 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Neural Physics: Solving Partial Differential Equations on Quantum Simulators using Quantum Convolutional Neural Networks
Mar 25, 2026In scientific computing, the formulation of numerical discretisations of partial differential equations (PDEs) as untrained convolutional layers within Convolutional Neural Networks (CNNs), referred to by some as Neural Physics, has demonstrated good efficiency for executing physics-based solvers on GPUs. However, classical grid-based methods still face computational bottlenecks when solving problems involving billions of degrees of freedom. To address this challenge, this paper proposes a novel framework called 'Quantum Neural Physics' and develops a Hybrid Quantum-Classical CNN Multigrid Solver (HQC-CNNMG). This approach maps analytically-determined stencils of discretised differential operators into parameter-free or untrained quantum convolutional kernels. By leveraging amplitude encoding, the Linear Combination of Unitaries technique and the Quantum Fourier Transform, the resulting quantum convolutional operators can be implemented using quantum circuits with a circuit depth that scales as O(log K), where K denotes the size of the encoded input block. These quantum operators are embedded into a classical W-Cycle multigrid using a U-Net. This design enables seamless integration of quantum operators within a hierarchical solver whilst retaining the robustness and convergence properties of classical multigrid methods. The proposed Quantum Neural Physics solver is validated on a quantum simulator for the Poisson equation, diffusion equation, convection-diffusion equation and incompressible Navier-Stokes equations. The solutions of the HQC-CNNMG are in close agreement with those from traditional solution methods. This work establishes a mapping from discretised physical equations to logarithmic-scale quantum circuits, providing a new and exploratory path to exponential memory compression and computational acceleration for PDE solvers on future fault-tolerant quantum computers.
A Unified Multi-Scale Attention-Based Network for Automatic 3D Segmentation of Lung Parenchyma & Nodules In Thoracic CT Images
May 23, 2025Lung cancer has been one of the major threats across the world with the highest mortalities. Computer-aided detection (CAD) can help in early detection and thus can help increase the survival rate. Accurate lung parenchyma segmentation (to include the juxta-pleural nodules) and lung nodule segmentation, the primary symptom of lung cancer, play a crucial role in the overall accuracy of the Lung CAD pipeline. Lung nodule segmentation is quite challenging because of the diverse nodule types and other inhibit structures present within the lung lobes. Traditional machine/deep learning methods suffer from generalization and robustness. Recent Vision Language Models/Foundation Models perform well on the anatomical level, but they suffer on fine-grained segmentation tasks, and their semi-automatic nature limits their effectiveness in real-time clinical scenarios. In this paper, we propose a novel method for accurate 3D segmentation of lung parenchyma and lung nodules. The proposed architecture is an attention-based network with residual blocks at each encoder-decoder state. Max pooling is replaced by strided convolutions at the encoder, and trilinear interpolation is replaced by transposed convolutions at the decoder to maximize the number of learnable parameters. Dilated convolutions at each encoder-decoder stage allow the model to capture the larger context without increasing computational costs. The proposed method has been evaluated extensively on one of the largest publicly available datasets, namely LUNA16, and is compared with recent notable work in the domain using standard performance metrics like Dice score, IOU, etc. It can be seen from the results that the proposed method achieves better performance than state-of-the-art methods. The source code, datasets, and pre-processed data can be accessed using the link: https://github.com/EMeRALDsNRPU/Attention-Based-3D-ResUNet.
Calculation of Femur Caput Collum Diaphyseal angle for X-Rays images using Semantic Segmentation
Apr 25, 2024This paper investigates the use of deep learning approaches to estimate the femur caput-collum-diaphyseal (CCD) angle from X-ray images. The CCD angle is an important measurement in the diagnosis of hip problems, and correct prediction can help in the planning of surgical procedures. Manual measurement of this angle, on the other hand, can be time-intensive and vulnerable to inter-observer variability. In this paper, we present a deep-learning algorithm that can reliably estimate the femur CCD angle from X-ray images. To train and test the performance of our model, we employed an X-ray image dataset with associated femur CCD angle measurements. Furthermore, we built a prototype to display the resulting predictions and to allow the user to interact with the predictions. As this is happening in a sterile setting during surgery, we expanded our interface to the possibility of being used only by voice commands. Our results show that our deep learning model predicts the femur CCD angle on X-ray images with great accuracy, with a mean absolute error of 4.3 degrees on the left femur and 4.9 degrees on the right femur on the test dataset. Our results suggest that deep learning has the potential to give a more efficient and accurate technique for predicting the femur CCD angle, which might have substantial therapeutic implications for the diagnosis and management of hip problems.
Robust Baggage Detection and Classification Based on Local Tri-directional Pattern
Jun 15, 2020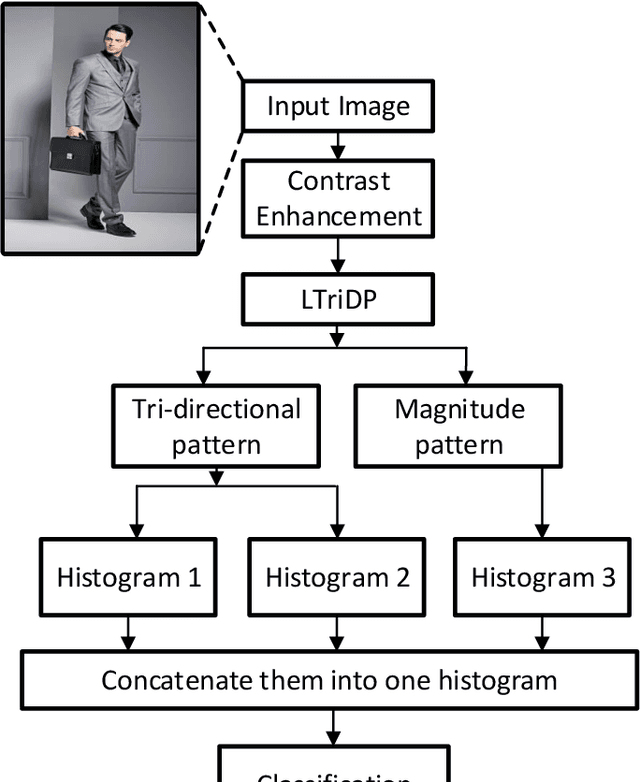
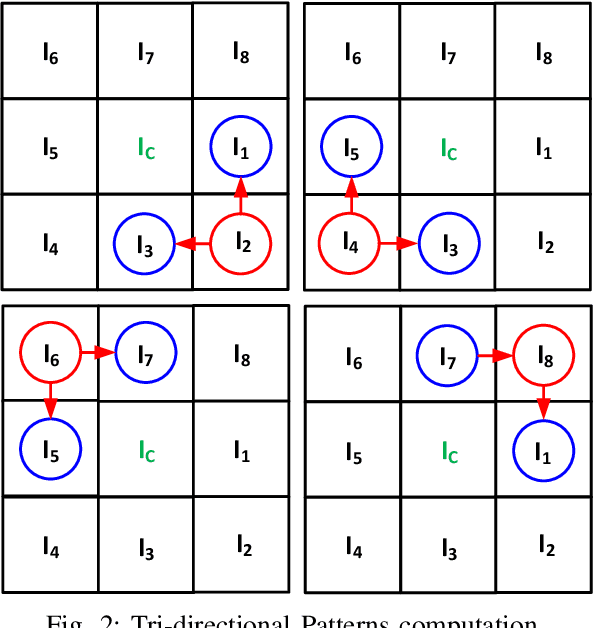


In recent decades, the automatic video surveillance system has gained significant importance in computer vision community. The crucial objective of surveillance is monitoring and security in public places. In the traditional Local Binary Pattern, the feature description is somehow inaccurate, and the feature size is large enough. Therefore, to overcome these shortcomings, our research proposed a detection algorithm for a human with or without carrying baggage. The Local tri-directional pattern descriptor is exhibited to extract features of different human body parts including head, trunk, and limbs. Then with the help of support vector machine, extracted features are trained and evaluated. Experimental results on INRIA and MSMT17 V1 datasets show that LtriDP outperforms several state-of-the-art feature descriptors and validate its effectiveness.
Systimator: A Design Space Exploration Methodology for Systolic Array based CNNs Acceleration on the FPGA-based Edge Nodes
Dec 15, 2018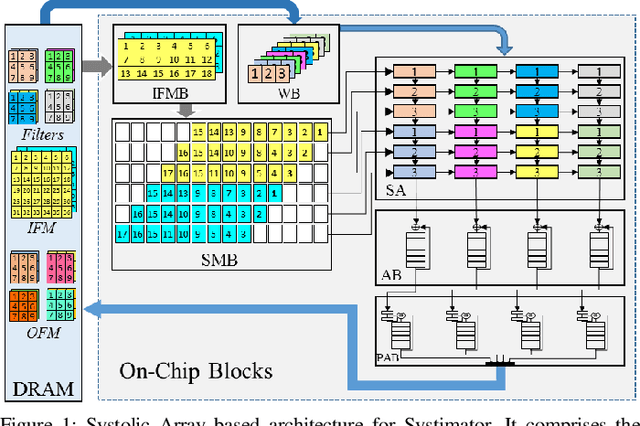
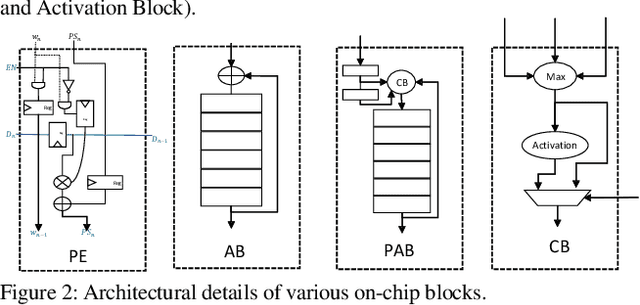
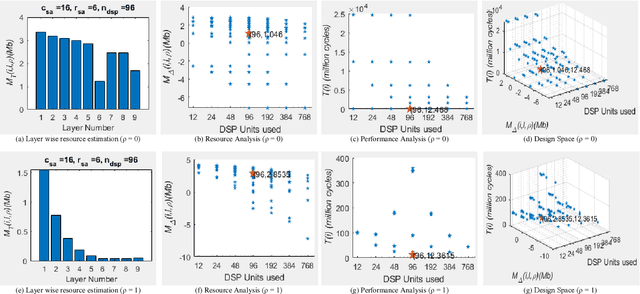
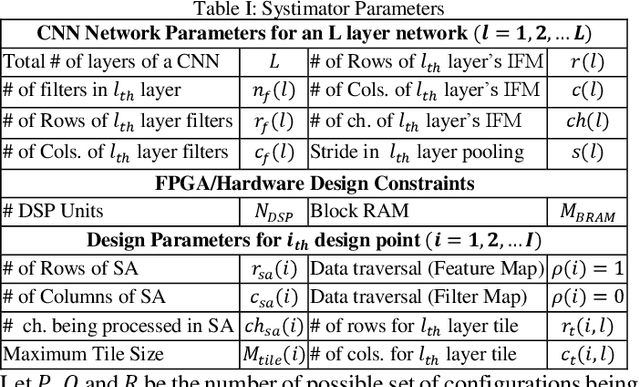
The evolution of IoT based smart applications demand porting of artificial intelligence algorithms to the edge computing devices. CNNs form a large part of these AI algorithms. Systolic array based CNN acceleration is being widely advocated due its ability to allow scalable architectures. However, CNNs are inherently memory and compute intensive algorithms, and hence pose significant challenges to be implemented on the resource-constrained edge computing devices. Memory-constrained low-cost FPGA based devices form a substantial fraction of these edge computing devices. Thus, when porting to such edge-computing devices, the designer is left unguided as to how to select a suitable systolic array configuration that could fit in the available hardware resources. In this paper we propose Systimator, a design space exploration based methodology that provides a set of design points that can be mapped within the memory bounds of the target FPGA device. The methodology is based upon an analytical model that is formulated to estimate the required resources for systolic arrays, assuming multiple data reuse patterns. The methodology further provides the performance estimates for each of the candidate design points. We show that Systimator provides an in-depth analysis of resource-requirement of systolic array based CNNs. We provide our resource estimation results for porting of convolutional layers of TINY YOLO, a CNN based object detector, on a Xilinx ARTIX 7 FPGA.