 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefacial recognition
Facial recognition is an AI-based technique for identifying or confirming an individual's identity using their face. It maps facial features from an image or video and then compares the information with a collection of known faces to find a match.
Papers and Code
Learning Transferable Facial Emotion Representations from Large-Scale Semantically Rich Captions
Jul 28, 2025Current facial emotion recognition systems are predominately trained to predict a fixed set of predefined categories or abstract dimensional values. This constrained form of supervision hinders generalization and applicability, as it reduces the rich and nuanced spectrum of emotions into oversimplified labels or scales. In contrast, natural language provides a more flexible, expressive, and interpretable way to represent emotions, offering a much broader source of supervision. Yet, leveraging semantically rich natural language captions as supervisory signals for facial emotion representation learning remains relatively underexplored, primarily due to two key challenges: 1) the lack of large-scale caption datasets with rich emotional semantics, and 2) the absence of effective frameworks tailored to harness such rich supervision. To this end, we introduce EmoCap100K, a large-scale facial emotion caption dataset comprising over 100,000 samples, featuring rich and structured semantic descriptions that capture both global affective states and fine-grained local facial behaviors. Building upon this dataset, we further propose EmoCapCLIP, which incorporates a joint global-local contrastive learning framework enhanced by a cross-modal guided positive mining module. This design facilitates the comprehensive exploitation of multi-level caption information while accommodating semantic similarities between closely related expressions. Extensive evaluations on over 20 benchmarks covering five tasks demonstrate the superior performance of our method, highlighting the promise of learning facial emotion representations from large-scale semantically rich captions. The code and data will be available at https://github.com/sunlicai/EmoCapCLIP.
Multimodal Prompt Alignment for Facial Expression Recognition
Jun 26, 2025Prompt learning has been widely adopted to efficiently adapt vision-language models (VLMs) like CLIP for various downstream tasks. Despite their success, current VLM-based facial expression recognition (FER) methods struggle to capture fine-grained textual-visual relationships, which are essential for distinguishing subtle differences between facial expressions. To address this challenge, we propose a multimodal prompt alignment framework for FER, called MPA-FER, that provides fine-grained semantic guidance to the learning process of prompted visual features, resulting in more precise and interpretable representations. Specifically, we introduce a multi-granularity hard prompt generation strategy that utilizes a large language model (LLM) like ChatGPT to generate detailed descriptions for each facial expression. The LLM-based external knowledge is injected into the soft prompts by minimizing the feature discrepancy between the soft prompts and the hard prompts. To preserve the generalization abilities of the pretrained CLIP model, our approach incorporates prototype-guided visual feature alignment, ensuring that the prompted visual features from the frozen image encoder align closely with class-specific prototypes. Additionally, we propose a cross-modal global-local alignment module that focuses on expression-relevant facial features, further improving the alignment between textual and visual features. Extensive experiments demonstrate our framework outperforms state-of-the-art methods on three FER benchmark datasets, while retaining the benefits of the pretrained model and minimizing computational costs.
Reading Smiles: Proxy Bias in Foundation Models for Facial Emotion Recognition
Jun 23, 2025Foundation Models (FMs) are rapidly transforming Affective Computing (AC), with Vision Language Models (VLMs) now capable of recognising emotions in zero shot settings. This paper probes a critical but underexplored question: what visual cues do these models rely on to infer affect, and are these cues psychologically grounded or superficially learnt? We benchmark varying scale VLMs on a teeth annotated subset of AffectNet dataset and find consistent performance shifts depending on the presence of visible teeth. Through structured introspection of, the best-performing model, i.e., GPT-4o, we show that facial attributes like eyebrow position drive much of its affective reasoning, revealing a high degree of internal consistency in its valence-arousal predictions. These patterns highlight the emergent nature of FMs behaviour, but also reveal risks: shortcut learning, bias, and fairness issues especially in sensitive domains like mental health and education.
Autonomous AI Surveillance: Multimodal Deep Learning for Cognitive and Behavioral Monitoring
Jul 02, 2025



This study presents a novel classroom surveillance system that integrates multiple modalities, including drowsiness, tracking of mobile phone usage, and face recognition,to assess student attentiveness with enhanced precision.The system leverages the YOLOv8 model to detect both mobile phone and sleep usage,(Ghatge et al., 2024) while facial recognition is achieved through LResNet Occ FC body tracking using YOLO and MTCNN.(Durai et al., 2024) These models work in synergy to provide comprehensive, real-time monitoring, offering insights into student engagement and behavior.(S et al., 2023) The framework is trained on specialized datasets, such as the RMFD dataset for face recognition and a Roboflow dataset for mobile phone detection. The extensive evaluation of the system shows promising results. Sleep detection achieves 97. 42% mAP@50, face recognition achieves 86. 45% validation accuracy and mobile phone detection reach 85. 89% mAP@50. The system is implemented within a core PHP web application and utilizes ESP32-CAM hardware for seamless data capture.(Neto et al., 2024) This integrated approach not only enhances classroom monitoring, but also ensures automatic attendance recording via face recognition as students remain seated in the classroom, offering scalability for diverse educational environments.(Banada,2025)
CAST-Phys: Contactless Affective States Through Physiological signals Database
Jul 08, 2025In recent years, affective computing and its applications have become a fast-growing research topic. Despite significant advancements, the lack of affective multi-modal datasets remains a major bottleneck in developing accurate emotion recognition systems. Furthermore, the use of contact-based devices during emotion elicitation often unintentionally influences the emotional experience, reducing or altering the genuine spontaneous emotional response. This limitation highlights the need for methods capable of extracting affective cues from multiple modalities without physical contact, such as remote physiological emotion recognition. To address this, we present the Contactless Affective States Through Physiological Signals Database (CAST-Phys), a novel high-quality dataset explicitly designed for multi-modal remote physiological emotion recognition using facial and physiological cues. The dataset includes diverse physiological signals, such as photoplethysmography (PPG), electrodermal activity (EDA), and respiration rate (RR), alongside high-resolution uncompressed facial video recordings, enabling the potential for remote signal recovery. Our analysis highlights the crucial role of physiological signals in realistic scenarios where facial expressions alone may not provide sufficient emotional information. Furthermore, we demonstrate the potential of remote multi-modal emotion recognition by evaluating the impact of individual and fused modalities, showcasing its effectiveness in advancing contactless emotion recognition technologies.
Bridging the gap in FER: addressing age bias in deep learning
Jul 10, 2025
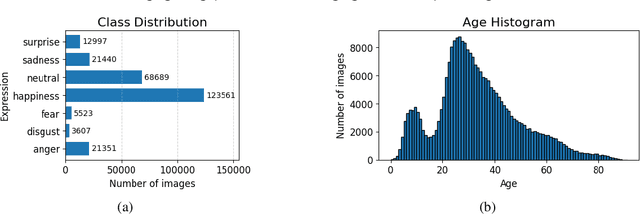
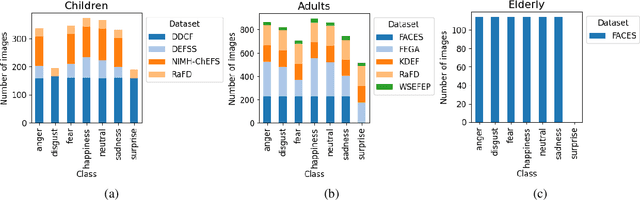
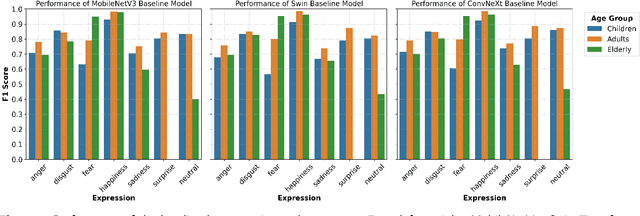
Facial Expression Recognition (FER) systems based on deep learning have achieved impressive performance in recent years. However, these models often exhibit demographic biases, particularly with respect to age, which can compromise their fairness and reliability. In this work, we present a comprehensive study of age-related bias in deep FER models, with a particular focus on the elderly population. We first investigate whether recognition performance varies across age groups, which expressions are most affected, and whether model attention differs depending on age. Using Explainable AI (XAI) techniques, we identify systematic disparities in expression recognition and attention patterns, especially for "neutral", "sadness", and "anger" in elderly individuals. Based on these findings, we propose and evaluate three bias mitigation strategies: Multi-task Learning, Multi-modal Input, and Age-weighted Loss. Our models are trained on a large-scale dataset, AffectNet, with automatically estimated age labels and validated on balanced benchmark datasets that include underrepresented age groups. Results show consistent improvements in recognition accuracy for elderly individuals, particularly for the most error-prone expressions. Saliency heatmap analysis reveals that models trained with age-aware strategies attend to more relevant facial regions for each age group, helping to explain the observed improvements. These findings suggest that age-related bias in FER can be effectively mitigated using simple training modifications, and that even approximate demographic labels can be valuable for promoting fairness in large-scale affective computing systems.
Color histogram equalization and fine-tuning to improve expression recognition of (partially occluded) faces on sign language datasets
Jul 27, 2025The goal of this investigation is to quantify to what extent computer vision methods can correctly classify facial expressions on a sign language dataset. We extend our experiments by recognizing expressions using only the upper or lower part of the face, which is needed to further investigate the difference in emotion manifestation between hearing and deaf subjects. To take into account the peculiar color profile of a dataset, our method introduces a color normalization stage based on histogram equalization and fine-tuning. The results show the ability to correctly recognize facial expressions with 83.8% mean sensitivity and very little variance (.042) among classes. Like for humans, recognition of expressions from the lower half of the face (79.6%) is higher than that from the upper half (77.9%). Noticeably, the classification accuracy from the upper half of the face is higher than human level.
FG 2025 TrustFAA: the First Workshop on Towards Trustworthy Facial Affect Analysis: Advancing Insights of Fairness, Explainability, and Safety (TrustFAA)
Jun 05, 2025With the increasing prevalence and deployment of Emotion AI-powered facial affect analysis (FAA) tools, concerns about the trustworthiness of these systems have become more prominent. This first workshop on "Towards Trustworthy Facial Affect Analysis: Advancing Insights of Fairness, Explainability, and Safety (TrustFAA)" aims to bring together researchers who are investigating different challenges in relation to trustworthiness-such as interpretability, uncertainty, biases, and privacy-across various facial affect analysis tasks, including macro/ micro-expression recognition, facial action unit detection, other corresponding applications such as pain and depression detection, as well as human-robot interaction and collaboration. In alignment with FG2025's emphasis on ethics, as demonstrated by the inclusion of an Ethical Impact Statement requirement for this year's submissions, this workshop supports FG2025's efforts by encouraging research, discussion and dialogue on trustworthy FAA.
AU-Blendshape for Fine-grained Stylized 3D Facial Expression Manipulation
Jul 16, 2025



While 3D facial animation has made impressive progress, challenges still exist in realizing fine-grained stylized 3D facial expression manipulation due to the lack of appropriate datasets. In this paper, we introduce the AUBlendSet, a 3D facial dataset based on AU-Blendshape representation for fine-grained facial expression manipulation across identities. AUBlendSet is a blendshape data collection based on 32 standard facial action units (AUs) across 500 identities, along with an additional set of facial postures annotated with detailed AUs. Based on AUBlendSet, we propose AUBlendNet to learn AU-Blendshape basis vectors for different character styles. AUBlendNet predicts, in parallel, the AU-Blendshape basis vectors of the corresponding style for a given identity mesh, thereby achieving stylized 3D emotional facial manipulation. We comprehensively validate the effectiveness of AUBlendSet and AUBlendNet through tasks such as stylized facial expression manipulation, speech-driven emotional facial animation, and emotion recognition data augmentation. Through a series of qualitative and quantitative experiments, we demonstrate the potential and importance of AUBlendSet and AUBlendNet in 3D facial animation tasks. To the best of our knowledge, AUBlendSet is the first dataset, and AUBlendNet is the first network for continuous 3D facial expression manipulation for any identity through facial AUs. Our source code is available at https://github.com/wslh852/AUBlendNet.git.
VisualSpeaker: Visually-Guided 3D Avatar Lip Synthesis
Jul 08, 2025



Realistic, high-fidelity 3D facial animations are crucial for expressive avatar systems in human-computer interaction and accessibility. Although prior methods show promising quality, their reliance on the mesh domain limits their ability to fully leverage the rapid visual innovations seen in 2D computer vision and graphics. We propose VisualSpeaker, a novel method that bridges this gap using photorealistic differentiable rendering, supervised by visual speech recognition, for improved 3D facial animation. Our contribution is a perceptual lip-reading loss, derived by passing photorealistic 3D Gaussian Splatting avatar renders through a pre-trained Visual Automatic Speech Recognition model during training. Evaluation on the MEAD dataset demonstrates that VisualSpeaker improves both the standard Lip Vertex Error metric by 56.1% and the perceptual quality of the generated animations, while retaining the controllability of mesh-driven animation. This perceptual focus naturally supports accurate mouthings, essential cues that disambiguate similar manual signs in sign language avatars.