 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecancer detection
Cancer detection using Artificial Intelligence (AI) involves leveraging advanced machine learning algorithms and techniques to identify and diagnose cancer from various medical data sources. The goal is to enhance early detection, improve diagnostic accuracy, and potentially reduce the need for invasive procedures.
Papers and Code
EndoSight AI: Deep Learning-Driven Real-Time Gastrointestinal Polyp Detection and Segmentation for Enhanced Endoscopic Diagnostics
Nov 17, 2025Precise and real-time detection of gastrointestinal polyps during endoscopic procedures is crucial for early diagnosis and prevention of colorectal cancer. This work presents EndoSight AI, a deep learning architecture developed and evaluated independently to enable accurate polyp localization and detailed boundary delineation. Leveraging the publicly available Hyper-Kvasir dataset, the system achieves a mean Average Precision (mAP) of 88.3% for polyp detection and a Dice coefficient of up to 69% for segmentation, alongside real-time inference speeds exceeding 35 frames per second on GPU hardware. The training incorporates clinically relevant performance metrics and a novel thermal-aware procedure to ensure model robustness and efficiency. This integrated AI solution is designed for seamless deployment in endoscopy workflows, promising to advance diagnostic accuracy and clinical decision-making in gastrointestinal healthcare.
RRTS Dataset: A Benchmark Colonoscopy Dataset from Resource-Limited Settings for Computer-Aided Diagnosis Research
Nov 10, 2025Background and Objective: Colorectal cancer prevention relies on early detection of polyps during colonoscopy. Existing public datasets, such as CVC-ClinicDB and Kvasir-SEG, provide valuable benchmarks but are limited by small sample sizes, curated image selection, or lack of real-world artifacts. There remains a need for datasets that capture the complexity of clinical practice, particularly in resource-constrained settings. Methods: We introduce a dataset, BUET Polyp Dataset (BPD), of colonoscopy images collected using Olympus 170 and Pentax i-Scan series endoscopes under routine clinical conditions. The dataset contains images with corresponding expert-annotated binary masks, reflecting diverse challenges such as motion blur, specular highlights, stool artifacts, blood, and low-light frames. Annotations were manually reviewed by clinical experts to ensure quality. To demonstrate baseline performance, we provide benchmark results for classification using VGG16, ResNet50, and InceptionV3, and for segmentation using UNet variants with VGG16, ResNet34, and InceptionV4 backbones. Results: The dataset comprises 1,288 images with polyps from 164 patients with corresponding ground-truth masks and 1,657 polyp-free images from 31 patients. Benchmarking experiments achieved up to 90.8% accuracy for binary classification (VGG16) and a maximum Dice score of 0.64 with InceptionV4-UNet for segmentation. Performance was lower compared to curated datasets, reflecting the real-world difficulty of images with artifacts and variable quality.
General OOD Detection via Model-aware and Subspace-aware Variable Priority
Dec 15, 2025Out-of-distribution (OOD) detection is essential for determining when a supervised model encounters inputs that differ meaningfully from its training distribution. While widely studied in classification, OOD detection for regression and survival analysis remains limited due to the absence of discrete labels and the challenge of quantifying predictive uncertainty. We introduce a framework for OOD detection that is simultaneously model aware and subspace aware, and that embeds variable prioritization directly into the detection step. The method uses the fitted predictor to construct localized neighborhoods around each test case that emphasize the features driving the model's learned relationship and downweight directions that are less relevant to prediction. It produces OOD scores without relying on global distance metrics or estimating the full feature density. The framework is applicable across outcome types, and in our implementation we use random forests, where the rule structure yields transparent neighborhoods and effective scoring. Experiments on synthetic and real data benchmarks designed to isolate functional shifts show consistent improvements over existing methods. We further demonstrate the approach in an esophageal cancer survival study, where distribution shifts related to lymphadenectomy identify patterns relevant to surgical guidelines.
Artificial Intelligence-Enabled Analysis of Radiology Reports: Epidemiology and Consequences of Incidental Thyroid Findings
Oct 30, 2025



Importance Incidental thyroid findings (ITFs) are increasingly detected on imaging performed for non-thyroid indications. Their prevalence, features, and clinical consequences remain undefined. Objective To develop, validate, and deploy a natural language processing (NLP) pipeline to identify ITFs in radiology reports and assess their prevalence, features, and clinical outcomes. Design, Setting, and Participants Retrospective cohort of adults without prior thyroid disease undergoing thyroid-capturing imaging at Mayo Clinic sites from July 1, 2017, to September 30, 2023. A transformer-based NLP pipeline identified ITFs and extracted nodule characteristics from image reports from multiple modalities and body regions. Main Outcomes and Measures Prevalence of ITFs, downstream thyroid ultrasound, biopsy, thyroidectomy, and thyroid cancer diagnosis. Logistic regression identified demographic and imaging-related factors. Results Among 115,683 patients (mean age, 56.8 [SD 17.2] years; 52.9% women), 9,077 (7.8%) had an ITF, of which 92.9% were nodules. ITFs were more likely in women, older adults, those with higher BMI, and when imaging was ordered by oncology or internal medicine. Compared with chest CT, ITFs were more likely via neck CT, PET, and nuclear medicine scans. Nodule characteristics were poorly documented, with size reported in 44% and other features in fewer than 15% (e.g. calcifications). Compared with patients without ITFs, those with ITFs had higher odds of thyroid nodule diagnosis, biopsy, thyroidectomy and thyroid cancer diagnosis. Most cancers were papillary, and larger when detected after ITFs vs no ITF. Conclusions ITFs were common and strongly associated with cascades leading to the detection of small, low-risk cancers. These findings underscore the role of ITFs in thyroid cancer overdiagnosis and the need for standardized reporting and more selective follow-up.
Topological Conditioning for Mammography Models via a Stable Wavelet-Persistence Vectorization
Dec 10, 2025Breast cancer is the most commonly diagnosed cancer in women and a leading cause of cancer death worldwide. Screening mammography reduces mortality, yet interpretation still suffers from substantial false negatives and false positives, and model accuracy often degrades when deployed across scanners, modalities, and patient populations. We propose a simple conditioning signal aimed at improving external performance based on a wavelet based vectorization of persistent homology. Using topological data analysis, we summarize image structure that persists across intensity thresholds and convert this information into spatial, multi scale maps that are provably stable to small intensity perturbations. These maps are integrated into a two stage detection pipeline through input level channel concatenation. The model is trained and validated on the CBIS DDSM digitized film mammography cohort from the United States and evaluated on two independent full field digital mammography cohorts from Portugal (INbreast) and China (CMMD), with performance reported at the patient level. On INbreast, augmenting ConvNeXt Tiny with wavelet persistence channels increases patient level AUC from 0.55 to 0.75 under a limited training budget.
A Clinical-grade Universal Foundation Model for Intraoperative Pathology
Oct 06, 2025Intraoperative pathology is pivotal to precision surgery, yet its clinical impact is constrained by diagnostic complexity and the limited availability of high-quality frozen-section data. While computational pathology has made significant strides, the lack of large-scale, prospective validation has impeded its routine adoption in surgical workflows. Here, we introduce CRISP, a clinical-grade foundation model developed on over 100,000 frozen sections from eight medical centers, specifically designed to provide Clinical-grade Robust Intraoperative Support for Pathology (CRISP). CRISP was comprehensively evaluated on more than 15,000 intraoperative slides across nearly 100 retrospective diagnostic tasks, including benign-malignant discrimination, key intraoperative decision-making, and pan-cancer detection, etc. The model demonstrated robust generalization across diverse institutions, tumor types, and anatomical sites-including previously unseen sites and rare cancers. In a prospective cohort of over 2,000 patients, CRISP sustained high diagnostic accuracy under real-world conditions, directly informing surgical decisions in 92.6% of cases. Human-AI collaboration further reduced diagnostic workload by 35%, avoided 105 ancillary tests and enhanced detection of micrometastases with 87.5% accuracy. Together, these findings position CRISP as a clinical-grade paradigm for AI-driven intraoperative pathology, bridging computational advances with surgical precision and accelerating the translation of artificial intelligence into routine clinical practice.
Breast Cancer Detection in Thermographic Images via Diffusion-Based Augmentation and Nonlinear Feature Fusion
Sep 08, 2025Data scarcity hinders deep learning for medical imaging. We propose a framework for breast cancer classification in thermograms that addresses this using a Diffusion Probabilistic Model (DPM) for data augmentation. Our DPM-based augmentation is shown to be superior to both traditional methods and a ProGAN baseline. The framework fuses deep features from a pre-trained ResNet-50 with handcrafted nonlinear features (e.g., Fractal Dimension) derived from U-Net segmented tumors. An XGBoost classifier trained on these fused features achieves 98.0\% accuracy and 98.1\% sensitivity. Ablation studies and statistical tests confirm that both the DPM augmentation and the nonlinear feature fusion are critical, statistically significant components of this success. This work validates the synergy between advanced generative models and interpretable features for creating highly accurate medical diagnostic tools.
NodMAISI: Nodule-Oriented Medical AI for Synthetic Imaging
Dec 19, 2025Objective: Although medical imaging datasets are increasingly available, abnormal and annotation-intensive findings critical to lung cancer screening, particularly small pulmonary nodules, remain underrepresented and inconsistently curated. Methods: We introduce NodMAISI, an anatomically constrained, nodule-oriented CT synthesis and augmentation framework trained on a unified multi-source cohort (7,042 patients, 8,841 CTs, 14,444 nodules). The framework integrates: (i) a standardized curation and annotation pipeline linking each CT with organ masks and nodule-level annotations, (ii) a ControlNet-conditioned rectified-flow generator built on MAISI-v2's foundational blocks to enforce anatomy- and lesion-consistent synthesis, and (iii) lesion-aware augmentation that perturbs nodule masks (controlled shrinkage) while preserving surrounding anatomy to generate paired CT variants. Results: Across six public test datasets, NodMAISI improved distributional fidelity relative to MAISI-v2 (real-to-synthetic FID range 1.18 to 2.99 vs 1.69 to 5.21). In lesion detectability analysis using a MONAI nodule detector, NodMAISI substantially increased average sensitivity and more closely matched clinical scans (IMD-CT: 0.69 vs 0.39; DLCS24: 0.63 vs 0.20), with the largest gains for sub-centimeter nodules where MAISI-v2 frequently failed to reproduce the conditioned lesion. In downstream nodule-level malignancy classification trained on LUNA25 and externally evaluated on LUNA16, LNDbv4, and DLCS24, NodMAISI augmentation improved AUC by 0.07 to 0.11 at <=20% clinical data and by 0.12 to 0.21 at 10%, consistently narrowing the performance gap under data scarcity.
H-CNN-ViT: A Hierarchical Gated Attention Multi-Branch Model for Bladder Cancer Recurrence Prediction
Nov 19, 2025Bladder cancer is one of the most prevalent malignancies worldwide, with a recurrence rate of up to 78%, necessitating accurate post-operative monitoring for effective patient management. Multi-sequence contrast-enhanced MRI is commonly used for recurrence detection; however, interpreting these scans remains challenging, even for experienced radiologists, due to post-surgical alterations such as scarring, swelling, and tissue remodeling. AI-assisted diagnostic tools have shown promise in improving bladder cancer recurrence prediction, yet progress in this field is hindered by the lack of dedicated multi-sequence MRI datasets for recurrence assessment study. In this work, we first introduce a curated multi-sequence, multi-modal MRI dataset specifically designed for bladder cancer recurrence prediction, establishing a valuable benchmark for future research. We then propose H-CNN-ViT, a new Hierarchical Gated Attention Multi-Branch model that enables selective weighting of features from the global (ViT) and local (CNN) paths based on contextual demands, achieving a balanced and targeted feature fusion. Our multi-branch architecture processes each modality independently, ensuring that the unique properties of each imaging channel are optimally captured and integrated. Evaluated on our dataset, H-CNN-ViT achieves an AUC of 78.6%, surpassing state-of-the-art models. Our model is publicly available at https://github.com/XLIAaron/H-CNN-ViT.
Interpretable Deep Transfer Learning for Breast Ultrasound Cancer Detection: A Multi-Dataset Study
Sep 05, 2025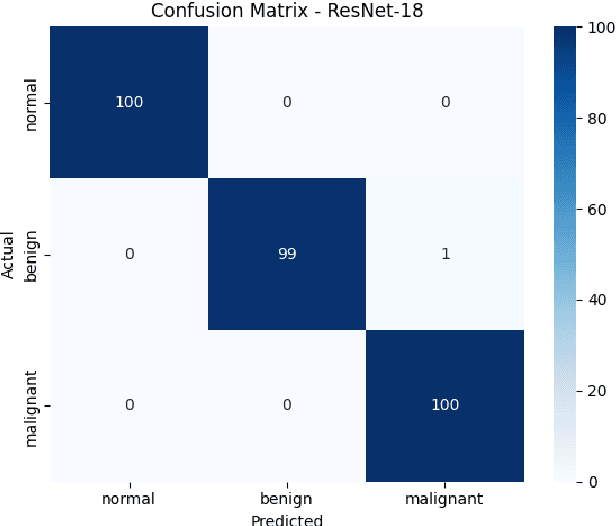
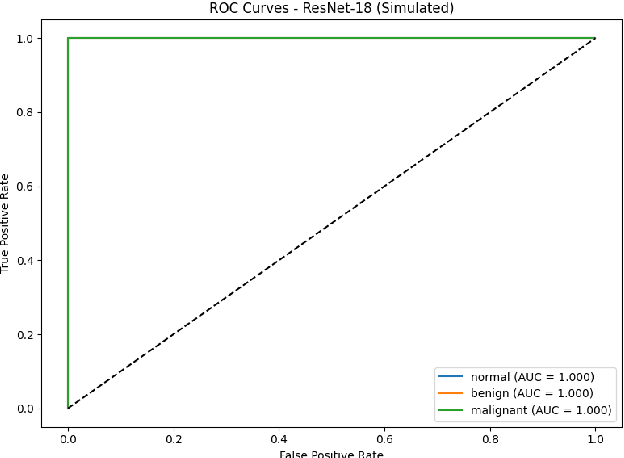
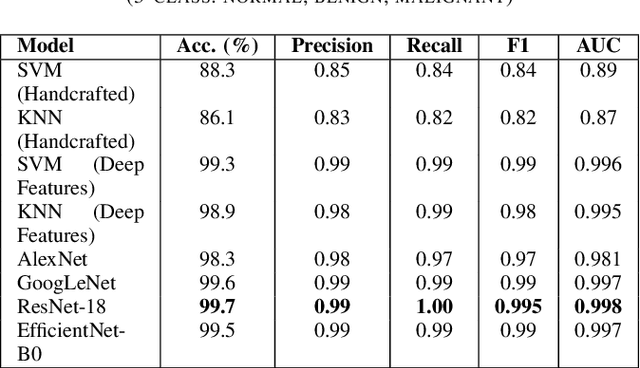
Breast cancer remains a leading cause of cancer-related mortality among women worldwide. Ultrasound imaging, widely used due to its safety and cost-effectiveness, plays a key role in early detection, especially in patients with dense breast tissue. This paper presents a comprehensive study on the application of machine learning and deep learning techniques for breast cancer classification using ultrasound images. Using datasets such as BUSI, BUS-BRA, and BrEaST-Lesions USG, we evaluate classical machine learning models (SVM, KNN) and deep convolutional neural networks (ResNet-18, EfficientNet-B0, GoogLeNet). Experimental results show that ResNet-18 achieves the highest accuracy (99.7%) and perfect sensitivity for malignant lesions. Classical ML models, though outperformed by CNNs, achieve competitive performance when enhanced with deep feature extraction. Grad-CAM visualizations further improve model transparency by highlighting diagnostically relevant image regions. These findings support the integration of AI-based diagnostic tools into clinical workflows and demonstrate the feasibility of deploying high-performing, interpretable systems for ultrasound-based breast cancer detection.