaluate unintended interactions at scale prior to model deployment and (b) researchers to design defenses which do not suffer from an unintended increase in unrelated risks. Ideally, such a library should be i) comprehensive by including representative attacks, defenses and metrics for different risks, ii) extensible to new modules due to its modular design, iii) consistent with a user-friendly API template for inputs and outputs, iv) applicable to evaluate previously unexplored unintended interactions. We present AMULET, a Python library that covers risks to security, privacy, and fairness, which satisfies all these requirements. AMULET can be used to evaluate unexplored unintended interactions, compare effectiveness between defenses or attacks, and include new attacks and defenses.
Combining Machine Learning Defenses without Conflicts
Nov 14, 2024



Machine learning (ML) defenses protect against various risks to security, privacy, and fairness. Real-life models need simultaneous protection against multiple different risks which necessitates combining multiple defenses. But combining defenses with conflicting interactions in an ML model can be ineffective, incurring a significant drop in the effectiveness of one or more defenses being combined. Practitioners need a way to determine if a given combination can be effective. Experimentally identifying effective combinations can be time-consuming and expensive, particularly when multiple defenses need to be combined. We need an inexpensive, easy-to-use combination technique to identify effective combinations. Ideally, a combination technique should be (a) accurate (correctly identifies whether a combination is effective or not), (b) scalable (allows combining multiple defenses), (c) non-invasive (requires no change to the defenses being combined), and (d) general (is applicable to different types of defenses). Prior works have identified several ad-hoc techniques but none satisfy all the requirements above. We propose a principled combination technique, Def\Con, to identify effective defense combinations. Def\Con meets all requirements, achieving 90% accuracy on eight combinations explored in prior work and 81% in 30 previously unexplored combinations that we empirically evaluate in this paper.
LLM-CI: Assessing Contextual Integrity Norms in Language Models
Sep 05, 2024



Large language models (LLMs), while memorizing parts of their training data scraped from the Internet, may also inadvertently encode societal preferences and norms. As these models are integrated into sociotechnical systems, it is crucial that the norms they encode align with societal expectations. These norms could vary across models, hyperparameters, optimization techniques, and datasets. This is especially challenging due to prompt sensitivity$-$small variations in prompts yield different responses, rendering existing assessment methodologies unreliable. There is a need for a comprehensive framework covering various models, optimization, and datasets, along with a reliable methodology to assess encoded norms. We present LLM-CI, the first open-sourced framework to assess privacy norms encoded in LLMs. LLM-CI uses a Contextual Integrity-based factorial vignette methodology to assess the encoded norms across different contexts and LLMs. We propose the multi-prompt assessment methodology to address prompt sensitivity by assessing the norms from only the prompts that yield consistent responses across multiple variants. Using LLM-CI and our proposed methodology, we comprehensively evaluate LLMs using IoT and COPPA vignettes datasets from prior work, examining the impact of model properties (e.g., hyperparameters, capacity) and optimization strategies (e.g., alignment, quantization).
Espresso: Robust Concept Filtering in Text-to-Image Models
May 01, 2024



Diffusion-based text-to-image (T2I) models generate high-fidelity images for given textual prompts. They are trained on large datasets scraped from the Internet, potentially containing unacceptable concepts (e.g., copyright infringing or unsafe). Retraining T2I models after filtering out unacceptable concepts in the training data is inefficient and degrades utility. Hence, there is a need for concept removal techniques (CRTs) which are effective in removing unacceptable concepts, utility-preserving on acceptable concepts, and robust against evasion with adversarial prompts. None of the prior filtering and fine-tuning CRTs satisfy all these requirements simultaneously. We introduce Espresso, the first robust concept filter based on Contrastive Language-Image Pre-Training (CLIP). It identifies unacceptable concepts by projecting the generated image's embedding onto the vector connecting unacceptable and acceptable concepts in the joint text-image embedding space. This ensures robustness by restricting the adversary to adding noise only along this vector, in the direction of the acceptable concept. Further fine-tuning Espresso to separate embeddings of acceptable and unacceptable concepts, while preserving their pairing with image embeddings, ensures both effectiveness and utility. We evaluate Espresso on eleven concepts to show that it is effective (~5% CLIP accuracy on unacceptable concepts), utility-preserving (~93% normalized CLIP score on acceptable concepts), and robust (~4% CLIP accuracy on adversarial prompts for unacceptable concepts). Finally, we present theoretical bounds for the certified robustness of Espresso against adversarial prompts, and an empirical analysis.
SoK: Unintended Interactions among Machine Learning Defenses and Risks
Dec 07, 2023



Machine learning (ML) models cannot neglect risks to security, privacy, and fairness. Several defenses have been proposed to mitigate such risks. When a defense is effective in mitigating one risk, it may correspond to increased or decreased susceptibility to other risks. Existing research lacks an effective framework to recognize and explain these unintended interactions. We present such a framework, based on the conjecture that overfitting and memorization underlie unintended interactions. We survey existing literature on unintended interactions, accommodating them within our framework. We use our framework to conjecture on two previously unexplored interactions, and empirically validate our conjectures.
Attesting Distributional Properties of Training Data for Machine Learning
Aug 18, 2023



The success of machine learning (ML) has been accompanied by increased concerns about its trustworthiness. Several jurisdictions are preparing ML regulatory frameworks. One such concern is ensuring that model training data has desirable distributional properties for certain sensitive attributes. For example, draft regulations indicate that model trainers are required to show that training datasets have specific distributional properties, such as reflecting diversity of the population. We propose the notion of property attestation allowing a prover (e.g., model trainer) to demonstrate relevant distributional properties of training data to a verifier (e.g., a customer) without revealing the data. We present an effective hybrid property attestation combining property inference with cryptographic mechanisms.
GrOVe: Ownership Verification of Graph Neural Networks using Embeddings
Apr 17, 2023



Graph neural networks (GNNs) have emerged as a state-of-the-art approach to model and draw inferences from large scale graph-structured data in various application settings such as social networking. The primary goal of a GNN is to learn an embedding for each graph node in a dataset that encodes both the node features and the local graph structure around the node. Embeddings generated by a GNN for a graph node are unique to that GNN. Prior work has shown that GNNs are prone to model extraction attacks. Model extraction attacks and defenses have been explored extensively in other non-graph settings. While detecting or preventing model extraction appears to be difficult, deterring them via effective ownership verification techniques offer a potential defense. In non-graph settings, fingerprinting models, or the data used to build them, have shown to be a promising approach toward ownership verification. We present GrOVe, a state-of-the-art GNN model fingerprinting scheme that, given a target model and a suspect model, can reliably determine if the suspect model was trained independently of the target model or if it is a surrogate of the target model obtained via model extraction. We show that GrOVe can distinguish between surrogate and independent models even when the independent model uses the same training dataset and architecture as the original target model. Using six benchmark datasets and three model architectures, we show that consistently achieves low false-positive and false-negative rates. We demonstrate that is robust against known fingerprint evasion techniques while remaining computationally efficient.
Leveraging Algorithmic Fairness to Mitigate Blackbox Attribute Inference Attacks
Nov 18, 2022Machine learning (ML) models have been deployed for high-stakes applications, e.g., healthcare and criminal justice. Prior work has shown that ML models are vulnerable to attribute inference attacks where an adversary, with some background knowledge, trains an ML attack model to infer sensitive attributes by exploiting distinguishable model predictions. However, some prior attribute inference attacks have strong assumptions about adversary's background knowledge (e.g., marginal distribution of sensitive attribute) and pose no more privacy risk than statistical inference. Moreover, none of the prior attacks account for class imbalance of sensitive attribute in datasets coming from real-world applications (e.g., Race and Sex). In this paper, we propose an practical and effective attribute inference attack that accounts for this imbalance using an adaptive threshold over the attack model's predictions. We exhaustively evaluate our proposed attack on multiple datasets and show that the adaptive threshold over the model's predictions drastically improves the attack accuracy over prior work. Finally, current literature lacks an effective defence against attribute inference attacks. We investigate the impact of fairness constraints (i.e., designed to mitigate unfairness in model predictions) during model training on our attribute inference attack. We show that constraint based fairness algorithms which enforces equalized odds acts as an effective defense against attribute inference attacks without impacting the model utility. Hence, the objective of algorithmic fairness and sensitive attribute privacy are aligned.
Inferring Sensitive Attributes from Model Explanations
Aug 21, 2022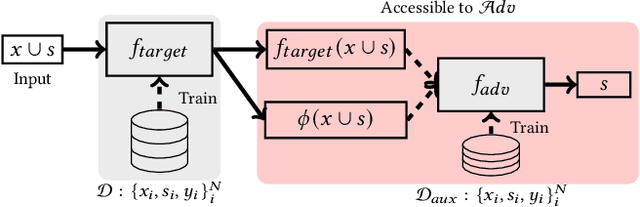
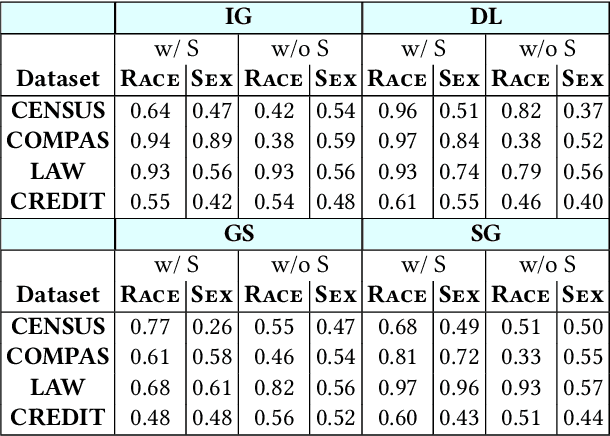
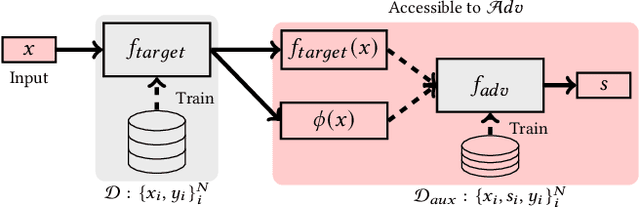
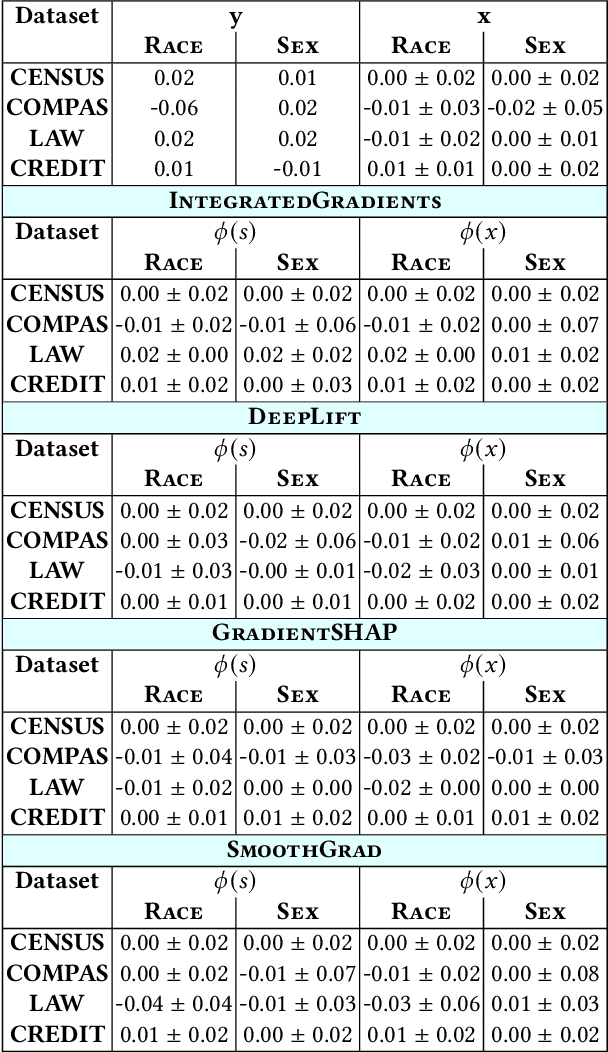
Model explanations provide transparency into a trained machine learning model's blackbox behavior to a model builder. They indicate the influence of different input attributes to its corresponding model prediction. The dependency of explanations on input raises privacy concerns for sensitive user data. However, current literature has limited discussion on privacy risks of model explanations. We focus on the specific privacy risk of attribute inference attack wherein an adversary infers sensitive attributes of an input (e.g., race and sex) given its model explanations. We design the first attribute inference attack against model explanations in two threat models where model builder either (a) includes the sensitive attributes in training data and input or (b) censors the sensitive attributes by not including them in the training data and input. We evaluate our proposed attack on four benchmark datasets and four state-of-the-art algorithms. We show that an adversary can successfully infer the value of sensitive attributes from explanations in both the threat models accurately. Moreover, the attack is successful even by exploiting only the explanations corresponding to sensitive attributes. These suggest that our attack is effective against explanations and poses a practical threat to data privacy. On combining the model predictions (an attack surface exploited by prior attacks) with explanations, we note that the attack success does not improve. Additionally, the attack success on exploiting model explanations is better compared to exploiting only model predictions. These suggest that model explanations are a strong attack surface to exploit for an adversary.