 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecancer detection
Cancer detection using Artificial Intelligence (AI) involves leveraging advanced machine learning algorithms and techniques to identify and diagnose cancer from various medical data sources. The goal is to enhance early detection, improve diagnostic accuracy, and potentially reduce the need for invasive procedures.
Papers and Code
From Future of Work to Future of Workers: Addressing Asymptomatic AI Harms for Dignified Human-AI Interaction
Jan 29, 2026In the future of work discourse, AI is touted as the ultimate productivity amplifier. Yet, beneath the efficiency gains lie subtle erosions of human expertise and agency. This paper shifts focus from the future of work to the future of workers by navigating the AI-as-Amplifier Paradox: AI's dual role as enhancer and eroder, simultaneously strengthening performance while eroding underlying expertise. We present a year-long study on the longitudinal use of AI in a high-stakes workplace among cancer specialists. Initial operational gains hid ``intuition rust'': the gradual dulling of expert judgment. These asymptomatic effects evolved into chronic harms, such as skill atrophy and identity commoditization. Building on these findings, we offer a framework for dignified Human-AI interaction co-constructed with professional knowledge workers facing AI-induced skill erosion without traditional labor protections. The framework operationalizes sociotechnical immunity through dual-purpose mechanisms that serve institutional quality goals while building worker power to detect, contain, and recover from skill erosion, and preserve human identity. Evaluated across healthcare and software engineering, our work takes a foundational step toward dignified human-AI interaction futures by balancing productivity with the preservation of human expertise.
Tumor-anchored deep feature random forests for out-of-distribution detection in lung cancer segmentation
Dec 09, 2025Accurate segmentation of cancerous lesions from 3D computed tomography (CT) scans is essential for automated treatment planning and response assessment. However, even state-of-the-art models combining self-supervised learning (SSL) pretrained transformers with convolutional decoders are susceptible to out-of-distribution (OOD) inputs, generating confidently incorrect tumor segmentations, posing risks for safe clinical deployment. Existing logit-based methods suffer from task-specific model biases, while architectural enhancements to explicitly detect OOD increase parameters and computational costs. Hence, we introduce a plug-and-play and lightweight post-hoc random forests-based OOD detection framework called RF-Deep that leverages deep features with limited outlier exposure. RF-Deep enhances generalization to imaging variations by repurposing the hierarchical features from the pretrained-then-finetuned backbone encoder, providing task-relevant OOD detection by extracting the features from multiple regions of interest anchored to the predicted tumor segmentations. Hence, it scales to images of varying fields-of-view. We compared RF-Deep against existing OOD detection methods using 1,916 CT scans across near-OOD (pulmonary embolism, negative COVID-19) and far-OOD (kidney cancer, healthy pancreas) datasets. RF-Deep achieved AUROC > 93.50 for the challenging near-OOD datasets and near-perfect detection (AUROC > 99.00) for the far-OOD datasets, substantially outperforming logit-based and radiomics approaches. RF-Deep maintained similar performance consistency across networks of different depths and pretraining strategies, demonstrating its effectiveness as a lightweight, architecture-agnostic approach to enhance the reliability of tumor segmentation from CT volumes.
DGSAN: Dual-Graph Spatiotemporal Attention Network for Pulmonary Nodule Malignancy Prediction
Dec 24, 2025Lung cancer continues to be the leading cause of cancer-related deaths globally. Early detection and diagnosis of pulmonary nodules are essential for improving patient survival rates. Although previous research has integrated multimodal and multi-temporal information, outperforming single modality and single time point, the fusion methods are limited to inefficient vector concatenation and simple mutual attention, highlighting the need for more effective multimodal information fusion. To address these challenges, we introduce a Dual-Graph Spatiotemporal Attention Network, which leverages temporal variations and multimodal data to enhance the accuracy of predictions. Our methodology involves developing a Global-Local Feature Encoder to better capture the local, global, and fused characteristics of pulmonary nodules. Additionally, a Dual-Graph Construction method organizes multimodal features into inter-modal and intra-modal graphs. Furthermore, a Hierarchical Cross-Modal Graph Fusion Module is introduced to refine feature integration. We also compiled a novel multimodal dataset named the NLST-cmst dataset as a comprehensive source of support for related research. Our extensive experiments, conducted on both the NLST-cmst and curated CSTL-derived datasets, demonstrate that our DGSAN significantly outperforms state-of-the-art methods in classifying pulmonary nodules with exceptional computational efficiency.
Prior-Guided DETR for Ultrasound Nodule Detection
Jan 05, 2026Accurate detection of ultrasound nodules is essential for the early diagnosis and treatment of thyroid and breast cancers. However, this task remains challenging due to irregular nodule shapes, indistinct boundaries, substantial scale variations, and the presence of speckle noise that degrades structural visibility. To address these challenges, we propose a prior-guided DETR framework specifically designed for ultrasound nodule detection. Instead of relying on purely data-driven feature learning, the proposed framework progressively incorporates different prior knowledge at multiple stages of the network. First, a Spatially-adaptive Deformable FFN with Prior Regularization (SDFPR) is embedded into the CNN backbone to inject geometric priors into deformable sampling, stabilizing feature extraction for irregular and blurred nodules. Second, a Multi-scale Spatial-Frequency Feature Mixer (MSFFM) is designed to extract multi-scale structural priors, where spatial-domain processing emphasizes contour continuity and boundary cues, while frequency-domain modeling captures global morphology and suppresses speckle noise. Furthermore, a Dense Feature Interaction (DFI) mechanism propagates and exploits these prior-modulated features across all encoder layers, enabling the decoder to enhance query refinement under consistent geometric and structural guidance. Experiments conducted on two clinically collected thyroid ultrasound datasets (Thyroid I and Thyroid II) and two public benchmarks (TN3K and BUSI) for thyroid and breast nodules demonstrate that the proposed method achieves superior accuracy compared with 18 detection methods, particularly in detecting morphologically complex nodules.The source code is publicly available at https://github.com/wjj1wjj/Ultrasound-DETR.
Feature Learning with Multi-Stage Vision Transformers on Inter-Modality HER2 Status Scoring and Tumor Classification on Whole Slides
Dec 26, 2025The popular use of histopathology images, such as hematoxylin and eosin (H&E), has proven to be useful in detecting tumors. However, moving such cancer cases forward for treatment requires accurate on the amount of the human epidermal growth factor receptor 2 (HER2) protein expression. Predicting both the lower and higher levels of HER2 can be challenging. Moreover, jointly analyzing H&E and immunohistochemistry (IHC) stained images for HER2 scoring is difficult. Although several deep learning methods have been investigated to address the challenge of HER2 scoring, they suffer from providing a pixel-level localization of HER2 status. In this study, we propose a single end-to-end pipeline using a system of vision transformers with HER2 status scoring on whole slide images of WSIs. The method includes patch-wise processing of H&E WSIs for tumor localization. A novel mapping function is proposed to correspondingly identify correlated IHC WSIs regions with malignant regions on H&E. A clinically inspired HER2 scoring mechanism is embedded in the pipeline and allows for automatic pixel-level annotation of 4-way HER2 scoring (0, 1+, 2+, and 3+). Also, the proposed method accurately returns HER2-negative and HER2-positive. Privately curated datasets were collaboratively extracted from 13 different cases of WSIs of H&E and IHC. A thorough experiment is conducted on the proposed method. Results obtained showed a good classification accuracy during tumor localization. Also, a classification accuracy of 0.94 and a specificity of 0.933 were returned for the prediction of HER2 status, scoring in the 4-way methods. The applicability of the proposed pipeline was investigated using WSIs patches as comparable to human pathologists. Findings from the study showed the usability of jointly evaluated H&E and IHC images on end-to-end ViTs-based models for HER2 scoring
Skin Lesion Classification Using a Soft Voting Ensemble of Convolutional Neural Networks
Dec 23, 2025Skin cancer can be identified by dermoscopic examination and ocular inspection, but early detection significantly increases survival chances. Artificial intelligence (AI), using annotated skin images and Convolutional Neural Networks (CNNs), improves diagnostic accuracy. This paper presents an early skin cancer classification method using a soft voting ensemble of CNNs. In this investigation, three benchmark datasets, namely HAM10000, ISIC 2016, and ISIC 2019, were used. The process involved rebalancing, image augmentation, and filtering techniques, followed by a hybrid dual encoder for segmentation via transfer learning. Accurate segmentation focused classification models on clinically significant features, reducing background artifacts and improving accuracy. Classification was performed through an ensemble of MobileNetV2, VGG19, and InceptionV3, balancing accuracy and speed for real-world deployment. The method achieved lesion recognition accuracies of 96.32\%, 90.86\%, and 93.92\% for the three datasets. The system performance was evaluated using established skin lesion detection metrics, yielding impressive results.
DBT-DINO: Towards Foundation model based analysis of Digital Breast Tomosynthesis
Dec 15, 2025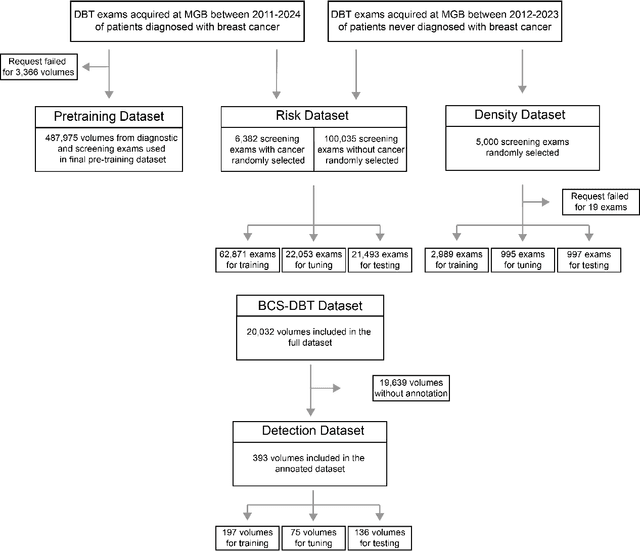
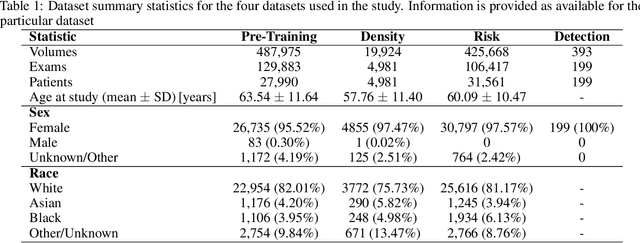
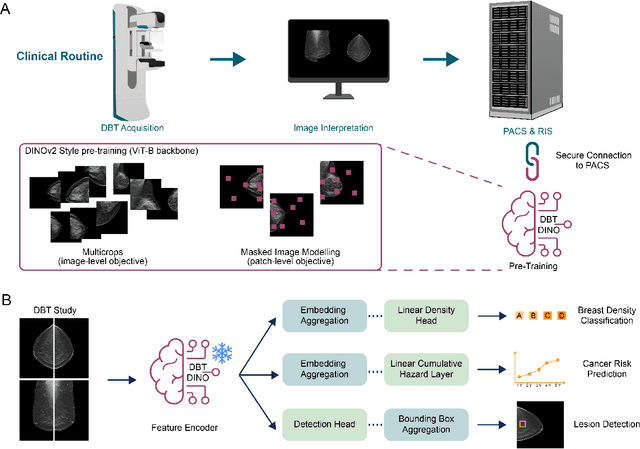

Foundation models have shown promise in medical imaging but remain underexplored for three-dimensional imaging modalities. No foundation model currently exists for Digital Breast Tomosynthesis (DBT), despite its use for breast cancer screening. To develop and evaluate a foundation model for DBT (DBT-DINO) across multiple clinical tasks and assess the impact of domain-specific pre-training. Self-supervised pre-training was performed using the DINOv2 methodology on over 25 million 2D slices from 487,975 DBT volumes from 27,990 patients. Three downstream tasks were evaluated: (1) breast density classification using 5,000 screening exams; (2) 5-year risk of developing breast cancer using 106,417 screening exams; and (3) lesion detection using 393 annotated volumes. For breast density classification, DBT-DINO achieved an accuracy of 0.79 (95\% CI: 0.76--0.81), outperforming both the MetaAI DINOv2 baseline (0.73, 95\% CI: 0.70--0.76, p<.001) and DenseNet-121 (0.74, 95\% CI: 0.71--0.76, p<.001). For 5-year breast cancer risk prediction, DBT-DINO achieved an AUROC of 0.78 (95\% CI: 0.76--0.80) compared to DINOv2's 0.76 (95\% CI: 0.74--0.78, p=.57). For lesion detection, DINOv2 achieved a higher average sensitivity of 0.67 (95\% CI: 0.60--0.74) compared to DBT-DINO with 0.62 (95\% CI: 0.53--0.71, p=.60). DBT-DINO demonstrated better performance on cancerous lesions specifically with a detection rate of 78.8\% compared to Dinov2's 77.3\%. Using a dataset of unprecedented size, we developed DBT-DINO, the first foundation model for DBT. DBT-DINO demonstrated strong performance on breast density classification and cancer risk prediction. However, domain-specific pre-training showed variable benefits on the detection task, with ImageNet baseline outperforming DBT-DINO on general lesion detection, indicating that localized detection tasks require further methodological development.
From 2D to 3D Without Extra Baggage: Data-Efficient Cancer Detection in Digital Breast Tomosynthesis
Nov 13, 2025



Digital Breast Tomosynthesis (DBT) enhances finding visibility for breast cancer detection by providing volumetric information that reduces the impact of overlapping tissues; however, limited annotated data has constrained the development of deep learning models for DBT. To address data scarcity, existing methods attempt to reuse 2D full-field digital mammography (FFDM) models by either flattening DBT volumes or processing slices individually, thus discarding volumetric information. Alternatively, 3D reasoning approaches introduce complex architectures that require more DBT training data. Tackling these drawbacks, we propose M&M-3D, an architecture that enables learnable 3D reasoning while remaining parameter-free relative to its FFDM counterpart, M&M. M&M-3D constructs malignancy-guided 3D features, and 3D reasoning is learned through repeatedly mixing these 3D features with slice-level information. This is achieved by modifying operations in M&M without adding parameters, thus enabling direct weight transfer from FFDM. Extensive experiments show that M&M-3D surpasses 2D projection and 3D slice-based methods by 11-54% for localization and 3-10% for classification. Additionally, M&M-3D outperforms complex 3D reasoning variants by 20-47% for localization and 2-10% for classification in the low-data regime, while matching their performance in high-data regime. On the popular BCS-DBT benchmark, M&M-3D outperforms previous top baseline by 4% for classification and 10% for localization.
On the Role of Calibration in Benchmarking Algorithmic Fairness for Skin Cancer Detection
Nov 10, 2025Artificial Intelligence (AI) models have demonstrated expert-level performance in melanoma detection, yet their clinical adoption is hindered by performance disparities across demographic subgroups such as gender, race, and age. Previous efforts to benchmark the performance of AI models have primarily focused on assessing model performance using group fairness metrics that rely on the Area Under the Receiver Operating Characteristic curve (AUROC), which does not provide insights into a model's ability to provide accurate estimates. In line with clinical assessments, this paper addresses this gap by incorporating calibration as a complementary benchmarking metric to AUROC-based fairness metrics. Calibration evaluates the alignment between predicted probabilities and observed event rates, offering deeper insights into subgroup biases. We assess the performance of the leading skin cancer detection algorithm of the ISIC 2020 Challenge on the ISIC 2020 Challenge dataset and the PROVE-AI dataset, and compare it with the second and third place models, focusing on subgroups defined by sex, race (Fitzpatrick Skin Tone), and age. Our findings reveal that while existing models enhance discriminative accuracy, they often over-diagnose risk and exhibit calibration issues when applied to new datasets. This study underscores the necessity for comprehensive model auditing strategies and extensive metadata collection to achieve equitable AI-driven healthcare solutions. All code is publicly available at https://github.com/bdominique/testing_strong_calibration.
* 19 pages, 4 figures. Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2025:027
Toward Scalable Early Cancer Detection: Evaluating EHR-Based Predictive Models Against Traditional Screening Criteria
Nov 14, 2025Current cancer screening guidelines cover only a few cancer types and rely on narrowly defined criteria such as age or a single risk factor like smoking history, to identify high-risk individuals. Predictive models using electronic health records (EHRs), which capture large-scale longitudinal patient-level health information, may provide a more effective tool for identifying high-risk groups by detecting subtle prediagnostic signals of cancer. Recent advances in large language and foundation models have further expanded this potential, yet evidence remains limited on how useful HER-based models are compared with traditional risk factors currently used in screening guidelines. We systematically evaluated the clinical utility of EHR-based predictive models against traditional risk factors, including gene mutations and family history of cancer, for identifying high-risk individuals across eight major cancers (breast, lung, colorectal, prostate, ovarian, liver, pancreatic, and stomach), using data from the All of Us Research Program, which integrates EHR, genomic, and survey data from over 865,000 participants. Even with a baseline modeling approach, EHR-based models achieved a 3- to 6-fold higher enrichment of true cancer cases among individuals identified as high risk compared with traditional risk factors alone, whether used as a standalone or complementary tool. The EHR foundation model, a state-of-the-art approach trained on comprehensive patient trajectories, further improved predictive performance across 26 cancer types, demonstrating the clinical potential of EHR-based predictive modeling to support more precise and scalable early detection strategies.