 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Registration
Papers and Code
A Multi-Mode Structured Light 3D Imaging System with Multi-Source Information Fusion for Underwater Pipeline Detection
Dec 12, 2025



Underwater pipelines are highly susceptible to corrosion, which not only shorten their service life but also pose significant safety risks. Compared with manual inspection, the intelligent real-time imaging system for underwater pipeline detection has become a more reliable and practical solution. Among various underwater imaging techniques, structured light 3D imaging can restore the sufficient spatial detail for precise defect characterization. Therefore, this paper develops a multi-mode underwater structured light 3D imaging system for pipeline detection (UW-SLD system) based on multi-source information fusion. First, a rapid distortion correction (FDC) method is employed for efficient underwater image rectification. To overcome the challenges of extrinsic calibration among underwater sensors, a factor graph-based parameter optimization method is proposed to estimate the transformation matrix between the structured light and acoustic sensors. Furthermore, a multi-mode 3D imaging strategy is introduced to adapt to the geometric variability of underwater pipelines. Given the presence of numerous disturbances in underwater environments, a multi-source information fusion strategy and an adaptive extended Kalman filter (AEKF) are designed to ensure stable pose estimation and high-accuracy measurements. In particular, an edge detection-based ICP (ED-ICP) algorithm is proposed. This algorithm integrates pipeline edge detection network with enhanced point cloud registration to achieve robust and high-fidelity reconstruction of defect structures even under variable motion conditions. Extensive experiments are conducted under different operation modes, velocities, and depths. The results demonstrate that the developed system achieves superior accuracy, adaptability and robustness, providing a solid foundation for autonomous underwater pipeline detection.
FUSER: Feed-Forward MUltiview 3D Registration Transformer and SE(3)$^N$ Diffusion Refinement
Dec 10, 2025Registration of multiview point clouds conventionally relies on extensive pairwise matching to build a pose graph for global synchronization, which is computationally expensive and inherently ill-posed without holistic geometric constraints. This paper proposes FUSER, the first feed-forward multiview registration transformer that jointly processes all scans in a unified, compact latent space to directly predict global poses without any pairwise estimation. To maintain tractability, FUSER encodes each scan into low-resolution superpoint features via a sparse 3D CNN that preserves absolute translation cues, and performs efficient intra- and inter-scan reasoning through a Geometric Alternating Attention module. Particularly, we transfer 2D attention priors from off-the-shelf foundation models to enhance 3D feature interaction and geometric consistency. Building upon FUSER, we further introduce FUSER-DF, an SE(3)$^N$ diffusion refinement framework to correct FUSER's estimates via denoising in the joint SE(3)$^N$ space. FUSER acts as a surrogate multiview registration model to construct the denoiser, and a prior-conditioned SE(3)$^N$ variational lower bound is derived for denoising supervision. Extensive experiments on 3DMatch, ScanNet and ArkitScenes demonstrate that our approach achieves the superior registration accuracy and outstanding computational efficiency.
Adaptive Agent Selection and Interaction Network for Image-to-point cloud Registration
Nov 08, 2025Typical detection-free methods for image-to-point cloud registration leverage transformer-based architectures to aggregate cross-modal features and establish correspondences. However, they often struggle under challenging conditions, where noise disrupts similarity computation and leads to incorrect correspondences. Moreover, without dedicated designs, it remains difficult to effectively select informative and correlated representations across modalities, thereby limiting the robustness and accuracy of registration. To address these challenges, we propose a novel cross-modal registration framework composed of two key modules: the Iterative Agents Selection (IAS) module and the Reliable Agents Interaction (RAI) module. IAS enhances structural feature awareness with phase maps and employs reinforcement learning principles to efficiently select reliable agents. RAI then leverages these selected agents to guide cross-modal interactions, effectively reducing mismatches and improving overall robustness. Extensive experiments on the RGB-D Scenes v2 and 7-Scenes benchmarks demonstrate that our method consistently achieves state-of-the-art performance.
IPCD: Intrinsic Point-Cloud Decomposition
Nov 13, 2025Point clouds are widely used in various fields, including augmented reality (AR) and robotics, where relighting and texture editing are crucial for realistic visualization. Achieving these tasks requires accurately separating albedo from shade. However, performing this separation on point clouds presents two key challenges: (1) the non-grid structure of point clouds makes conventional image-based decomposition models ineffective, and (2) point-cloud models designed for other tasks do not explicitly consider global-light direction, resulting in inaccurate shade. In this paper, we introduce \textbf{Intrinsic Point-Cloud Decomposition (IPCD)}, which extends image decomposition to the direct decomposition of colored point clouds into albedo and shade. To overcome challenge (1), we propose \textbf{IPCD-Net} that extends image-based model with point-wise feature aggregation for non-grid data processing. For challenge (2), we introduce \textbf{Projection-based Luminance Distribution (PLD)} with a hierarchical feature refinement, capturing global-light ques via multi-view projection. For comprehensive evaluation, we create a synthetic outdoor-scene dataset. Experimental results demonstrate that IPCD-Net reduces cast shadows in albedo and enhances color accuracy in shade. Furthermore, we showcase its applications in texture editing, relighting, and point-cloud registration under varying illumination. Finally, we verify the real-world applicability of IPCD-Net.
FUSE: A Flow-based Mapping Between Shapes
Nov 17, 2025



We introduce a novel neural representation for maps between 3D shapes based on flow-matching models, which is computationally efficient and supports cross-representation shape matching without large-scale training or data-driven procedures. 3D shapes are represented as the probability distribution induced by a continuous and invertible flow mapping from a fixed anchor distribution. Given a source and a target shape, the composition of the inverse flow (source to anchor) with the forward flow (anchor to target), we continuously map points between the two surfaces. By encoding the shapes with a pointwise task-tailored embedding, this construction provides an invertible and modality-agnostic representation of maps between shapes across point clouds, meshes, signed distance fields (SDFs), and volumetric data. The resulting representation consistently achieves high coverage and accuracy across diverse benchmarks and challenging settings in shape matching. Beyond shape matching, our framework shows promising results in other tasks, including UV mapping and registration of raw point cloud scans of human bodies.
ArtReg: Visuo-Tactile based Pose Tracking and Manipulation of Unseen Articulated Objects
Nov 09, 2025



Robots operating in real-world environments frequently encounter unknown objects with complex structures and articulated components, such as doors, drawers, cabinets, and tools. The ability to perceive, track, and manipulate these objects without prior knowledge of their geometry or kinematic properties remains a fundamental challenge in robotics. In this work, we present a novel method for visuo-tactile-based tracking of unseen objects (single, multiple, or articulated) during robotic interaction without assuming any prior knowledge regarding object shape or dynamics. Our novel pose tracking approach termed ArtReg (stands for Articulated Registration) integrates visuo-tactile point clouds in an unscented Kalman Filter formulation in the SE(3) Lie Group for point cloud registration. ArtReg is used to detect possible articulated joints in objects using purposeful manipulation maneuvers such as pushing or hold-pulling with a two-robot team. Furthermore, we leverage ArtReg to develop a closed-loop controller for goal-driven manipulation of articulated objects to move the object into the desired pose configuration. We have extensively evaluated our approach on various types of unknown objects through real robot experiments. We also demonstrate the robustness of our method by evaluating objects with varying center of mass, low-light conditions, and with challenging visual backgrounds. Furthermore, we benchmarked our approach on a standard dataset of articulated objects and demonstrated improved performance in terms of pose accuracy compared to state-of-the-art methods. Our experiments indicate that robust and accurate pose tracking leveraging visuo-tactile information enables robots to perceive and interact with unseen complex articulated objects (with revolute or prismatic joints).
Registration-Free Monitoring of Unstructured Point Cloud Data via Intrinsic Geometrical Properties
Nov 06, 2025Modern sensing technologies have enabled the collection of unstructured point cloud data (PCD) of varying sizes, which are used to monitor the geometric accuracy of 3D objects. PCD are widely applied in advanced manufacturing processes, including additive, subtractive, and hybrid manufacturing. To ensure the consistency of analysis and avoid false alarms, preprocessing steps such as registration and mesh reconstruction are commonly applied prior to monitoring. However, these steps are error-prone, time-consuming and may introduce artifacts, potentially affecting monitoring outcomes. In this paper, we present a novel registration-free approach for monitoring PCD of complex shapes, eliminating the need for both registration and mesh reconstruction. Our proposal consists of two alternative feature learning methods and a common monitoring scheme. Feature learning methods leverage intrinsic geometric properties of the shape, captured via the Laplacian and geodesic distances. In the monitoring scheme, thresholding techniques are used to further select intrinsic features most indicative of potential out-of-control conditions. Numerical experiments and case studies highlight the effectiveness of the proposed approach in identifying different types of defects.
NeuralBoneReg: A Novel Self-Supervised Method for Robust and Accurate Multi-Modal Bone Surface Registration
Nov 18, 2025In computer- and robot-assisted orthopedic surgery (CAOS), patient-specific surgical plans derived from preoperative imaging define target locations and implant trajectories. During surgery, these plans must be accurately transferred, relying on precise cross-registration between preoperative and intraoperative data. However, substantial modality heterogeneity across imaging modalities makes this registration challenging and error-prone. Robust, automatic, and modality-agnostic bone surface registration is therefore clinically important. We propose NeuralBoneReg, a self-supervised, surface-based framework that registers bone surfaces using 3D point clouds as a modality-agnostic representation. NeuralBoneReg includes two modules: an implicit neural unsigned distance field (UDF) that learns the preoperative bone model, and an MLP-based registration module that performs global initialization and local refinement by generating transformation hypotheses to align the intraoperative point cloud with the neural UDF. Unlike SOTA supervised methods, NeuralBoneReg operates in a self-supervised manner, without requiring inter-subject training data. We evaluated NeuralBoneReg against baseline methods on two publicly available multi-modal datasets: a CT-ultrasound dataset of the fibula and tibia (UltraBones100k) and a CT-RGB-D dataset of spinal vertebrae (SpineDepth). The evaluation also includes a newly introduced CT--ultrasound dataset of cadaveric subjects containing femur and pelvis (UltraBones-Hip), which will be made publicly available. NeuralBoneReg matches or surpasses existing methods across all datasets, achieving mean RRE/RTE of 1.68°/1.86 mm on UltraBones100k, 1.88°/1.89 mm on UltraBones-Hip, and 3.79°/2.45 mm on SpineDepth. These results demonstrate strong generalizability across anatomies and modalities, providing robust and accurate cross-modal alignment for CAOS.
Breaking the Static Assumption: A Dynamic-Aware LIO Framework Via Spatio-Temporal Normal Analysis
Oct 25, 2025This paper addresses the challenge of Lidar-Inertial Odometry (LIO) in dynamic environments, where conventional methods often fail due to their static-world assumptions. Traditional LIO algorithms perform poorly when dynamic objects dominate the scenes, particularly in geometrically sparse environments. Current approaches to dynamic LIO face a fundamental challenge: accurate localization requires a reliable identification of static features, yet distinguishing dynamic objects necessitates precise pose estimation. Our solution breaks this circular dependency by integrating dynamic awareness directly into the point cloud registration process. We introduce a novel dynamic-aware iterative closest point algorithm that leverages spatio-temporal normal analysis, complemented by an efficient spatial consistency verification method to enhance static map construction. Experimental evaluations demonstrate significant performance improvements over state-of-the-art LIO systems in challenging dynamic environments with limited geometric structure. The code and dataset are available at https://github.com/thisparticle/btsa.
HOTFLoc++: End-to-End Hierarchical LiDAR Place Recognition, Re-Ranking, and 6-DoF Metric Localisation in Forests
Nov 12, 2025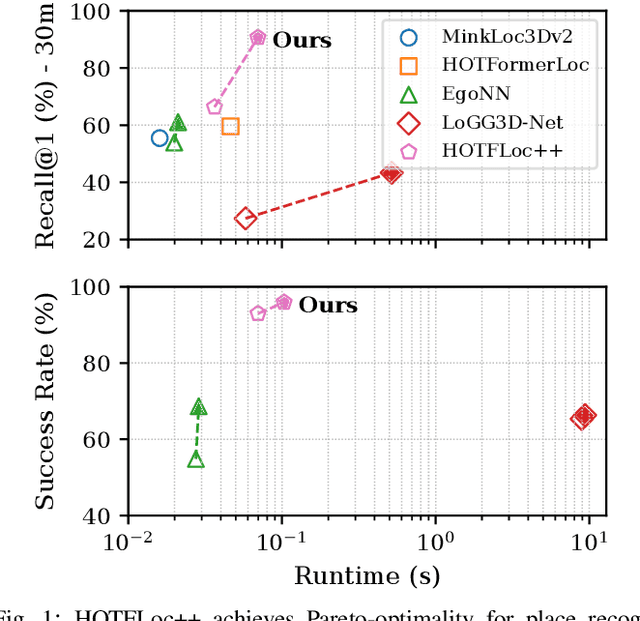
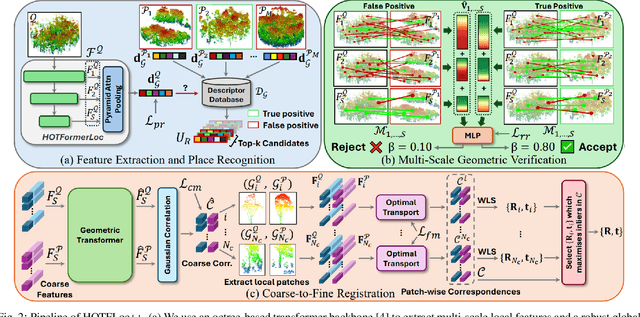

This article presents HOTFLoc++, an end-to-end framework for LiDAR place recognition, re-ranking, and 6-DoF metric localisation in forests. Leveraging an octree-based transformer, our approach extracts hierarchical local descriptors at multiple granularities to increase robustness to clutter, self-similarity, and viewpoint changes in challenging scenarios, including ground-to-ground and ground-to-aerial in forest and urban environments. We propose a learnable multi-scale geometric verification module to reduce re-ranking failures in the presence of degraded single-scale correspondences. Our coarse-to-fine registration approach achieves comparable or lower localisation errors to baselines, with runtime improvements of two orders of magnitude over RANSAC for dense point clouds. Experimental results on public datasets show the superiority of our approach compared to state-of-the-art methods, achieving an average Recall@1 of 90.7% on CS-Wild-Places: an improvement of 29.6 percentage points over baselines, while maintaining high performance on single-source benchmarks with an average Recall@1 of 91.7% and 96.0% on Wild-Places and MulRan, respectively. Our method achieves under 2 m and 5 degrees error for 97.2% of 6-DoF registration attempts, with our multi-scale re-ranking module reducing localisation errors by ~2$\times$ on average. The code will be available upon acceptance.