 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamsum Corpus
Papers and Code
CONFIT: Toward Faithful Dialogue Summarization with Linguistically-Informed Contrastive Fine-tuning
Dec 16, 2021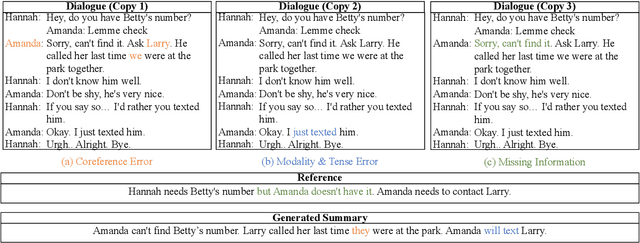
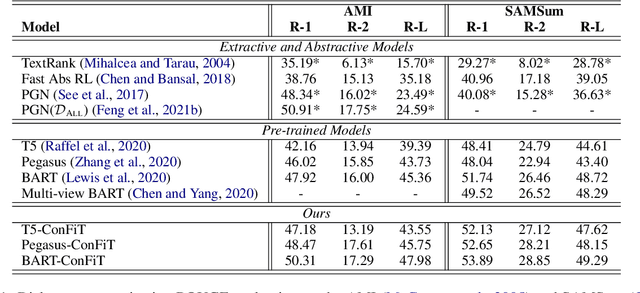
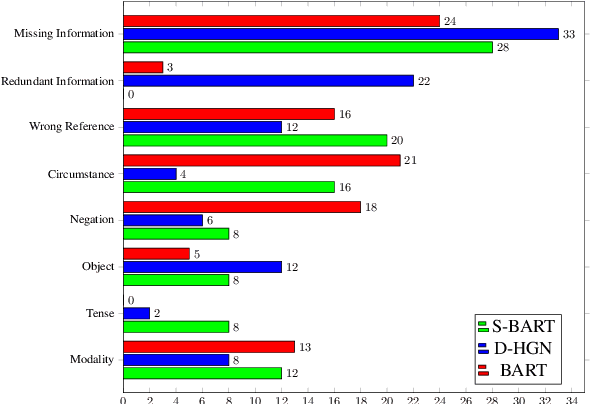
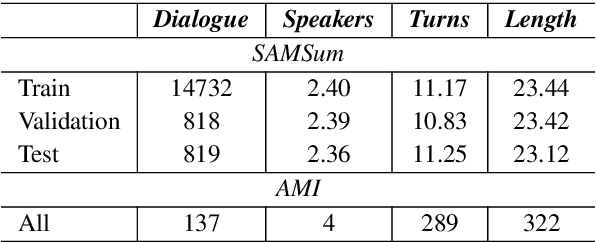
Factual inconsistencies in generated summaries severely limit the practical applications of abstractive dialogue summarization. Although significant progress has been achieved by using pre-trained models, substantial amounts of hallucinated content are found during the human evaluation. Pre-trained models are most commonly fine-tuned with cross-entropy loss for text summarization, which may not be an optimal strategy. In this work, we provide a typology of factual errors with annotation data to highlight the types of errors and move away from a binary understanding of factuality. We further propose a training strategy that improves the factual consistency and overall quality of summaries via a novel contrastive fine-tuning, called ConFiT. Based on our linguistically-informed typology of errors, we design different modular objectives that each target a specific type. Specifically, we utilize hard negative samples with errors to reduce the generation of factual inconsistency. In order to capture the key information between speakers, we also design a dialogue-specific loss. Using human evaluation and automatic faithfulness metrics, we show that our model significantly reduces all kinds of factual errors on the dialogue summarization, SAMSum corpus. Moreover, our model could be generalized to the meeting summarization, AMI corpus, and it produces significantly higher scores than most of the baselines on both datasets regarding word-overlap metrics.
Who says like a style of Vitamin: Towards Syntax-Aware DialogueSummarization using Multi-task Learning
Sep 29, 2021
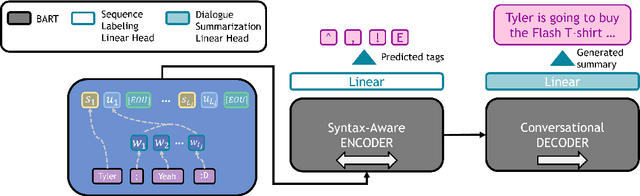
Abstractive dialogue summarization is a challenging task for several reasons. First, most of the important pieces of information in a conversation are scattered across utterances through multi-party interactions with different textual styles. Second, dialogues are often informal structures, wherein different individuals express personal perspectives, unlike text summarization, tasks that usually target formal documents such as news articles. To address these issues, we focused on the association between utterances from individual speakers and unique syntactic structures. Speakers have unique textual styles that can contain linguistic information, such as voiceprint. Therefore, we constructed a syntax-aware model by leveraging linguistic information (i.e., POS tagging), which alleviates the above issues by inherently distinguishing sentences uttered from individual speakers. We employed multi-task learning of both syntax-aware information and dialogue summarization. To the best of our knowledge, our approach is the first method to apply multi-task learning to the dialogue summarization task. Experiments on a SAMSum corpus (a large-scale dialogue summarization corpus) demonstrated that our method improved upon the vanilla model. We further analyze the costs and benefits of our approach relative to baseline models.
Controllable Abstractive Dialogue Summarization with Sketch Supervision
Jun 03, 2021
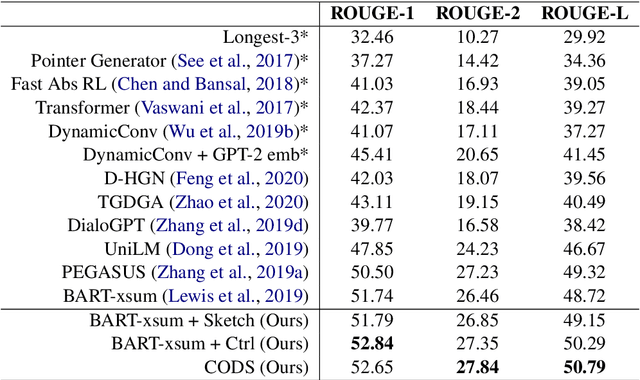
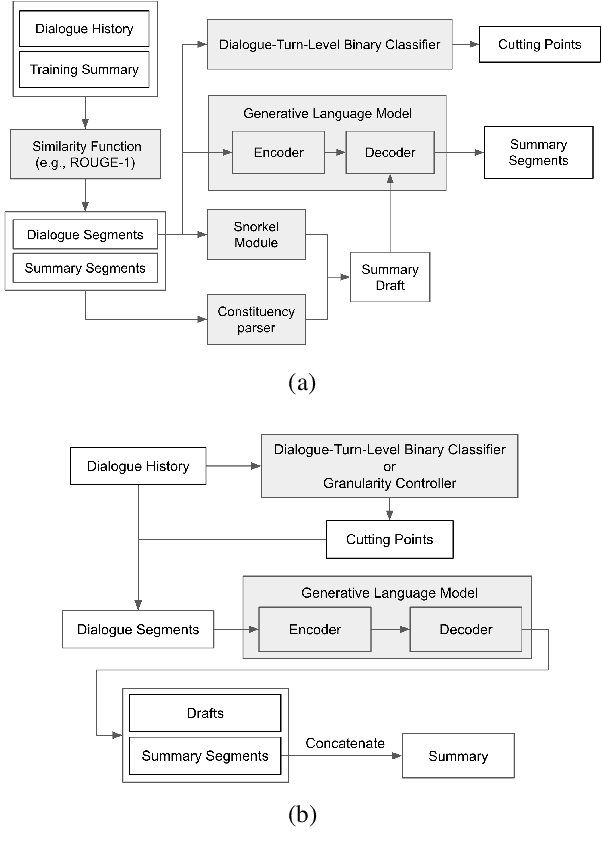

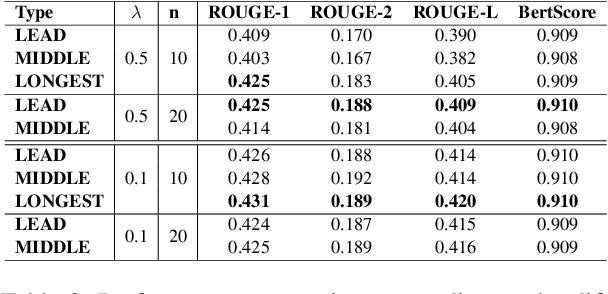
In this paper, we aim to improve abstractive dialogue summarization quality and, at the same time, enable granularity control. Our model has two primary components and stages: 1) a two-stage generation strategy that generates a preliminary summary sketch serving as the basis for the final summary. This summary sketch provides a weakly supervised signal in the form of pseudo-labeled interrogative pronoun categories and key phrases extracted using a constituency parser. 2) A simple strategy to control the granularity of the final summary, in that our model can automatically determine or control the number of generated summary sentences for a given dialogue by predicting and highlighting different text spans from the source text. Our model achieves state-of-the-art performance on the largest dialogue summarization corpus SAMSum, with as high as 50.79 in ROUGE-L score. In addition, we conduct a case study and show competitive human evaluation results and controllability to human-annotated summaries.
SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization
Nov 29, 2019

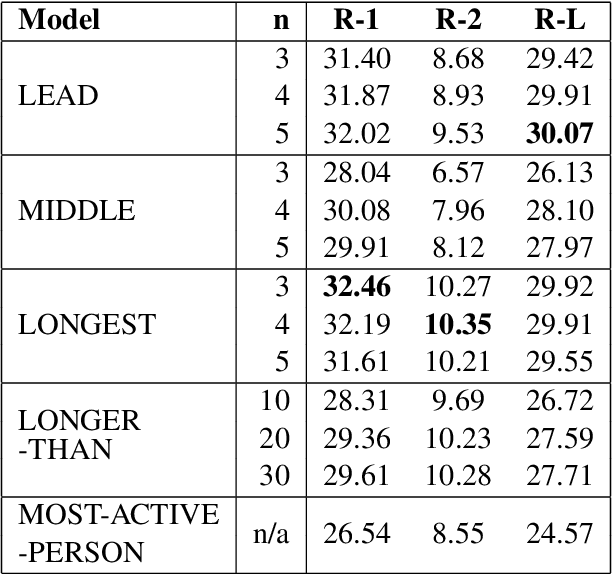
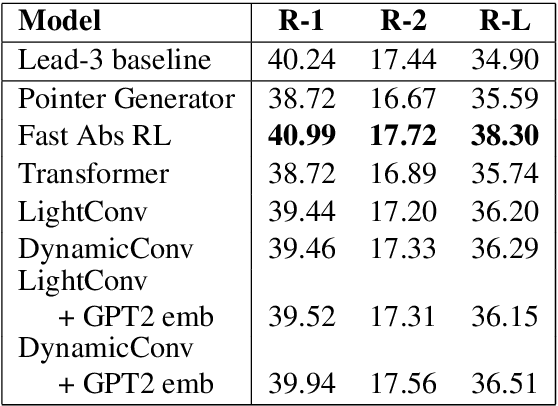
This paper introduces the SAMSum Corpus, a new dataset with abstractive dialogue summaries. We investigate the challenges it poses for automated summarization by testing several models and comparing their results with those obtained on a corpus of news articles. We show that model-generated summaries of dialogues achieve higher ROUGE scores than the model-generated summaries of news -- in contrast with human evaluators' judgement. This suggests that a challenging task of abstractive dialogue summarization requires dedicated models and non-standard quality measures. To our knowledge, our study is the first attempt to introduce a high-quality chat-dialogues corpus, manually annotated with abstractive summarizations, which can be used by the research community for further studies.
* Attachment contains the described dataset archived in 7z format. Please see the attached readme and licence. Update of the previous version: changed formats of train/val/test files in corpus.7z
Incorporating Commonsense Knowledge into Abstractive Dialogue Summarization via Heterogeneous Graph Networks
Oct 20, 2020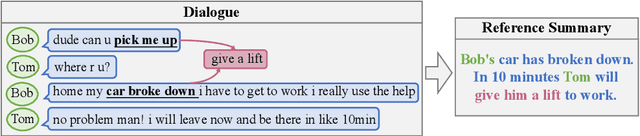
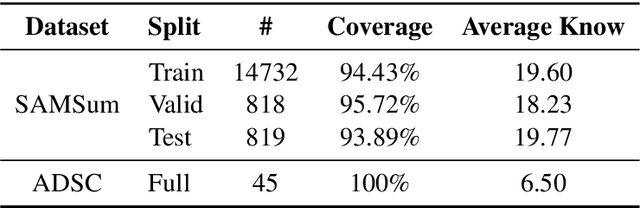
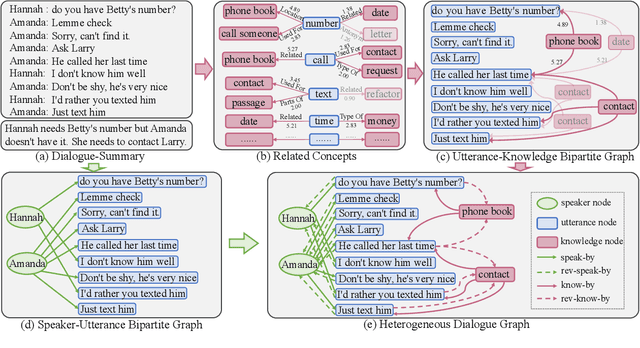
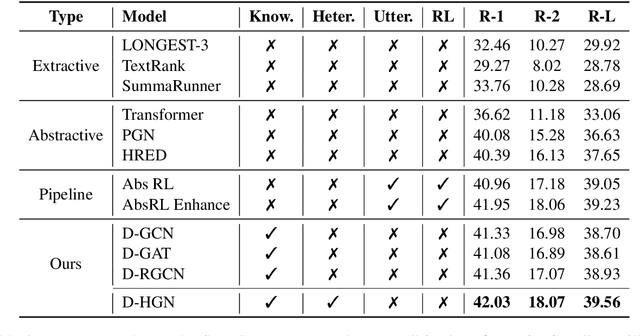
Abstractive dialogue summarization is the task of capturing the highlights of a dialogue and rewriting them into a concise version. In this paper, we present a novel multi-speaker dialogue summarizer to demonstrate how large-scale commonsense knowledge can facilitate dialogue understanding and summary generation. In detail, we consider utterance and commonsense knowledge as two different types of data and design a Dialogue Heterogeneous Graph Network (D-HGN) for modeling both information. Meanwhile, we also add speakers as heterogeneous nodes to facilitate information flow. Experimental results on the SAMSum dataset show that our model can outperform various methods. We also conduct zero-shot setting experiments on the Argumentative Dialogue Summary Corpus, the results show that our model can better generalized to the new domain.