 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Classification
Papers and Code
LLM-Guided Dynamic-UMAP for Personalized Federated Graph Learning
Nov 12, 2025

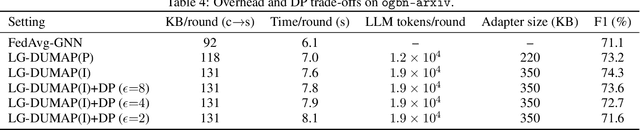
We propose a method that uses large language models to assist graph machine learning under personalization and privacy constraints. The approach combines data augmentation for sparse graphs, prompt and instruction tuning to adapt foundation models to graph tasks, and in-context learning to supply few-shot graph reasoning signals. These signals parameterize a Dynamic UMAP manifold of client-specific graph embeddings inside a Bayesian variational objective for personalized federated learning. The method supports node classification and link prediction in low-resource settings and aligns language model latent representations with graph structure via a cross-modal regularizer. We outline a convergence argument for the variational aggregation procedure, describe a differential privacy threat model based on a moments accountant, and present applications to knowledge graph completion, recommendation-style link prediction, and citation and product graphs. We also discuss evaluation considerations for benchmarking LLM-assisted graph machine learning.
Robust GNN Watermarking via Implicit Perception of Topological Invariants
Oct 29, 2025Graph Neural Networks (GNNs) are valuable intellectual property, yet many watermarks rely on backdoor triggers that break under common model edits and create ownership ambiguity. We present InvGNN-WM, which ties ownership to a model's implicit perception of a graph invariant, enabling trigger-free, black-box verification with negligible task impact. A lightweight head predicts normalized algebraic connectivity on an owner-private carrier set; a sign-sensitive decoder outputs bits, and a calibrated threshold controls the false-positive rate. Across diverse node and graph classification datasets and backbones, InvGNN-WM matches clean accuracy while yielding higher watermark accuracy than trigger- and compression-based baselines. It remains strong under unstructured pruning, fine-tuning, and post-training quantization; plain knowledge distillation (KD) weakens the mark, while KD with a watermark loss (KD+WM) restores it. We provide guarantees for imperceptibility and robustness, and we prove that exact removal is NP-complete.
Enhancing Graph Representations with Neighborhood-Contextualized Message-Passing
Nov 14, 2025Graph neural networks (GNNs) have become an indispensable tool for analyzing relational data. In the literature, classical GNNs may be classified into three variants: convolutional, attentional, and message-passing. While the standard message-passing variant is highly expressive, its typical pair-wise messages nevertheless only consider the features of the center node and each neighboring node individually. This design fails to incorporate the rich contextual information contained within the broader local neighborhood, potentially hindering its ability to learn complex relationships within the entire set of neighboring nodes. To address this limitation, this work first formalizes the concept of neighborhood-contextualization, rooted in a key property of the attentional variant. This then serves as the foundation for generalizing the message-passing variant to the proposed neighborhood-contextualized message-passing (NCMP) framework. To demonstrate its utility, a simple, practical, and efficient method to parametrize and operationalize NCMP is presented, leading to the development of the proposed Soft-Isomorphic Neighborhood-Contextualized Graph Convolution Network (SINC-GCN). A preliminary analysis on a synthetic binary node classification problem then underscores both the expressivity and efficiency of the proposed GNN architecture. Overall, the paper lays the foundation for the novel NCMP framework as a practical path toward further enhancing the graph representational power of classical GNNs.
Diagnosing and Mitigating Semantic Inconsistencies in Wikidata's Classification Hierarchy
Nov 07, 2025Wikidata is currently the largest open knowledge graph on the web, encompassing over 120 million entities. It integrates data from various domain-specific databases and imports a substantial amount of content from Wikipedia, while also allowing users to freely edit its content. This openness has positioned Wikidata as a central resource in knowledge graph research and has enabled convenient knowledge access for users worldwide. However, its relatively loose editorial policy has also led to a degree of taxonomic inconsistency. Building on prior work, this study proposes and applies a novel validation method to confirm the presence of classification errors, over-generalized subclass links, and redundant connections in specific domains of Wikidata. We further introduce a new evaluation criterion for determining whether such issues warrant correction and develop a system that allows users to inspect the taxonomic relationships of arbitrary Wikidata entities-leveraging the platform's crowdsourced nature to its full potential.
GFT: Graph Feature Tuning for Efficient Point Cloud Analysis
Nov 13, 2025



Parameter-efficient fine-tuning (PEFT) significantly reduces computational and memory costs by updating only a small subset of the model's parameters, enabling faster adaptation to new tasks with minimal loss in performance. Previous studies have introduced PEFTs tailored for point cloud data, as general approaches are suboptimal. To further reduce the number of trainable parameters, we propose a point-cloud-specific PEFT, termed Graph Features Tuning (GFT), which learns a dynamic graph from initial tokenized inputs of the transformer using a lightweight graph convolution network and passes these graph features to deeper layers via skip connections and efficient cross-attention modules. Extensive experiments on object classification and segmentation tasks show that GFT operates in the same domain, rivalling existing methods, while reducing the trainable parameters. Code is at https://github.com/manishdhakal/GFT.
Sign language recognition from skeletal data using graph and recurrent neural networks
Nov 08, 2025This work presents an approach for recognizing isolated sign language gestures using skeleton-based pose data extracted from video sequences. A Graph-GRU temporal network is proposed to model both spatial and temporal dependencies between frames, enabling accurate classification. The model is trained and evaluated on the AUTSL (Ankara university Turkish sign language) dataset, achieving high accuracy. Experimental results demonstrate the effectiveness of integrating graph-based spatial representations with temporal modeling, providing a scalable framework for sign language recognition. The results of this approach highlight the potential of pose-driven methods for sign language understanding.
Laplace Learning in Wasserstein Space
Nov 17, 2025The manifold hypothesis posits that high-dimensional data typically resides on low-dimensional sub spaces. In this paper, we assume manifold hypothesis to investigate graph-based semi-supervised learning methods. In particular, we examine Laplace Learning in the Wasserstein space, extending the classical notion of graph-based semi-supervised learning algorithms from finite-dimensional Euclidean spaces to an infinite-dimensional setting. To achieve this, we prove variational convergence of a discrete graph p- Dirichlet energy to its continuum counterpart. In addition, we characterize the Laplace-Beltrami operator on asubmanifold of the Wasserstein space. Finally, we validate the proposed theoretical framework through numerical experiments conducted on benchmark datasets, demonstrating the consistency of our classification performance in high-dimensional settings.
Persistent reachability homology in machine learning applications
Nov 06, 2025



We explore the recently introduced persistent reachability homology (PRH) of digraph data, i.e. data in the form of directed graphs. In particular, we study the effectiveness of PRH in network classification task in a key neuroscience problem: epilepsy detection. PRH is a variation of the persistent homology of digraphs, more traditionally based on the directed flag complex (DPH). A main advantage of PRH is that it considers the condensations of the digraphs appearing in the persistent filtration and thus is computed from smaller digraphs. We compare the effectiveness of PRH to that of DPH and we show that PRH outperforms DPH in the classification task. We use the Betti curves and their integrals as topological features and implement our pipeline on support vector machine.
Saliency Map-Guided Knowledge Discovery for Subclass Identification with LLM-Based Symbolic Approximations
Nov 10, 2025This paper proposes a novel neuro-symbolic approach for sensor signal-based knowledge discovery, focusing on identifying latent subclasses in time series classification tasks. The approach leverages gradient-based saliency maps derived from trained neural networks to guide the discovery process. Multiclass time series classification problems are transformed into binary classification problems through label subsumption, and classifiers are trained for each of these to yield saliency maps. The input signals, grouped by predicted class, are clustered under three distinct configurations. The centroids of the final set of clusters are provided as input to an LLM for symbolic approximation and fuzzy knowledge graph matching to discover the underlying subclasses of the original multiclass problem. Experimental results on well-established time series classification datasets demonstrate the effectiveness of our saliency map-driven method for knowledge discovery, outperforming signal-only baselines in both clustering and subclass identification.
Complex-Weighted Convolutional Networks: Provable Expressiveness via Complex Diffusion
Nov 17, 2025Graph Neural Networks (GNNs) have achieved remarkable success across diverse applications, yet they remain limited by oversmoothing and poor performance on heterophilic graphs. To address these challenges, we introduce a novel framework that equips graphs with a complex-weighted structure, assigning each edge a complex number to drive a diffusion process that extends random walks into the complex domain. We prove that this diffusion is highly expressive: with appropriately chosen complex weights, any node-classification task can be solved in the steady state of a complex random walk. Building on this insight, we propose the Complex-Weighted Convolutional Network (CWCN), which learns suitable complex-weighted structures directly from data while enriching diffusion with learnable matrices and nonlinear activations. CWCN is simple to implement, requires no additional hyperparameters beyond those of standard GNNs, and achieves competitive performance on benchmark datasets. Our results demonstrate that complex-weighted diffusion provides a principled and general mechanism for enhancing GNN expressiveness, opening new avenues for models that are both theoretically grounded and practically effective.