 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinTrace: Holistic Trajectory-Level Evaluation of LLM Tool Calling for Long-Horizon Financial Tasks
Apr 11, 2026Recent studies demonstrate that tool-calling capability enables large language models (LLMs) to interact with external environments for long-horizon financial tasks. While existing benchmarks have begun evaluating financial tool calling, they focus on limited scenarios and rely on call-level metrics that fail to capture trajectory-level reasoning quality. To address this gap, we introduce FinTrace, a benchmark comprising 800 expert-annotated trajectories spanning 34 real-world financial task categories across multiple difficulty levels. FinTrace employs a rubric-based evaluation protocol with nine metrics organized along four axes -- action correctness, execution efficiency, process quality, and output quality -- enabling fine-grained assessment of LLM tool-calling behavior. Our evaluation of 13 LLMs reveals that while frontier models achieve strong tool selection, all models struggle with information utilization and final answer quality, exposing a critical gap between invoking the right tools and reasoning effectively over their outputs. To move beyond diagnosis, we construct FinTrace-Training, the first trajectory-level preference dataset for financial tool-calling, containing 8,196 curated trajectories with tool-augmented contexts and preference pairs. We fine-tune Qwen-3.5-9B using supervised fine-tuning followed by direct preference optimization (DPO) and show that training on FinTrace-Training consistently improves intermediate reasoning metrics, with DPO more effectively suppressing failure modes. However, end-to-end answer quality remains a bottleneck, indicating that trajectory-level improvements do not yet fully propagate to final output quality.
MERMAID: Memory-Enhanced Retrieval and Reasoning with Multi-Agent Iterative Knowledge Grounding for Veracity Assessment
Jan 29, 2026Assessing the veracity of online content has become increasingly critical. Large language models (LLMs) have recently enabled substantial progress in automated veracity assessment, including automated fact-checking and claim verification systems. Typical veracity assessment pipelines break down complex claims into sub-claims, retrieve external evidence, and then apply LLM reasoning to assess veracity. However, existing methods often treat evidence retrieval as a static, isolated step and do not effectively manage or reuse retrieved evidence across claims. In this work, we propose MERMAID, a memory-enhanced multi-agent veracity assessment framework that tightly couples the retrieval and reasoning processes. MERMAID integrates agent-driven search, structured knowledge representations, and a persistent memory module within a Reason-Action style iterative process, enabling dynamic evidence acquisition and cross-claim evidence reuse. By retaining retrieved evidence in an evidence memory, the framework reduces redundant searches and improves verification efficiency and consistency. We evaluate MERMAID on three fact-checking benchmarks and two claim-verification datasets using multiple LLMs, including GPT, LLaMA, and Qwen families. Experimental results show that MERMAID achieves state-of-the-art performance while improving the search efficiency, demonstrating the effectiveness of synergizing retrieval, reasoning, and memory for reliable veracity assessment.
Systematic Evaluation of Machine-Generated Reasoning and PHQ-9 Labeling for Depression Detection Using Large Language Models
May 21, 2025Recent research leverages large language models (LLMs) for early mental health detection, such as depression, often optimized with machine-generated data. However, their detection may be subject to unknown weaknesses. Meanwhile, quality control has not been applied to these generated corpora besides limited human verifications. Our goal is to systematically evaluate LLM reasoning and reveal potential weaknesses. To this end, we first provide a systematic evaluation of the reasoning over machine-generated detection and interpretation. Then we use the models' reasoning abilities to explore mitigation strategies for enhanced performance. Specifically, we do the following: A. Design an LLM instruction strategy that allows for systematic analysis of the detection by breaking down the task into several subtasks. B. Design contrastive few-shot and chain-of-thought prompts by selecting typical positive and negative examples of detection reasoning. C. Perform human annotation for the subtasks identified in the first step and evaluate the performance. D. Identify human-preferred detection with desired logical reasoning from the few-shot generation and use them to explore different optimization strategies. We conducted extensive comparisons on the DepTweet dataset across the following subtasks: 1. identifying whether the speaker is describing their own depression; 2. accurately detecting the presence of PHQ-9 symptoms, and 3. finally, detecting depression. Human verification of statistical outliers shows that LLMs demonstrate greater accuracy in analyzing and detecting explicit language of depression as opposed to implicit expressions of depression. Two optimization methods are used for performance enhancement and reduction of the statistic bias: supervised fine-tuning (SFT) and direct preference optimization (DPO). Notably, the DPO approach achieves significant performance improvement.
ECC Analyzer: Extract Trading Signal from Earnings Conference Calls using Large Language Model for Stock Performance Prediction
Apr 29, 2024



In the realm of financial analytics, leveraging unstructured data, such as earnings conference calls (ECCs), to forecast stock performance is a critical challenge that has attracted both academics and investors. While previous studies have used deep learning-based models to obtain a general view of ECCs, they often fail to capture detailed, complex information. Our study introduces a novel framework: \textbf{ECC Analyzer}, combining Large Language Models (LLMs) and multi-modal techniques to extract richer, more predictive insights. The model begins by summarizing the transcript's structure and analyzing the speakers' mode and confidence level by detecting variations in tone and pitch for audio. This analysis helps investors form an overview perception of the ECCs. Moreover, this model uses the Retrieval-Augmented Generation (RAG) based methods to meticulously extract the focuses that have a significant impact on stock performance from an expert's perspective, providing a more targeted analysis. The model goes a step further by enriching these extracted focuses with additional layers of analysis, such as sentiment and audio segment features. By integrating these insights, the ECC Analyzer performs multi-task predictions of stock performance, including volatility, value-at-risk (VaR), and return for different intervals. The results show that our model outperforms traditional analytic benchmarks, confirming the effectiveness of using advanced LLM techniques in financial analytics.
RiskLabs: Predicting Financial Risk Using Large Language Model Based on Multi-Sources Data
Apr 11, 2024



The integration of Artificial Intelligence (AI) techniques, particularly large language models (LLMs), in finance has garnered increasing academic attention. Despite progress, existing studies predominantly focus on tasks like financial text summarization, question-answering (Q$\&$A), and stock movement prediction (binary classification), with a notable gap in the application of LLMs for financial risk prediction. Addressing this gap, in this paper, we introduce \textbf{RiskLabs}, a novel framework that leverages LLMs to analyze and predict financial risks. RiskLabs uniquely combines different types of financial data, including textual and vocal information from Earnings Conference Calls (ECCs), market-related time series data, and contextual news data surrounding ECC release dates. Our approach involves a multi-stage process: initially extracting and analyzing ECC data using LLMs, followed by gathering and processing time-series data before the ECC dates to model and understand risk over different timeframes. Using multimodal fusion techniques, RiskLabs amalgamates these varied data features for comprehensive multi-task financial risk prediction. Empirical experiment results demonstrate RiskLab's effectiveness in forecasting both volatility and variance in financial markets. Through comparative experiments, we demonstrate how different data sources contribute to financial risk assessment and discuss the critical role of LLMs in this context. Our findings not only contribute to the AI in finance application but also open new avenues for applying LLMs in financial risk assessment.
Can Large Language Models Detect Misinformation in Scientific News Reporting?
Feb 22, 2024



Scientific facts are often spun in the popular press with the intent to influence public opinion and action, as was evidenced during the COVID-19 pandemic. Automatic detection of misinformation in the scientific domain is challenging because of the distinct styles of writing in these two media types and is still in its nascence. Most research on the validity of scientific reporting treats this problem as a claim verification challenge. In doing so, significant expert human effort is required to generate appropriate claims. Our solution bypasses this step and addresses a more real-world scenario where such explicit, labeled claims may not be available. The central research question of this paper is whether it is possible to use large language models (LLMs) to detect misinformation in scientific reporting. To this end, we first present a new labeled dataset SciNews, containing 2.4k scientific news stories drawn from trusted and untrustworthy sources, paired with related abstracts from the CORD-19 database. Our dataset includes both human-written and LLM-generated news articles, making it more comprehensive in terms of capturing the growing trend of using LLMs to generate popular press articles. Then, we identify dimensions of scientific validity in science news articles and explore how this can be integrated into the automated detection of scientific misinformation. We propose several baseline architectures using LLMs to automatically detect false representations of scientific findings in the popular press. For each of these architectures, we use several prompt engineering strategies including zero-shot, few-shot, and chain-of-thought prompting. We also test these architectures and prompting strategies on GPT-3.5, GPT-4, and Llama2-7B, Llama2-13B.
Revisiting Attention Weights as Explanations from an Information Theoretic Perspective
Oct 31, 2022



Attention mechanisms have recently demonstrated impressive performance on a range of NLP tasks, and attention scores are often used as a proxy for model explainability. However, there is a debate on whether attention weights can, in fact, be used to identify the most important inputs to a model. We approach this question from an information theoretic perspective by measuring the mutual information between the model output and the hidden states. From extensive experiments, we draw the following conclusions: (i) Additive and Deep attention mechanisms are likely to be better at preserving the information between the hidden states and the model output (compared to Scaled Dot-product); (ii) ablation studies indicate that Additive attention can actively learn to explain the importance of its input hidden representations; (iii) when attention values are nearly the same, the rank order of attention values is not consistent with the rank order of the mutual information(iv) Using Gumbel-Softmax with a temperature lower than one, tends to produce a more skewed attention score distribution compared to softmax and hence is a better choice for explainable design; (v) some building blocks are better at preserving the correlation between the ordered list of mutual information and attention weights order (for e.g., the combination of BiLSTM encoder and Additive attention). Our findings indicate that attention mechanisms do have the potential to function as a shortcut to model explanations when they are carefully combined with other model elements.
MMCoVaR: Multimodal COVID-19 Vaccine Focused Data Repository for Fake News Detection and a Baseline Architecture for Classification
Sep 23, 2021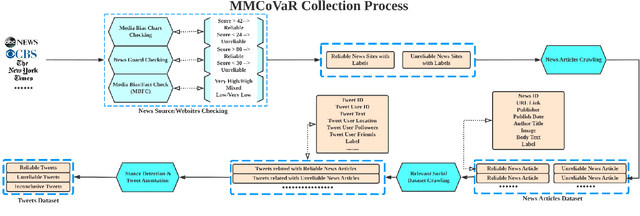
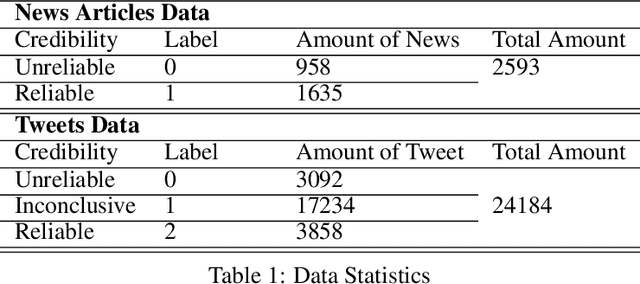
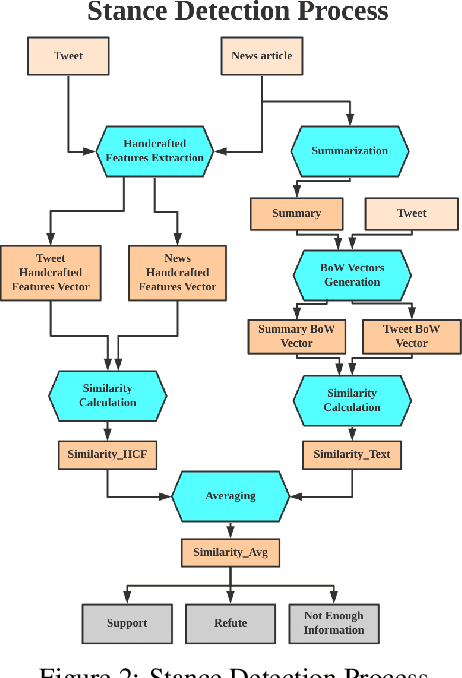

The outbreak of COVID-19 has resulted in an "infodemic" that has encouraged the propagation of misinformation about COVID-19 and cure methods which, in turn, could negatively affect the adoption of recommended public health measures in the larger population. In this paper, we provide a new multimodal (consisting of images, text and temporal information) labeled dataset containing news articles and tweets on the COVID-19 vaccine. We collected 2,593 news articles from 80 publishers for one year between Feb 16th 2020 to May 8th 2021 and 24184 Twitter posts (collected between April 17th 2021 to May 8th 2021). We combine ratings from two news media ranking sites: Medias Bias Chart and Media Bias/Fact Check (MBFC) to classify the news dataset into two levels of credibility: reliable and unreliable. The combination of two filters allows for higher precision of labeling. We also propose a stance detection mechanism to annotate tweets into three levels of credibility: reliable, unreliable and inconclusive. We provide several statistics as well as other analytics like, publisher distribution, publication date distribution, topic analysis, etc. We also provide a novel architecture that classifies the news data into misinformation or truth to provide a baseline performance for this dataset. We find that the proposed architecture has an F-Score of 0.919 and accuracy of 0.882 for fake news detection. Furthermore, we provide benchmark performance for misinformation detection on tweet dataset. This new multimodal dataset can be used in research on COVID-19 vaccine, including misinformation detection, influence of fake COVID-19 vaccine information, etc.
Learning Models for Suicide Prediction from Social Media Posts
Apr 29, 2021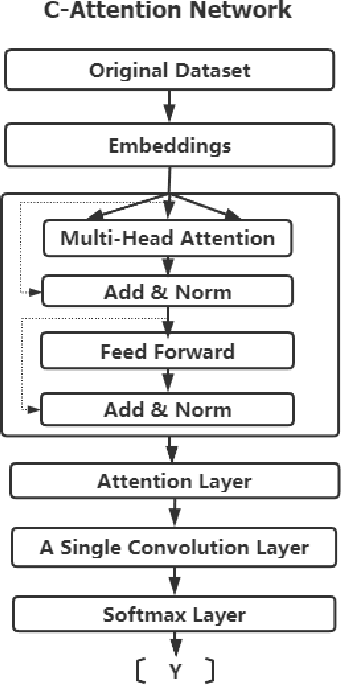
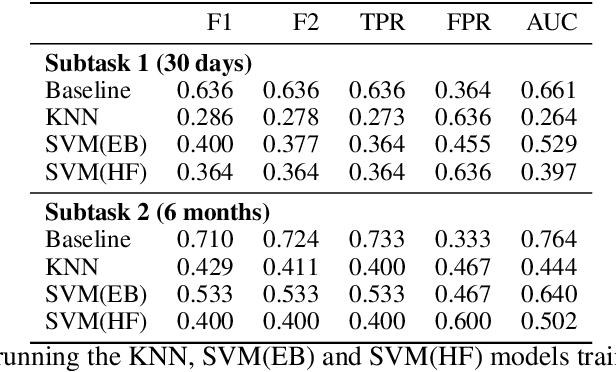
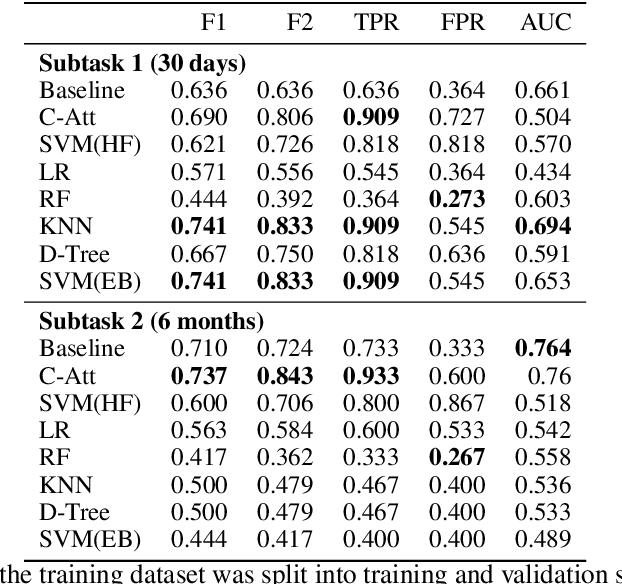
We propose a deep learning architecture and test three other machine learning models to automatically detect individuals that will attempt suicide within (1) 30 days and (2) six months, using their social media post data provided in the CLPsych 2021 shared task. Additionally, we create and extract three sets of handcrafted features for suicide risk detection based on the three-stage theory of suicide and prior work on emotions and the use of pronouns among persons exhibiting suicidal ideations. Extensive experimentations show that some of the traditional machine learning methods outperform the baseline with an F1 score of 0.741 and F2 score of 0.833 on subtask 1 (prediction of a suicide attempt 30 days prior). However, the proposed deep learning method outperforms the baseline with F1 score of 0.737 and F2 score of 0.843 on subtask 2 (prediction of suicide 6 months prior).
Causal-TGAN: Generating Tabular Data Using Causal Generative Adversarial Networks
Apr 21, 2021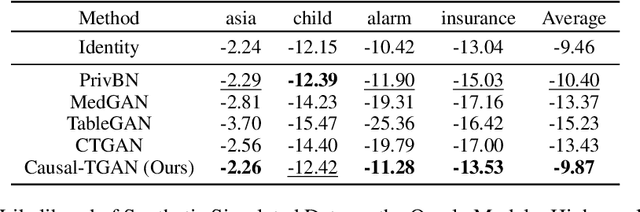
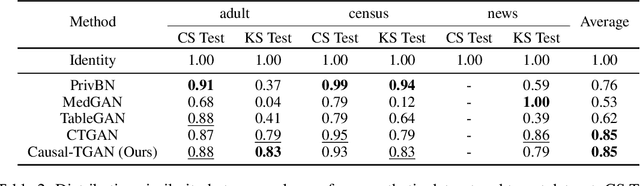
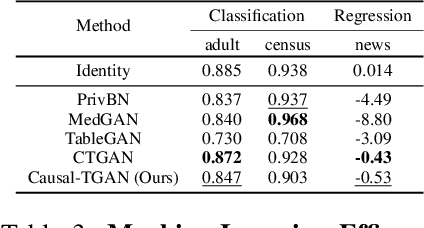
Synthetic data generation becomes prevalent as a solution to privacy leakage and data shortage. Generative models are designed to generate a realistic synthetic dataset, which can precisely express the data distribution for the real dataset. The generative adversarial networks (GAN), which gain great success in the computer vision fields, are doubtlessly used for synthetic data generation. Though there are prior works that have demonstrated great progress, most of them learn the correlations in the data distributions rather than the true processes in which the datasets are naturally generated. Correlation is not reliable for it is a statistical technique that only tells linear dependencies and is easily affected by the dataset's bias. Causality, which encodes all underlying factors of how the real data be naturally generated, is more reliable than correlation. In this work, we propose a causal model named Causal Tabular Generative Neural Network (Causal-TGAN) to generate synthetic tabular data using the tabular data's causal information. Extensive experiments on both simulated datasets and real datasets demonstrate the better performance of our method when given the true causal graph and a comparable performance when using the estimated causal graph.