 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlood Mapping from RGB imagery using a Vision Foundation Model
Jun 23, 2026Timely, high-resolution maps of flood extent around settlements are essential for emergency response and damage assessment. We consider airborne RGB imagery for flood mapping as it can be collected rapidly at low cost. To produce flood maps, deep learning models for water segmentation are often used. CNN based and small vision transformer models are used. However, they need much data for adaptation to a change of scenery, i.e., another flooding event. Vision foundation models or large vision transformers are known to generalize across domains. Recently, foundation models for Earth observation became available. They are pretrained on satellite data, whose spatial resolution, viewing geometry, and radiometry differ from nadir RGB imagery. Thus, adaptation is required. We investigate how a satellite-pretrained Earth observation foundation model can be adapted to centimeter-scale floodwater mapping from RGB imagery. Specifically, we fine-tune a model we call Prithvi-2.0-UPN consisting of the Prithvi-EO-2.0-600M Vision Transformer combined with a UPerNet decoder for binary water segmentation on two RGB datasets (BlessemFlood21, NeuenahrFlood). In a first experiment we observe that Prithvi-2.0-UPN reaches state-of-the-art results on BlessemFlood21 and NeuenahrFlood, when trained on their datasets. In a second experiment we show that Prithvi-2.0-UPN performs better than state-of-the-art baseline models for transfer to a new flood event (trained on BlessemFlood21, tested on NeuenahrFlood) in a zero-shot setting. However, the performance indicates room for improvement. In this respect, we investigate in a third experiment how performance improves when further fine-tuning the models with small shares of NeuenahrFlood training data: Prithvi-2.0-UPN improves the fastest and reaches almost the performance level when fully trained on NeuenahrFlood, indicating transfer capabilities.
Schmidt Decomposition-Based Methods for Efficient Quantum Image Encoding
Jun 09, 2026In quantum image processing, a fundamental step is encoding classical image data into quantum states. This can be achieved using methods such as Flexible Representation of Quantum Images (FRQI), Quantum Probability Image Encoding (QPIE), and Novel Enhanced Quantum Representation (NEQR). However, on real quantum hardware, these encodings can quickly lead to circuits with many gates, large circuit depth, and high qubit usage, which is a problem for Noisy Intermediate-Scale Quantum (NISQ) devices. In this work, we investigate whether low-rank state approximation, formulated via Schmidt decomposition, can help reduce this complexity. The method keeps only the most significant parts of a quantum state's entanglement structure, making state preparation more efficient while preserving most of the image information. We compare the three encoding techniques in their original form and with low-rank approximation, evaluating metrics such as circuit depth, CNOT count, MSE, and visual quality of reconstructed images. The results reveal meaningful trade-offs between accuracy and resource efficiency, with the FRQI model achieving a 97 percent reduction in circuit depth while maintaining a near-perfect reconstruction (MSE of about 0.27). This demonstrates the potential of low-rank techniques for advancing practical quantum image processing on near-term hardware.
Using Deep Learning Models Pretrained by Self-Supervised Learning for Protein Localization
Apr 13, 2026Background: Task-specific microscopy datasets are often small, making it difficult to train deep learning models that learn robust features. While self-supervised learning (SSL) has shown promise through pretraining on large, domain-specific datasets, generalizability across datasets with differing staining protocols and channel configurations remains underexplored. We investigated the generalizability of SSL models pretrained on ImageNet-1k and HPA FOV, evaluating their embeddings on OpenCell with and without fine-tuning, two channel-mismatch strategies, and varying fine-tuning data fractions. We additionally analyzed single-cell embeddings on a labeled OpenCell subset. Result: DINO-based ViT backbones pretrained on HPA FOV or ImageNet-1k transfer well to OpenCell even without fine-tuning. The HPA FOV-pretrained model achieved the highest zero-shot performance (macro $F_1$ 0.822 $\pm$ 0.007). Fine-tuning further improved performance to 0.860 $\pm$ 0.013. At the single-cell level, the HPA single-cell-pretrained model achieved the highest k-nearest neighbor performance across all neighborhood sizes (macro $F_1$ $\geq$ 0.796). Conclusion: SSL methods like DINO, pretrained on large domain-relevant datasets, enable effective use of deep learning features for fine-tuning on small, task-specific microscopy datasets.
Hybrid Quantum-Classical AI for Industrial Defect Classification in Welding Images
Mar 30, 2026Hybrid quantum-classical machine learning offers a promising direction for advancing automated quality control in industrial settings. In this study, we investigate two hybrid quantum-classical approaches for classifying defects in aluminium TIG welding images and benchmarking their performance against a conventional deep learning model. A convolutional neural network is used to extract compact and informative feature vectors from weld images, effectively reducing the higher-dimensional pixel space to a lower-dimensional feature space. Our first quantum approach encodes these features into quantum states using a parameterized quantum feature map composed of rotation and entangling gates. We compute a quantum kernel matrix from the inner products of these states, defining a linear system in a higher-dimensional Hilbert space corresponding to the support vector machine (SVM) optimization problem and solving it using a Variational Quantum Linear Solver (VQLS). We also examine the effect of the quantum kernel condition number on classification performance. In our second method, we apply angle encoding to the extracted features in a variational quantum circuit and use a classical optimizer for model training. Both quantum models are tested on binary and multiclass classification tasks and the performance is compared with the classical CNN model. Our results show that while the CNN model demonstrates robust performance, hybrid quantum-classical models perform competitively. This highlights the potential of hybrid quantum-classical approaches for near-term real-world applications in industrial defect detection and quality assurance.
Generalization of Self-Supervised Vision Transformers for Protein Localization Across Microscopy Domains
Feb 05, 2026Task-specific microscopy datasets are often too small to train deep learning models that learn robust feature representations. Self-supervised learning (SSL) can mitigate this by pretraining on large unlabeled datasets, but it remains unclear how well such representations transfer across microscopy domains with different staining protocols and channel configurations. We investigate the cross-domain transferability of DINO-pretrained Vision Transformers for protein localization on the OpenCell dataset. We generate image embeddings using three DINO backbones pretrained on ImageNet-1k, the Human Protein Atlas (HPA), and OpenCell, and evaluate them by training a supervised classification head on OpenCell labels. All pretrained models transfer well, with the microscopy-specific HPA-pretrained model achieving the best performance (mean macro $F_1$-score = 0.8221 \pm 0.0062), slightly outperforming a DINO model trained directly on OpenCell (0.8057 \pm 0.0090). These results highlight the value of large-scale pretraining and indicate that domain-relevant SSL representations can generalize effectively to related but distinct microscopy datasets, enabling strong downstream performance even when task-specific labeled data are limited.
Vision-Language Model for Accurate Crater Detection
Jan 12, 2026The European Space Agency (ESA), driven by its ambitions on planned lunar missions with the Argonaut lander, has a profound interest in reliable crater detection, since craters pose a risk to safe lunar landings. This task is usually addressed with automated crater detection algorithms (CDA) based on deep learning techniques. It is non-trivial due to the vast amount of craters of various sizes and shapes, as well as challenging conditions such as varying illumination and rugged terrain. Therefore, we propose a deep-learning CDA based on the OWLv2 model, which is built on a Vision Transformer, that has proven highly effective in various computer vision tasks. For fine-tuning, we utilize a manually labeled dataset fom the IMPACT project, that provides crater annotations on high-resolution Lunar Reconnaissance Orbiter Camera Calibrated Data Record images. We insert trainable parameters using a parameter-efficient fine-tuning strategy with Low-Rank Adaptation, and optimize a combined loss function consisting of Complete Intersection over Union (CIoU) for localization and a contrastive loss for classification. We achieve satisfactory visual results, along with a maximum recall of 94.0% and a maximum precision of 73.1% on a test dataset from IMPACT. Our method achieves reliable crater detection across challenging lunar imaging conditions, paving the way for robust crater analysis in future lunar exploration.
Detector-Augmented SAMURAI for Long-Duration Drone Tracking
Jan 08, 2026Robust long-term tracking of drone is a critical requirement for modern surveillance systems, given their increasing threat potential. While detector-based approaches typically achieve strong frame-level accuracy, they often suffer from temporal inconsistencies caused by frequent detection dropouts. Despite its practical relevance, research on RGB-based drone tracking is still limited and largely reliant on conventional motion models. Meanwhile, foundation models like SAMURAI have established their effectiveness across other domains, exhibiting strong category-agnostic tracking performance. However, their applicability in drone-specific scenarios has not been investigated yet. Motivated by this gap, we present the first systematic evaluation of SAMURAI's potential for robust drone tracking in urban surveillance settings. Furthermore, we introduce a detector-augmented extension of SAMURAI to mitigate sensitivity to bounding-box initialization and sequence length. Our findings demonstrate that the proposed extension significantly improves robustness in complex urban environments, with pronounced benefits in long-duration sequences - especially under drone exit-re-entry events. The incorporation of detector cues yields consistent gains over SAMURAI's zero-shot performance across datasets and metrics, with success rate improvements of up to +0.393 and FNR reductions of up to -0.475.
Fast and Exact Least Absolute Deviations Line Fitting via Piecewise Affine Lower-Bounding
Dec 22, 2025



Least-absolute-deviations (LAD) line fitting is robust to outliers but computationally more involved than least squares regression. Although the literature includes linear and near-linear time algorithms for the LAD line fitting problem, these methods are difficult to implement and, to our knowledge, lack maintained public implementations. As a result, practitioners often resort to linear programming (LP) based methods such as the simplex-based Barrodale-Roberts method and interior-point methods, or on iteratively reweighted least squares (IRLS) approximation which does not guarantee exact solutions. To close this gap, we propose the Piecewise Affine Lower-Bounding (PALB) method, an exact algorithm for LAD line fitting. PALB uses supporting lines derived from subgradients to build piecewise-affine lower bounds, and employs a subdivision scheme involving minima of these lower bounds. We prove correctness and provide bounds on the number of iterations. On synthetic datasets with varied signal types and noise including heavy-tailed outliers as well as a real dataset from the NOAA's Integrated Surface Database, PALB exhibits empirical log-linear scaling. It is consistently faster than publicly available implementations of LP based and IRLS based solvers. We provide a reference implementation written in Rust with a Python API.
Performance Optimization of YOLO-FEDER FusionNet for Robust Drone Detection in Visually Complex Environments
Sep 17, 2025
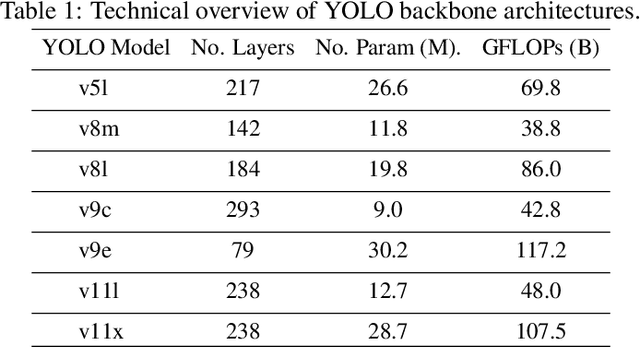
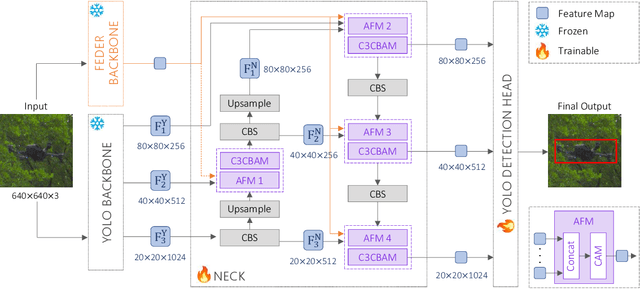
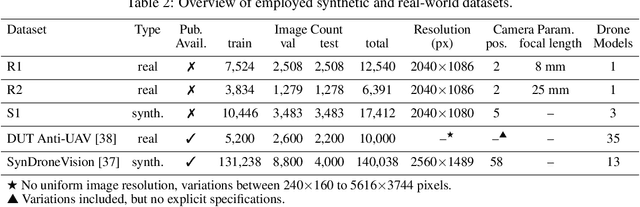
Drone detection in visually complex environments remains challenging due to background clutter, small object scale, and camouflage effects. While generic object detectors like YOLO exhibit strong performance in low-texture scenes, their effectiveness degrades in cluttered environments with low object-background separability. To address these limitations, this work presents an enhanced iteration of YOLO-FEDER FusionNet -- a detection framework that integrates generic object detection with camouflage object detection techniques. Building upon the original architecture, the proposed iteration introduces systematic advancements in training data composition, feature fusion strategies, and backbone design. Specifically, the training process leverages large-scale, photo-realistic synthetic data, complemented by a small set of real-world samples, to enhance robustness under visually complex conditions. The contribution of intermediate multi-scale FEDER features is systematically evaluated, and detection performance is comprehensively benchmarked across multiple YOLO-based backbone configurations. Empirical results indicate that integrating intermediate FEDER features, in combination with backbone upgrades, contributes to notable performance improvements. In the most promising configuration -- YOLO-FEDER FusionNet with a YOLOv8l backbone and FEDER features derived from the DWD module -- these enhancements lead to a FNR reduction of up to 39.1 percentage points and a mAP increase of up to 62.8 percentage points at an IoU threshold of 0.5, compared to the initial baseline.
Fast Trajectory-Independent Model-Based Reconstruction Algorithm for Multi-Dimensional Magnetic Particle Imaging
May 28, 2025Magnetic Particle Imaging (MPI) is a promising tomographic technique for visualizing the spatio-temporal distribution of superparamagnetic nanoparticles, with applications ranging from cancer detection to real-time cardiovascular monitoring. Traditional MPI reconstruction relies on either time-consuming calibration (measured system matrix) or model-based simulation of the forward operator. Recent developments have shown the applicability of Chebyshev polynomials to multi-dimensional Lissajous Field-Free Point (FFP) scans. This method is bound to the particular choice of sinusoidal scanning trajectories. In this paper, we present the first reconstruction on real 2D MPI data with a trajectory-independent model-based MPI reconstruction algorithm. We further develop the zero-shot Plug-and-Play (PnP) algorithm of the authors -- with automatic noise level estimation -- to address the present deconvolution problem, leveraging a state-of-the-art denoiser trained on natural images without retraining on MPI-specific data. We evaluate our method on the publicly available 2D FFP MPI dataset ``MPIdata: Equilibrium Model with Anisotropy", featuring scans of six phantoms acquired using a Bruker preclinical scanner. Moreover, we show reconstruction performed on custom data on a 2D scanner with additional high-frequency excitation field and partial data. Our results demonstrate strong reconstruction capabilities across different scanning scenarios -- setting a precedent for general-purpose, flexible model-based MPI reconstruction.