 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRwth Phoenix Weather 2014
Papers and Code
Evaluation of Pose Estimation Systems for Sign Language Translation
Apr 27, 2026Many sign language translation (SLT) systems operate on pose sequences instead of raw video to reduce input dimensionality, improve portability, and partially anonymize signers. The choice of pose estimator is often treated as an implementation detail, with systems defaulting to widely available tools such as MediaPipe Holistic or OpenPose. We present a systematic comparison of pose estimators for pose-based SLT, covering widely used baselines (MediaPipe Holistic, OpenPose) and newer whole-body/high-capacity models (MMPose WholeBody, OpenPifPaf, AlphaPose, SDPose, Sapiens, SMPLest-X). We quantify downstream impact by training a controlled SLT pipeline on RWTH-PHOENIX-Weather 2014 where only the pose representation varies, evaluating with BLEU and BLEURT. To contextualize translation outcomes, we analyze temporal stability, missing hand keypoints, and robustness to occlusion using higher-resolution videos from the Signsuisse dataset. SDPose and Sapiens achieve the best translation performance (BLEU ~11.5), outperforming the common MediaPipe baseline (BLEU ~10). In occlusion cases, Sapiens is correct in all tested instances (15/15), while OpenPifPaf fails in nearly all (1/15) and also yields the weakest translation scores. Estimators that frequently leave out hand keypoints are associated with lower BLEU/BLEURT. We release code that can be used not only to reproduce our experiments, but also considerably lowers the barrier for other researchers to use alternative pose estimators.
A multitask transformer to sign language translation using motion gesture primitives
Mar 25, 2025The absence of effective communication the deaf population represents the main social gap in this community. Furthermore, the sign language, main deaf communication tool, is unlettered, i.e., there is no formal written representation. In consequence, main challenge today is the automatic translation among spatiotemporal sign representation and natural text language. Recent approaches are based on encoder-decoder architectures, where the most relevant strategies integrate attention modules to enhance non-linear correspondences, besides, many of these approximations require complex training and architectural schemes to achieve reasonable predictions, because of the absence of intermediate text projections. However, they are still limited by the redundant background information of the video sequences. This work introduces a multitask transformer architecture that includes a gloss learning representation to achieve a more suitable translation. The proposed approach also includes a dense motion representation that enhances gestures and includes kinematic information, a key component in sign language. From this representation it is possible to avoid background information and exploit the geometry of the signs, in addition, it includes spatiotemporal representations that facilitate the alignment between gestures and glosses as an intermediate textual representation. The proposed approach outperforms the state-of-the-art evaluated on the CoL-SLTD dataset, achieving a BLEU-4 of 72,64% in split 1, and a BLEU-4 of 14,64% in split 2. Additionally, the strategy was validated on the RWTH-PHOENIX-Weather 2014 T dataset, achieving a competitive BLEU-4 of 11,58%.
Improvement in Sign Language Translation Using Text CTC Alignment
Dec 12, 2024



Current sign language translation (SLT) approaches often rely on gloss-based supervision with Connectionist Temporal Classification (CTC), limiting their ability to handle non-monotonic alignments between sign language video and spoken text. In this work, we propose a novel method combining joint CTC/Attention and transfer learning. The joint CTC/Attention introduces hierarchical encoding and integrates CTC with the attention mechanism during decoding, effectively managing both monotonic and non-monotonic alignments. Meanwhile, transfer learning helps bridge the modality gap between vision and language in SLT. Experimental results on two widely adopted benchmarks, RWTH-PHOENIX-Weather 2014 T and CSL-Daily, show that our method achieves results comparable to state-of-the-art and outperforms the pure-attention baseline. Additionally, this work opens a new door for future research into gloss-free SLT using text-based CTC alignment.
A Comparative Study of Continuous Sign Language Recognition Techniques
Jun 18, 2024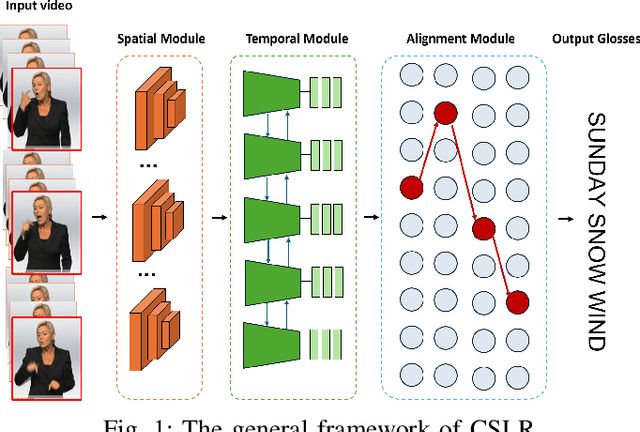

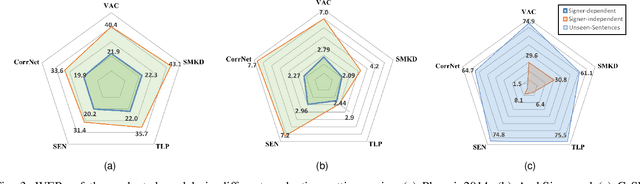

Continuous Sign Language Recognition (CSLR) focuses on the interpretation of a sequence of sign language gestures performed continually without pauses. In this study, we conduct an empirical evaluation of recent deep learning CSLR techniques and assess their performance across various datasets and sign languages. The models selected for analysis implement a range of approaches for extracting meaningful features and employ distinct training strategies. To determine their efficacy in modeling different sign languages, these models were evaluated using multiple datasets, specifically RWTH-PHOENIX-Weather-2014, ArabSign, and GrSL, each representing a unique sign language. The performance of the models was further tested with unseen signers and sentences. The conducted experiments establish new benchmarks on the selected datasets and provide valuable insights into the robustness and generalization of the evaluated techniques under challenging scenarios.
Multi-Scale Local-Temporal Similarity Fusion for Continuous Sign Language Recognition
Jul 27, 2021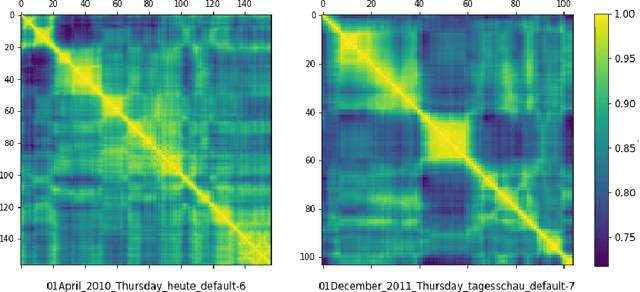

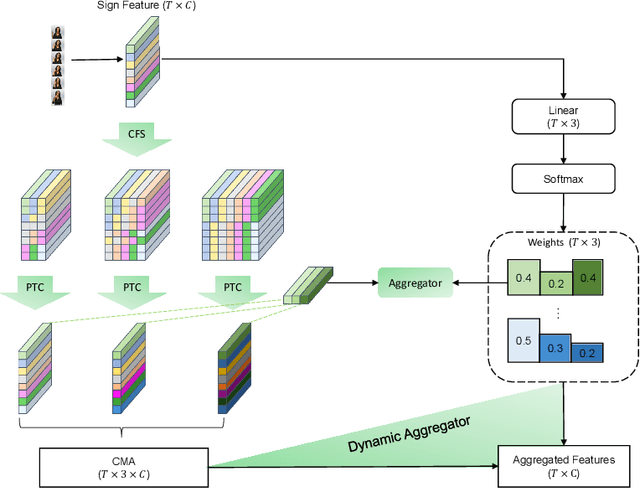

Continuous sign language recognition (cSLR) is a public significant task that transcribes a sign language video into an ordered gloss sequence. It is important to capture the fine-grained gloss-level details, since there is no explicit alignment between sign video frames and the corresponding glosses. Among the past works, one promising way is to adopt a one-dimensional convolutional network (1D-CNN) to temporally fuse the sequential frames. However, CNNs are agnostic to similarity or dissimilarity, and thus are unable to capture local consistent semantics within temporally neighboring frames. To address the issue, we propose to adaptively fuse local features via temporal similarity for this task. Specifically, we devise a Multi-scale Local-Temporal Similarity Fusion Network (mLTSF-Net) as follows: 1) In terms of a specific video frame, we firstly select its similar neighbours with multi-scale receptive regions to accommodate different lengths of glosses. 2) To ensure temporal consistency, we then use position-aware convolution to temporally convolve each scale of selected frames. 3) To obtain a local-temporally enhanced frame-wise representation, we finally fuse the results of different scales using a content-dependent aggregator. We train our model in an end-to-end fashion, and the experimental results on RWTH-PHOENIX-Weather 2014 datasets (RWTH) demonstrate that our model achieves competitive performance compared with several state-of-the-art models.
Sign Segmentation with Changepoint-Modulated Pseudo-Labelling
Apr 28, 2021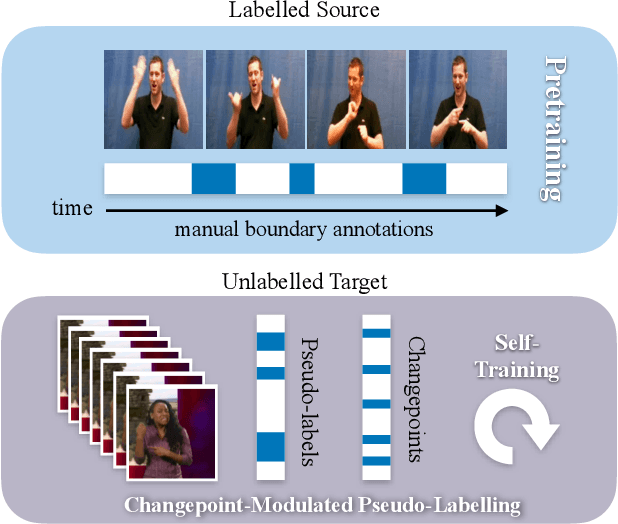
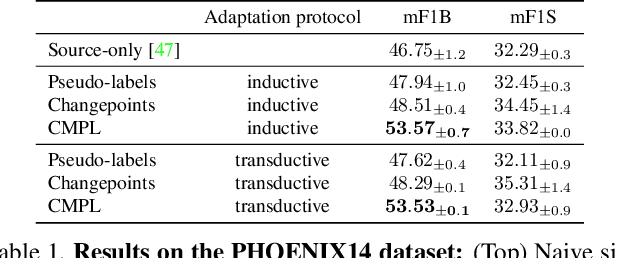
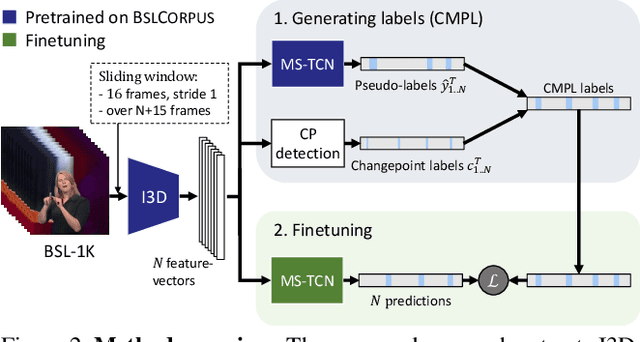

The objective of this work is to find temporal boundaries between signs in continuous sign language. Motivated by the paucity of annotation available for this task, we propose a simple yet effective algorithm to improve segmentation performance on unlabelled signing footage from a domain of interest. We make the following contributions: (1) We motivate and introduce the task of source-free domain adaptation for sign language segmentation, in which labelled source data is available for an initial training phase, but is not available during adaptation. (2) We propose the Changepoint-Modulated Pseudo-Labelling (CMPL) algorithm to leverage cues from abrupt changes in motion-sensitive feature space to improve pseudo-labelling quality for adaptation. (3) We showcase the effectiveness of our approach for category-agnostic sign segmentation, transferring from the BSLCORPUS to the BSL-1K and RWTH-PHOENIX-Weather 2014 datasets, where we outperform the prior state of the art.
Context Matters: Self-Attention for Sign Language Recognition
Jan 12, 2021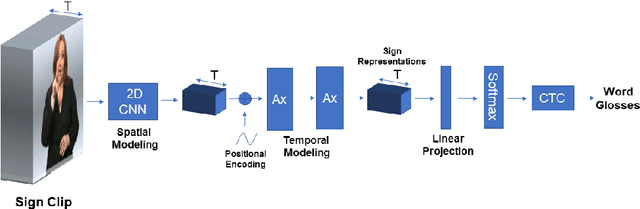
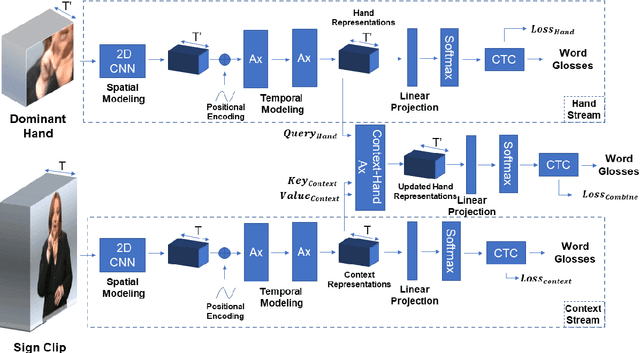
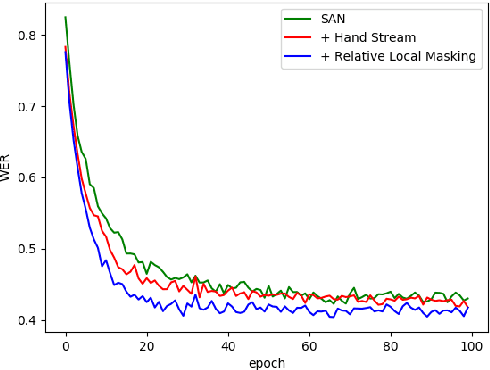

This paper proposes an attentional network for the task of Continuous Sign Language Recognition. The proposed approach exploits co-independent streams of data to model the sign language modalities. These different channels of information can share a complex temporal structure between each other. For that reason, we apply attention to synchronize and help capture entangled dependencies between the different sign language components. Even though Sign Language is multi-channel, handshapes represent the central entities in sign interpretation. Seeing handshapes in their correct context defines the meaning of a sign. Taking that into account, we utilize the attention mechanism to efficiently aggregate the hand features with their appropriate spatio-temporal context for better sign recognition. We found that by doing so the model is able to identify the essential Sign Language components that revolve around the dominant hand and the face areas. We test our model on the benchmark dataset RWTH-PHOENIX-Weather 2014, yielding competitive results.
FePh: An Annotated Facial Expression Dataset for the RWTH-PHOENIX-Weather 2014 Dataset
Mar 03, 2020

Facial expressions are important parts of both gesture and sign language recognition systems. Despite the recent advances in both fields, annotated facial expression dataset in the context of sign language are still scarce resources. In this manuscript, we introduce a continuous sign language facial expression dataset, comprising over $3000$ annotated images of the RWTH-PHOENIX-Weather 2014 development set. Unlike the majority of currently existing facial expression datasets, FePh provides sequenced semi-blurry facial images with different head poses, orientations, and movements. In addition, in the majority of images, identities are mouthing the words, which makes the data more challenging. To annotate this dataset we consider primary, secondary, and tertiary dyads of seven basic emotions of "sad", "surprise", "fear", "angry", "neutral", "disgust", and "happy". We also considered the "None" class if the image's facial expression could not be described by any of the aforementioned emotions. Although we provide FePh in the context of facial expression and sign language, it has a wider application in gesture recognition and Human Computer Interaction (HCI) systems. The dataset will be publicly available.
Quantitative Survey of the State of the Art in Sign Language Recognition
Aug 29, 2020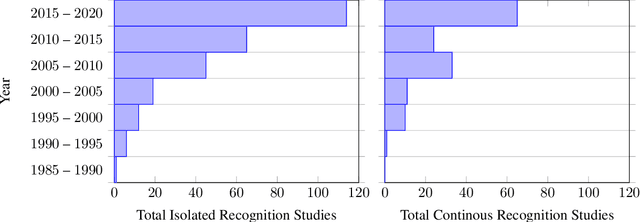
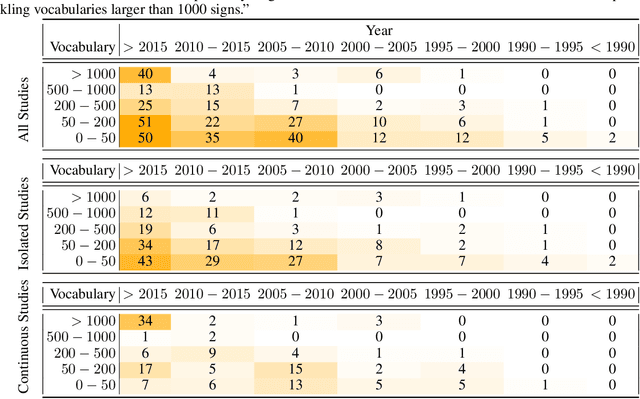
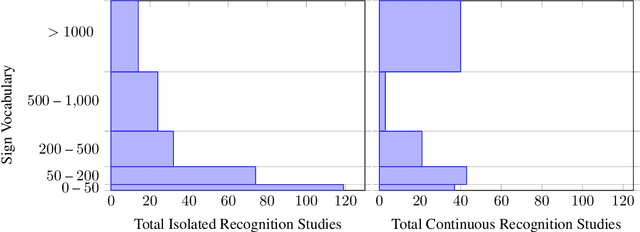
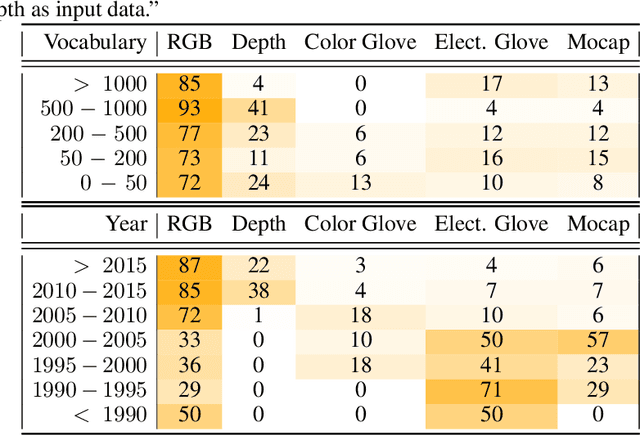
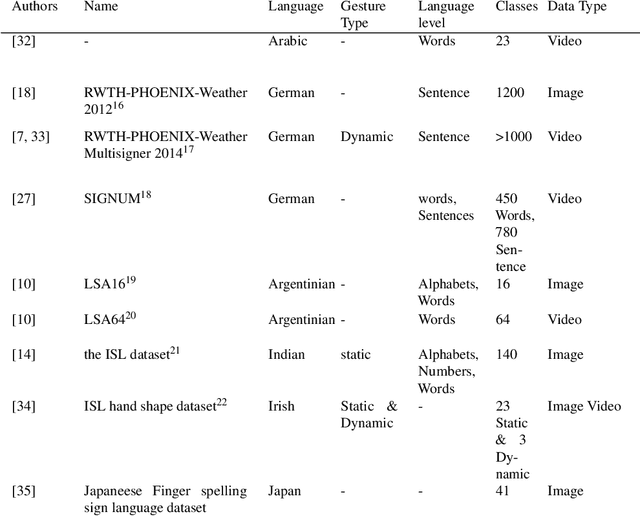
This work presents a meta study covering around 300 published sign language recognition papers with over 400 experimental results. It includes most papers between the start of the field in 1983 and 2020. Additionally, it covers a fine-grained analysis on over 25 studies that have compared their recognition approaches on RWTH-PHOENIX-Weather 2014, the standard benchmark task of the field. Research in the domain of sign language recognition has progressed significantly in the last decade, reaching a point where the task attracts much more attention than ever before. This study compiles the state of the art in a concise way to help advance the field and reveal open questions. Moreover, all of this meta study's source data is made public, easing future work with it and further expansion. The analyzed papers have been manually labeled with a set of categories. The data reveals many insights, such as, among others, shifts in the field from intrusive to non-intrusive capturing, from local to global features and the lack of non-manual parameters included in medium and larger vocabulary recognition systems. Surprisingly, RWTH-PHOENIX-Weather with a vocabulary of 1080 signs represents the only resource for large vocabulary continuous sign language recognition benchmarking world wide.