 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning for Semantic Alignment of Language, Audio, and Visual Modalities
May 20, 2025This paper proposes a single-stage training approach that semantically aligns three modalities - audio, visual, and text using a contrastive learning framework. Contrastive training has gained prominence for multimodal alignment, utilizing large-scale unlabeled data to learn shared representations. Existing deep learning approach for trimodal alignment involves two-stages, that separately align visual-text and audio-text modalities. This approach suffers from mismatched data distributions, resulting in suboptimal alignment. Leveraging the AVCaps dataset, which provides audio, visual and audio-visual captions for video clips, our method jointly optimizes the representation of all the modalities using contrastive training. Our results demonstrate that the single-stage approach outperforms the two-stage method, achieving a two-fold improvement in audio based visual retrieval, highlighting the advantages of unified multimodal representation learning.
STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events
Jun 15, 2023



While direction of arrival (DOA) of sound events is generally estimated from multichannel audio data recorded in a microphone array, sound events usually derive from visually perceptible source objects, e.g., sounds of footsteps come from the feet of a walker. This paper proposes an audio-visual sound event localization and detection (SELD) task, which uses multichannel audio and video information to estimate the temporal activation and DOA of target sound events. Audio-visual SELD systems can detect and localize sound events using signals from a microphone array and audio-visual correspondence. We also introduce an audio-visual dataset, Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23), which consists of multichannel audio data recorded with a microphone array, video data, and spatiotemporal annotation of sound events. Sound scenes in STARSS23 are recorded with instructions, which guide recording participants to ensure adequate activity and occurrences of sound events. STARSS23 also serves human-annotated temporal activation labels and human-confirmed DOA labels, which are based on tracking results of a motion capture system. Our benchmark results show that the audio-visual SELD system achieves lower localization error than the audio-only system. The data is available at https://zenodo.org/record/7880637.
Attention-Based Methods For Audio Question Answering
May 31, 2023



Audio question answering (AQA) is the task of producing natural language answers when a system is provided with audio and natural language questions. In this paper, we propose neural network architectures based on self-attention and cross-attention for the AQA task. The self-attention layers extract powerful audio and textual representations. The cross-attention maps audio features that are relevant to the textual features to produce answers. All our models are trained on the recently proposed Clotho-AQA dataset for both binary yes/no questions and single-word answer questions. Our results clearly show improvement over the reference method reported in the original paper. On the yes/no binary classification task, our proposed model achieves an accuracy of 68.3% compared to 62.7% in the reference model. For the single-word answers multiclass classifier, our model produces a top-1 and top-5 accuracy of 57.9% and 99.8% compared to 54.2% and 93.7% in the reference model respectively. We further discuss some of the challenges in the Clotho-AQA dataset such as the presence of the same answer word in multiple tenses, singular and plural forms, and the presence of specific and generic answers to the same question. We address these issues and present a revised version of the dataset.
STARSS22: A dataset of spatial recordings of real scenes with spatiotemporal annotations of sound events
Jun 04, 2022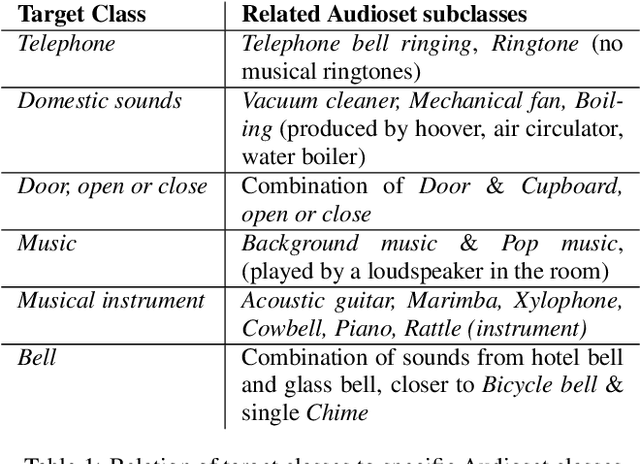
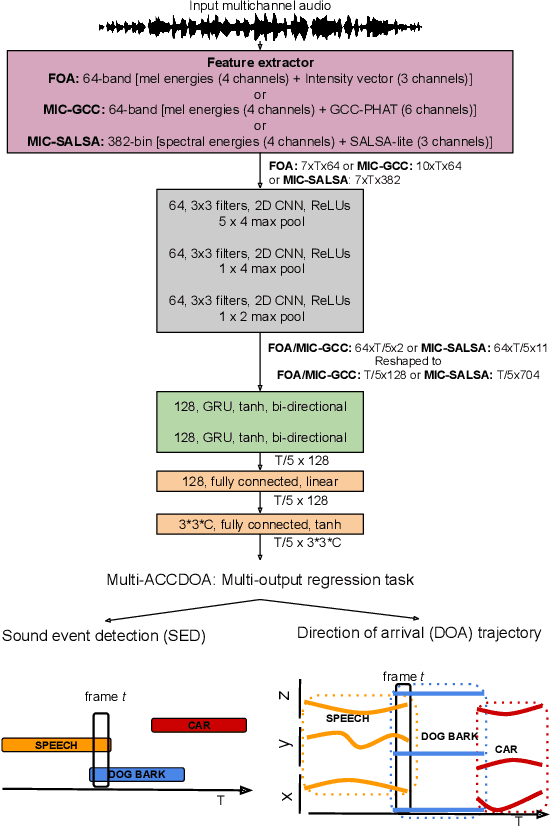
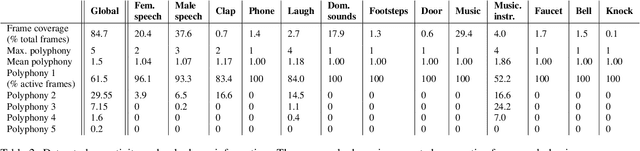

This report presents the Sony-TAu Realistic Spatial Soundscapes 2022 (STARS22) dataset for sound event localization and detection, comprised of spatial recordings of real scenes collected in various interiors of two different sites. The dataset is captured with a high resolution spherical microphone array and delivered in two 4-channel formats, first-order Ambisonics and tetrahedral microphone array. Sound events in the dataset belonging to 13 target sound classes are annotated both temporally and spatially through a combination of human annotation and optical tracking. The dataset serves as the development and evaluation dataset for the Task 3 of the DCASE2022 Challenge on Sound Event Localization and Detection and introduces significant new challenges for the task compared to the previous iterations, which were based on synthetic spatialized sound scene recordings. Dataset specifications are detailed including recording and annotation process, target classes and their presence, and details on the development and evaluation splits. Additionally, the report presents the baseline system that accompanies the dataset in the challenge with emphasis on the differences with the baseline of the previous iterations; namely, introduction of the multi-ACCDOA representation to handle multiple simultaneous occurences of events of the same class, and support for additional improved input features for the microphone array format. Results of the baseline indicate that with a suitable training strategy a reasonable detection and localization performance can be achieved on real sound scene recordings. The dataset is available in https://zenodo.org/record/6387880.
Clotho-AQA: A Crowdsourced Dataset for Audio Question Answering
Apr 20, 2022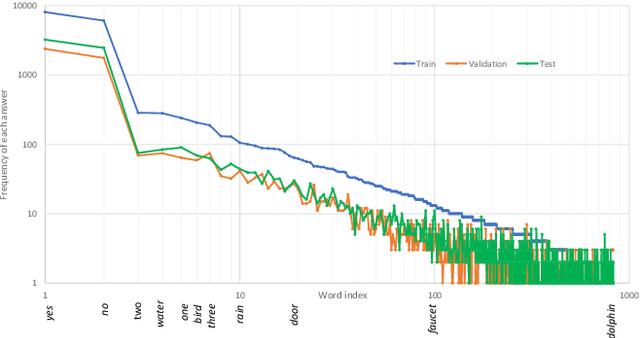
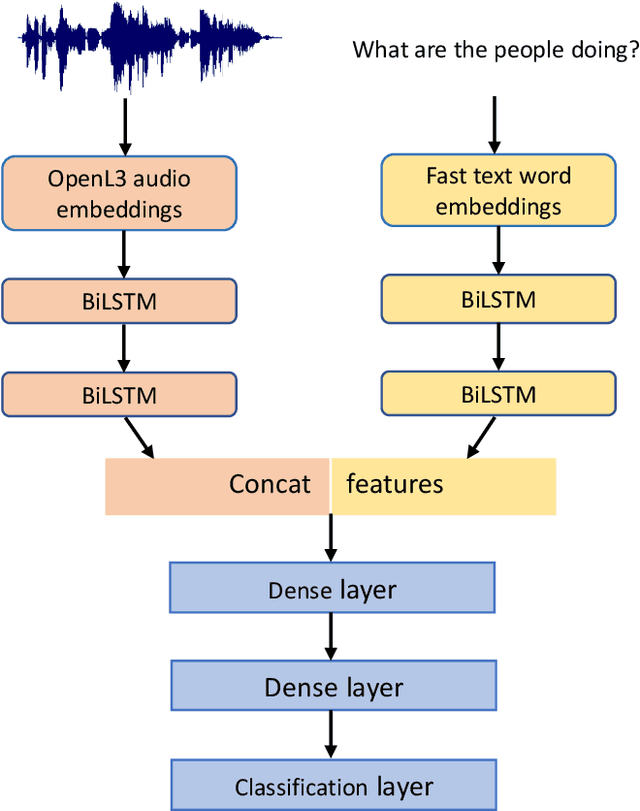
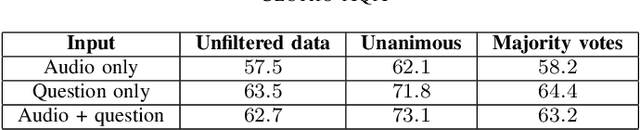

Audio question answering (AQA) is a multimodal translation task where a system analyzes an audio signal and a natural language question, to generate a desirable natural language answer. In this paper, we introduce Clotho-AQA, a dataset for Audio question answering consisting of 1991 audio files each between 15 to 30 seconds in duration selected from the Clotho dataset [1]. For each audio file, we collect six different questions and corresponding answers by crowdsourcing using Amazon Mechanical Turk. The questions and answers are produced by different annotators. Out of the six questions for each audio, two questions each are designed to have 'yes' and 'no' as answers, while the remaining two questions have other single-word answers. For each question, we collect answers from three different annotators. We also present two baseline experiments to describe the usage of our dataset for the AQA task - an LSTM-based multimodal binary classifier for 'yes' or 'no' type answers and an LSTM-based multimodal multi-class classifier for 828 single-word answers. The binary classifier achieved an accuracy of 62.7% and the multi-class classifier achieved a top-1 accuracy of 54.2% and a top-5 accuracy of 93.7%. Clotho-AQA dataset is freely available online at https://zenodo.org/record/6473207.
Assessment of Self-Attention on Learned Features For Sound Event Localization and Detection
Jul 20, 2021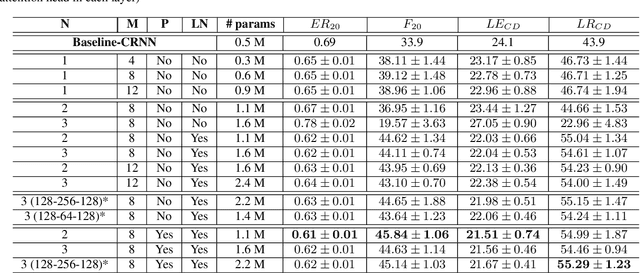
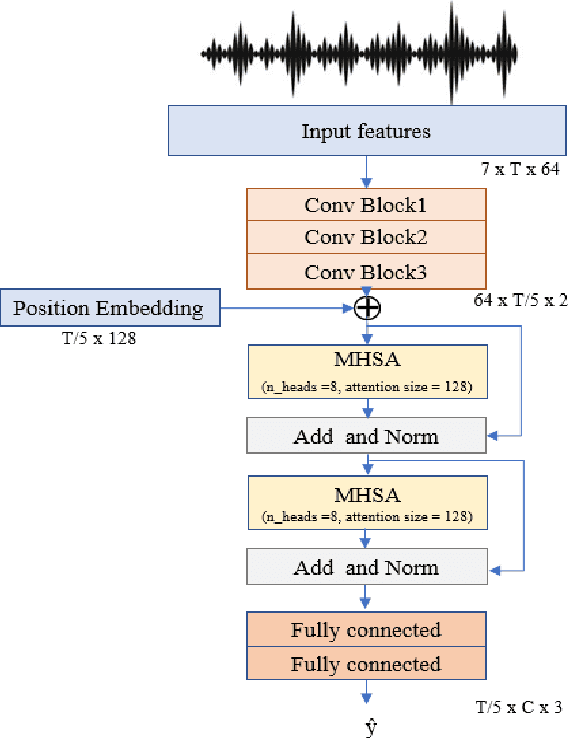
Joint sound event localization and detection (SELD) is an emerging audio signal processing task adding spatial dimensions to acoustic scene analysis and sound event detection. A popular approach to modeling SELD jointly is using convolutional recurrent neural network (CRNN) models, where CNNs learn high-level features from multi-channel audio input and the RNNs learn temporal relationships from these high-level features. However, RNNs have some drawbacks, such as a limited capability to model long temporal dependencies and slow training and inference times due to their sequential processing nature. Recently, a few SELD studies used multi-head self-attention (MHSA), among other innovations in their models. MHSA and the related transformer networks have shown state-of-the-art performance in various domains. While they can model long temporal dependencies, they can also be parallelized efficiently. In this paper, we study in detail the effect of MHSA on the SELD task. Specifically, we examined the effects of replacing the RNN blocks with self-attention layers. We studied the influence of stacking multiple self-attention blocks, using multiple attention heads in each self-attention block, and the effect of position embeddings and layer normalization. Evaluation on the DCASE 2021 SELD (task 3) development data set shows a significant improvement in all employed metrics compared to the baseline CRNN accompanying the task.
Improving Voice Separation by Incorporating End-to-end Speech Recognition
Nov 29, 2019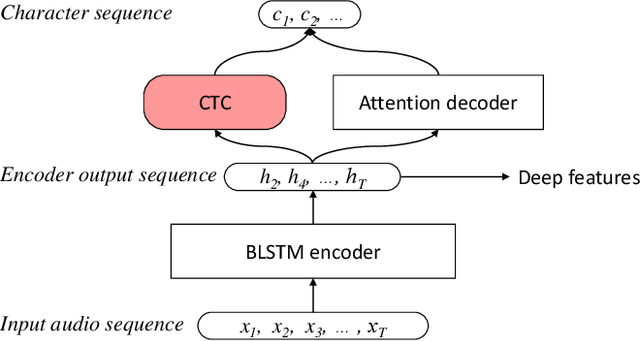
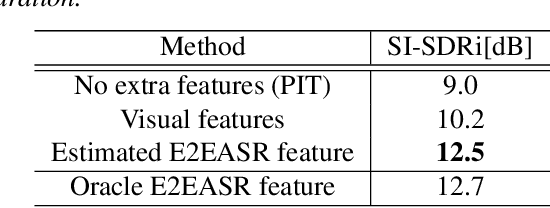
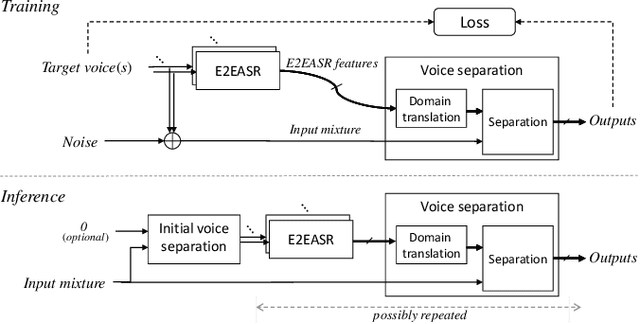

Despite recent advances in voice separation methods, many challenges remain in realistic scenarios such as noisy recording and the limits of available data. In this work, we propose to explicitly incorporate the phonetic and linguistic nature of speech by taking a transfer learning approach using an end-to-end automatic speech recognition (E2EASR) system. The voice separation is conditioned on deep features extracted from E2EASR to cover the long-term dependence of phonetic aspects. Experimental results on speech separation and enhancement task on the AVSpeech dataset show that the proposed method significantly improves the signal-to-distortion ratio over the baseline model and even outperforms an audio visual model, that utilizes visual information of lip movements.