 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTau Spatial Sound Events
Papers and Code
Class-Incremental Learning for Sound Event Localization and Detection
Nov 19, 2024This paper investigates the feasibility of class-incremental learning (CIL) for Sound Event Localization and Detection (SELD) tasks. The method features an incremental learner that can learn new sound classes independently while preserving knowledge of old classes. The continual learning is achieved through a mean square error-based distillation loss to minimize output discrepancies between subsequent learners. The experiments are conducted on the TAU-NIGENS Spatial Sound Events 2021 dataset, which includes 12 different sound classes and demonstrate the efficacy of proposed method. We begin by learning 8 classes and introduce the 4 new classes at next stage. After the incremental phase, the system is evaluated on the full set of learned classes. Results show that, for this realistic dataset, our proposed method successfully maintains baseline performance across all metrics.
PSELDNets: Pre-trained Neural Networks on Large-scale Synthetic Datasets for Sound Event Localization and Detection
Nov 10, 2024



Sound event localization and detection (SELD) has seen substantial advancements through learning-based methods. These systems, typically trained from scratch on specific datasets, have shown considerable generalization capabilities. Recently, deep neural networks trained on large-scale datasets have achieved remarkable success in the sound event classification (SEC) field, prompting an open question of whether these advancements can be extended to develop general-purpose SELD models. In this paper, leveraging the power of pre-trained SEC models, we propose pre-trained SELD networks (PSELDNets) on large-scale synthetic datasets. These synthetic datasets, generated by convolving sound events with simulated spatial room impulse responses (SRIRs), contain 1,167 hours of audio clips with an ontology of 170 sound classes. These PSELDNets are transferred to downstream SELD tasks. When we adapt PSELDNets to specific scenarios, particularly in low-resource data cases, we introduce a data-efficient fine-tuning method, AdapterBit. PSELDNets are evaluated on a synthetic-test-set using collected SRIRs from TAU Spatial Room Impulse Response Database (TAU-SRIR DB) and achieve satisfactory performance. We also conduct our experiments to validate the transferability of PSELDNets to three publicly available datasets and our own collected audio recordings. Results demonstrate that PSELDNets surpass state-of-the-art systems across all publicly available datasets. Given the need for direction-of-arrival estimation, SELD generally relies on sufficient multi-channel audio clips. However, incorporating the AdapterBit, PSELDNets show more efficient adaptability to various tasks using minimal multi-channel or even just monophonic audio clips, outperforming the traditional fine-tuning approaches.
Squeeze-and-Excite ResNet-Conformers for Sound Event Localization, Detection, and Distance Estimation for DCASE 2024 Challenge
Jul 12, 2024



This technical report details our systems submitted for Task 3 of the DCASE 2024 Challenge: Audio and Audiovisual Sound Event Localization and Detection (SELD) with Source Distance Estimation (SDE). We address only the audio-only SELD with SDE (SELDDE) task in this report. We propose to improve the existing ResNet-Conformer architectures with Squeeze-and-Excitation blocks in order to introduce additional forms of channel- and spatial-wise attention. In order to improve SELD performance, we also utilize the Spatial Cue-Augmented Log-Spectrogram (SALSA) features over the commonly used log-mel spectra features for polyphonic SELD. We complement the existing Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23) dataset with the audio channel swapping technique and synthesize additional data using the SpatialScaper generator. We also perform distance scaling in order to prevent large distance errors from contributing more towards the loss function. Finally, we evaluate our approach on the evaluation subset of the STARSS23 dataset.
Sound Event Detection and Localization with Distance Estimation
Mar 18, 2024



Sound Event Detection and Localization (SELD) is a combined task of identifying sound events and their corresponding direction-of-arrival (DOA). While this task has numerous applications and has been extensively researched in recent years, it fails to provide full information about the sound source position. In this paper, we overcome this problem by extending the task to Sound Event Detection, Localization with Distance Estimation (3D SELD). We study two ways of integrating distance estimation within the SELD core - a multi-task approach, in which the problem is tackled by a separate model output, and a single-task approach obtained by extending the multi-ACCDOA method to include distance information. We investigate both methods for the Ambisonic and binaural versions of STARSS23: Sony-TAU Realistic Spatial Soundscapes 2023. Moreover, our study involves experiments on the loss function related to the distance estimation part. Our results show that it is possible to perform 3D SELD without any degradation of performance in sound event detection and DOA estimation.
Selective-Memory Meta-Learning with Environment Representations for Sound Event Localization and Detection
Dec 27, 2023Environment shifts and conflicts present significant challenges for learning-based sound event localization and detection (SELD) methods. SELD systems, when trained in particular acoustic settings, often show restricted generalization capabilities for diverse acoustic environments. Furthermore, it is notably costly to obtain annotated samples for spatial sound events. Deploying a SELD system in a new environment requires extensive time for re-training and fine-tuning. To overcome these challenges, we propose environment-adaptive Meta-SELD, designed for efficient adaptation to new environments using minimal data. Our method specifically utilizes computationally synthesized spatial data and employs Model-Agnostic Meta-Learning (MAML) on a pre-trained, environment-independent model. The method then utilizes fast adaptation to unseen real-world environments using limited samples from the respective environments. Inspired by the Learning-to-Forget approach, we introduce the concept of selective memory as a strategy for resolving conflicts across environments. This approach involves selectively memorizing target-environment-relevant information and adapting to the new environments through the selective attenuation of model parameters. In addition, we introduce environment representations to characterize different acoustic settings, enhancing the adaptability of our attenuation approach to various environments. We evaluate our proposed method on the development set of the Sony-TAU Realistic Spatial Soundscapes 2023 (STARSS23) dataset and computationally synthesized scenes. Experimental results demonstrate the superior performance of the proposed method compared to conventional supervised learning methods, particularly in localization.
STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events
Jun 15, 2023



While direction of arrival (DOA) of sound events is generally estimated from multichannel audio data recorded in a microphone array, sound events usually derive from visually perceptible source objects, e.g., sounds of footsteps come from the feet of a walker. This paper proposes an audio-visual sound event localization and detection (SELD) task, which uses multichannel audio and video information to estimate the temporal activation and DOA of target sound events. Audio-visual SELD systems can detect and localize sound events using signals from a microphone array and audio-visual correspondence. We also introduce an audio-visual dataset, Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23), which consists of multichannel audio data recorded with a microphone array, video data, and spatiotemporal annotation of sound events. Sound scenes in STARSS23 are recorded with instructions, which guide recording participants to ensure adequate activity and occurrences of sound events. STARSS23 also serves human-annotated temporal activation labels and human-confirmed DOA labels, which are based on tracking results of a motion capture system. Our benchmark results show that the audio-visual SELD system achieves lower localization error than the audio-only system. The data is available at https://zenodo.org/record/7880637.
Improving trajectory localization accuracy via direction-of-arrival derivative estimation
Dec 10, 2022Sound source localization is crucial in acoustic sensing and monitoring-related applications. In this paper, we do a comprehensive analysis of improvement in sound source localization by combining the direction of arrivals (DOAs) with their derivatives which quantify the changes in the positions of sources over time. This study uses the SALSA-Lite feature with a convolutional recurrent neural network (CRNN) model for predicting DOAs and their first-order derivatives. An update rule is introduced to combine the predicted DOAs with the estimated derivatives to obtain the final DOAs. The experimental validation is done using TAU-NIGENS Spatial Sound Events (TNSSE) 2021 dataset. We compare the performance of the networks predicting DOAs with derivative vs. the one predicting only the DOAs at low SNR levels. The results show that combining the derivatives with the DOAs improves the localization accuracy of moving sources.
META-SELD: Meta-Learning for Fast Adaptation to the new environment in Sound Event Localization and Detection
Aug 17, 2023


For learning-based sound event localization and detection (SELD) methods, different acoustic environments in the training and test sets may result in large performance differences in the validation and evaluation stages. Different environments, such as different sizes of rooms, different reverberation times, and different background noise, may be reasons for a learning-based system to fail. On the other hand, acquiring annotated spatial sound event samples, which include onset and offset time stamps, class types of sound events, and direction-of-arrival (DOA) of sound sources is very expensive. In addition, deploying a SELD system in a new environment often poses challenges due to time-consuming training and fine-tuning processes. To address these issues, we propose Meta-SELD, which applies meta-learning methods to achieve fast adaptation to new environments. More specifically, based on Model Agnostic Meta-Learning (MAML), the proposed Meta-SELD aims to find good meta-initialized parameters to adapt to new environments with only a small number of samples and parameter updating iterations. We can then quickly adapt the meta-trained SELD model to unseen environments. Our experiments compare fine-tuning methods from pre-trained SELD models with our Meta-SELD on the Sony-TAU Realistic Spatial Soundscapes 2023 (STARSSS23) dataset. The evaluation results demonstrate the effectiveness of Meta-SELD when adapting to new environments.
Dynamic Kernel Convolution Network with Scene-dedicate Training for Sound Event Localization and Detection
Jul 17, 2023



DNN-based methods have shown high performance in sound event localization and detection(SELD). While in real spatial sound scenes, reverberation and the imbalanced presence of various sound events increase the complexity of the SELD task. In this paper, we propose an effective SELD system in real spatial scenes.In our approach, a dynamic kernel convolution module is introduced after the convolution blocks to adaptively model the channel-wise features with different receptive fields. Secondly, we incorporate the SELDnet and EINv2 framework into the proposed SELD system with multi-track ACCDOA. Moreover, two scene-dedicated strategies are introduced into the training stage to improve the generalization of the system in realistic spatial sound scenes. Finally, we apply data augmentation methods to extend the dataset using channel rotation, spatial data synthesis. Four joint metrics are used to evaluate the performance of the SELD system on the Sony-TAu Realistic Spatial Soundscapes 2022 dataset.Experimental results show that the proposed systems outperform the fixed-kernel convolution SELD systems. In addition, the proposed system achieved an SELD score of 0.348 in the DCASE SELD task and surpassed the SOTA methods.
STARSS22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events
Jun 04, 2022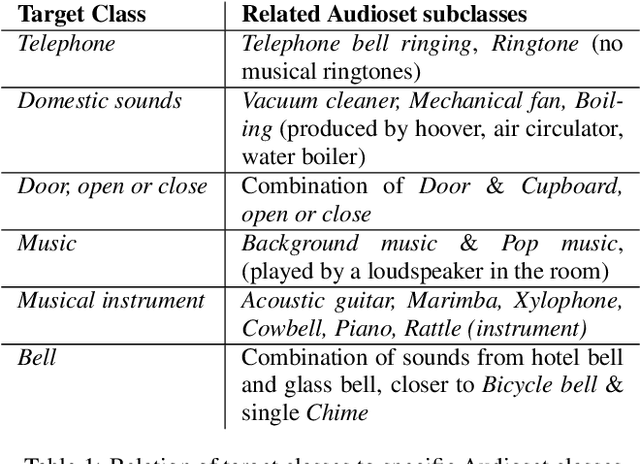
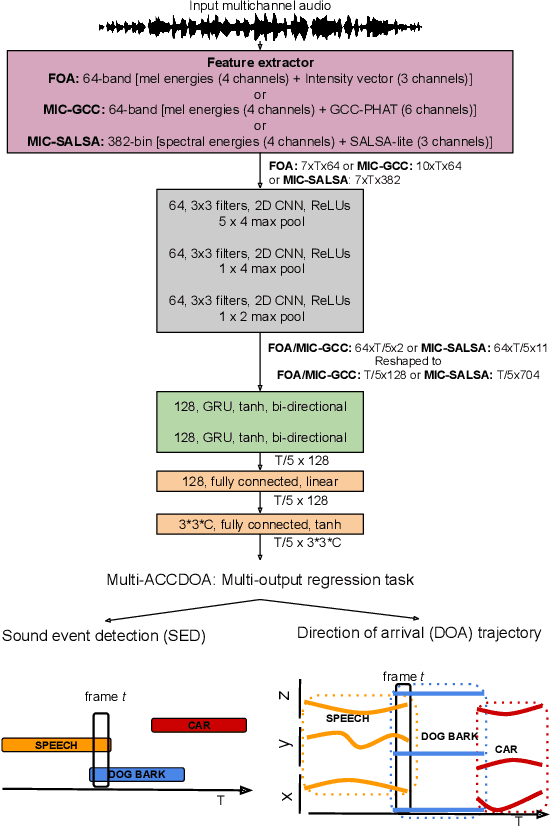
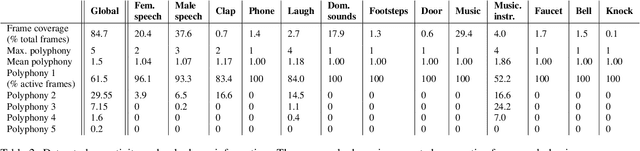

This report presents the Sony-TAu Realistic Spatial Soundscapes 2022 (STARS22) dataset for sound event localization and detection, comprised of spatial recordings of real scenes collected in various interiors of two different sites. The dataset is captured with a high resolution spherical microphone array and delivered in two 4-channel formats, first-order Ambisonics and tetrahedral microphone array. Sound events in the dataset belonging to 13 target sound classes are annotated both temporally and spatially through a combination of human annotation and optical tracking. The dataset serves as the development and evaluation dataset for the Task 3 of the DCASE2022 Challenge on Sound Event Localization and Detection and introduces significant new challenges for the task compared to the previous iterations, which were based on synthetic spatialized sound scene recordings. Dataset specifications are detailed including recording and annotation process, target classes and their presence, and details on the development and evaluation splits. Additionally, the report presents the baseline system that accompanies the dataset in the challenge with emphasis on the differences with the baseline of the previous iterations; namely, introduction of the multi-ACCDOA representation to handle multiple simultaneous occurences of events of the same class, and support for additional improved input features for the microphone array format. Results of the baseline indicate that with a suitable training strategy a reasonable detection and localization performance can be achieved on real sound scene recordings. The dataset is available in https://zenodo.org/record/6387880.