 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese Network
Papers and Code
Self-Supervised Learning with a Multi-Task Latent Space Objective
Feb 05, 2026Self-supervised learning (SSL) methods based on Siamese networks learn visual representations by aligning different views of the same image. The multi-crop strategy, which incorporates small local crops to global ones, enhances many SSL frameworks but causes instability in predictor-based architectures such as BYOL, SimSiam, and MoCo v3. We trace this failure to the shared predictor used across all views and demonstrate that assigning a separate predictor to each view type stabilizes multi-crop training, resulting in significant performance gains. Extending this idea, we treat each spatial transformation as a distinct alignment task and add cutout views, where part of the image is masked before encoding. This yields a simple multi-task formulation of asymmetric Siamese SSL that combines global, local, and masked views into a single framework. The approach is stable, generally applicable across backbones, and consistently improves the performance of ResNet and ViT models on ImageNet.
EoCD: Encoder only Remote Sensing Change Detection
Feb 05, 2026Being a cornerstone of temporal analysis, change detection has been playing a pivotal role in modern earth observation. Existing change detection methods rely on the Siamese encoder to individually extract temporal features followed by temporal fusion. Subsequently, these methods design sophisticated decoders to improve the change detection performance without taking into consideration the complexity of the model. These aforementioned issues intensify the overall computational cost as well as the network's complexity which is undesirable. Alternatively, few methods utilize the early fusion scheme to combine the temporal images. These methods prevent the extra overhead of Siamese encoder, however, they also rely on sophisticated decoders for better performance. In addition, these methods demonstrate inferior performance as compared to late fusion based methods. To bridge these gaps, we introduce encoder only change detection (EoCD) that is a simple and effective method for the change detection task. The proposed method performs the early fusion of the temporal data and replaces the decoder with a parameter-free multiscale feature fusion module thereby significantly reducing the overall complexity of the model. EoCD demonstrate the optimal balance between the change detection performance and the prediction speed across a variety of encoder architectures. Additionally, EoCD demonstrate that the performance of the model is predominantly dependent on the encoder network, making the decoder an additional component. Extensive experimentation on four challenging change detection datasets reveals the effectiveness of the proposed method.
Auto-Augmentation Contrastive Learning for Wearable-based Human Activity Recognition
Jan 30, 2026For low-semantic sensor signals from human activity recognition (HAR), contrastive learning (CL) is essential to implement novel applications or generic models without manual annotation, which is a high-performance self-supervised learning (SSL) method. However, CL relies heavily on data augmentation for pairwise comparisons. Especially for low semantic data in the HAR area, conducting good performance augmentation strategies in pretext tasks still rely on manual attempts lacking generalizability and flexibility. To reduce the augmentation burden, we propose an end-to-end auto-augmentation contrastive learning (AutoCL) method for wearable-based HAR. AutoCL is based on a Siamese network architecture that shares the parameters of the backbone and with a generator embedded to learn auto-augmentation. AutoCL trains the generator based on the representation in the latent space to overcome the disturbances caused by noise and redundant information in raw sensor data. The architecture empirical study indicates the effectiveness of this design. Furthermore, we propose a stop-gradient design and correlation reduction strategy in AutoCL to enhance encoder representation learning. Extensive experiments based on four wide-used HAR datasets demonstrate that the proposed AutoCL method significantly improves recognition accuracy compared with other SOTA methods.
Simple Network Graph Comparative Learning
Jan 15, 2026The effectiveness of contrastive learning methods has been widely recognized in the field of graph learning, especially in contexts where graph data often lack labels or are difficult to label. However, the application of these methods to node classification tasks still faces a number of challenges. First, existing data enhancement techniques may lead to significant differences from the original view when generating new views, which may weaken the relevance of the view and affect the efficiency of model training. Second, the vast majority of existing graph comparison learning algorithms rely on the use of a large number of negative samples. To address the above challenges, this study proposes a novel node classification contrast learning method called Simple Network Graph Comparative Learning (SNGCL). Specifically, SNGCL employs a superimposed multilayer Laplace smoothing filter as a step in processing the data to obtain global and local feature smoothing matrices, respectively, which are thus passed into the target and online networks of the siamese network, and finally employs an improved triple recombination loss function to bring the intra-class distance closer and the inter-class distance farther. We have compared SNGCL with state-of-the-art models in node classification tasks, and the experimental results show that SNGCL is strongly competitive in most tasks.
One-Shot Identification with Different Neural Network Approaches
Jan 13, 2026Convolutional neural networks (CNNs) have been widely used in the computer vision community, significantly improving the state-of-the-art. But learning good features often is computationally expensive in machine learning settings and is especially difficult when there is a lack of data. One-shot learning is one such area where only limited data is available. In one-shot learning, predictions have to be made after seeing only one example from one class, which requires special techniques. In this paper we explore different approaches to one-shot identification tasks in different domains including an industrial application and face recognition. We use a special technique with stacked images and use siamese capsule networks. It is encouraging to see that the approach using capsule architecture achieves strong results and exceeds other techniques on a wide range of datasets from industrial application to face recognition benchmarks while being easy to use and optimise.
* 18 pages, Keywords: One-shot learning, Convolutional neural networks, Siamese networks, Capsules, Industrial application
Multi-Sensor Matching with HyperNetworks
Jan 18, 2026Hypernetworks are models that generate or modulate the weights of another network. They provide a flexible mechanism for injecting context and task conditioning and have proven broadly useful across diverse applications without significant increases in model size. We leverage hypernetworks to improve multimodal patch matching by introducing a lightweight descriptor-learning architecture that augments a Siamese CNN with (i) hypernetwork modules that compute adaptive, per-channel scaling and shifting and (ii) conditional instance normalization that provides modality-specific adaptation (e.g., visible vs. infrared, VIS-IR) in shallow layers. This combination preserves the efficiency of descriptor-based methods during inference while increasing robustness to appearance shifts. Trained with a triplet loss and hard-negative mining, our approach achieves state-of-the-art results on VIS-NIR and other VIS-IR benchmarks and matches or surpasses prior methods on additional datasets, despite their higher inference cost. To spur progress on domain shift, we also release GAP-VIR, a cross-platform (ground/aerial) VIS-IR patch dataset with 500K pairs, enabling rigorous evaluation of cross-domain generalization and adaptation.
Automated User Identification from Facial Thermograms with Siamese Networks
Dec 15, 2025The article analyzes the use of thermal imaging technologies for biometric identification based on facial thermograms. It presents a comparative analysis of infrared spectral ranges (NIR, SWIR, MWIR, and LWIR). The paper also defines key requirements for thermal cameras used in biometric systems, including sensor resolution, thermal sensitivity, and a frame rate of at least 30 Hz. Siamese neural networks are proposed as an effective approach for automating the identification process. In experiments conducted on a proprietary dataset, the proposed method achieved an accuracy of approximately 80%. The study also examines the potential of hybrid systems that combine visible and infrared spectra to overcome the limitations of individual modalities. The results indicate that thermal imaging is a promising technology for developing reliable security systems.
Colormap-Enhanced Vision Transformers for MRI-Based Multiclass (4-Class) Alzheimer's Disease Classification
Dec 18, 2025
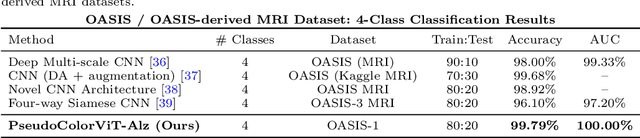
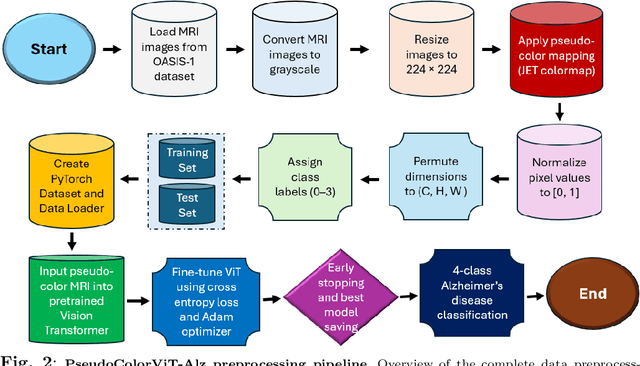
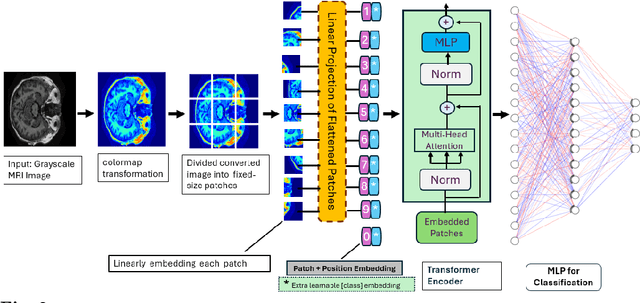
Magnetic Resonance Imaging (MRI) plays a pivotal role in the early diagnosis and monitoring of Alzheimer's disease (AD). However, the subtle structural variations in brain MRI scans often pose challenges for conventional deep learning models to extract discriminative features effectively. In this work, we propose PseudoColorViT-Alz, a colormap-enhanced Vision Transformer framework designed to leverage pseudo-color representations of MRI images for improved Alzheimer's disease classification. By combining colormap transformations with the global feature learning capabilities of Vision Transformers, our method amplifies anatomical texture and contrast cues that are otherwise subdued in standard grayscale MRI scans. We evaluate PseudoColorViT-Alz on the OASIS-1 dataset using a four-class classification setup (non-demented, moderate dementia, mild dementia, and very mild dementia). Our model achieves a state-of-the-art accuracy of 99.79% with an AUC of 100%, surpassing the performance of recent 2024--2025 methods, including CNN-based and Siamese-network approaches, which reported accuracies ranging from 96.1% to 99.68%. These results demonstrate that pseudo-color augmentation combined with Vision Transformers can significantly enhance MRI-based Alzheimer's disease classification. PseudoColorViT-Alz offers a robust and interpretable framework that outperforms current methods, providing a promising tool to support clinical decision-making and early detection of Alzheimer's disease.
Siamese-Driven Optimization for Low-Resolution Image Latent Embedding in Image Captioning
Dec 09, 2025Image captioning is essential in many fields including assisting visually impaired individuals, improving content management systems, and enhancing human-computer interaction. However, a recent challenge in this domain is dealing with low-resolution image (LRI). While performance can be improved by using larger models like transformers for encoding, these models are typically heavyweight, demanding significant computational resources and memory, leading to challenges in retraining. To address this, the proposed SOLI (Siamese-Driven Optimization for Low-Resolution Image Latent Embedding in Image Captioning) approach presents a solution specifically designed for lightweight, low-resolution images captioning. It employs a Siamese network architecture to optimize latent embeddings, enhancing the efficiency and accuracy of the image-to-text translation process. By focusing on a dual-pathway neural network structure, SOLI minimizes computational overhead without sacrificing performance, making it an ideal choice for training on resource-constrained scenarios.
* 6 pages
Accurate online action and gesture recognition system using detectors and Deep SPD Siamese Networks
Nov 07, 2025Online continuous motion recognition is a hot topic of research since it is more practical in real life application cases. Recently, Skeleton-based approaches have become increasingly popular, demonstrating the power of using such 3D temporal data. However, most of these works have focused on segment-based recognition and are not suitable for the online scenarios. In this paper, we propose an online recognition system for skeleton sequence streaming composed from two main components: a detector and a classifier, which use a Semi-Positive Definite (SPD) matrix representation and a Siamese network. The powerful statistical representations for the skeletal data given by the SPD matrices and the learning of their semantic similarity by the Siamese network enable the detector to predict time intervals of the motions throughout an unsegmented sequence. In addition, they ensure the classifier capability to recognize the motion in each predicted interval. The proposed detector is flexible and able to identify the kinetic state continuously. We conduct extensive experiments on both hand gesture and body action recognition benchmarks to prove the accuracy of our online recognition system which in most cases outperforms state-of-the-art performances.