 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreak to Protect: Buffering and Reinforcing via Temporary Jailbreaking for Safe Fine-Tuning in Large Language Models
May 23, 2026Fine-tuning-as-a-Service (FaaS) enables personalization of large language models (LLMs), but it can weaken safety-alignment under harmful fine-tuning attacks. Recent work has shown that activating harmful-behavior modules during fine-tuning can prevent models from learning undesired behaviors, but its mechanism remains unclear. In this paper, we revisit temporary jailbreaking as a defense against harmful fine-tuning and provide a gradient-level analysis showing that it saturates safety-degrading gradients while preserving benign task-relevant gradients. Based on this insight, we propose a Buffer-and-Reinforce fine-tuning framework that buffers harmful updates during user fine-tuning and reinforces safety after adaptation. Specifically, BufferLoRA induces temporary jailbreaking as a removable adapter to reduce harmful updates during user fine-tuning. After adaptation, ReinforceLoRA, trained to recover refusal behavior under the temporarily jailbroken state, is integrated with UserLoRA via QR decomposition-based merging to reinforce safety while preserving user-task performance. Extensive experiments show that our framework achieves superior safety and utility with no additional safety data during user fine-tuning and minimal computational cost.
Understanding Latent Diffusability via Fisher Geometry
Apr 03, 2026Diffusion models often degrade when trained in latent spaces (e.g., VAEs), yet the formal causes remain poorly understood. We quantify latent-space diffusability through the rate of change of the Minimum Mean Squared Error (MMSE) along the diffusion trajectory. Our framework decomposes this MMSE rate into contributions from Fisher Information (FI) and Fisher Information Rate (FIR). We demonstrate that while global isometry ensures FI alignment, FIR is governed by the encoder's local geometric properties. Our analysis explicitly decouples latent geometric distortion into three measurable penalties: dimensional compression, tangential distortion, and curvature injection. We derive theoretical conditions for FIR preservation across spaces, ensuring maintained diffusability. Experiments across diverse autoencoding architectures validate our framework and establish these efficient FI and FIR metrics as a robust diagnostic suite for identifying and mitigating latent diffusion failure.
IgPose: A Generative Data-Augmented Pipeline for Robust Immunoglobulin-Antigen Binding Prediction
Mar 16, 2026Predicting immunoglobulin-antigen (Ig-Ag) binding remains a significant challenge due to the paucity of experimentally-resolved complexes and the limited accuracy of de novo Ig structure prediction. We introduce IgPose, a generalizable framework for Ig-Ag pose identification and scoring, built on a generative data-augmentation pipeline. To mitigate data scarcity, we constructed the Structural Immunoglobulin Decoy Database (SIDD), a comprehensive repository of high-fidelity synthetic decoys. IgPose integrates equivariant graph neural networks, ESM-2 embeddings, and gated recurrent units to synergistically capture both geometric and evolutionary features. We implemented interface-focused k-hop sampling with biologically guided pooling to enhance generalization across diverse interfaces. The framework comprises two sub-networks--IgPoseClassifier for binding pose discrimination and IgPoseScore for DockQ score estimation--and achieves robust performance on curated internal test sets and the CASP-16 benchmark compared to physics and deep learning baselines. IgPose serves as a versatile computational tool for high-throughput antibody discovery pipelines by providing accurate pose filtering and ranking. IgPose is available on GitHub (https://github.com/arontier/igpose).
* 11 pages, 4 figures, Bioinformatics
Efficient Test-Time Optimization for Depth Completion via Low-Rank Decoder Adaptation
Mar 03, 2026Zero-shot depth completion has gained attention for its ability to generalize across environments without sensor-specific datasets or retraining. However, most existing approaches rely on diffusion-based test-time optimization, which is computationally expensive due to iterative denoising. Recent visual-prompt-based methods reduce training cost but still require repeated forward--backward passes through the full frozen network to optimize input-level prompts, resulting in slow inference. In this work, we show that adapting only the decoder is sufficient for effective test-time optimization, as depth foundation models concentrate depth-relevant information within a low-dimensional decoder subspace. Based on this insight, we propose a lightweight test-time adaptation method that updates only this low-dimensional subspace using sparse depth supervision. Our approach achieves state-of-the-art performance, establishing a new Pareto frontier between accuracy and efficiency for test-time adaptation. Extensive experiments on five indoor and outdoor datasets demonstrate consistent improvements over prior methods, highlighting the practicality of fast zero-shot depth completion.
Mixture-of-Experts with Intermediate CTC Supervision for Accented Speech Recognition
Feb 02, 2026Accented speech remains a persistent challenge for automatic speech recognition (ASR), as most models are trained on data dominated by a few high-resource English varieties, leading to substantial performance degradation for other accents. Accent-agnostic approaches improve robustness yet struggle with heavily accented or unseen varieties, while accent-specific methods rely on limited and often noisy labels. We introduce Moe-Ctc, a Mixture-of-Experts architecture with intermediate CTC supervision that jointly promotes expert specialization and generalization. During training, accent-aware routing encourages experts to capture accent-specific patterns, which gradually transitions to label-free routing for inference. Each expert is equipped with its own CTC head to align routing with transcription quality, and a routing-augmented loss further stabilizes optimization. Experiments on the Mcv-Accent benchmark demonstrate consistent gains across both seen and unseen accents in low- and high-resource conditions, achieving up to 29.3% relative WER reduction over strong FastConformer baselines.
Jailbreaking on Text-to-Video Models via Scene Splitting Strategy
Sep 26, 2025Along with the rapid advancement of numerous Text-to-Video (T2V) models, growing concerns have emerged regarding their safety risks. While recent studies have explored vulnerabilities in models like LLMs, VLMs, and Text-to-Image (T2I) models through jailbreak attacks, T2V models remain largely unexplored, leaving a significant safety gap. To address this gap, we introduce SceneSplit, a novel black-box jailbreak method that works by fragmenting a harmful narrative into multiple scenes, each individually benign. This approach manipulates the generative output space, the abstract set of all potential video outputs for a given prompt, using the combination of scenes as a powerful constraint to guide the final outcome. While each scene individually corresponds to a wide and safe space where most outcomes are benign, their sequential combination collectively restricts this space, narrowing it to an unsafe region and significantly increasing the likelihood of generating a harmful video. This core mechanism is further enhanced through iterative scene manipulation, which bypasses the safety filter within this constrained unsafe region. Additionally, a strategy library that reuses successful attack patterns further improves the attack's overall effectiveness and robustness. To validate our method, we evaluate SceneSplit across 11 safety categories on T2V models. Our results show that it achieves a high average Attack Success Rate (ASR) of 77.2% on Luma Ray2, 84.1% on Hailuo, and 78.2% on Veo2, significantly outperforming the existing baseline. Through this work, we demonstrate that current T2V safety mechanisms are vulnerable to attacks that exploit narrative structure, providing new insights for understanding and improving the safety of T2V models.
DeRAGEC: Denoising Named Entity Candidates with Synthetic Rationale for ASR Error Correction
Jun 09, 2025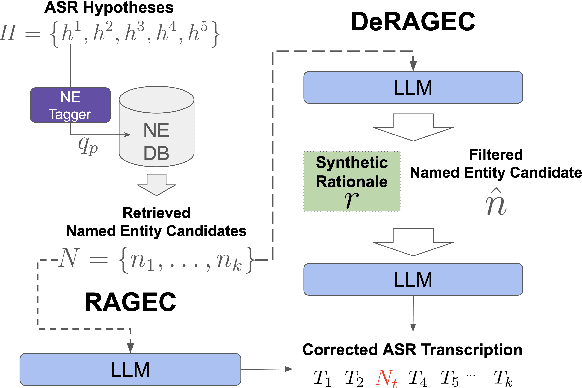
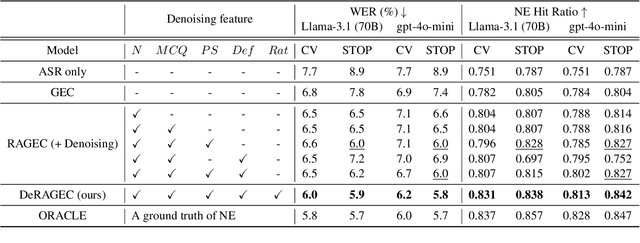
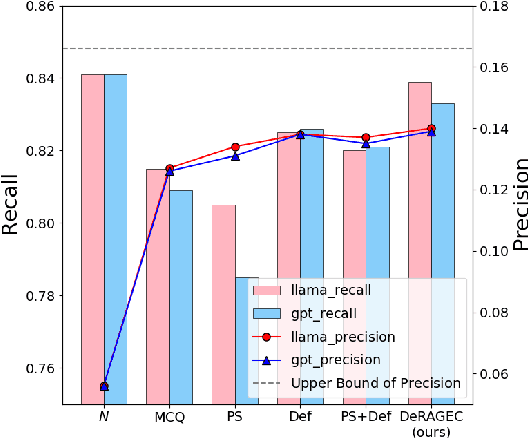
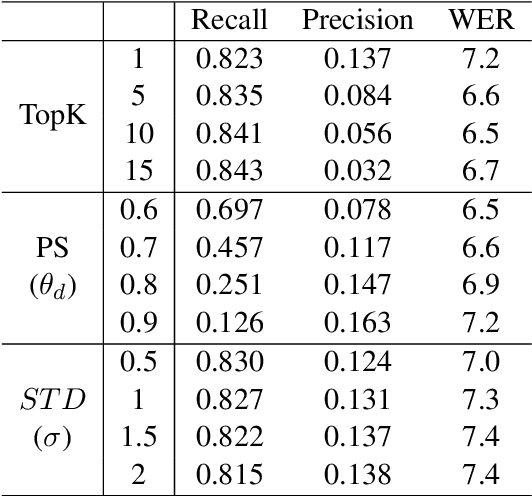
We present DeRAGEC, a method for improving Named Entity (NE) correction in Automatic Speech Recognition (ASR) systems. By extending the Retrieval-Augmented Generative Error Correction (RAGEC) framework, DeRAGEC employs synthetic denoising rationales to filter out noisy NE candidates before correction. By leveraging phonetic similarity and augmented definitions, it refines noisy retrieved NEs using in-context learning, requiring no additional training. Experimental results on CommonVoice and STOP datasets show significant improvements in Word Error Rate (WER) and NE hit ratio, outperforming baseline ASR and RAGEC methods. Specifically, we achieved a 28% relative reduction in WER compared to ASR without postprocessing. Our source code is publicly available at: https://github.com/solee0022/deragec
Benign-to-Toxic Jailbreaking: Inducing Harmful Responses from Harmless Prompts
May 26, 2025Optimization-based jailbreaks typically adopt the Toxic-Continuation setting in large vision-language models (LVLMs), following the standard next-token prediction objective. In this setting, an adversarial image is optimized to make the model predict the next token of a toxic prompt. However, we find that the Toxic-Continuation paradigm is effective at continuing already-toxic inputs, but struggles to induce safety misalignment when explicit toxic signals are absent. We propose a new paradigm: Benign-to-Toxic (B2T) jailbreak. Unlike prior work, we optimize adversarial images to induce toxic outputs from benign conditioning. Since benign conditioning contains no safety violations, the image alone must break the model's safety mechanisms. Our method outperforms prior approaches, transfers in black-box settings, and complements text-based jailbreaks. These results reveal an underexplored vulnerability in multimodal alignment and introduce a fundamentally new direction for jailbreak approaches.
ELITE: Enhanced Language-Image Toxicity Evaluation for Safety
Feb 10, 2025



Current Vision Language Models (VLMs) remain vulnerable to malicious prompts that induce harmful outputs. Existing safety benchmarks for VLMs primarily rely on automated evaluation methods, but these methods struggle to detect implicit harmful content or produce inaccurate evaluations. Therefore, we found that existing benchmarks have low levels of harmfulness, ambiguous data, and limited diversity in image-text pair combinations. To address these issues, we propose the ELITE benchmark, a high-quality safety evaluation benchmark for VLMs, underpinned by our enhanced evaluation method, the ELITE evaluator. The ELITE evaluator explicitly incorporates a toxicity score to accurately assess harmfulness in multimodal contexts, where VLMs often provide specific, convincing, but unharmful descriptions of images. We filter out ambiguous and low-quality image-text pairs from existing benchmarks using the ELITE evaluator and generate diverse combinations of safe and unsafe image-text pairs. Our experiments demonstrate that the ELITE evaluator achieves superior alignment with human evaluations compared to prior automated methods, and the ELITE benchmark offers enhanced benchmark quality and diversity. By introducing ELITE, we pave the way for safer, more robust VLMs, contributing essential tools for evaluating and mitigating safety risks in real-world applications.
Maximizing the Position Embedding for Vision Transformers with Global Average Pooling
Feb 05, 2025In vision transformers, position embedding (PE) plays a crucial role in capturing the order of tokens. However, in vision transformer structures, there is a limitation in the expressiveness of PE due to the structure where position embedding is simply added to the token embedding. A layer-wise method that delivers PE to each layer and applies independent Layer Normalizations for token embedding and PE has been adopted to overcome this limitation. In this paper, we identify the conflicting result that occurs in a layer-wise structure when using the global average pooling (GAP) method instead of the class token. To overcome this problem, we propose MPVG, which maximizes the effectiveness of PE in a layer-wise structure with GAP. Specifically, we identify that PE counterbalances token embedding values at each layer in a layer-wise structure. Furthermore, we recognize that the counterbalancing role of PE is insufficient in the layer-wise structure, and we address this by maximizing the effectiveness of PE through MPVG. Through experiments, we demonstrate that PE performs a counterbalancing role and that maintaining this counterbalancing directionality significantly impacts vision transformers. As a result, the experimental results show that MPVG outperforms existing methods across vision transformers on various tasks.