 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeautonomous cars
Autonomous cars are self-driving vehicles that use artificial intelligence (AI) and sensors to navigate and operate without human intervention, using high-resolution cameras and lidars that detect what happens in the car's immediate surroundings. They have the potential to revolutionize transportation by improving safety, efficiency, and accessibility.
Papers and Code
Car-1000: A New Large Scale Fine-Grained Visual Categorization Dataset
Mar 16, 2025



Fine-grained visual categorization (FGVC) is a challenging but significant task in computer vision, which aims to recognize different sub-categories of birds, cars, airplanes, etc. Among them, recognizing models of different cars has significant application value in autonomous driving, traffic surveillance and scene understanding, which has received considerable attention in the past few years. However, Stanford-Car, the most widely used fine-grained dataset for car recognition, only has 196 different categories and only includes vehicle models produced earlier than 2013. Due to the rapid advancements in the automotive industry during recent years, the appearances of various car models have become increasingly intricate and sophisticated. Consequently, the previous Stanford-Car dataset fails to capture this evolving landscape and cannot satisfy the requirements of automotive industry. To address these challenges, in our paper, we introduce Car-1000, a large-scale dataset designed specifically for fine-grained visual categorization of diverse car models. Car-1000 encompasses vehicles from 165 different automakers, spanning a wide range of 1000 distinct car models. Additionally, we have reproduced several state-of-the-art FGVC methods on the Car-1000 dataset, establishing a new benchmark for research in this field. We hope that our work will offer a fresh perspective for future FGVC researchers. Our dataset is available at https://github.com/toggle1995/Car-1000.
The Meeseeks Mesh: Spatially Consistent 3D Adversarial Objects for BEV Detector
May 29, 20253D object detection is a critical component in autonomous driving systems. It allows real-time recognition and detection of vehicles, pedestrians and obstacles under varying environmental conditions. Among existing methods, 3D object detection in the Bird's Eye View (BEV) has emerged as the mainstream framework. To guarantee a safe, robust and trustworthy 3D object detection, 3D adversarial attacks are investigated, where attacks are placed in 3D environments to evaluate the model performance, e.g. putting a film on a car, clothing a pedestrian. The vulnerability of 3D object detection models to 3D adversarial attacks serves as an important indicator to evaluate the robustness of the model against perturbations. To investigate this vulnerability, we generate non-invasive 3D adversarial objects tailored for real-world attack scenarios. Our method verifies the existence of universal adversarial objects that are spatially consistent across time and camera views. Specifically, we employ differentiable rendering techniques to accurately model the spatial relationship between adversarial objects and the target vehicle. Furthermore, we introduce an occlusion-aware module to enhance visual consistency and realism under different viewpoints. To maintain attack effectiveness across multiple frames, we design a BEV spatial feature-guided optimization strategy. Experimental results demonstrate that our approach can reliably suppress vehicle predictions from state-of-the-art 3D object detectors, serving as an important tool to test robustness of 3D object detection models before deployment. Moreover, the generated adversarial objects exhibit strong generalization capabilities, retaining its effectiveness at various positions and distances in the scene.
REACT: Runtime-Enabled Active Collision-avoidance Technique for Autonomous Driving
May 16, 2025Achieving rapid and effective active collision avoidance in dynamic interactive traffic remains a core challenge for autonomous driving. This paper proposes REACT (Runtime-Enabled Active Collision-avoidance Technique), a closed-loop framework that integrates risk assessment with active avoidance control. By leveraging energy transfer principles and human-vehicle-road interaction modeling, REACT dynamically quantifies runtime risk and constructs a continuous spatial risk field. The system incorporates physically grounded safety constraints such as directional risk and traffic rules to identify high-risk zones and generate feasible, interpretable avoidance behaviors. A hierarchical warning trigger strategy and lightweight system design enhance runtime efficiency while ensuring real-time responsiveness. Evaluations across four representative high-risk scenarios including car-following braking, cut-in, rear-approaching, and intersection conflict demonstrate REACT's capability to accurately identify critical risks and execute proactive avoidance. Its risk estimation aligns closely with human driver cognition (i.e., warning lead time < 0.4 s), achieving 100% safe avoidance with zero false alarms or missed detections. Furthermore, it exhibits superior real-time performance (< 50 ms latency), strong foresight, and generalization. The lightweight architecture achieves state-of-the-art accuracy, highlighting its potential for real-time deployment in safety-critical autonomous systems.
Contour Errors: An Ego-Centric Metric for Reliable 3D Multi-Object Tracking
Jun 04, 2025Finding reliable matches is essential in multi-object tracking to ensure the accuracy and reliability of perception systems in safety-critical applications such as autonomous vehicles. Effective matching mitigates perception errors, enhancing object identification and tracking for improved performance and safety. However, traditional metrics such as Intersection over Union (IoU) and Center Point Distances (CPDs), which are effective in 2D image planes, often fail to find critical matches in complex 3D scenes. To address this limitation, we introduce Contour Errors (CEs), an ego or object-centric metric for identifying matches of interest in tracking scenarios from a functional perspective. By comparing bounding boxes in the ego vehicle's frame, contour errors provide a more functionally relevant assessment of object matches. Extensive experiments on the nuScenes dataset demonstrate that contour errors improve the reliability of matches over the state-of-the-art 2D IoU and CPD metrics in tracking-by-detection methods. In 3D car tracking, our results show that Contour Errors reduce functional failures (FPs/FNs) by 80% at close ranges and 60% at far ranges compared to IoU in the evaluation stage.
Virtual Roads, Smarter Safety: A Digital Twin Framework for Mixed Autonomous Traffic Safety Analysis
Apr 24, 2025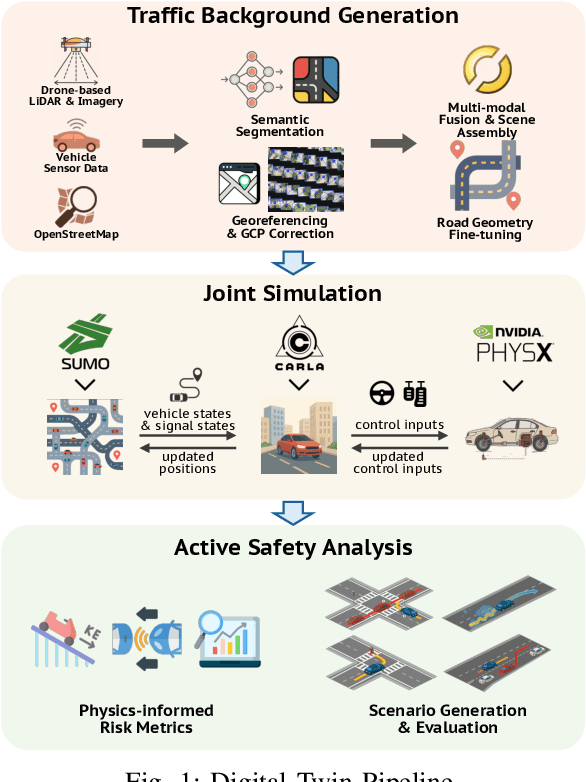
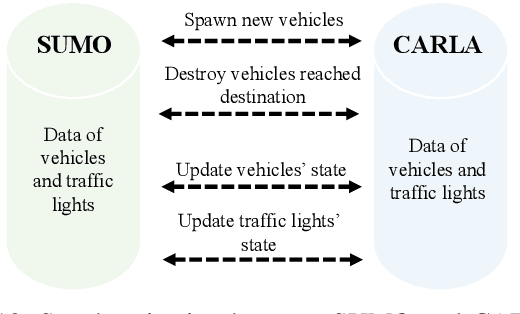
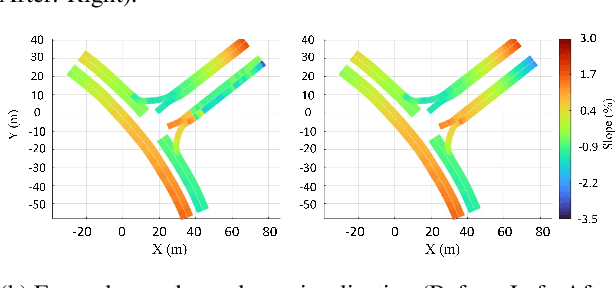
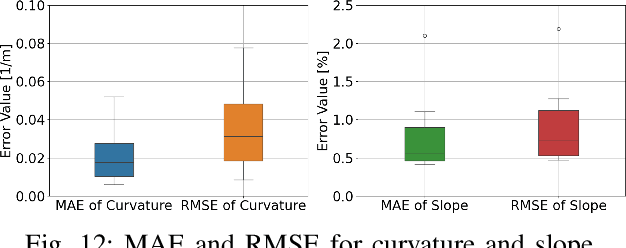
This paper presents a digital-twin platform for active safety analysis in mixed traffic environments. The platform is built using a multi-modal data-enabled traffic environment constructed from drone-based aerial LiDAR, OpenStreetMap, and vehicle sensor data (e.g., GPS and inclinometer readings). High-resolution 3D road geometries are generated through AI-powered semantic segmentation and georeferencing of aerial LiDAR data. To simulate real-world driving scenarios, the platform integrates the CAR Learning to Act (CARLA) simulator, Simulation of Urban MObility (SUMO) traffic model, and NVIDIA PhysX vehicle dynamics engine. CARLA provides detailed micro-level sensor and perception data, while SUMO manages macro-level traffic flow. NVIDIA PhysX enables accurate modeling of vehicle behaviors under diverse conditions, accounting for mass distribution, tire friction, and center of mass. This integrated system supports high-fidelity simulations that capture the complex interactions between autonomous and conventional vehicles. Experimental results demonstrate the platform's ability to reproduce realistic vehicle dynamics and traffic scenarios, enhancing the analysis of active safety measures. Overall, the proposed framework advances traffic safety research by enabling in-depth, physics-informed evaluation of vehicle behavior in dynamic and heterogeneous traffic environments.
On learning racing policies with reinforcement learning
Apr 03, 2025



Fully autonomous vehicles promise enhanced safety and efficiency. However, ensuring reliable operation in challenging corner cases requires control algorithms capable of performing at the vehicle limits. We address this requirement by considering the task of autonomous racing and propose solving it by learning a racing policy using Reinforcement Learning (RL). Our approach leverages domain randomization, actuator dynamics modeling, and policy architecture design to enable reliable and safe zero-shot deployment on a real platform. Evaluated on the F1TENTH race car, our RL policy not only surpasses a state-of-the-art Model Predictive Control (MPC), but, to the best of our knowledge, also represents the first instance of an RL policy outperforming expert human drivers in RC racing. This work identifies the key factors driving this performance improvement, providing critical insights for the design of robust RL-based control strategies for autonomous vehicles.
Safety Monitoring of Machine Learning Perception Functions: a Survey
Dec 09, 2024Machine Learning (ML) models, such as deep neural networks, are widely applied in autonomous systems to perform complex perception tasks. New dependability challenges arise when ML predictions are used in safety-critical applications, like autonomous cars and surgical robots. Thus, the use of fault tolerance mechanisms, such as safety monitors, is essential to ensure the safe behavior of the system despite the occurrence of faults. This paper presents an extensive literature review on safety monitoring of perception functions using ML in a safety-critical context. In this review, we structure the existing literature to highlight key factors to consider when designing such monitors: threat identification, requirements elicitation, detection of failure, reaction, and evaluation. We also highlight the ongoing challenges associated with safety monitoring and suggest directions for future research.
Robusto-1 Dataset: Comparing Humans and VLMs on real out-of-distribution Autonomous Driving VQA from Peru
Mar 10, 2025



As multimodal foundational models start being deployed experimentally in Self-Driving cars, a reasonable question we ask ourselves is how similar to humans do these systems respond in certain driving situations -- especially those that are out-of-distribution? To study this, we create the Robusto-1 dataset that uses dashcam video data from Peru, a country with one of the worst (aggressive) drivers in the world, a high traffic index, and a high ratio of bizarre to non-bizarre street objects likely never seen in training. In particular, to preliminarly test at a cognitive level how well Foundational Visual Language Models (VLMs) compare to Humans in Driving, we move away from bounding boxes, segmentation maps, occupancy maps or trajectory estimation to multi-modal Visual Question Answering (VQA) comparing both humans and machines through a popular method in systems neuroscience known as Representational Similarity Analysis (RSA). Depending on the type of questions we ask and the answers these systems give, we will show in what cases do VLMs and Humans converge or diverge allowing us to probe on their cognitive alignment. We find that the degree of alignment varies significantly depending on the type of questions asked to each type of system (Humans vs VLMs), highlighting a gap in their alignment.
Enhancing Autonomous Driving Safety with Collision Scenario Integration
Mar 05, 2025Autonomous vehicle safety is crucial for the successful deployment of self-driving cars. However, most existing planning methods rely heavily on imitation learning, which limits their ability to leverage collision data effectively. Moreover, collecting collision or near-collision data is inherently challenging, as it involves risks and raises ethical and practical concerns. In this paper, we propose SafeFusion, a training framework to learn from collision data. Instead of over-relying on imitation learning, SafeFusion integrates safety-oriented metrics during training to enable collision avoidance learning. In addition, to address the scarcity of collision data, we propose CollisionGen, a scalable data generation pipeline to generate diverse, high-quality scenarios using natural language prompts, generative models, and rule-based filtering. Experimental results show that our approach improves planning performance in collision-prone scenarios by 56\% over previous state-of-the-art planners while maintaining effectiveness in regular driving situations. Our work provides a scalable and effective solution for advancing the safety of autonomous driving systems.
Epipolar Attention Field Transformers for Bird's Eye View Semantic Segmentation
Dec 02, 2024



Spatial understanding of the semantics of the surroundings is a key capability needed by autonomous cars to enable safe driving decisions. Recently, purely vision-based solutions have gained increasing research interest. In particular, approaches extracting a bird's eye view (BEV) from multiple cameras have demonstrated great performance for spatial understanding. This paper addresses the dependency on learned positional encodings to correlate image and BEV feature map elements for transformer-based methods. We propose leveraging epipolar geometric constraints to model the relationship between cameras and the BEV by Epipolar Attention Fields. They are incorporated into the attention mechanism as a novel attribution term, serving as an alternative to learned positional encodings. Experiments show that our method EAFormer outperforms previous BEV approaches by 2% mIoU for map semantic segmentation and exhibits superior generalization capabilities compared to implicitly learning the camera configuration.