 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Story Qa
Papers and Code
What You See is What You Ask: Evaluating Audio Descriptions
Oct 01, 2025



Audio descriptions (ADs) narrate important visual details in movies, enabling Blind and Low Vision (BLV) users to understand narratives and appreciate visual details. Existing works in automatic AD generation mostly focus on few-second trimmed clips, and evaluate them by comparing against a single ground-truth reference AD. However, writing ADs is inherently subjective. Through alignment and analysis of two independent AD tracks for the same movies, we quantify the subjectivity in when and whether to describe, and what and how to highlight. Thus, we show that working with trimmed clips is inadequate. We propose ADQA, a QA benchmark that evaluates ADs at the level of few-minute long, coherent video segments, testing whether they would help BLV users understand the story and appreciate visual details. ADQA features visual appreciation (VA) questions about visual facts and narrative understanding (NU) questions based on the plot. Through ADQA, we show that current AD generation methods lag far behind human-authored ADs. We conclude with several recommendations for future work and introduce a public leaderboard for benchmarking.
Long Story Short: a Summarize-then-Search Method for Long Video Question Answering
Nov 02, 2023Large language models such as GPT-3 have demonstrated an impressive capability to adapt to new tasks without requiring task-specific training data. This capability has been particularly effective in settings such as narrative question answering, where the diversity of tasks is immense, but the available supervision data is small. In this work, we investigate if such language models can extend their zero-shot reasoning abilities to long multimodal narratives in multimedia content such as drama, movies, and animation, where the story plays an essential role. We propose Long Story Short, a framework for narrative video QA that first summarizes the narrative of the video to a short plot and then searches parts of the video relevant to the question. We also propose to enhance visual matching with CLIPCheck. Our model outperforms state-of-the-art supervised models by a large margin, highlighting the potential of zero-shot QA for long videos.
Co-attentional Transformers for Story-Based Video Understanding
Oct 27, 2020
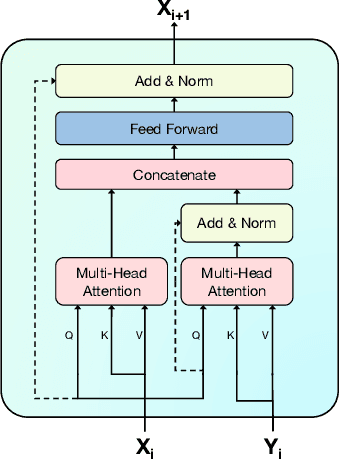
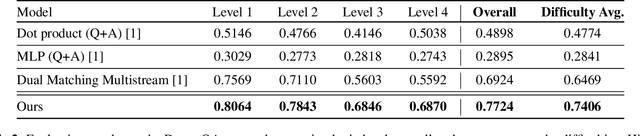
Inspired by recent trends in vision and language learning, we explore applications of attention mechanisms for visio-lingual fusion within an application to story-based video understanding. Like other video-based QA tasks, video story understanding requires agents to grasp complex temporal dependencies. However, as it focuses on the narrative aspect of video it also requires understanding of the interactions between different characters, as well as their actions and their motivations. We propose a novel co-attentional transformer model to better capture long-term dependencies seen in visual stories such as dramas and measure its performance on the video question answering task. We evaluate our approach on the recently introduced DramaQA dataset which features character-centered video story understanding questions. Our model outperforms the baseline model by 8 percentage points overall, at least 4.95 and up to 12.8 percentage points on all difficulty levels and manages to beat the winner of the DramaQA challenge.
DramaQA: Character-Centered Video Story Understanding with Hierarchical QA
May 07, 2020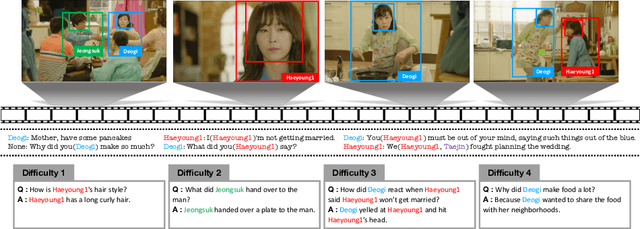
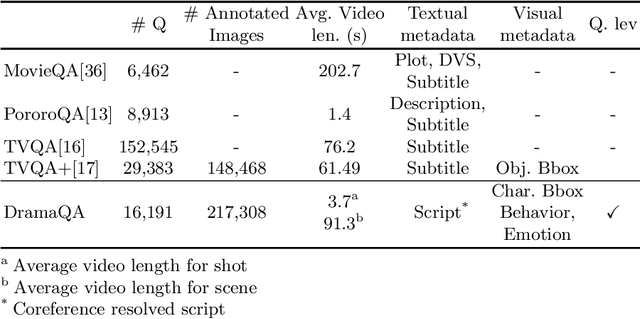
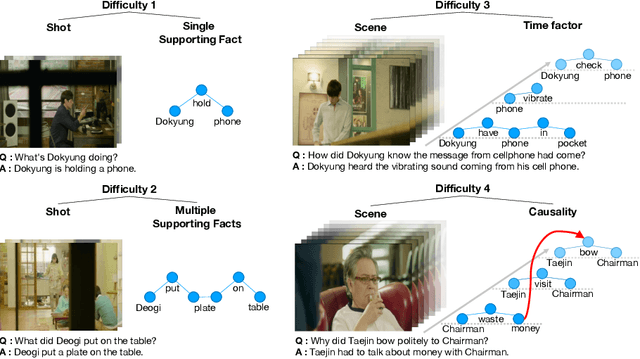
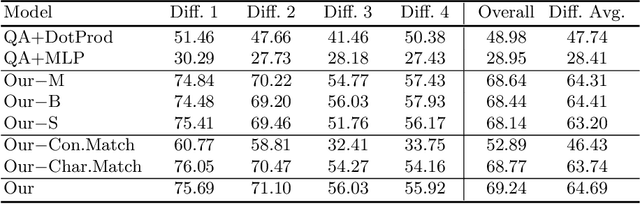
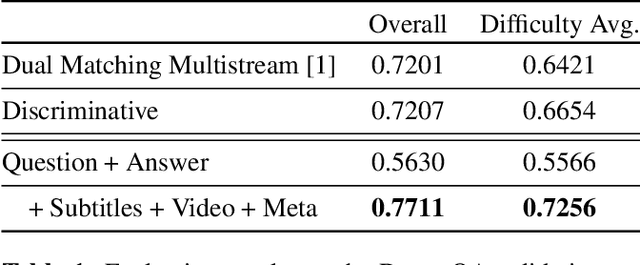
Despite recent progress on computer vision and natural language processing, developing video understanding intelligence is still hard to achieve due to the intrinsic difficulty of story in video. Moreover, there is not a theoretical metric for evaluating the degree of video understanding. In this paper, we propose a novel video question answering (Video QA) task, DramaQA, for a comprehensive understanding of the video story. The DramaQA focused on two perspectives: 1) hierarchical QAs as an evaluation metric based on the cognitive developmental stages of human intelligence. 2) character-centered video annotations to model local coherence of the story. Our dataset is built upon the TV drama "Another Miss Oh" and it contains 16,191 QA pairs from 23,928 various length video clips, with each QA pair belonging to one of four difficulty levels. We provide 217,308 annotated images with rich character-centered annotations, including visual bounding boxes, behaviors, and emotions of main characters, and coreference resolved scripts. Additionally, we provide analyses of the dataset as well as Dual Matching Multistream model which effectively learns character-centered representations of video to answer questions about the video. We are planning to release our dataset and model publicly for research purposes and expect that our work will provide a new perspective on video story understanding research.
CogME: A Novel Evaluation Metric for Video Understanding Intelligence
Jul 21, 2021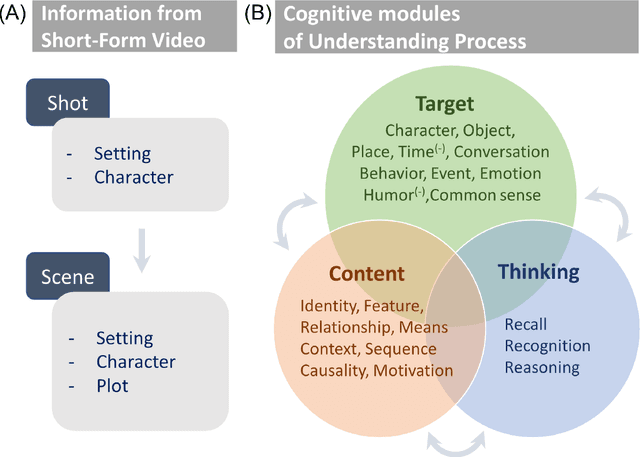
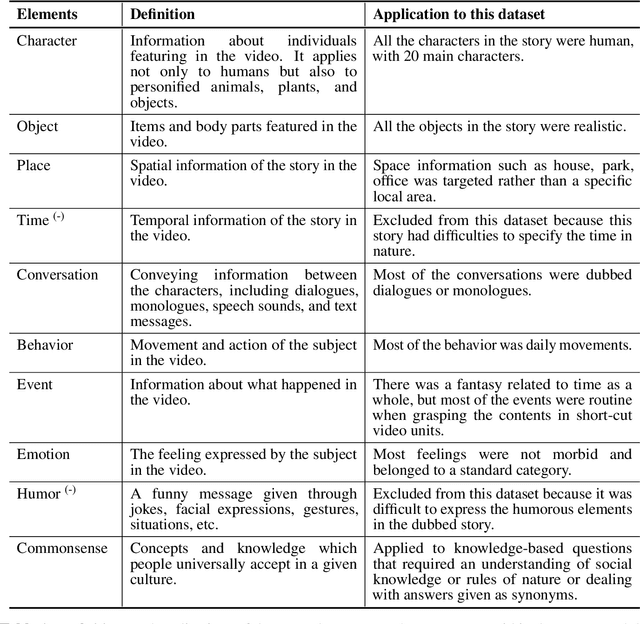
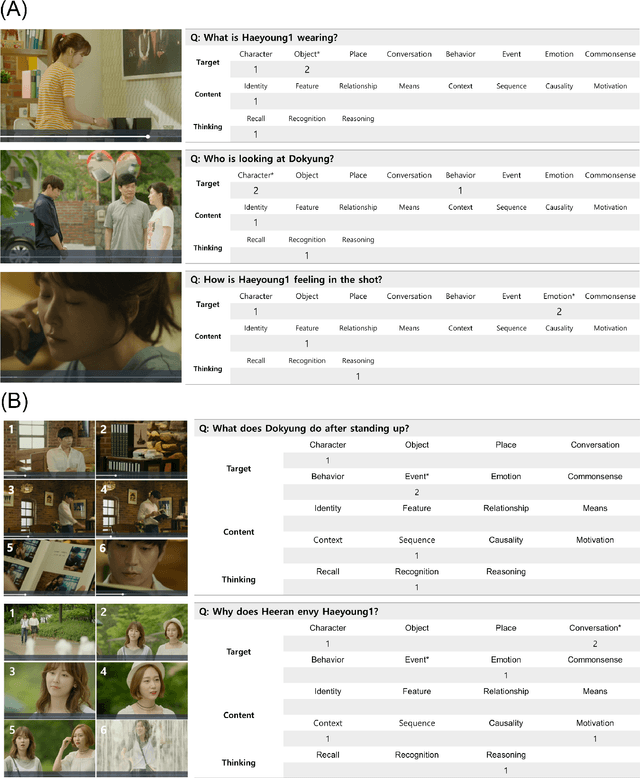
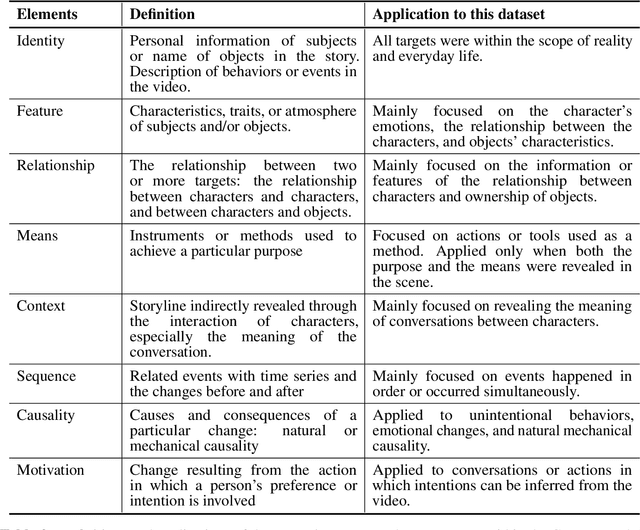
Developing video understanding intelligence is quite challenging because it requires holistic integration of images, scripts, and sounds based on natural language processing, temporal dependency, and reasoning. Recently, substantial attempts have been made on several video datasets with associated question answering (QA) on a large scale. However, existing evaluation metrics for video question answering (VideoQA) do not provide meaningful analysis. To make progress, we argue that a well-made framework, established on the way humans understand, is required to explain and evaluate the performance of understanding in detail. Then we propose a top-down evaluation system for VideoQA, based on the cognitive process of humans and story elements: Cognitive Modules for Evaluation (CogME). CogME is composed of three cognitive modules: targets, contents, and thinking. The interaction among the modules in the understanding procedure can be expressed in one sentence as follows: "I understand the CONTENT of the TARGET through a way of THINKING." Each module has sub-components derived from the story elements. We can specify the required aspects of understanding by annotating the sub-components to individual questions. CogME thus provides a framework for an elaborated specification of VideoQA datasets. To examine the suitability of a VideoQA dataset for validating video understanding intelligence, we evaluated the baseline model of the DramaQA dataset by applying CogME. The evaluation reveals that story elements are unevenly reflected in the existing dataset, and the model based on the dataset may cause biased predictions. Although this study has only been able to grasp a narrow range of stories, we expect that it offers the first step in considering the cognitive process of humans on the video understanding intelligence of humans and AI.
DeepStory: Video Story QA by Deep Embedded Memory Networks
Jul 04, 2017


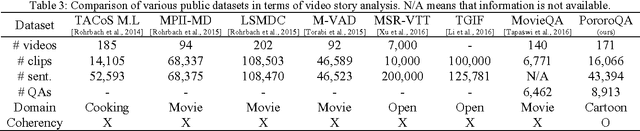
Question-answering (QA) on video contents is a significant challenge for achieving human-level intelligence as it involves both vision and language in real-world settings. Here we demonstrate the possibility of an AI agent performing video story QA by learning from a large amount of cartoon videos. We develop a video-story learning model, i.e. Deep Embedded Memory Networks (DEMN), to reconstruct stories from a joint scene-dialogue video stream using a latent embedding space of observed data. The video stories are stored in a long-term memory component. For a given question, an LSTM-based attention model uses the long-term memory to recall the best question-story-answer triplet by focusing on specific words containing key information. We trained the DEMN on a novel QA dataset of children's cartoon video series, Pororo. The dataset contains 16,066 scene-dialogue pairs of 20.5-hour videos, 27,328 fine-grained sentences for scene description, and 8,913 story-related QA pairs. Our experimental results show that the DEMN outperforms other QA models. This is mainly due to 1) the reconstruction of video stories in a scene-dialogue combined form that utilize the latent embedding and 2) attention. DEMN also achieved state-of-the-art results on the MovieQA benchmark.
Multimodal Dual Attention Memory for Video Story Question Answering
Sep 21, 2018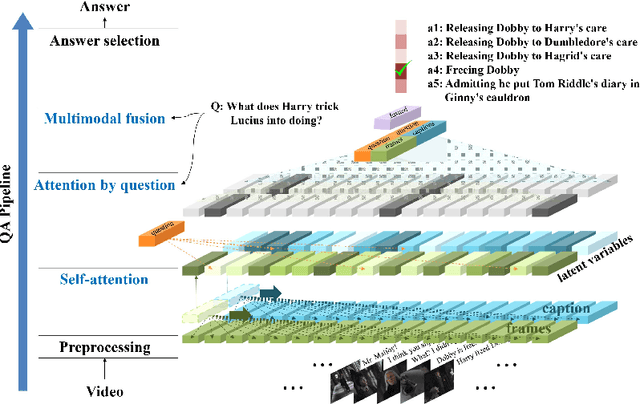
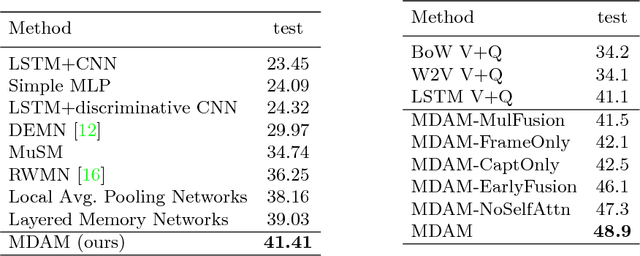
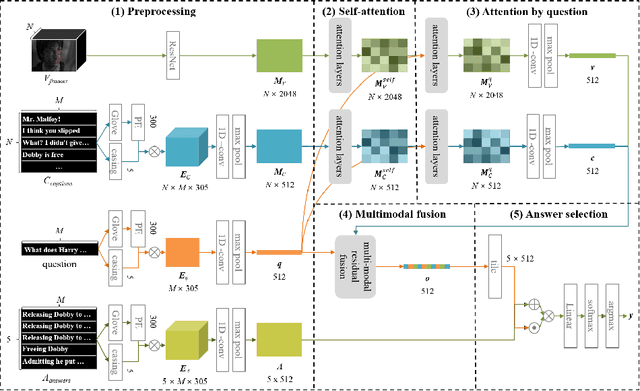
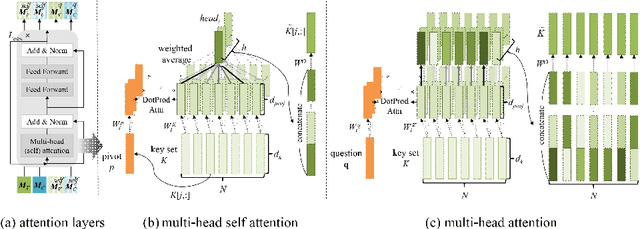
We propose a video story question-answering (QA) architecture, Multimodal Dual Attention Memory (MDAM). The key idea is to use a dual attention mechanism with late fusion. MDAM uses self-attention to learn the latent concepts in scene frames and captions. Given a question, MDAM uses the second attention over these latent concepts. Multimodal fusion is performed after the dual attention processes (late fusion). Using this processing pipeline, MDAM learns to infer a high-level vision-language joint representation from an abstraction of the full video content. We evaluate MDAM on PororoQA and MovieQA datasets which have large-scale QA annotations on cartoon videos and movies, respectively. For both datasets, MDAM achieves new state-of-the-art results with significant margins compared to the runner-up models. We confirm the best performance of the dual attention mechanism combined with late fusion by ablation studies. We also perform qualitative analysis by visualizing the inference mechanisms of MDAM.
Progressive Attention Memory Network for Movie Story Question Answering
Apr 18, 2019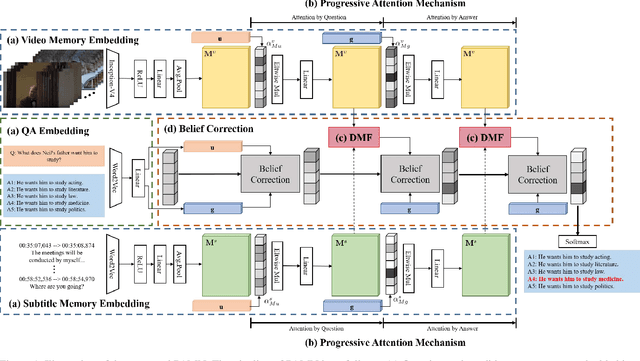
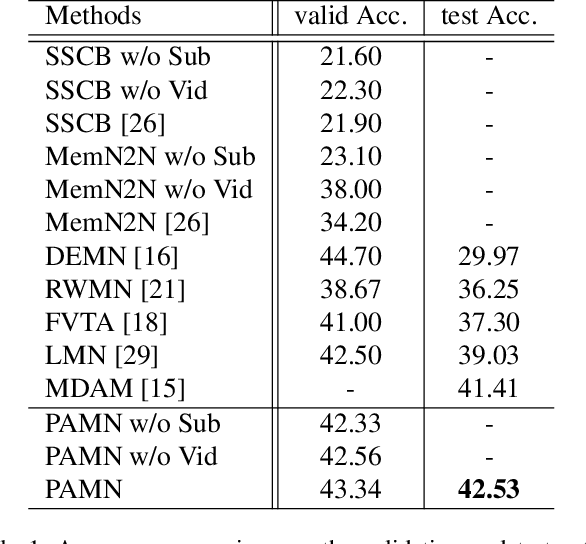
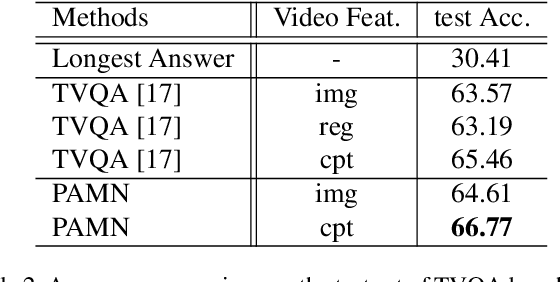
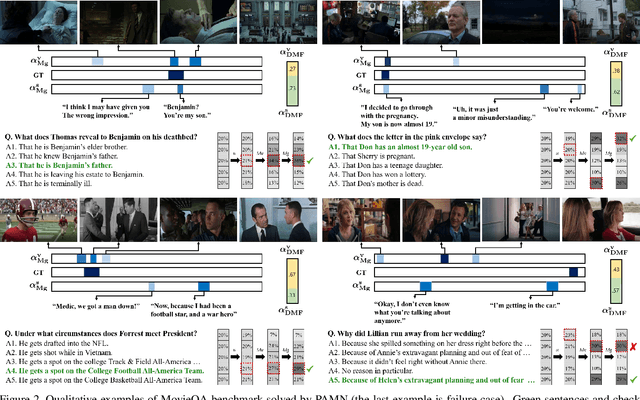
This paper proposes the progressive attention memory network (PAMN) for movie story question answering (QA). Movie story QA is challenging compared to VQA in two aspects: (1) pinpointing the temporal parts relevant to answer the question is difficult as the movies are typically longer than an hour, (2) it has both video and subtitle where different questions require different modality to infer the answer. To overcome these challenges, PAMN involves three main features: (1) progressive attention mechanism that utilizes cues from both question and answer to progressively prune out irrelevant temporal parts in memory, (2) dynamic modality fusion that adaptively determines the contribution of each modality for answering the current question, and (3) belief correction answering scheme that successively corrects the prediction score on each candidate answer. Experiments on publicly available benchmark datasets, MovieQA and TVQA, demonstrate that each feature contributes to our movie story QA architecture, PAMN, and improves performance to achieve the state-of-the-art result. Qualitative analysis by visualizing the inference mechanism of PAMN is also provided.
Two-stream Spatiotemporal Feature for Video QA Task
Jul 11, 2019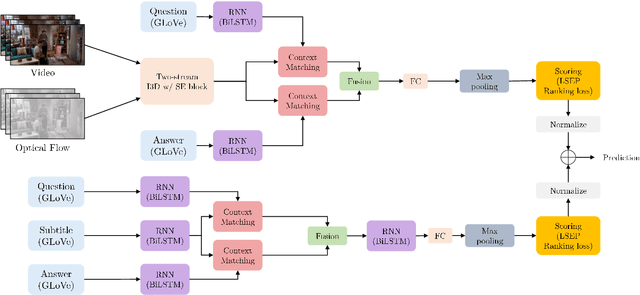
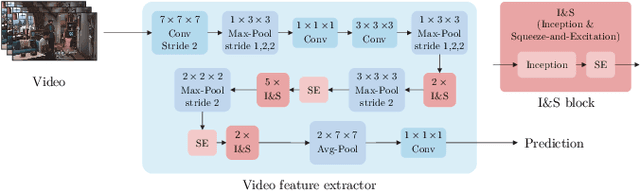
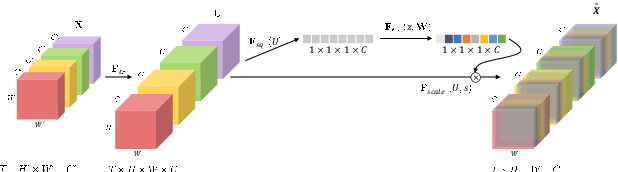

Understanding the content of videos is one of the core techniques for developing various helpful applications in the real world, such as recognizing various human actions for surveillance systems or customer behavior analysis in an autonomous shop. However, understanding the content or story of the video still remains a challenging problem due to its sheer amount of data and temporal structure. In this paper, we propose a multi-channel neural network structure that adopts a two-stream network structure, which has been shown high performance in human action recognition field, and use it as a spatiotemporal video feature extractor for solving video question and answering task. We also adopt a squeeze-and-excitation structure to two-stream network structure for achieving a channel-wise attended spatiotemporal feature. For jointly modeling the spatiotemporal features from video and the textual features from the question, we design a context matching module with a level adjusting layer to remove the gap of information between visual and textual features by applying attention mechanism on joint modeling. Finally, we adopt a scoring mechanism and smoothed ranking loss objective function for selecting the correct answer from answer candidates. We evaluate our model with TVQA dataset, and our approach shows the improved result in textual only setting, but the result with visual feature shows the limitation and possibility of our approach.
MovieQA: Understanding Stories in Movies through Question-Answering
Sep 21, 2016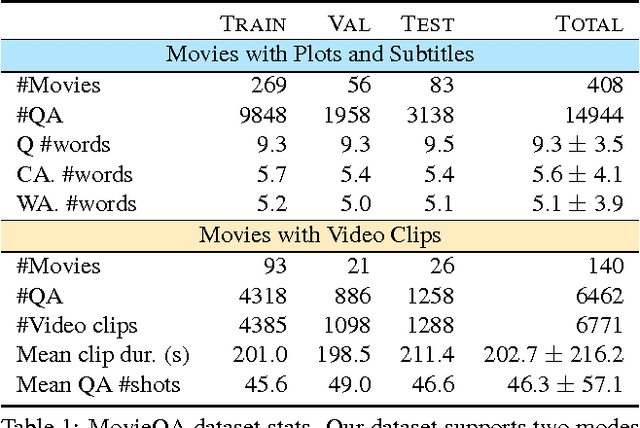

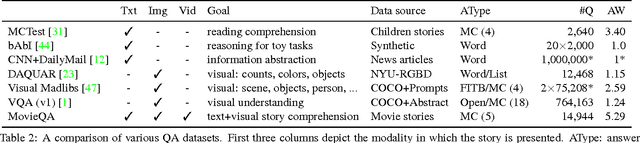
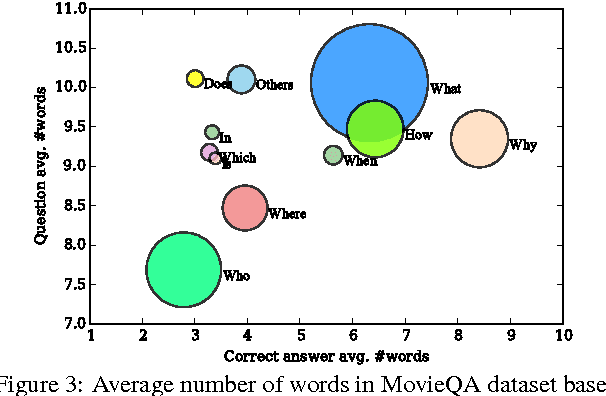
We introduce the MovieQA dataset which aims to evaluate automatic story comprehension from both video and text. The dataset consists of 14,944 questions about 408 movies with high semantic diversity. The questions range from simpler "Who" did "What" to "Whom", to "Why" and "How" certain events occurred. Each question comes with a set of five possible answers; a correct one and four deceiving answers provided by human annotators. Our dataset is unique in that it contains multiple sources of information -- video clips, plots, subtitles, scripts, and DVS. We analyze our data through various statistics and methods. We further extend existing QA techniques to show that question-answering with such open-ended semantics is hard. We make this data set public along with an evaluation benchmark to encourage inspiring work in this challenging domain.