 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTgan
Papers and Code
AI-based System for Transforming text and sound to Educational Videos
Jan 16, 2026Technological developments have produced methods that can generate educational videos from input text or sound. Recently, the use of deep learning techniques for image and video generation has been widely explored, particularly in education. However, generating video content from conditional inputs such as text or speech remains a challenging area. In this paper, we introduce a novel method to the educational structure, Generative Adversarial Network (GAN), which develop frame-for-frame frameworks and are able to create full educational videos. The proposed system is structured into three main phases In the first phase, the input (either text or speech) is transcribed using speech recognition. In the second phase, key terms are extracted and relevant images are generated using advanced models such as CLIP and diffusion models to enhance visual quality and semantic alignment. In the final phase, the generated images are synthesized into a video format, integrated with either pre-recorded or synthesized sound, resulting in a fully interactive educational video. The proposed system is compared with other systems such as TGAN, MoCoGAN, and TGANS-C, achieving a Fréchet Inception Distance (FID) score of 28.75%, which indicates improved visual quality and better over existing methods.
Deep Generative Models-Assisted Automated Labeling for Electron Microscopy Images Segmentation
Jul 28, 2024



The rapid advancement of deep learning has facilitated the automated processing of electron microscopy (EM) big data stacks. However, designing a framework that eliminates manual labeling and adapts to domain gaps remains challenging. Current research remains entangled in the dilemma of pursuing complete automation while still requiring simulations or slight manual annotations. Here we demonstrate tandem generative adversarial network (tGAN), a fully label-free and simulation-free pipeline capable of generating EM images for computer vision training. The tGAN can assimilate key features from new data stacks, thus producing a tailored virtual dataset for the training of automated EM analysis tools. Using segmenting nanoparticles for analyzing size distribution of supported catalysts as the demonstration, our findings showcased that the recognition accuracy of tGAN even exceeds the manually-labeling method by 5%. It can also be adaptively deployed to various data domains without further manual manipulation, which is verified by transfer learning from HAADF-STEM to BF-TEM. This generalizability may enable it to extend its application to a broader range of imaging characterizations, liberating microscopists and materials scientists from tedious dataset annotations.
Observer study-based evaluation of TGAN architecture used to generate oncological PET images
Nov 28, 2023The application of computer-vision algorithms in medical imaging has increased rapidly in recent years. However, algorithm training is challenging due to limited sample sizes, lack of labeled samples, as well as privacy concerns regarding data sharing. To address these issues, we previously developed (Bergen et al. 2022) a synthetic PET dataset for Head and Neck (H and N) cancer using the temporal generative adversarial network (TGAN) architecture and evaluated its performance segmenting lesions and identifying radiomics features in synthesized images. In this work, a two-alternative forced-choice (2AFC) observer study was performed to quantitatively evaluate the ability of human observers to distinguish between real and synthesized oncological PET images. In the study eight trained readers, including two board-certified nuclear medicine physicians, read 170 real/synthetic image pairs presented as 2D-transaxial using a dedicated web app. For each image pair, the observer was asked to identify the real image and input their confidence level with a 5-point Likert scale. P-values were computed using the binomial test and Wilcoxon signed-rank test. A heat map was used to compare the response accuracy distribution for the signed-rank test. Response accuracy for all observers ranged from 36.2% [27.9-44.4] to 63.1% [54.8-71.3]. Six out of eight observers did not identify the real image with statistical significance, indicating that the synthetic dataset was reasonably representative of oncological PET images. Overall, this study adds validity to the realism of our simulated H&N cancer dataset, which may be implemented in the future to train AI algorithms while favoring patient confidentiality and privacy protection.
Row Conditional-TGAN for generating synthetic relational databases
Nov 14, 2022

Besides reproducing tabular data properties of standalone tables, synthetic relational databases also require modeling the relationships between related tables. In this paper, we propose the Row Conditional-Tabular Generative Adversarial Network (RC-TGAN), a novel generative adversarial network (GAN) model that extends the tabular GAN to support modeling and synthesizing relational databases. The RC-TGAN models relationship information between tables by incorporating conditional data of parent rows into the design of the child table's GAN. We further extend the RC-TGAN to model the influence that grandparent table rows may have on their grandchild rows, in order to prevent the loss of this connection when the rows of the parent table fail to transfer this relationship information. The experimental results, using eight real relational databases, show significant improvements in the quality of the synthesized relational databases when compared to the benchmark system, demonstrating the effectiveness of the RC-TGAN in preserving relationships between tables of the original database.
3-D PET Image Generation with tumour masks using TGAN
Nov 02, 2021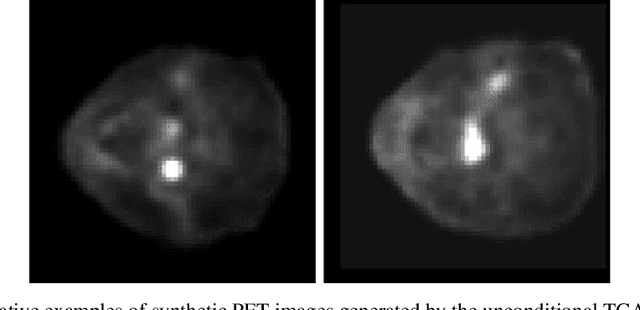
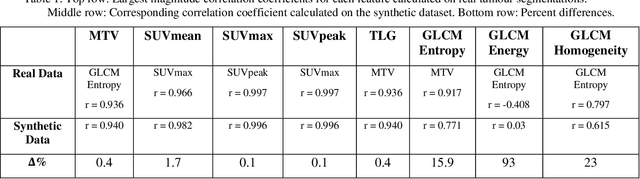
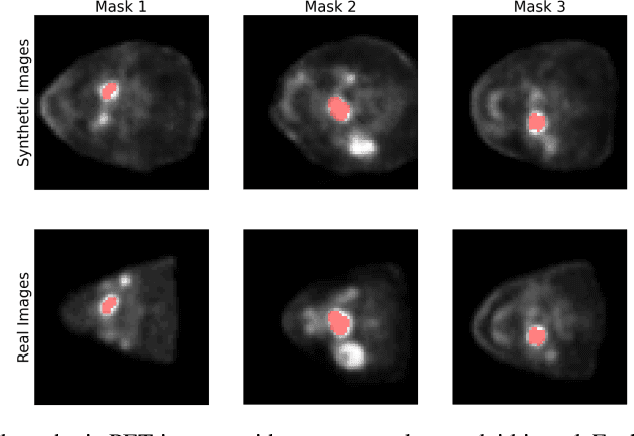
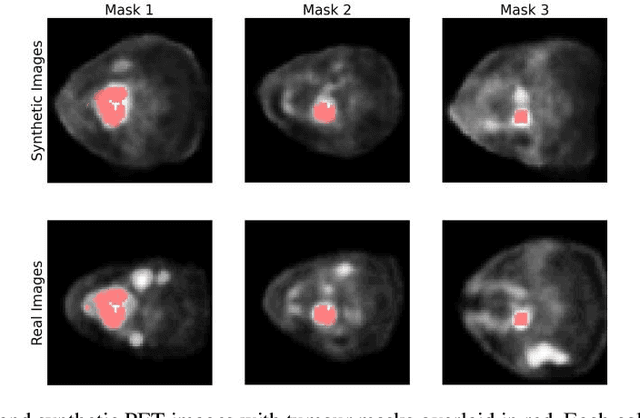
Training computer-vision related algorithms on medical images for disease diagnosis or image segmentation is difficult due to the lack of training data, labeled samples, and privacy concerns. For this reason, a robust generative method to create synthetic data is highly sought after. However, most three-dimensional image generators require additional image input or are extremely memory intensive. To address these issues we propose adapting video generation techniques for 3-D image generation. Using the temporal GAN (TGAN) architecture, we show we are able to generate realistic head and neck PET images. We also show that by conditioning the generator on tumour masks, we are able to control the geometry and location of the tumour in the generated images. To test the utility of the synthetic images, we train a segmentation model using the synthetic images. Synthetic images conditioned on real tumour masks are automatically segmented, and the corresponding real images are also segmented. We evaluate the segmentations using the Dice score and find the segmentation algorithm performs similarly on both datasets (0.65 synthetic data, 0.70 real data). Various radionomic features are then calculated over the segmented tumour volumes for each data set. A comparison of the real and synthetic feature distributions show that seven of eight feature distributions had statistically insignificant differences (p>0.05). Correlation coefficients were also calculated between all radionomic features and it is shown that all of the strong statistical correlations in the real data set are preserved in the synthetic data set.
Fed-TGAN: Federated Learning Framework for Synthesizing Tabular Data
Aug 18, 2021
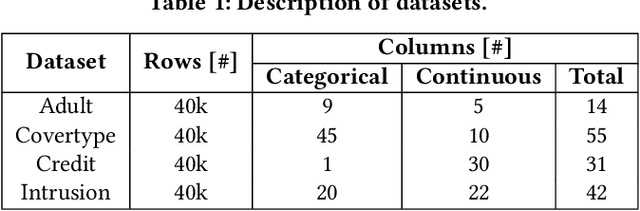
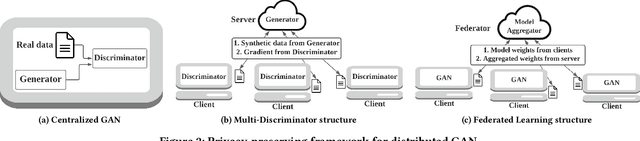
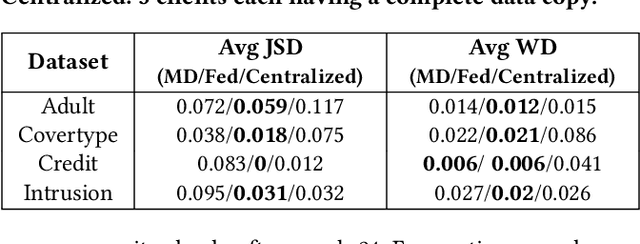
Generative Adversarial Networks (GANs) are typically trained to synthesize data, from images and more recently tabular data, under the assumption of directly accessible training data. Recently, federated learning (FL) is an emerging paradigm that features decentralized learning on client's local data with a privacy-preserving capability. And, while learning GANs to synthesize images on FL systems has just been demonstrated, it is unknown if GANs for tabular data can be learned from decentralized data sources. Moreover, it remains unclear which distributed architecture suits them best. Different from image GANs, state-of-the-art tabular GANs require prior knowledge on the data distribution of each (discrete and continuous) column to agree on a common encoding -- risking privacy guarantees. In this paper, we propose Fed-TGAN, the first Federated learning framework for Tabular GANs. To effectively learn a complex tabular GAN on non-identical participants, Fed-TGAN designs two novel features: (i) a privacy-preserving multi-source feature encoding for model initialization; and (ii) table similarity aware weighting strategies to aggregate local models for countering data skew. We extensively evaluate the proposed Fed-TGAN against variants of decentralized learning architectures on four widely used datasets. Results show that Fed-TGAN accelerates training time per epoch up to 200% compared to the alternative architectures, for both IID and Non-IID data. Overall, Fed-TGAN not only stabilizes the training loss, but also achieves better similarity between generated and original data.
DTGAN: Differential Private Training for Tabular GANs
Aug 02, 2021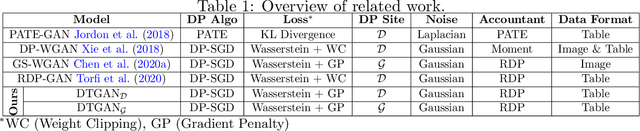
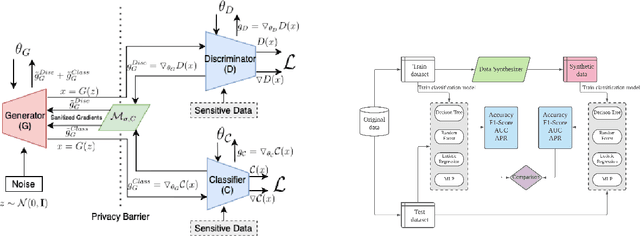

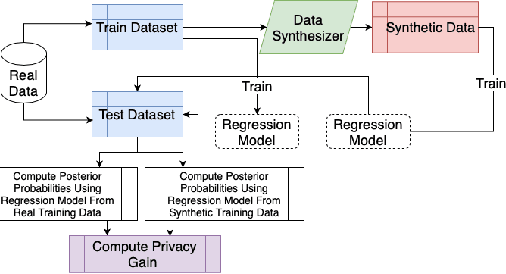
Tabular generative adversarial networks (TGAN) have recently emerged to cater to the need of synthesizing tabular data -- the most widely used data format. While synthetic tabular data offers the advantage of complying with privacy regulations, there still exists a risk of privacy leakage via inference attacks due to interpolating the properties of real data during training. Differential private (DP) training algorithms provide theoretical guarantees for training machine learning models by injecting statistical noise to prevent privacy leaks. However, the challenges of applying DP on TGAN are to determine the most optimal framework (i.e., PATE/DP-SGD) and neural network (i.e., Generator/Discriminator)to inject noise such that the data utility is well maintained under a given privacy guarantee. In this paper, we propose DTGAN, a novel conditional Wasserstein tabular GAN that comes in two variants DTGAN_G and DTGAN_D, for providing a detailed comparison of tabular GANs trained using DP-SGD for the generator vs discriminator, respectively. We elicit the privacy analysis associated with training the generator with complex loss functions (i.e., classification and information losses) needed for high quality tabular data synthesis. Additionally, we rigorously evaluate the theoretical privacy guarantees offered by DP empirically against membership and attribute inference attacks. Our results on 3 datasets show that the DP-SGD framework is superior to PATE and that a DP discriminator is more optimal for training convergence. Thus, we find (i) DTGAN_D is capable of maintaining the highest data utility across 4 ML models by up to 18% in terms of the average precision score for a strict privacy budget, epsilon = 1, as compared to the prior studies and (ii) DP effectively prevents privacy loss against inference attacks by restricting the success probability of membership attacks to be close to 50%.
Causal-TGAN: Generating Tabular Data Using Causal Generative Adversarial Networks
Apr 21, 2021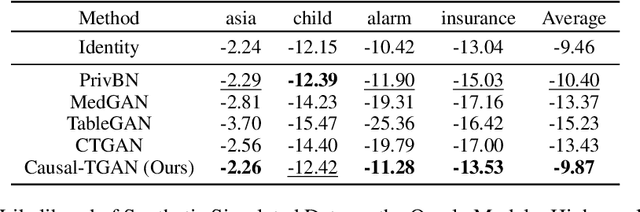
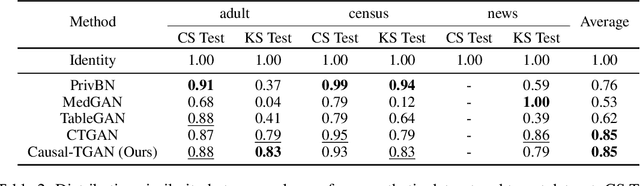
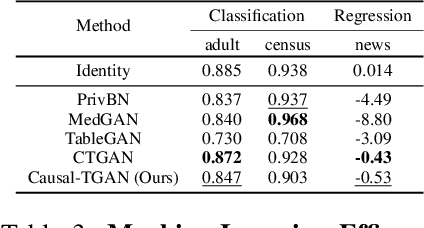
Synthetic data generation becomes prevalent as a solution to privacy leakage and data shortage. Generative models are designed to generate a realistic synthetic dataset, which can precisely express the data distribution for the real dataset. The generative adversarial networks (GAN), which gain great success in the computer vision fields, are doubtlessly used for synthetic data generation. Though there are prior works that have demonstrated great progress, most of them learn the correlations in the data distributions rather than the true processes in which the datasets are naturally generated. Correlation is not reliable for it is a statistical technique that only tells linear dependencies and is easily affected by the dataset's bias. Causality, which encodes all underlying factors of how the real data be naturally generated, is more reliable than correlation. In this work, we propose a causal model named Causal Tabular Generative Neural Network (Causal-TGAN) to generate synthetic tabular data using the tabular data's causal information. Extensive experiments on both simulated datasets and real datasets demonstrate the better performance of our method when given the true causal graph and a comparable performance when using the estimated causal graph.
Modeling Tabular data using Conditional GAN
Jul 01, 2019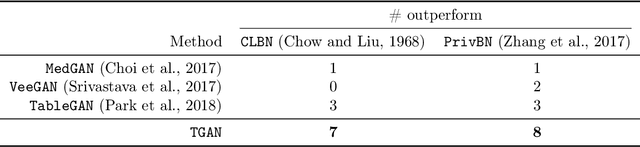
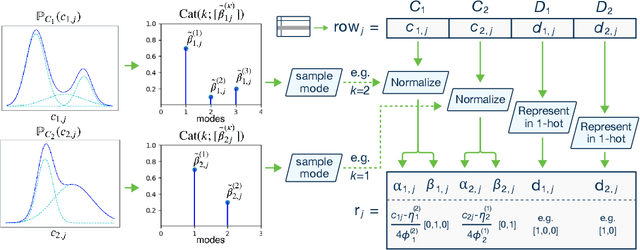
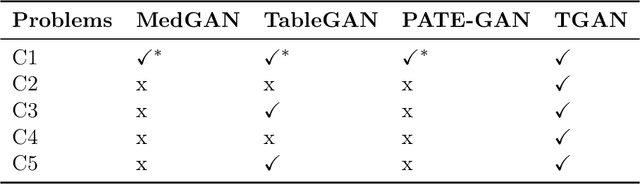
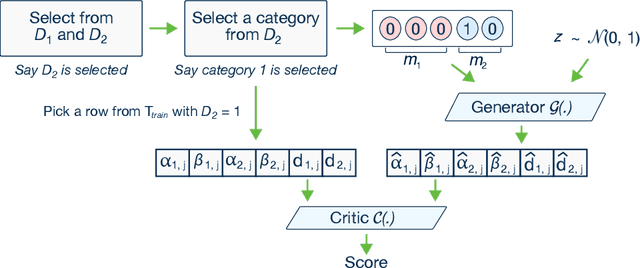
Modeling the probability distribution of rows in tabular data and generating realistic synthetic data is a non-trivial task. Tabular data usually contains a mix of discrete and continuous columns. Continuous columns may have multiple modes whereas discrete columns are sometimes imbalanced making the modeling difficult. Existing statistical and deep neural network models fail to properly model this type of data. We design TGAN, which uses a conditional generative adversarial network to address these challenges. To aid in a fair and thorough comparison, we design a benchmark with 7 simulated and 8 real datasets and several Bayesian network baselines. TGAN outperforms Bayesian methods on most of the real datasets whereas other deep learning methods could not.
TGAN: Deep Tensor Generative Adversarial Nets for Large Image Generation
Jan 28, 2019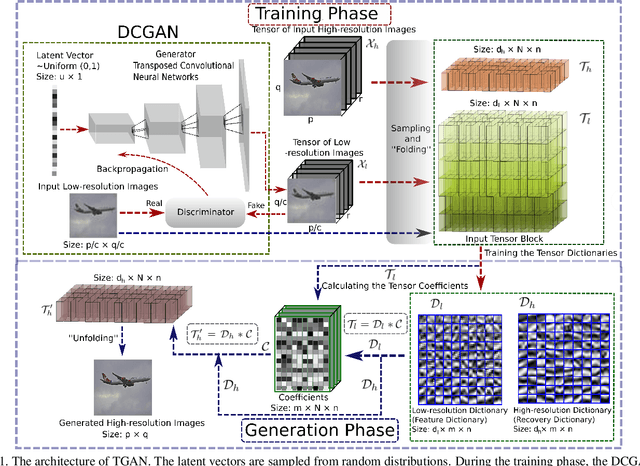
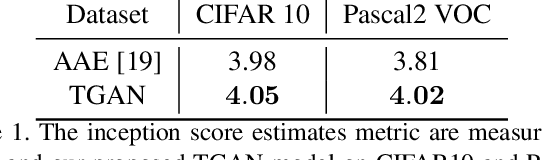
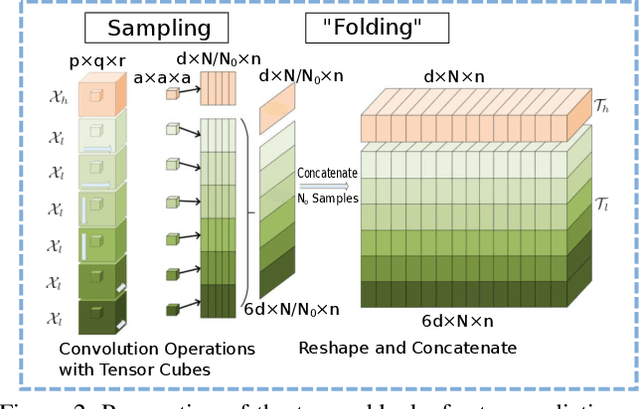

Deep generative models have been successfully applied to many applications. However, existing works experience limitations when generating large images (the literature usually generates small images, e.g. 32 * 32 or 128 * 128). In this paper, we propose a novel scheme, called deep tensor adversarial generative nets (TGAN), that generates large high-quality images by exploring tensor structures. Essentially, the adversarial process of TGAN takes place in a tensor space. First, we impose tensor structures for concise image representation, which is superior in capturing the pixel proximity information and the spatial patterns of elementary objects in images, over the vectorization preprocess in existing works. Secondly, we propose TGAN that integrates deep convolutional generative adversarial networks and tensor super-resolution in a cascading manner, to generate high-quality images from random distributions. More specifically, we design a tensor super-resolution process that consists of tensor dictionary learning and tensor coefficients learning. Finally, on three datasets, the proposed TGAN generates images with more realistic textures, compared with state-of-the-art adversarial autoencoders. The size of the generated images is increased by over 8.5 times, namely 374 * 374 in PASCAL2.