 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese U Net
Papers and Code
Deep Learning-Based Burned Area Mapping Using Bi-Temporal Siamese Networks and AlphaEarth Foundation Datasets
Sep 09, 2025Accurate and timely mapping of burned areas is crucial for environmental monitoring, disaster management, and assessment of climate change. This study presents a novel approach to automated burned area mapping using the AlphaEArth dataset combined with the Siamese U-Net deep learning architecture. The AlphaEArth Dataset, comprising high-resolution optical and thermal infrared imagery with comprehensive ground-truth annotations, provides an unprecedented resource for training robust burned area detection models. We trained our model with the Monitoring Trends in Burn Severity (MTBS) dataset in the contiguous US and evaluated it with 17 regions cross in Europe. Our experimental results demonstrate that the proposed ensemble approach achieves superior performance with an overall accuracy of 95%, IoU of 0.6, and F1-score of 74% on the test dataset. The model successfully identifies burned areas across diverse ecosystems with complex background, showing particular strength in detecting partially burned vegetation and fire boundaries and its transferability and high generalization in burned area mapping. This research contributes to the advancement of automated fire damage assessment and provides a scalable solution for global burn area monitoring using the AlphaEarth dataset.
Barlow-Swin: Toward a novel siamese-based segmentation architecture using Swin-Transformers
Sep 08, 2025Medical image segmentation is a critical task in clinical workflows, particularly for the detection and delineation of pathological regions. While convolutional architectures like U-Net have become standard for such tasks, their limited receptive field restricts global context modeling. Recent efforts integrating transformers have addressed this, but often result in deep, computationally expensive models unsuitable for real-time use. In this work, we present a novel end-to-end lightweight architecture designed specifically for real-time binary medical image segmentation. Our model combines a Swin Transformer-like encoder with a U-Net-like decoder, connected via skip pathways to preserve spatial detail while capturing contextual information. Unlike existing designs such as Swin Transformer or U-Net, our architecture is significantly shallower and competitively efficient. To improve the encoder's ability to learn meaningful features without relying on large amounts of labeled data, we first train it using Barlow Twins, a self-supervised learning method that helps the model focus on important patterns by reducing unnecessary repetition in the learned features. After this pretraining, we fine-tune the entire model for our specific task. Experiments on benchmark binary segmentation tasks demonstrate that our model achieves competitive accuracy with substantially reduced parameter count and faster inference, positioning it as a practical alternative for deployment in real-time and resource-limited clinical environments. The code for our method is available at Github repository: https://github.com/mkianih/Barlow-Swin.
MultiTaskDeltaNet: Change Detection-based Image Segmentation for Operando ETEM with Application to Carbon Gasification Kinetics
Jul 22, 2025



Transforming in-situ transmission electron microscopy (TEM) imaging into a tool for spatially-resolved operando characterization of solid-state reactions requires automated, high-precision semantic segmentation of dynamically evolving features. However, traditional deep learning methods for semantic segmentation often encounter limitations due to the scarcity of labeled data, visually ambiguous features of interest, and small-object scenarios. To tackle these challenges, we introduce MultiTaskDeltaNet (MTDN), a novel deep learning architecture that creatively reconceptualizes the segmentation task as a change detection problem. By implementing a unique Siamese network with a U-Net backbone and using paired images to capture feature changes, MTDN effectively utilizes minimal data to produce high-quality segmentations. Furthermore, MTDN utilizes a multi-task learning strategy to leverage correlations between physical features of interest. In an evaluation using data from in-situ environmental TEM (ETEM) videos of filamentous carbon gasification, MTDN demonstrated a significant advantage over conventional segmentation models, particularly in accurately delineating fine structural features. Notably, MTDN achieved a 10.22% performance improvement over conventional segmentation models in predicting small and visually ambiguous physical features. This work bridges several key gaps between deep learning and practical TEM image analysis, advancing automated characterization of nanomaterials in complex experimental settings.
A Comparative Study of U-Net Architectures for Change Detection in Satellite Images
Jun 09, 2025



Remote sensing change detection is essential for monitoring the everchanging landscapes of the Earth. The U-Net architecture has gained popularity for its capability to capture spatial information and perform pixel-wise classification. However, their application in the Remote sensing field remains largely unexplored. Therefore, this paper fill the gap by conducting a comprehensive analysis of 34 papers. This study conducts a comparison and analysis of 18 different U-Net variations, assessing their potential for detecting changes in remote sensing. We evaluate both benefits along with drawbacks of each variation within the framework of this particular application. We emphasize variations that are explicitly built for change detection, such as Siamese Swin-U-Net, which utilizes a Siamese architecture. The analysis highlights the significance of aspects such as managing data from different time periods and collecting relationships over a long distance to enhance the precision of change detection. This study provides valuable insights for researchers and practitioners that choose U-Net versions for remote sensing change detection tasks.
Npix2Cpix: A GAN-based Image-to-Image Translation Network with Retrieval-Classification Integration for Watermark Retrieval from Historical Document Images
Jun 05, 2024



The identification and restoration of ancient watermarks have long been a major topic in codicology and history. Classifying historical documents based on watermarks can be difficult due to the diversity of watermarks, crowded and noisy samples, multiple modes of representation, and minor distinctions between classes and intra-class changes. This paper proposes a U-net-based conditional generative adversarial network (GAN) to translate noisy raw historical watermarked images into clean, handwriting-free images with just watermarks. Considering its ability to perform image translation from degraded (noisy) pixels to clean pixels, the proposed network is termed as Npix2Cpix. Instead of employing directly degraded watermarked images, the proposed network uses image-to-image translation using adversarial learning to create clutter and handwriting-free images for restoring and categorizing the watermarks for the first time. In order to learn the mapping from input noisy image to output clean image, the generator and discriminator of the proposed U-net-based GAN are trained using two separate loss functions, each of which is based on the distance between images. After using the proposed GAN to pre-process noisy watermarked images, Siamese-based one-shot learning is used to classify watermarks. According to experimental results on a large-scale historical watermark dataset, extracting watermarks from tainted images can result in high one-shot classification accuracy. The qualitative and quantitative evaluation of the retrieved watermarks illustrates the effectiveness of the proposed approach.
Separate and Reconstruct: Asymmetric Encoder-Decoder for Speech Separation
Jun 10, 2024Since the success of a time-domain speech separation, further improvements have been made by expanding the length and channel of a feature sequence to increase the amount of computation. When temporally expanded to a long sequence, the feature is segmented into chunks as a dual-path model in most studies of speech separation. In particular, it is common for the process of separating features corresponding to each speaker to be located in the final stage of the network. However, it is more advantageous and intuitive to proactively expand the feature sequence to include the number of speakers as an extra dimension. In this paper, we present an asymmetric strategy in which the encoder and decoder are partitioned to perform distinct processing in separation tasks. The encoder analyzes features, and the output of the encoder is split into the number of speakers to be separated. The separated sequences are then reconstructed by the weight-shared decoder, as Siamese network, in addition to cross-speaker processing. By using the Siamese network in the decoder, without using speaker information, the network directly learns to discriminate the features using a separation objective. With a common split layer, intermediate encoder features for skip connections are also split for the reconstruction decoder based on the U-Net structure. In addition, instead of segmenting the feature into chunks as dual-path, we design global and local Transformer blocks to directly process long sequences. The experimental results demonstrated that this separation-and-reconstruction framework is effective and that the combination of proposed global and local Transformer can sufficiently replace the role of inter- and intra-chunk processing in dual-path structure. Finally, the presented model including both of these achieved state-of-the-art performance with less computation than before in various benchmark datasets.
AB2CD: AI for Building Climate Damage Classification and Detection
Sep 03, 2023We explore the implementation of deep learning techniques for precise building damage assessment in the context of natural hazards, utilizing remote sensing data. The xBD dataset, comprising diverse disaster events from across the globe, serves as the primary focus, facilitating the evaluation of deep learning models. We tackle the challenges of generalization to novel disasters and regions while accounting for the influence of low-quality and noisy labels inherent in natural hazard data. Furthermore, our investigation quantitatively establishes that the minimum satellite imagery resolution essential for effective building damage detection is 3 meters and below 1 meter for classification using symmetric and asymmetric resolution perturbation analyses. To achieve robust and accurate evaluations of building damage detection and classification, we evaluated different deep learning models with residual, squeeze and excitation, and dual path network backbones, as well as ensemble techniques. Overall, the U-Net Siamese network ensemble with F-1 score of 0.812 performed the best against the xView2 challenge benchmark. Additionally, we evaluate a Universal model trained on all hazards against a flood expert model and investigate generalization gaps across events, and out of distribution from field data in the Ahr Valley. Our research findings showcase the potential and limitations of advanced AI solutions in enhancing the impact assessment of climate change-induced extreme weather events, such as floods and hurricanes. These insights have implications for disaster impact assessment in the face of escalating climate challenges.
Attentive Dual Stream Siamese U-net for Flood Detection on Multi-temporal Sentinel-1 Data
Apr 20, 2022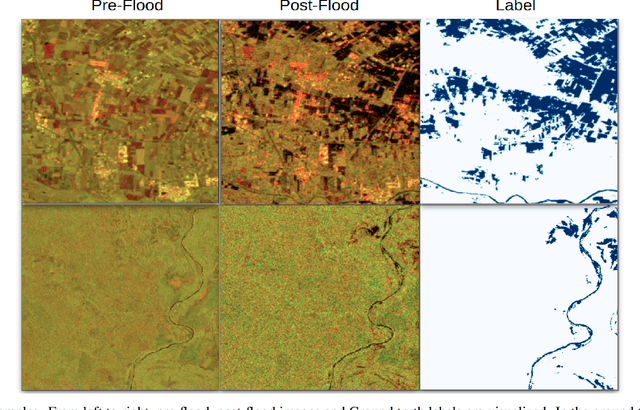

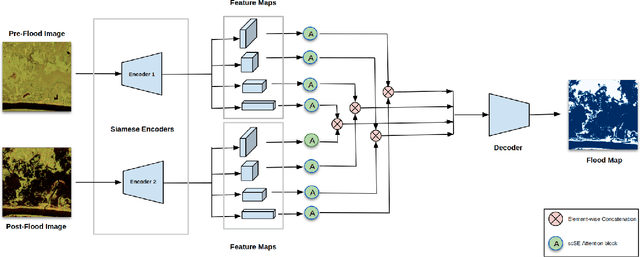

Due to climate and land-use change, natural disasters such as flooding have been increasing in recent years. Timely and reliable flood detection and mapping can help emergency response and disaster management. In this work, we propose a flood detection network using bi-temporal SAR acquisitions. The proposed segmentation network has an encoder-decoder architecture with two Siamese encoders for pre and post-flood images. The network's feature maps are fused and enhanced using attention blocks to achieve more accurate detection of the flooded areas. Our proposed network is evaluated on publicly available Sen1Flood11 benchmark dataset. The network outperformed the existing state-of-the-art (uni-temporal) flood detection method by 6\% IOU. The experiments highlight that the combination of bi-temporal SAR data with an effective network architecture achieves more accurate flood detection than uni-temporal methods.
PCRLv2: A Unified Visual Information Preservation Framework for Self-supervised Pre-training in Medical Image Analysis
Jan 02, 2023Recent advances in self-supervised learning (SSL) in computer vision are primarily comparative, whose goal is to preserve invariant and discriminative semantics in latent representations by comparing siamese image views. However, the preserved high-level semantics do not contain enough local information, which is vital in medical image analysis (e.g., image-based diagnosis and tumor segmentation). To mitigate the locality problem of comparative SSL, we propose to incorporate the task of pixel restoration for explicitly encoding more pixel-level information into high-level semantics. We also address the preservation of scale information, a powerful tool in aiding image understanding but has not drawn much attention in SSL. The resulting framework can be formulated as a multi-task optimization problem on the feature pyramid. Specifically, we conduct multi-scale pixel restoration and siamese feature comparison in the pyramid. In addition, we propose non-skip U-Net to build the feature pyramid and develop sub-crop to replace multi-crop in 3D medical imaging. The proposed unified SSL framework (PCRLv2) surpasses its self-supervised counterparts on various tasks, including brain tumor segmentation (BraTS 2018), chest pathology identification (ChestX-ray, CheXpert), pulmonary nodule detection (LUNA), and abdominal organ segmentation (LiTS), sometimes outperforming them by large margins with limited annotations.
A Dense Siamese U-Net trained with Edge Enhanced 3D IOU Loss for Image Co-segmentation
Aug 17, 2021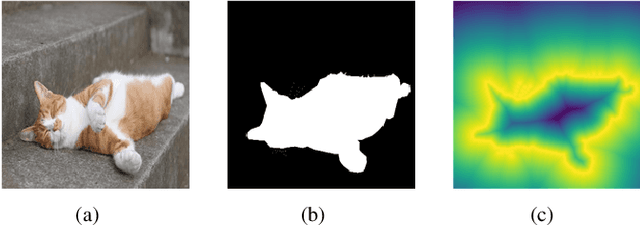
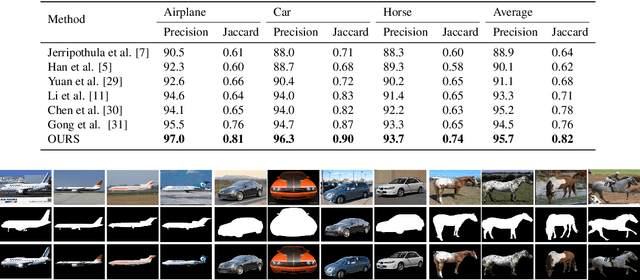
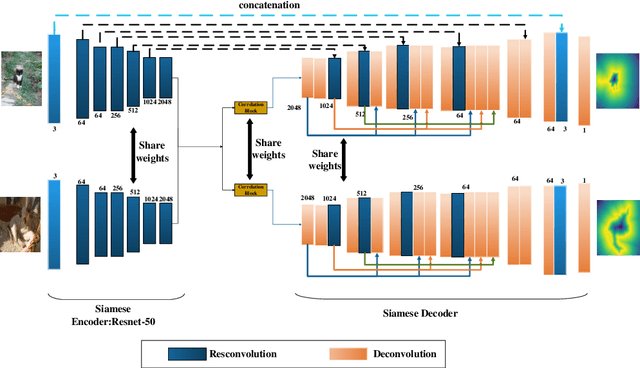
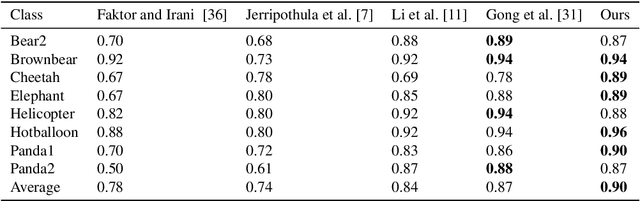
Image co-segmentation has attracted a lot of attentions in computer vision community. In this paper, we propose a new approach to image co-segmentation through introducing the dense connections into the decoder path of Siamese U-net and presenting a new edge enhanced 3D IOU loss measured over distance maps. Considering the rigorous mapping between the signed normalized distance map (SNDM) and the binary segmentation mask, we estimate the SNDMs directly from original images and use them to determine the segmentation results. We apply the Siamese U-net for solving this problem and improve its effectiveness by densely connecting each layer with subsequent layers in the decoder path. Furthermore, a new learning loss is designed to measure the 3D intersection over union (IOU) between the generated SNDMs and the labeled SNDMs. The experimental results on commonly used datasets for image co-segmentation demonstrate the effectiveness of our presented dense structure and edge enhanced 3D IOU loss of SNDM. To our best knowledge, they lead to the state-of-the-art performance on the Internet and iCoseg datasets.