 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWsj0 2mix
Papers and Code
A Study of the Scale Invariant Signal to Distortion Ratio in Speech Separation with Noisy References
Aug 20, 2025This paper examines the implications of using the Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) as both evaluation and training objective in supervised speech separation, when the training references contain noise, as is the case with the de facto benchmark WSJ0-2Mix. A derivation of the SI-SDR with noisy references reveals that noise limits the achievable SI-SDR, or leads to undesired noise in the separated outputs. To address this, a method is proposed to enhance references and augment the mixtures with WHAM!, aiming to train models that avoid learning noisy references. Two models trained on these enhanced datasets are evaluated with the non-intrusive NISQA.v2 metric. Results show reduced noise in separated speech but suggest that processing references may introduce artefacts, limiting overall quality gains. Negative correlation is found between SI-SDR and perceived noisiness across models on the WSJ0-2Mix and Libri2Mix test sets, underlining the conclusion from the derivation.
Dynamic Slimmable Networks for Efficient Speech Separation
Jul 08, 2025Recent progress in speech separation has been largely driven by advances in deep neural networks, yet their high computational and memory requirements hinder deployment on resource-constrained devices. A significant inefficiency in conventional systems arises from using static network architectures that maintain constant computational complexity across all input segments, regardless of their characteristics. This approach is sub-optimal for simpler segments that do not require intensive processing, such as silence or non-overlapping speech. To address this limitation, we propose a dynamic slimmable network (DSN) for speech separation that adaptively adjusts its computational complexity based on the input signal. The DSN combines a slimmable network, which can operate at different network widths, with a lightweight gating module that dynamically determines the required width by analyzing the local input characteristics. To balance performance and efficiency, we introduce a signal-dependent complexity loss that penalizes unnecessary computation based on segmental reconstruction error. Experiments on clean and noisy two-speaker mixtures from the WSJ0-2mix and WHAM! datasets show that the DSN achieves a better performance-efficiency trade-off than individually trained static networks of different sizes.
An Investigation on Speaker Augmentation for End-to-End Speaker Extraction
May 27, 2025Target confusion, defined as occasional switching to non-target speakers, poses a key challenge for end-to-end speaker extraction (E2E-SE) systems. We argue that this problem is largely caused by the lack of generalizability and discrimination of the speaker embeddings, and introduce a simple yet effective speaker augmentation strategy to tackle the problem. Specifically, we propose a time-domain resampling and rescaling pipeline that alters speaker traits while preserving other speech properties. This generates a variety of pseudo-speakers to help establish a generalizable speaker embedding space, while the speaker-trait-specific augmentation creates hard samples that force the model to focus on genuine speaker characteristics. Experiments on WSJ0-2Mix and LibriMix show that our method mitigates the target confusion and improves extraction performance. Moreover, it can be combined with metric learning, another effective approach to address target confusion, leading to further gains.
Listen to Extract: Onset-Prompted Target Speaker Extraction
May 08, 2025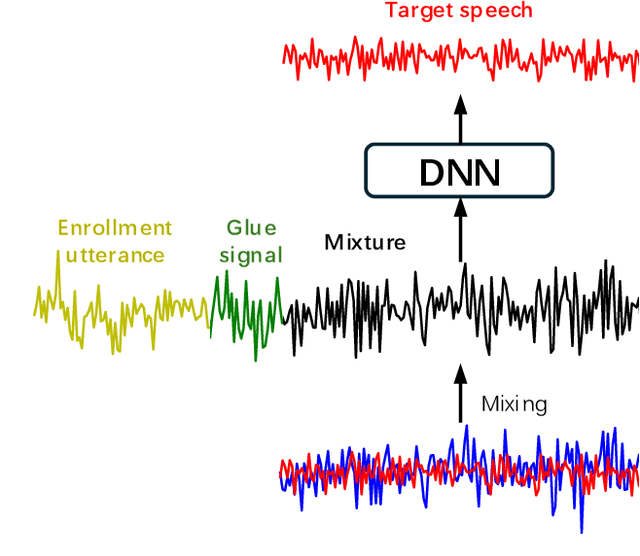
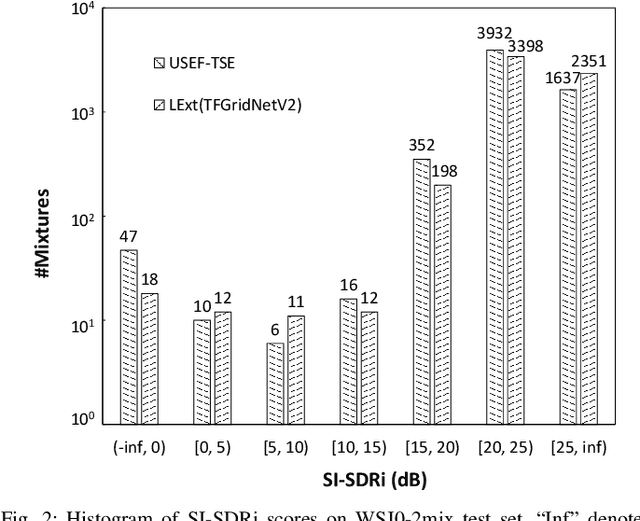
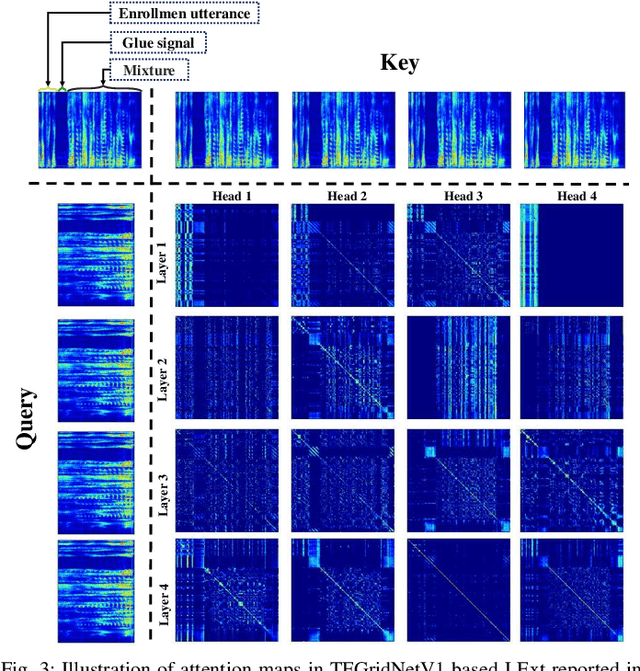
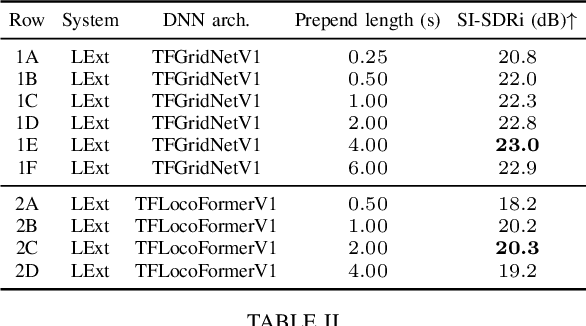
We propose $\textit{listen to extract}$ (LExt), a highly-effective while extremely-simple algorithm for monaural target speaker extraction (TSE). Given an enrollment utterance of a target speaker, LExt aims at extracting the target speaker from the speaker's mixed speech with other speakers. For each mixture, LExt concatenates an enrollment utterance of the target speaker to the mixture signal at the waveform level, and trains deep neural networks (DNN) to extract the target speech based on the concatenated mixture signal. The rationale is that, this way, an artificial speech onset is created for the target speaker and it could prompt the DNN (a) which speaker is the target to extract; and (b) spectral-temporal patterns of the target speaker that could help extraction. This simple approach produces strong TSE performance on multiple public TSE datasets including WSJ0-2mix, WHAM! and WHAMR!.
EDSep: An Effective Diffusion-Based Method for Speech Source Separation
Jan 27, 2025


Generative models have attracted considerable attention for speech separation tasks, and among these, diffusion-based methods are being explored. Despite the notable success of diffusion techniques in generation tasks, their adaptation to speech separation has encountered challenges, notably slow convergence and suboptimal separation outcomes. To address these issues and enhance the efficacy of diffusion-based speech separation, we introduce EDSep, a novel single-channel method grounded in score matching via stochastic differential equation (SDE). This method enhances generative modeling for speech source separation by optimizing training and sampling efficiency. Specifically, a novel denoiser function is proposed to approximate data distributions, which obtains ideal denoiser outputs. Additionally, a stochastic sampler is carefully designed to resolve the reverse SDE during the sampling process, gradually separating speech from mixtures. Extensive experiments on databases such as WSJ0-2mix, LRS2-2mix, and VoxCeleb2-2mix demonstrate our proposed method's superior performance over existing diffusion and discriminative models, validating its efficacy.
SQ-Whisper: Speaker-Querying based Whisper Model for Target-Speaker ASR
Dec 07, 2024Benefiting from massive and diverse data sources, speech foundation models exhibit strong generalization and knowledge transfer capabilities to a wide range of downstream tasks. However, a limitation arises from their exclusive handling of single-speaker speech input, making them ineffective in recognizing multi-speaker overlapped speech, a common occurrence in real-world scenarios. In this study, we delve into the adaptation of speech foundation models to eliminate interfering speakers from overlapping speech and perform target-speaker automatic speech recognition (TS-ASR). Initially, we utilize the Whisper model as the foundation for adaptation and conduct a thorough comparison of its integration with existing target-speaker adaptation techniques. We then propose an innovative model termed Speaker-Querying Whisper (SQ-Whisper), which employs a set number of trainable queries to capture speaker prompts from overlapping speech based on target-speaker enrollment. These prompts serve to steer the model in extracting speaker-specific features and accurately recognizing target-speaker transcriptions. Experimental results demonstrate that our approach effectively adapts the pre-trained speech foundation model to TS-ASR. Compared with the robust TS-HuBERT model, the proposed SQ-Whisper significantly improves performance, yielding up to 15% and 10% relative reductions in word error rates (WERs) on the Libri2Mix and WSJ0-2Mix datasets, respectively. With data augmentation, we establish new state-of-the-art WERs of 14.6% on the Libri2Mix Test set and 4.4% on the WSJ0-2Mix Test set. Furthermore, we evaluate our model on the real-world AMI meeting dataset, which shows consistent improvement over other adaptation methods.
Speech Separation using Neural Audio Codecs with Embedding Loss
Nov 27, 2024



Neural audio codecs have revolutionized audio processing by enabling speech tasks to be performed on highly compressed representations. Recent work has shown that speech separation can be achieved within these compressed domains, offering faster training and reduced inference costs. However, current approaches still rely on waveform-based loss functions, necessitating unnecessary decoding steps during training. We propose a novel embedding loss for neural audio codec-based speech separation that operates directly on compressed audio representations, eliminating the need for decoding during training. To validate our approach, we conduct comprehensive evaluations using both objective metrics and perceptual assessment techniques, including intrusive and non-intrusive methods. Our results demonstrate that embedding loss can be used to train codec-based speech separation models with a 2x improvement in training speed and computational cost while achieving better DNSMOS and STOI performance on the WSJ0-2mix dataset across 3 different pre-trained codecs.
X-CrossNet: A complex spectral mapping approach to target speaker extraction with cross attention speaker embedding fusion
Nov 21, 2024



Target speaker extraction (TSE) is a technique for isolating a target speaker's voice from mixed speech using auxiliary features associated with the target speaker. This approach addresses the cocktail party problem and is generally considered more promising for practical applications than conventional speech separation methods. Although academic research in this area has achieved high accuracy and evaluation scores on public datasets, most models exhibit significantly reduced performance in real-world noisy or reverberant conditions. To address this limitation, we propose a novel TSE model, X-CrossNet, which leverages CrossNet as its backbone. CrossNet is a speech separation network specifically optimized for challenging noisy and reverberant environments, achieving state-of-the-art performance in tasks such as speaker separation under these conditions. Additionally, to enhance the network's ability to capture and utilize auxiliary features of the target speaker, we integrate a Cross-Attention mechanism into the global multi-head self-attention (GMHSA) module within each CrossNet block. This facilitates more effective integration of target speaker features with mixed speech features. Experimental results show that our method performs superior separation on the WSJ0-2mix and WHAMR! datasets, demonstrating strong robustness and stability.
USEF-TSE: Universal Speaker Embedding Free Target Speaker Extraction
Sep 04, 2024



Target speaker extraction aims to isolate the voice of a specific speaker from mixed speech. Traditionally, this process has relied on extracting a speaker embedding from a reference speech, necessitating a speaker recognition model. However, identifying an appropriate speaker recognition model can be challenging, and using the target speaker embedding as reference information may not be optimal for target speaker extraction tasks. This paper introduces a Universal Speaker Embedding-Free Target Speaker Extraction (USEF-TSE) framework that operates without relying on speaker embeddings. USEF-TSE utilizes a multi-head cross-attention mechanism as a frame-level target speaker feature extractor. This innovative approach allows mainstream speaker extraction solutions to bypass the dependency on speaker recognition models and to fully leverage the information available in the enrollment speech, including speaker characteristics and contextual details. Additionally, USEF-TSE can seamlessly integrate with any time-domain or time-frequency domain speech separation model to achieve effective speaker extraction. Experimental results show that our proposed method achieves state-of-the-art (SOTA) performance in terms of Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) on the WSJ0-2mix, WHAM!, and WHAMR! datasets, which are standard benchmarks for monaural anechoic, noisy and noisy-reverberant two-speaker speech separation and speaker extraction.
Dual-path Mamba: Short and Long-term Bidirectional Selective Structured State Space Models for Speech Separation
Mar 27, 2024



Transformers have been the most successful architecture for various speech modeling tasks, including speech separation. However, the self-attention mechanism in transformers with quadratic complexity is inefficient in computation and memory. Recent models incorporate new layers and modules along with transformers for better performance but also introduce extra model complexity. In this work, we replace transformers with Mamba, a selective state space model, for speech separation. We propose dual-path Mamba, which models short-term and long-term forward and backward dependency of speech signals using selective state spaces. Our experimental results on the WSJ0-2mix data show that our dual-path Mamba models match or outperform dual-path transformer models Sepformer with only 60% of its parameters, and the QDPN with only 30% of its parameters. Our large model also reaches a new state-of-the-art SI-SNRi of 24.4 dB.